A Closer Look at the Convolutional Layer
1. What CNNs Can Do
2. Image Classification
Different lighting, contrast, viewpoints, etc.
This is hard for traditional methods like multi-layer perceptrons, because the prediction is basically based on a sum of pixel intensities.
3. Convolutional Neural Network Basics
Relational Inductive Biases:
Independence, Locality, Sequentiality
LeNet-5:
1989, Backpropagation Applied to Handwritten Zip Code Recognition
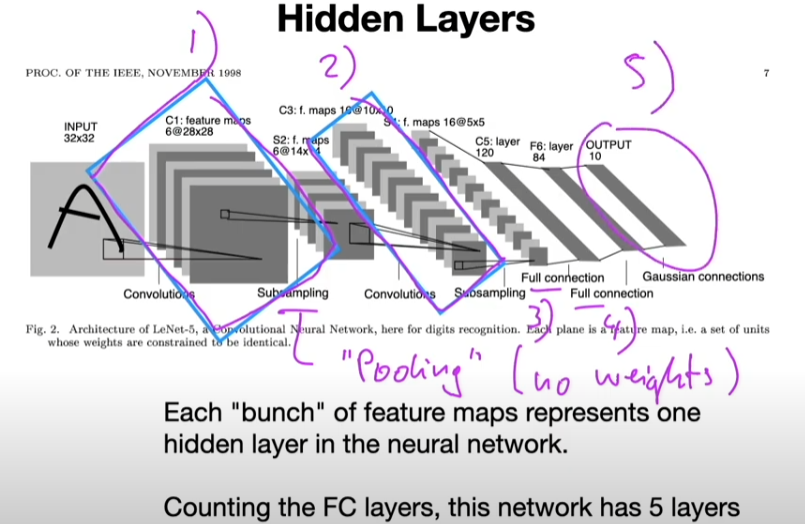
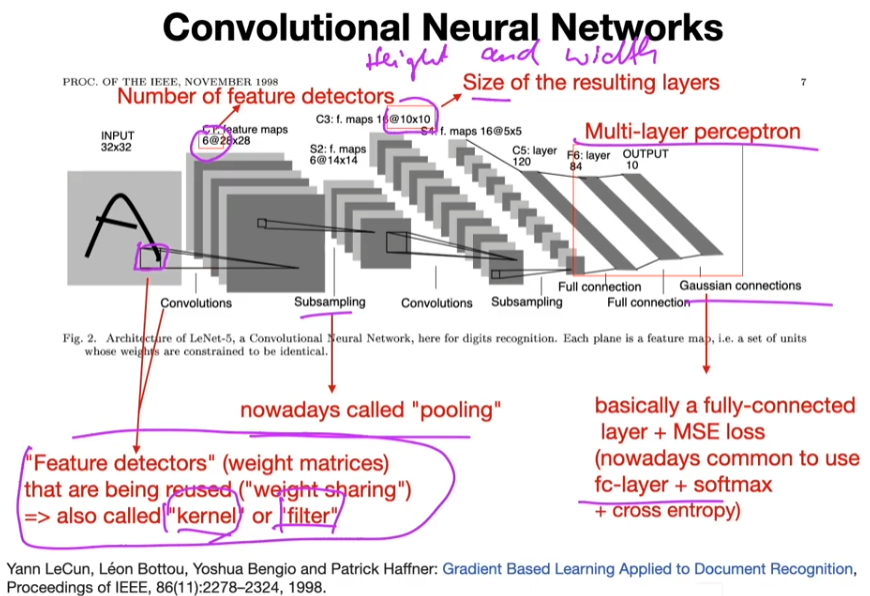
Main Concepts Behind Convolutional Neural Networks
- Sparse-connectivity: A single element in the feature map in connected to only a small patch of pixels.
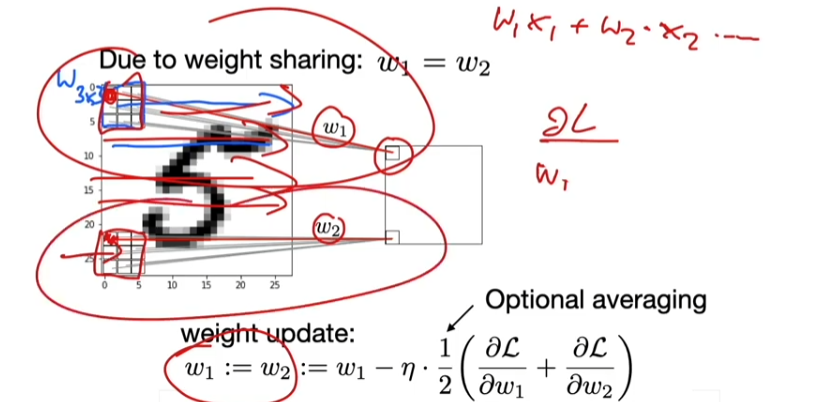
- Parameter-sharing: The same weights are used for different patches of the input image.
