Evaluation
评估通常是在面对新数据时估计被测系统的性能。为了进行客观的评价,系统输入以前未见过的数据,这些数据有参考注释。然后将系统输出与参考进行比较,以计算其性能的度量。性能意味着什么,以及应该如何测量它可能会因所开发系统的规格和要求而有所不同:我们可以测量精度来反映系统正确分类或检测声音的频率,或者我们可以测量错误率来反映系统出错的频率。通过使用相同的数据和相同的方法来评估不同的系统(可能在不同的地方和/或在不同的时间),可以对系统的能力进行公平和直接的比较。系统的主观评价也是可能的,它依赖于人类对系统性能的评价。
主观评价通常包括听力实验,并结合对系统输出的同意或满意评级。当测试数据没有可用的参考注释,或者系统明确以客户满意度为目标时,主观评价是有用的。下面,我们将讨论局限于客观评价,因为通过定性方法测量用户体验是特定于应用程序的,超出了本书的范围,在可用性工程和人机交互中更常见。
Evaluation Setup
在系统开发过程中,需要对系统进行迭代训练和测试,对系统参数进行调优。为此,可用于开发的标记数据被分割为互不关联的训练集和测试集。然而,标记的数据通常是短缺的,并且很难选择是使用更多的数据进行训练(导致更好的系统性能)还是用于测试(给出更精确和可靠的系统性能估计)。为了有效地使用所有可用数据,系统开发可以使用交叉验证折叠[11,第483页]来使用相同的数据人为地创建多个训练/测试分割;总体性能是每次分割的性能平均值。交叉验证折叠还有助于避免过拟合,并支持系统的泛化属性,因此当系统用于新数据时,它有望具有与用于开发的数据相似的性能。

如果可用,可以使用带有参考注释的单独示例集来评估完全调优系统的泛化属性——我们将此集称为评估集,并使用它来评估系统在新数据上的表现。图6.5演示了将数据集划分为开发数据和评估数据的示例,并将开发数据进一步划分为训练和测试子集,分为五次。这里进行了拆分,这样所有数据最多只能测试一个时间,但也可以通过在每个子集中随机选择数据来创建训练/测试子集。然而,根据原始数据集的创建方式,有一些细节需要考虑。
当将数据集分割为训练和测试子集时,音频示例可用的元数据有助于确保来自相同位置的数据(相同原始长录音的片段)或具有相同内容的数据(使用相同实例的合成数据)不会在训练和测试集之间分割。这是必要的,以确保系统学习数据的一般属性,而不是特定实例的细节。
如果可能的话,建议对数据进行分层。这意味着以一种有监督的方式将数据分割为折叠,这样每个折叠都是数据的代表。分层的目的是确保开发中使用的训练和测试集包含平衡的数据,所有类都存在于所有折叠中,每个类[50]的数据量相似。不幸的是,这并不总是可行的,特别是在多标签分类或复调声音事件检测时。大多数情况下,可用的数据并不是完全平衡的,在这种情况下,应该至少构造训练/测试的分割,以确保没有在相应的训练数据中不存在的被测试的类。
在开发过程中经常需要对系统进行重复评估,这包括在测试系统后计算选择的度量。对于不平衡的数据,不同的折叠会有不同数量的类数据,甚至在给定折叠的测试集中完全缺失类。在这种情况下,将整体性能计算为折叠性能的平均值将取决于数据在折叠中的分布方式,并且对于任何不同的分割都会有所不同。这可以通过将折叠视为单个实验并仅在执行完整的交叉验证之后评估系统性能来避免,从而确保所有类都在测试集中[15]中得到充分表示。
Evaluation Measures
评估是通过将系统输出与测试数据可用的参考注释进行比较来完成的。用于声音场景和声音事件检测和分类的指标包括
- 准确性accuracy
- 精度precision
- 召回率recall
- F-score
- 接收者工作特征(ROC)曲线receiver operating characteristic (ROC) curve
- 曲线下面积(AUC)area under the curve (AUC)
- 声音事件错误率(AEER)acoustic event error rate(AEER)
- 简单的错误率(ER) simply error rate
对于哪种度量标准能够普遍地有效地衡量声音事件检测的性能,人们并没有达成共识,因为它们都反映了系统能力的不同角度。
Intermediate Statistics
许多性能测量依赖于试验,即系统正确或错误的原子机会的概念,并且指标是基于正确预测的计数和系统所犯的不同类型的错误来计算的。这些计数被称为中间统计量,并根据评估程序进行定义。给定类c,它们的定义如下:
- True positive: A correct prediction, meaning that the system ouput and the reference both indicate class c preesnet or active.
