2019, Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
Abstract
Gradient-weighted Class Activation Mapping, uses the gradients of any target concept flowing into the final convolutional layer to prodece a coarse localization map highlighting the important regions in the image for predicting the concept.
Apply to a wide variety of CNN model-families.
Introduction
What makes a good visual explanation?
a)class-discriminative (i.e. localize the category in the image)
b)high-resolution (i.e. capture fine-grained detail)
Related Work
Visualizing CNNs
Backpropagation - not class-discriminative
Other - not specific to a single input image
Assessing Model Trust
human studies
Aligning Gradient-based Importances
Weakly-supervised localization
Class Activation Mapping (CAM) - it is only applicable to a particular kind of CNN architectures performing global average pooling over convolutional maps immediately prior to prediction.
Grad-CAM
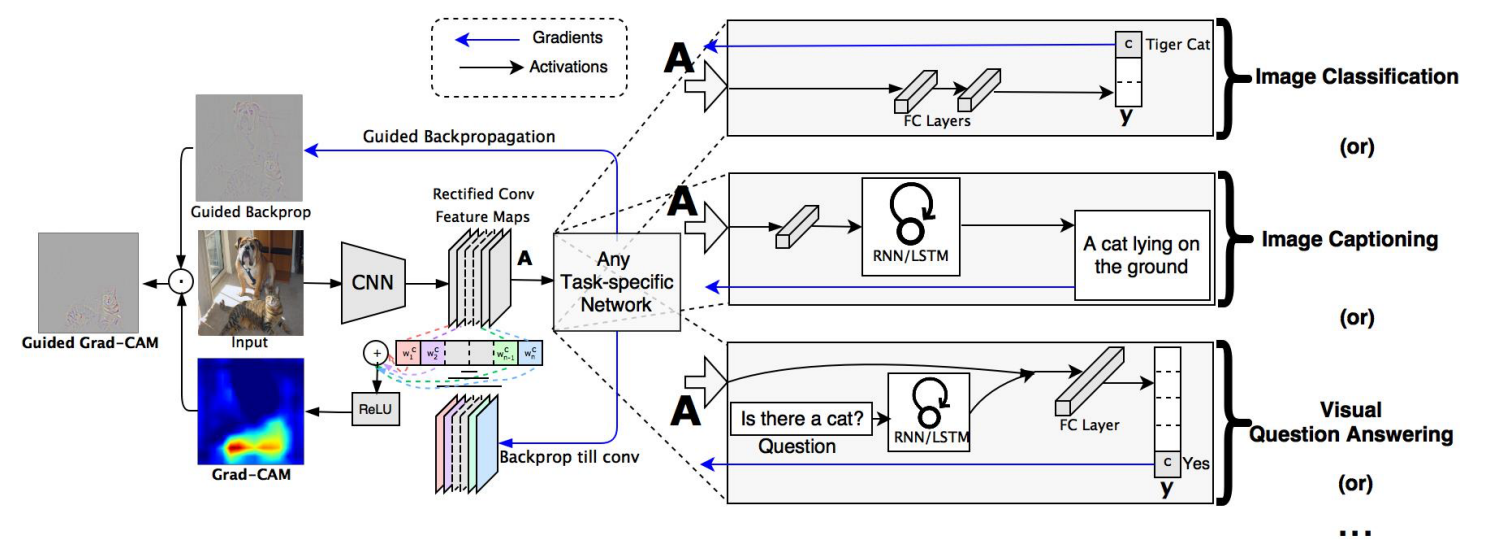
As shown in Fig, in order to obtain the class-discriminative localization map Grad-CAM \(L_{Grad-CAM}^{c}\in \R^{u\times v}\) of width \(u\) and height \(v\) for any class \(c\),
we first compute the gradient of the score for class \(c\), \(y^{c}\) (before the softmax), with respect to feature map activations \(A^{k}\) of a convolutional layer, i.e. \(\frac{\partial y^{c}}{\partial A^{k}}\).
These gradients flowing back are global-average-pooled over the width and height dimensions (indexed by \(i\) and \(j\) respectively) to obtain the neuron importance weights \(\alpha_{k}^{c}\):
During computation of \(\alpha_{k}^{c}\) while backpropagating gradients with respect to activations, the exact computation amounts to successive matrix products of the weight matrices and the gradient with respect to activation functions till the final convolution layer that the gradient are being propagated to.
Hence, this weight \(\alpha_{k}^{c}\) represnets a partial linearization of the deep network downstream from \(A\), and captures the 'importance' of feature map \(k\) for a target class \(c\).
