langchain note
目录
- 一、langchain组件
- 二、langchain的简单使用
- 三、output_parsers解析模型输出
- 四、memory为模型提供记忆
- 五、核心功能Chains
- 六、基于本地文档的QA程序
- 七、模型评估
- 八、核心功能Agents
- 九、Agent+Tools+Chains+Chroma
一、langchain组件
- models:提供各种大语言模型的接口,可以用来调用许多大语言模型。
- prompts:用于提示控制语言模型做什么,可以用来实现各种有趣的功能。通过创建特定的prompt可以让模型实现特定的功能。
- 输出解析器:以更结构化的格式解析模型的输出,比如指定模型输出JSON或字典。
- chains:langchain的核心思想,将模型的一个完整功能视作一个块,将各个块连接起来组成链,提供端到端的连接。我认为这是langchain最有意思的地方,通过设计不同的链,可以让大语言模型真正做到类似人类逻辑的思考,环环相扣。
- indexs:index使得语言模型可以更好的结合我们已有的数据,index实现了将数据注入系统以与大语言模型结合使用的方式。
- agents:langchain的核心功能,agents让模型和工具可以结合,让模型可以作为推理引擎使用。我认为这也是langchain很有特色的地方,一方面agents可以使语言模型和各种数据源和数据工具结合使用,另外一方面,agents实现了让模型结合我们自己写的功能函数,让我们的程序更智能化。
二、langchain的简单使用
设置openai的细节部分,api_key以及api_base
import os
import openai
os.environ['OPENAI_API_KEY'] = '你的密钥'
openai.api_key = os.environ['OPENAI_API_KEY']
# os.environ['OPENAI_API_BASE'] = 'https://api.openai.com' # 这里的作用,懂的都懂
# openai.api_base = os.environ['OPENAI_API_BASE']简单使用langchain框架调用大语言模型
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
# 1.实例化大语言模型
llm = ChatOpenAI(model_name='gpt-3.5-turbo', temperature=0.7)
# template->prompt->variables->message
# 2.设置template
template = """请翻译下边这段中文为英文:{text}"""
# 3.设置prompt
prompt = ChatPromptTemplate.from_template(template)
# 3.设置传给prompt的variables
variables = """我喜欢吃苹果!"""
# 得到传递给llm的message
messages = prompt.format_messages(text=variables)
# 4.调用模型得到回答
response = llm(messages)
print(response.content)普通调用LLM后,输出的结果均为str类型。如果想要得到json,需要使用output_parsers。
三、output_parsers解析模型输出
output_parsers可以将llm输出的str解析为json
# 导入两个用于解析结果的包Response和StructureOutputParser
from langchain.output_parsers import ResponseSchema
from langchain.output_parsers import StructuredOutputParser
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
# 这里我们想得到一个字典格式的回复
# {"name": "zhangsan", "age": "15", "id": "123456"}
# 1. 设置这三个字段的结构信息
name_schema = ResponseSchema(name="name", description="string类型的,用户的姓名")
age_schema = ResponseSchema(name="age", description="int类型的,用户的年龄")
id_schema = ResponseSchema(name="id", description="string类型的,用户的id")
# 2.将这三个字段统一放入响应结构中
response_schemas = [name_schema,
age_schema,
id_schema]
# 3. 将响应结构导入到解析器中,得到输出解析器
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
# 4. 从输出解析器output_parser中得到 传给LLM的指令格式
format_instructions = output_parser.get_format_instructions()
# 5. 设置模板,模板中最后要加入指令格式format_instructions
template = """下边的text是一个学生的基本情况,对其提取以下信息:\
name:这个学生的姓名是什么?
age:这个学生的年龄是多少?
id:这个学生的学号是多少?
text:{text}
{format_instructions}"""
# 一段人类世界的普通文字
text = """这是ai大学的一个学生,他来自北京,\
现在他刚刚成年了,今天他准备去买一个蛋糕,\
学校门口的保安让他报一下他的学号,他就说他的学号是194050225,\
到了蛋糕店,老板需要把他的名字写在蛋糕上,因此他就告诉老板,他的名字叫李逍遥.\
最后他成功的买上了蛋糕,回学校了."""
# 6. 加载模板到prompt中
prompt = ChatPromptTemplate.from_template(template=template)
# 7. 给提示中的变量赋值,得到最终要传给LLM的消息
messages = prompt.format_messages(text=text, format_instructions=format_instructions)
# 8.实例化大语言模型
llm = ChatOpenAI(temperature=0.9)
# 9.将消息输入给大语言模型
response = llm(messages) # 注意此时得到的结果仍然是str类型的
# 10.使用解析器来解析这个结果,将其转变为字典类型
output_dict = output_parser.parse(response.content)
# 输出字典形式的结果
print(type(output_dict), output_dict)四、memory为模型提供记忆
langchain提供了多种记忆机制,如下所示:
ConversationBufferMemory # 保留会话到缓存区,内存无限增长
ConversationBufferWindowMemory # 保留近几次的对话记录,防止内存无限增长
ConversationTokenBufferMemory # 会话标记缓存记忆
ConversationSummaryMemory # 对话摘要缓存记忆,对超过token限制的部分总结
#vector data memory 使用这种类型的向量数据库检索最相关的文本块作为其内存
#entity memories 实现数字实体的
#或者是将整个对话存储在传统数据库中,比如sql数据库使用ConversationBufferMemory记忆机制实现连续对话
from langchain.chat_models import ChatOpenAI # 导入聊天模型
from langchain.chains import ConversationChain # 导入会话链
from langchain.memory import ConversationBufferMemory # 导入会话缓冲记忆类
from langchain.schema import SystemMessage # 导入系统消息
# 1. 实例化大语言模型
llm = ChatOpenAI(temperature=0.7)
# 2. 设置语言模型的SystemMessage
llm([SystemMessage(content='你是一个精通同态加密的教授,你会用非常通俗易懂的语言解答关于同态加密的问题。')])
# 3. 实例化会话缓冲记忆对象
memory = ConversationBufferMemory()
# 4. 实例化会话链
conversation = ConversationChain(llm=llm, memory=memory, verbose=False)
# 5. 开始进行连续对话
res1 = conversation.predict(input="什么是同态加密?")
