
正则表达式
一、字符串的匹配:matches()
用法:

/*常用写法*/
1. boolean b = Pattern.matches("正则表达式", "匹配内容");
/*标准写法*/
2.Pattern p = Pattern.compile("正则表达式"); Matcher m = p.matcher("匹配内容");
boolean b = m.matches();
二、正则表达式匹配规则
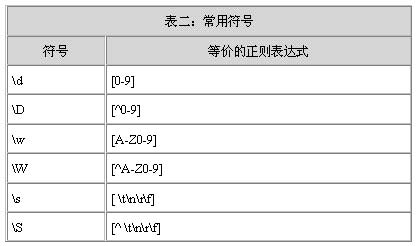
模式 描述
\w 匹配字母、数字、下划线
\W 匹配非字母、数字、下划线
\s 匹配任意空白字符,相当于[\t\n\r\f]
\S 匹配任意非空字符
\d 匹配任意数字,相当于[0-9]
\D 匹配非数字的字符
\A 匹配字符串开头
\Z 匹配字符串结尾,如果存在换行,只匹配到换行前的结束字符串
\z 匹配字符串结尾,如果存在换行,同时还会匹配换行符
\G 匹配最后匹配完成的位置
\n 匹配一个换行符
\t 匹配一个制表符
^ 匹配一行字符串的开头
$ 匹配一行字符串的结尾
. 匹配任意字符,除了换行符
[^…] 不在[]中的字符,比如[^abc]匹配除了a、b、c之外的字符
* 匹配0个或多个表达式
+ 匹配1个或多个表达式
? 匹配0个或1个前面的正则表达式定义的片段,非贪婪方式
() 匹配括号内的表达式,也表示一个组
{n} 精确匹配n个前面的表达式,比如\d{n},代表n个数字
{n,m} 匹配n到m次由前面正则表达式定义的片段,贪婪方式
正则表达式语法
在其他语言中,\\ 表示:我想要在正则表达式中插入一个普通的(字面上的)反斜杠,请不要给它任何特殊的意义。
在 Java 中,\\ 表示:我要插入一个正则表达式的反斜线,所以其后的字符具有特殊的意义。
所以,在其他的语言中(如Perl),一个反斜杠 \ 就足以具有转义的作用,而在 Java 中正则表达式中则需要有两个反斜杠才能被解析为其他语言中的转义作用。也可以简单的理解在 Java 的正则表达式中,两个 \\ 代表其他语言中的一个 \,这也就是为什么表示一位数字的正则表达式是 \\d,而表示一个普通的反斜杠是 \\\\。
字符 说明
^ 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与"\n"或"\r"之后的位置匹配。
$ 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与"\n"或"\r"之前的位置匹配。
* 零次或多次匹配前面的字符或子表达式。例如,zo* 匹配"z"和"zoo"。* 等效于 {0,}。
+ 一次或多次匹配前面的字符或子表达式。例如,"zo+"与"zo"和"zoo"匹配,但与"z"不匹配。+ 等效于 {1,}。
? 零次或一次匹配前面的字符或子表达式。例如,"do(es)?“匹配"do"或"does"中的"do”。? 等效于 {0,1}。
{n} n 是非负整数。正好匹配 n 次。例如,"o{2}"与"Bob"中的"o"不匹配,但与"food"中的两个"o"匹配。
{n,} n 是非负整数。至少匹配 n 次。例如,"o{2,}“不匹配"Bob"中的"o”,而匹配"foooood"中的所有 o。"o{1,}“等效于"o+”。"o{0,}“等效于"o*”。
{n,m} m 和 n 是非负整数,其中 n <= m。匹配至少 n 次,至多 m 次。例如,"o{1,3}"匹配"fooooood"中的头三个 o。‘o{0,1}’ 等效于 ‘o?’。注意:您不能将空格插入逗号和数字之间。
x y
[xyz] 字符集。匹配包含的任一字符。例如,"[abc]“匹配"plain"中的"a”。
[ ^xyz] 反向字符集。匹配未包含的任何字符。例如,"[^abc]“匹配"plain"中"p”,“l”,“i”,“n”。
[a-z] 字符范围。匹配指定范围内的任何字符。例如,"[a-z]"匹配"a"到"z"范围内的任何小写字母。
\d 数字字符匹配。等效于 [0-9]。
\D 非数字字符匹配。等效于 [ ^0-9]。
\w 匹配任何字类字符,包括下划线。与"[A-Za-z0-9_]"等效。
\W 与任何非单词字符匹配。与"[ ^A-Za-z0-9_]"等效。
常用的正则表达式
说明 正则表达式
一、校验数字的表达式 ~ ~ ~ ~ ~ ~ ~ ~ ~ ~
数字 ^ [0-9]*$
n位的数字 ^\d{n}$
至少n位的数字 ^\d{n,}$
m-n位的数字 ^\d{m,n}$
非零开头的最多带两位小数的数字 ^([1-9][0-9]*)+(.[0-9]{1,2})?$
带1-2位小数的正数或负数 ^(-)?\d+(.\d{1,2})?$
有1~3位小数的正实数 ^ [0-9]+(.[0-9]{1,3})?$
非负整数 ^\d+$
非正整数 ^((-\d+)
二、校验字符的表达式 ~ ~ ~ ~ ~ ~ ~ ~ ~ ~
汉字 ^ [\u4e00-\u9fa5]{0,}$
英文和数字 ^ [A-Za-z0-9]+$
长度为3-20的所有字符 ^.{3,20}$
由26个英文字母组成的字符串 ^ [A-Za-z]+$
由数字、26个英文字母或者下划线组成的字符串 ^\w+$ 或 ^\w{3,20}$
中文、英文、数字包括下划线 ^ [\u4E00-\u9FA5A-Za-z0-9_]+$
中文、英文、数字但不包括下划线等符号 ^ [\u4E00-\u9FA5A-Za-z0-9]+$
可以输入含有^%&’,;=?$"等字符 [^%&’,;=?$\x22]+
禁止输入含有~的字符 [^~\x22]+
三、特殊需求表达式 ~ ~ ~ ~ ~ ~ ~ ~ ~ ~
Email地址 ^\w+([-+.]\w+)@\w+([-.]\w+).\w+([-.]\w+)*$
域名 [a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?
InternetURL [a-zA-z]+://[^\s]* 或 ^http://([\w-]+.)+[\w-]+(/[\w-./?%&=]*)?$
手机号码 ^(13[0-9]
电话号码 ^((\d{3,4}-)
身份证号(15位、18位数字) ^\d{15}
短身份证号码(数字、字母x结尾) ^([0-9]){7,18}(x
帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线) ^ [a-zA-Z][a-zA-Z0-9_]{4,15}$
密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线) ^ [a-zA-Z]\w{5,17}$
日期格式 ^\d{4}-\d{1,2}-\d{1,2}
中国邮政编码 [1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
腾讯QQ号 [1-9][0-9]{4,} (腾讯QQ号从10000开始)
IP地址 \d+.\d+.\d+.\d+ (提取IP地址时有用)
中文字符的正则表达式 [\u4e00-\u9fa5]