- True negative: The system output and the reference both indicate class c not presnet or inactive.
- False positive or insertion: The system output indicates class c present or active, while the reference indicates class c not presnet or inactive.
- False negative or deletion: The system output indicates class c is not present or inactive, while the reference indicates class c present or active.
当系统输出指示类别c而引用指示类别g时,假阳性可能与假阴性同时出现。在这种情况下,一些指标认为系统犯了一个错误(替换),而不是两个单独的错误。关于如何为特定情况定义替换的更多细节将随使用它们的度量的描述一起呈现。
中间统计数据是根据系统输出和测试数据[47]的可用参考之间的试验比较计算出来的。单个试验可以由注释中标识的特定项目组成,或者简单地由固定长度的间隔组成。固定长度的间隔可以是任何小的时间单位,例如20- 100ms的帧,类似于典型的音频分析帧[39,53],或者更长的间隔,如1s[24]。在项目级比较中,项目可以是从头到尾的整个音频剪辑,也可以是一个声音事件实例。对应的度量在声音事件中被称为基于分段的度量和基于项目或基于事件的[32]度量。
声学场景分类通常是一个单标签多类问题,由此产生的中间指标反映了每个示例是否正确识别单个真实类。在这个任务中,没有替换的角色计数错误输出;假阳性和假阴性之间没有区别。在场景分割中,中间统计量可以在短时间间隔内进行统计,也可以基于分割边界进行统计。
在声音事件检测中,测量的选择决定了结果的解释:使用基于段的度量,性能显示了系统正确检测声音事件活跃的时间区域的程度;使用基于事件的度量,性能可以显示系统检测具有正确起始和偏移的事件实例的能力。如果我们考虑复调声音事件检测的场景,基于段的度量实际上是将测试音频的持续时间分割为固定长度的段,这些段具有多个关联标签,反映给定段中任何地方活动的声音事件。在这方面,求值验证系统输出和参考在分配的标签中是否重合,而段的长度决定了求值的时间分辨率。基于事件的度量逐个比较事件实例。由于系统检测到的事件的时间范围可能与地面真相不完全匹配,一种常见的方法是允许一个时间偏差阈值,作为一个固定的值(例如,100毫秒)或作为总事件持续时间的固定比例(例如,50%)[53]。时间阈值可以仅应用于开始时间,也可以同时应用于开始时间和偏移时间。真正的否定(即正确地记录在给定的时间内没有发生任何事件)不会出现在这种评估中,因为没有基于实例的真正否定可以被计算在内。图6.6展示了系统输出与基于段和基于事件的评估中的引用之间的比较,以获得中间统计信息。
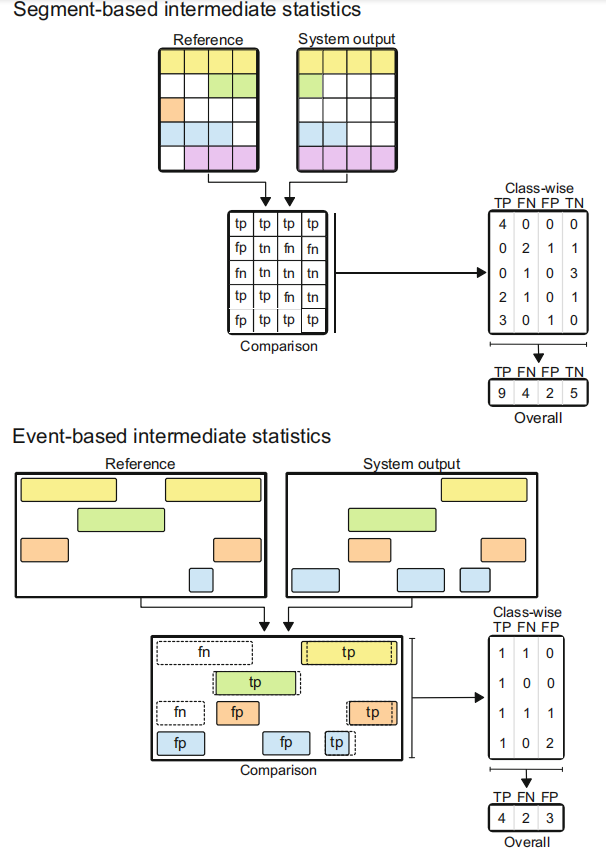
metric
性能度量是根据中间统计值的累积值来计算的。
我们用TP、TN、FP和FN表示整个测试数据中累积的真阳性、真阴性、假阳性和假阴性的总和。按照同样的约定,我们将用S表示替换的总数,用I表示插入,用D表示删除。
We denote by TP, TN, FP, and FN the sums of the true positives, ture negatives, false positives, and false negtives accumulated throughout the test data.