- Many layers: Combining extracted local patterns to global patterns
4. Convolutional Filters and Weight-Sharing
Weight Sharing
Rationale: A feature detector that works well in one region may also work well in another region. Plus, it is a nice reduction in parameters to fit.
Multiple "feature detectors" (kernel) are used to create multiple feature maps
Size Before and After Convolutions
Feature map size:
output_width = (input_width-kernel_width + 2*padding)/stride+1
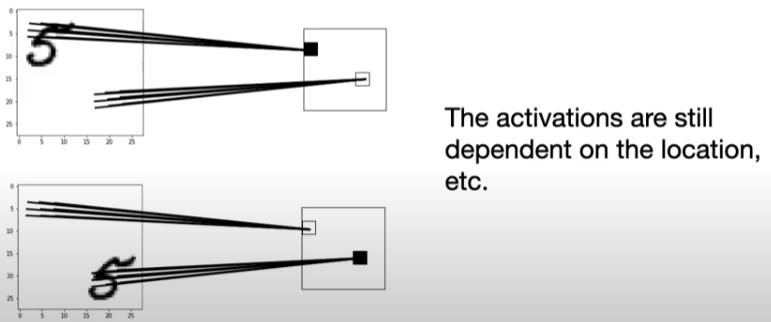
Note that CNNs are not really invariant to scale, ratation, translation, etc.
Cross-Correlation:
1)2)3)
4)5)6)
7)8)9)
Convolution:
9)8)7)
6)5)4)
3)2)1)
Basically, we are flipping the kernel (or the receptive field) horizontally and vertically.
In DL, we usually don't care about that (as opposed to many traditional computer vision and signal processing applications).
Also, cross-correlation is easier to implement.
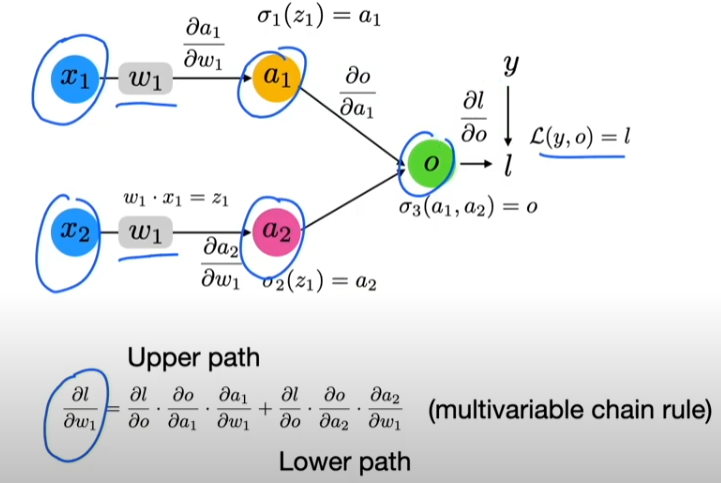
6. CNNs & Backpropagation
Same overall concept as before: Multivariable chain rule, but now with an additional weight sharing constraint.
7. CNN Architectures
main breakthrough for CNNs AlexNet & ImageNet
Note that the actual network inputs were still 224x224 images (random crops from downsampled 256x256 images)
224x224 is still a good/reasonable size tody (224x224x3=150,528 features)
8. What a CNN Can See
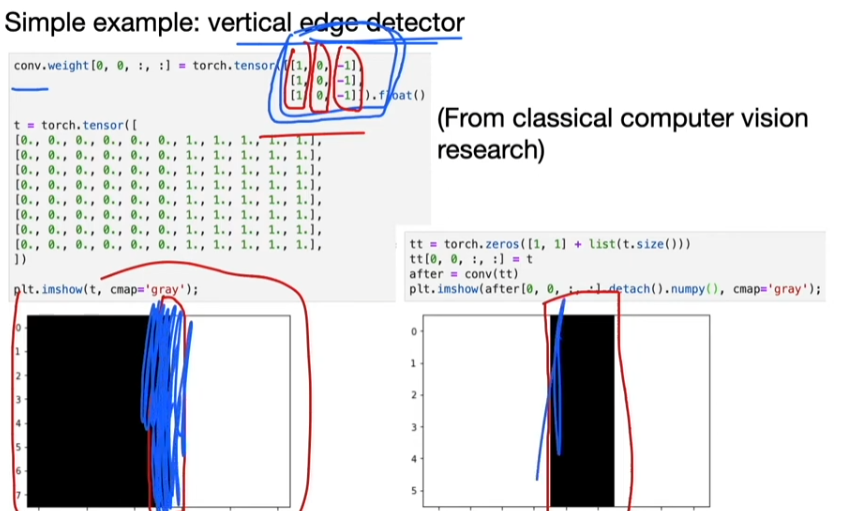
2014, Visualizing and understanding convolutional network.
Method: backpropagate strong activation siganls in hidden layers to the input images, then apply "unpooling" to map the values to the original pixel space for visualization.
Grad-GAM...
https://thegradient.pub/a-visual-history-of-interpretation-for-image-recognition/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号