如下图一:假设我们要在文本文件中搜索美国的社会安全号码。这个号码的格式是999-99-9999。用来匹配它的正则表达式如图一所示。在正则表达式中,连字符(“-”)有着特殊的意义,它表示一个范围,比如从0到9。因此,匹配社会安全号码中的连字符号时,它的前面要加上一个转义字符“/”。

图一:匹配所有123-12-1234形式的社会安全号码
如下图二:假设进行搜索的时候,你希望连字符号可以出现,也可以不出现——即,999-99-9999和999999999都属于正确的格式。这时,你可以在连字符号后面加上“?”数量限定符号,如图二所示:

图二:匹配所有123-12-1234和123121234形式的社会安全号码
如下图三:美国汽车牌照的一种格式是四个数字加上二个字母。它的正则表达式前面是数字部分“[0-9]{4}”,再加上字母部分“[A-Z]{2}”。图三显示了完整的正则表达式。
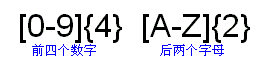
图三:匹配典型的美国汽车牌照号码,如8836KV
如下图四:“^”符号称为“否”符号。如果用在方括号内,“^”表示不想要匹配的字符。例如,图四的正则表达式匹配所有单词,但以“X”字母开头的单词除外。

图四:匹配所有单词,但“X”开头的除外
如下图五:假设要从格式为“June 26, 1951”的生日日期中提取出月份部分,用来匹配该日期的正则表达式可以如图五所示:

图五:匹配所有Moth DD,YYYY格式的日期
如下图六:新出现的“/s”符号是空白符号,匹配所有的空白字符,包括Tab字符。如果字符串正确匹配,接下来如何提取出月份部分呢?只需在月份周围加上一个圆括号创建一个组,然后用ORO API(本文后面详细讨论)提取出它的值。修改后的正则表达式如图六所示:

图六:匹配所有Month DD,YYYY格式的日期,定义月份值为第一个组
如下图七:在前面社会安全号码的例子中,所有出现“[0-9]”的地方我们都可以使用“/d”。修改后的正则表达式如图七所示

图七:匹配所有123-12-1234格式的社会安全号码
如下图八:首先我们来看看IP地址。IP地址有4个字节构成,每一个字节的值在0到255之间,各个字节通过一个句点分隔。因此,IP地址中的每一个字节有至少一个、最多三个数字。图八显示了为IP地址编写的正则表达式:

图八:匹配IP地址
IP地址中的句点字符必须进行转义处理(前面加上“/”),因为IP地址中的句点具有它本来的含义,而不是采用正则表达式语法中的特殊含义。
如下图九:日志记录的时间部分由一对方括号包围。你可以按照如下思路提取出方括号里面的所有内容:首先搜索起始方括号字符(“[”),提取出所有不超过结束方括号字符(“]”)的内容,向前寻找直至找到结束方括号字符。图九显示了这部分的正则表达式。

图九:匹配至少一个字符,直至找到“]”
如下图十:把上述两个正则表达式加上分组符号(圆括号)后合并成单个表达式,这样就可以从日志记录提取出IP地址和时间。注意,为了匹配“- -”(但不提取它),正则表达式中间加入了“/s-/s-/s”。完整的正则表达式如图十所示。
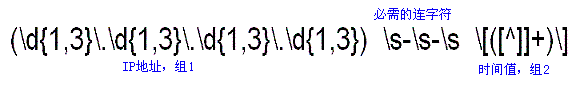
图十:匹配IP地址和时间标记
如下图十一:分析HTML页面内FONT标记的所有属性。匹配FONT标记的所有属性,它从字体标记提取出“"face="Arial, Serif" size="+2" color="red"”。

图十一:匹配FONT标记的所有属性
如下图十二:它把从字体标记提取出“"face="Arial, Serif" size="+2" color="red"”各个属性分割成名字-值对。

图十二:匹配单个属性,并把它分割成名字-值对
参考:
https://www.cnblogs.com/hd92/p/11322415.html
https://blog.csdn.net/weixin_44259720/article/details/88179885

 浙公网安备 33010602011771号
浙公网安备 33010602011771号