PANNs: Large-Scale Pretrianed Audio Neural Networks for Audio Pattern Recognition
Audio Pattern Recognition includes:
- audio tagging
- acoustic scene classification
- music classification
- speech emotion classification
- sound event detection
...
We investigate the performance and computational complexity of PANNs modeled by a variety of convolutioanl neural networks.
We propose an architecture called Wavegram-Logmel-CNN using both log-mel spectrogram and waveform as input feature.
The contribution of this work includes:
(1) We introduec PANNs trained on AudioSet with 1.9 million audio clip with an ontology of 527 sound classes;
(2) We investigate the trade-off between audio tagging performance and computatoin complexity of a wide range of PANNs;
(3) We propose a system that we call Wavegram-Logmel-CNN that achieves a ..
(4) We show that PANNs can be transferred to other audio pattern recognitioini tasks, outperforming several sota systems
(5) We have released the source code and pretrained PANN models.
CNN
- Conventioanl CNNs: A CNN consists of several convolutioanl layers.
Each convolutioanl layer contains several kernels that are convolved with the input feature maps to capture their local patterns.
CNNs adopted for audio tagging often use log mel spectrograms as input. - Adapting CNNs for AudioSet tagging: The PANNs we use are based on our previously-proposed cross-task CNN systems for the DCASE 2019 challenge, with an extra fully-connected layer added to the penultimate layer(倒数第二层) of CNNs to further increase the representation ability.
We investigate 6-, 10- and 14-layer CNNs.
The 6-layer CNN consists of 4 convolutional layers with a kernel size of 5x5, based on AlexNet.
The 10- and 14-layer CNNs consist of 4 and 6 convolutional layers, respectively, inspired by the VGG-like CNNs.
Each convolutioanl block consists of 2 convolutional layers with a kernel size of 3x3. Batch normalization is applied between each convolutioanl layer, and the ReLU nonlinearity is used to speed up and stabilize the training.
We apply average pooling of size of 2x2 to each convolutioanl block for downsampling, as 2x2 average pooling has been shown to outperform 2x2 max pooling.
Global pooling is applied after the last convolutional layer to summarize the feature maps into a fixed-length vector. To combine maximum and average operation, we sum the averaged and maximized vectors.
In our previous work, those fixed-length vectors were used as embedding features for audio clips. In this work, we add an extra fully-connected layer to the fixed length vectors to extract embedding features which can further increase their representation ability.
For a particular audio pattern recognition task, a linear classifier is applied to the embedding features, followed by either a softmax nonlinearity for classififcation tasks or a sigmoid nonlinearity for tagging task.
Dropout is applied after each downsampling operation and fully connected layers to prevent systems from overfitting.
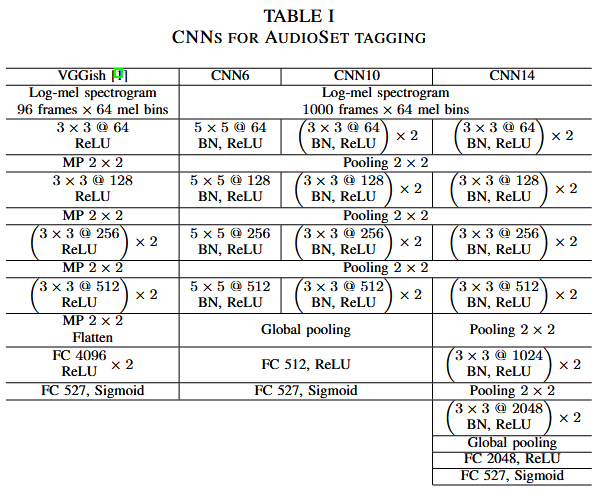
Table 1 summarizes our proposed CNN systems. The number after the "@" symbol indicates the number of feature maps.
We denote the waveform of an audio clip as \(x_{n}\), where n is the index of audio clips, and \(f(x_{n})\in [0,1]^{K}\) is the output of a PANN representing the presence probabilities of \(K\) sound classes. The label of \(x_{n}\) is denoted as \(y_{n}\in \{0,1\}^{K}\).
A binary cross-entropy loss funciton \(l\) is used to trian a PANN:
where \(N\) is the number of training clips in AudioSet.
In training, the parameters of \(f()\) are optimized by using gradient descent methods to minimize the loss funciton \(l\).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号