With same convention, we will use S for the total number of substitutions, I for insertions, and D for deletions.
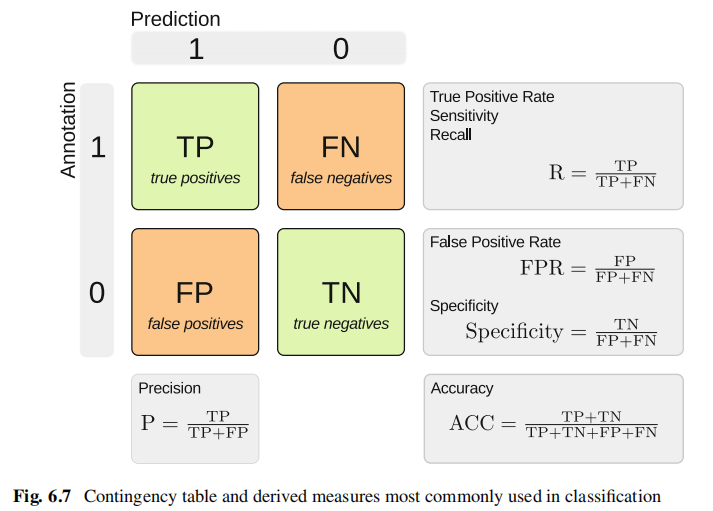
考虑一个简单的二元分类,我们比较c类的参考和系统输出,我们可以构造列联表,或如图6.7所示的混淆矩阵。基于中间统计的总数,可以得出许多不同的测量方法,其中最常用的是召回率(R,也称为真阳性率(TPR)或敏感性、精密度(P)、假阳性率(FPR)、特异性和准确性(ACC)。这些措施在图6.7中给出并定义。
在处理多类问题时,中间统计信息的积累可以全局地执行,也可以为每个类[49]单独执行,从而得出基于实例或基于类的整体度量。高度不平衡的类或个别类的表现,在用这两种方法计算时,会导致整体表现非常不同。在基于实例的平均(也称为微观平均)中,中间统计信息是在整个数据上累积的。总体性能是基于这些指标来计算的计算基于类别的度量,然后使用非均匀加权将它们组合起来,以创建一个平均值,该平均值反映了不同类别的相对重要性,这些类别可能与它们在测试数据中出现的频率不同。
Accuracy
Accuracy measures how often the classifier makes the correct decision, as the ratio of correct system outputs to total number of outputs.
准确性的优点是为系统做出正确决策的能力提供了一个简单的衡量标准;它是声音场景和声音事件分类中使用最多的度量,计算简单易懂。然而,它有一个严重的缺点,即受类平衡的影响:对于很少的类(即TP+FN很小),即使没有做出正确的预测,系统也可能有高比例的真负值,这导致了一个矛盾的高准确度值。精度不提供任何关于错误类型的信息(即FP和FN的平衡);然而,在许多情况下,这些不同类型的错误具有非常不同的含义。
Precision, Recall, and F-Score
Precision, recall, and F-Score were introduced in [42] in the context of information retrieval, but have found their way into measuring performance in other applicationis. Precision and recall are also defined in Fig.6.7:
as based on them, balanced F-score is calculated as their harmonic mean:
精密度precision和查全率recall是信息检索中的首选指标,但在分类中也以阳性预测值positive prediction value和敏感性sensitivity的名称使用。在检测理论术语中,召回率recall等于真阳性率true positive rate,但精度precision没有简单的等价。
F-score的优势在于它是一种熟悉且易于理解的指标。它的主要缺点是它的值受到平均值的选择和类之间的数据平衡的强烈影响:在基于实例的平均中,公共类的性能占主导地位,而在基于类的平均(平衡指标)中,必须至少确保在测试数据的所有折叠中存在所有类,以避免召回未定义的情况(当TP+FN=0时);对实例很少的类的度量估计本质上也是有噪声的。任何真实世界记录的数据集都很可能具有不平衡的事件类;因此,在建立实验设置时,必须考虑到度量的选择。
Average Precision
由于精度和召回率依赖于每次试验做出的硬决策,它们通常依赖于应用于某些潜在决策变量的阈值,例如到决策边界的距离或神经网络的输出。降低阈值将增加接受正面和负面例子的可能性,提高recall,但在许多情况下会损害准确性precision。F-measure将这些值组合在一个单一的阈值上,试图平衡这种权衡,但是通过绘制精度作为召回率的函数在整个可能的阈值范围内-精度-召回率(P-R)曲线by plotting precision as a function of recall over the full range of possible thresholds--the precision-recall (P-R) curve,可以提供更全面的图像。图6.8显示了一个二元分类问题的P-R曲线示例。

While P-R curves carry rich information, they can be difficult to compare, so a single figure of merit summarizing the precision-recall tradeoff is desirable.