We perform a weighted combination of forward activation maps, and follow it by a ReLU to obtain,
We apply a ReLU to the linear combination of maps because we are only interested in the features that have a positive influence on the class of interest, i.e. pixels whose intensity should be increased in order to increase \(y^{c}\). Negative pixels are likely to belong to other categories in the image.
Grad-CAM generalizes CAM
Recall that CAM produces a localization map for an image classification CNN with a specific kind of architecture where global average pooled convolutional feature maps are fed directly into softmax.
Specifically, let the penultimate layer produce \(K\) feature maps, \(A^{k}\in\R^{u\times v}\), with each element indexed by \(i,j\). So \(A^{k}_{i j}\) refers to the activation at location \((i,j)\) of the feature map \(A^{k}\).
These feature maps are then spatially pooled using Global Average Pooling (GAP) and linearly transformed to produce a score \(Y^{c}\) for each class c,
Let us define \(F^{k}\) to be the global average pooled output, CAM computes the final scores by,
where \(w^{c}_{k}\) is the weight connecting the kth feature map with the cth class. Taking the gradient of the score for class \(c(Y^{c})\) with respect to the feature map \(F^{k}\) we get,
Summing both sides of over all pixels \((i,j)\),
Since \(Z\) and \(w_{k}^{c}\) do not depend on \((i,j)\), Note that \(Z\) is the number of pixels in the feature map (or \(Z=\sum_{i}\sum_{j}1\)). Thus, we can re-order terms and see that
Up to a proportioanlity constant \((1/Z)\) that gets normalized-out during visualization, the expression for \(w_{k}^{c}\) is identical to \(\alpha_{k}^{c}\) used by Grad-GAM. Thus, Grad-GAM is a strict generalization of CAM.
Guided Grad-CAM
Counterfactual Explanations
Using a slight modification to Grad-CAM, we can obtain explanations that highlight support for regions that would make the networks change its prediction. We refer to this explanation modality as counterfactual explanations.
Specifically, we negate the gradient of \(y^c\) with respect to feature maps \(A\) of a convolutional layer. Thus the importance weights \(\alpha_k^c\) now become
We take a weighted sum of the forward activation maps, A, with weights \(a_k^c\), and follow it by a ReLU to obtain counterfactual explanations as shown in Fig.

Evaluating Localization Ability of Grad-CAM
Weakly-supervised Localization
在本节中,我们在图像分类的背景下评估GradCAM的定位能力。ImageNet的定位挑战[14]要求除分类标签外还提供边界框的方法。与分类类似,对前1和前5预测类别进行评估。
给定一张图像,我们首先从我们的网络中获得类预测,然后为每个预测的类生成Grad-CAM映射,并以最大强度的15%的阈值将它们二值化。这将导致像素的连接片段,我们在最大的单个片段周围画一个边界框。注意,这是弱监督的定位,在训练过程中,模型从未暴露在边界框注释中。
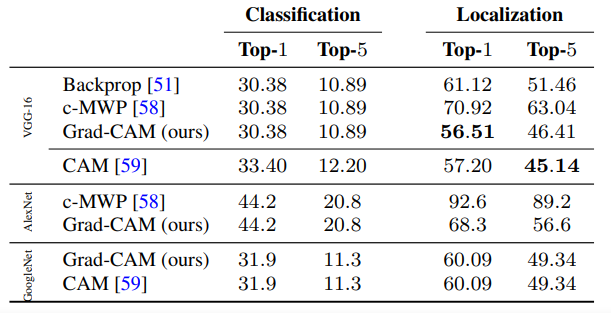
我们用现成的预先训练好的VGG-16[52], AlexNet[33]和GoogleNet[54]评估Grad-CAM定位(获取自Caffe [27] Zoo)。在ILSVRC-15评估后,我们报告了表1中val集的前1和前5位定位错误。Grad-CAM定位误差明显优于c-MWP[58]和Simonyan等人[51]实现的定位误差,后者使用抓取切割将图像空间梯度后处理成热图。VGG-16的Grad-CAM的top-1定位误差也优于CAM[59],这需要改变模型架构,需要重新训练,因此分类误差更差(top-1差2.98%),而Grad-CAM在分类性能上没有妥协。
Weakly-supervised Segmentation
Pointing Game
Evaluating Visualizations
Evaluating Class Discrimination
Evaluating Trust
Faithfulness vs. Interpretability
Diagnosing image classification CNNs with Grad-CAM
在本节中,我们进一步演示了在imagenet上预训练的VGG-16的背景下,Grad-CAM在分析图像分类cnn的故障模式、理解对抗性噪声的影响以及识别和去除数据集中的偏差方面的使用。
Analyzing failure modes for VGG-16
为了看到网络犯了什么错误,我们首先得到一个网络(VGG-16)未能正确分类的示例列表。对于这些错误分类的例子,我们使用Guided Grad-CAM来可视化正确的和预测的类。如图6所示,一些失败是由于ImageNet分类固有的模糊性造成的。我们还可以看到,看似不合理的预测都有合理的解释,HOGgles[56]中也有这样的观察。与其他方法相比,Guided Grad-CAM可视化的一个主要优势是,由于其高分辨率和类别区分能力,它很容易实现这些分析。

Effect of adversarial noise on VGG-16
Goodfellow等人[22]演示了当前深度网络对对抗性示例的脆弱性,对抗性示例是对输入图像的轻微不可察觉的扰动,可以欺骗网络,使其以高可信度错误分类。我们为imagenet预训练的vg -16模型生成对抗图像,以便它将高概率(> 0.9999)分配给图像中不存在的类别以及存在类别的低概率。然后,我们计算现有类别的Grad-CAM可视化。如图7所示,尽管网络确定不存在这些类别(“虎猫”和“拳击手”),但Grad-CAM可视化可以正确地定位它们。这表明Grad-CAM对对抗噪声具有相当的鲁棒性。

Grad-CAM for the top-2 predicted classes “airliner” and “space shuttle” seems to highlight the background.