The information retrieval community most commonly uses average precision (AP), which is defined as the precision averaged over all thresholds at which a new positive example is accepted:
虽然P-R曲线包含了丰富的信息,但它们很难进行比较,因此需要一个总结精度-召回率权衡的单一优点数字。信息检索界最常用的是平均精度(AP),它被定义为所有阈值上的平均精度,在此阈值上,一个新的正例被接受:
where NP=TP+FN is the total number of positve examples,
\(\Theta_{P}\) is the set of NP thresholds at which a new positve example is accepted,
and \(TP(\theta)\) and \(FP(\theta)\) are the true and false positive counts, respectively, of the system running with threshold \(\theta\).
这个值接近P-R曲线下的面积;然而,它避免了由曲线的非单调性引起的问题——当召回率随着阈值的降低而单调增长时,精度可能会上升或下降,这取决于新阈值下包含的正示例和反示例的平衡。相对于由f分数总结的单个工作点(即阈值),AP反映了整个工作点范围内的性能。因为它基于更大的测量集(积分曲线),它通常比点测量(如F-score)更稳定(噪音更小),这是它受欢迎的原因之一。一个多类问题的类别之间的平均精度组合称为平均平均精度,或mAP。
ROC Curves and AUC
The receiver operating characteristic (ROC) curve and corresponding area under the curve (AUC) are used to examine the performance of a binary classifier over a range of discrimination thresholds.
An ROC curve, as illustrated in Fig.6.8, plots the true positive rate (TPR) as a function of the false positive rate (FPR), or sensitivity vs. (1-specificity) as the decision threshold is varied.
AUC将整个ROC曲线总结为一个数字,并允许在所有工作点上比较分类器,更好的分类器具有更高的AUC。AUC可以等效地用更直观易懂的d-prime来指定,d-prime定义为两个单位方差高斯函数的均值之间的分离,其ROC曲线产生给定的AUC。一个相关的度量是等错误率(EER),它是ROC曲线上真阳性率和假阳性率相等的点(即ROC曲线与y = 1 - x线的交点);因此,更好的分类器具有较小的EER。像F-measure一样,EER是一个点测量,通常比AUC更容易变化,它集成了一系列工作点。然而,EER的优势在于,它直接用一个可解释的值来表示,即分类错误率(正面例子和反面例子)。
AUC将整个ROC曲线总结为一个数字,并允许在所有工作点上比较分类器,更好的分类器具有更高的AUC。AUC可以等效地用更直观易懂的dprime来指定,dprime定义为两个单位方差高斯函数的均值之间的分离,其ROC曲线产生给定的AUC。一个相关的度量是等错误率(EER),它是ROC曲线上真阳性率和假阳性率相等的点(即ROC曲线与y = 1 - x线的交点);因此,更好的分类器具有较小的EER。像f测量一样,EER是一个点测量,通常比AUC更容易变化,它集成了一系列工作点。然而,EER的优势在于,它直接用一个可解释的值来表示,即分类错误率(正面例子和反面例子)。
ROC曲线的替代方法是DET曲线(用于检测误差权衡)[30]。DET曲线,如图6.8的第三个面板所示,绘制假阴性率(FNR = 1 -TPR)作为FPR的函数,其中两个轴都被“probit”函数扭曲。如果底层的类别条件分数分布为高斯分布,则得到的图形将成为一条直线,其斜率反映了正类和负类分数分布的相对方差,其与they = x线的截距表示总体类别可分性。
ROC曲线的主要缺点是它们只适用于二元分类器,对多类问题的泛化没有很好的定义。与精度/召回率测量一样,最常见的泛化方法是将每个类的性能单独视为二进制分类器输出,并将性能计算为按类的AUC或EER的平均值。这种方法隐藏了跨类的任何性能变化,以产生一个单一的性能值来表征系统。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号