Identifying bias in dataset
在有偏见的数据集上训练可能无法推广到现实场景,更糟糕的是,可能会使偏见和刻板印象(w.r.t.性别、种族、年龄等)持续存在。我们调整了一个ImageNetpre训练的vgg-16模型,用于“医生”vs.“护士”二元分类任务。我们使用来自一个流行的图像搜索引擎的前250张相关图像(每个类)构建了我们的训练和验证分割。测试集被控制在两个类别的性别分布上是平衡的。虽然训练后的模型获得了良好的验证精度,但它的泛化效果并不好(82%的测试精度)。模型预测的Grad-CAM可视化显示(见图8中间栏的红框区域)在本节中,我们演示了Grad-CAM的另一种用法: 识别和减少训练数据集中的偏差。模型模型已经学会了通过观察人的脸/发型来区分护士和医生,从而学习性别刻板印象。事实上,这种模式错误地将几名女医生划分为护士,将几名男护士划分为医生。显然,这是有问题的。事实证明,图片搜索结果存在性别偏见(78%的医生图片是男性,93%的护士图片是女性)。
通过从Grad-CAM可视化中获得的这些直觉,我们通过添加男护士和女医生的图像来减少训练集中的偏见,同时保持每个类的图像数量与以前相同。重新训练的模型不仅泛化得更好(90%的测试准确率),而且还能看到正确的区域(图8的最后一列)。这个实验证明了一个概念,即grada-cam可以帮助检测和消除数据集中的偏差,这不仅对更好的泛化很重要,而且随着社会上做出更多的算法决策,对公平和道德的结果也很重要。
Textual Explanations with Grad-CAM
方程(1)给出了一种获取特定类卷积层中每个神经元的神经元重要性a的方法。文献[60,57]中提出了神经元作为概念“探测器”的假设。神经元重要性值越高,表明该概念的存在会导致该类别得分的增加,而值越高,表明该概念的不存在会导致该类别得分的增加。基于这种直觉,让我们研究一种生成文本解释的方法。在最近的工作中,Bau et al.[4]提出
一种在训练网络的任何卷积层中自动命名神经元的方法。这些名称表示神经元在图像中寻找的概念。使用他们的方法。我们首先获得最后一个卷积层的神经元名称。接下来,我们根据前5和后5神经元的类别特定重要性分数(ak)对它们进行排序并获得,这些神经元的名称可以用作文本解释。
图9显示了在Places365数据集上训练的图像分类模型(vg -16)的一些视觉和文本解释示例[61]。在(a)中,由(1)计算的正重要神经元寻找直观的概念,如书和架子,这些概念表示类“书店”。还要注意的是,负重要神经元会寻找天空、道路、水和汽车等概念,而这些概念不会出现在“书店”图像中。在(b)中,为了预测“瀑布”,视觉和文本解释都突出了“水”和“分层”,这是对“瀑布”图像的描述。(e)是由于分类错误导致的失败案例,因为网络在没有绳子的情况下预测了“索桥”,但仍然有重要的概念(水和桥)表明了预测的类别。在(f)中,虽然Grad-CAM正确地观察了纸上的门和楼梯来预测“电梯门”,但检测门的神经元没有超过0.05的IoU阈值7(选择这些阈值是为了抑制神经元名称中的噪声),因此不是文本解释的一部分。更多定性的例子可以在第六章中找到。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号