print(res1)
res2 = conversation.predict(input="hello,我的名字是逍遥")
print(res2)
res3 = conversation.predict(input="我的名字是什么?")
print(res3)使用ConversationBufferWindowMemory记忆机制实现连续对话
from langchain.memory import ConversationBufferWindowMemory # 导入对话缓冲窗口记忆
from langchain.chains import ConversationChain # 导入会话链
from langchain.chat_models import ChatOpenAI
from langchain.schema import SystemMessage
# 1.实例化大语言模型
llm = ChatOpenAI(temperature=0.9)
# 2.设置语言模型的SystemMessage
llm([SystemMessage(content='你是一个精通同态加密的教授,你会解答学生关于同态加密的问题。')])
# 3.实例化会话缓存窗口记忆对象,参数k表示记忆对话的条数
memory = ConversationBufferWindowMemory(k=1)
# 4.实例化会话链
conversation = ConversationChain(llm=llm, memory=memory, verbose=False)
# 5.使用memory.save_context来模拟连续对话,这里模拟进行了两次连续会话
memory.save_context({"input": "hi!"}, {"output": "what's up?"}) # 必须以字典的形式输入命令
memory.save_context({"input": "Not much, just hanging"}, {"output": "Cool!"}) # 多次调用,会将记忆叠加
# 6.由于k=1,故会话记忆中仅保存一条记忆
print(memory.load_memory_variables({}))使用ConversationTokenBufferMemory记忆机制实现连续对话
from langchain.memory import ConversationTokenBufferMemory
from langchain.chains import ConversationChain
from langchain.chat_models import ChatOpenAI
from langchain.schema import SystemMessage
# 1.实例化大语言模型
llm = ChatOpenAI(temperature=0.7)
# 2.设置语言模型的SystemMessage
llm([SystemMessage(content='你是一个精通同态加密的教授,你会解答学生关于同态加密的问题。')])
# 3.实例化会话标记缓存记忆对象,参数llm=大语言模型,max_token_limit=最大标记限制
memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=60)
# 4.实例化会话链
conversation = ConversationChain(llm=llm, memory=memory, verbose=False)
# 5.模拟连续对话
memory.save_context({"input": "AI is what?!"}, {"output": "Amazing!"})
memory.save_context({"input": "Backpropagation is what?"}, {"output": "Beautiful!"})
memory.save_context({"input": "Chatbots are what?"}, {"output": "Charming!"})
# 6.会话记忆中会根据max_token_limit来缓存
print(memory.load_memory_variables({}))使用ConversationSummaryBufferMemory记忆机制实现连续对话
from langchain.memory import ConversationSummaryBufferMemory # 会话摘要缓存记忆
from langchain.chat_models import ChatOpenAI
from langchain.schema import SystemMessage
from langchain.chains import ConversationChain
# 1.实例化大语言模型
llm = ChatOpenAI(temperature=0.7)
# 2.设置语言模型的SystemMessage
llm([SystemMessage(content='……')])
# 3.实例化会话摘要缓存记忆对象,参数llm=大语言模型,max_token_limit=最大标记数量(对当该值特别大时,会保存完整的聊天记录,否则保留会话总结)
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=100)
# 4.实例化会话链
conversation = ConversationChain(llm=llm, memory=memory, verbose=False)
# 5.模拟连续对话
schedule = "一大段对话。"
memory.save_context({"input": "Hello"}, {"output": "What's up"})
memory.save_context({"input": "Not much, just hanging"}, {"output": "Cool"})
memory.save_context({"input": "What is on the schedule today?"}, {"output": f"{schedule}"})
# 6.根据大语言模型对超过token限制的所有对话进行一个总结,保证消息的显式存储不会超过我们指定的token数量,对超过的部分,进行总结
print(memory.load_memory_variables({}))介绍memory所涉及的几个功能函数
memory.save_context({"input": "Hi"}, {"output": "What's up"}) # 自定义一次会话记录,并保存早memory中
memory.load_memory_variables({}) # 加载根据会话缓存记忆包对应的记忆变量
memory.buffer # 记忆的缓存五、核心功能Chains
1. LLM链
LLM链是最基本的一种链式结构
from langchain.chat_models import ChatOpenAI # 导入大语言模型
from langchain.prompts import ChatPromptTemplate # 导入聊天提示模板
from langchain.chains import LLMChain # 导入llm链
# 1.实例化大语言模型
llm = ChatOpenAI(temperature=0.9)
# 2. 实例化prompt
prompt = ChatPromptTemplate.from_template(
"what is the best name to describe a company that makes {product}?")
# 3.实例化llm链
chain = LLMChain(llm=llm, prompt=prompt) # 现在这个链中,仅需要填入一个{product}即可
# 4.声明product
product = "Queen Size Sheet Set" # 产品名字
# 5.运行链
response = chain.run(product)
print(response)2. Sequential Chains
按顺序运行的一系列链
(1) SimpleSequential Chains
简单顺序链:当仅有一个输入和一个输出时,简单顺序链才能很好的工作
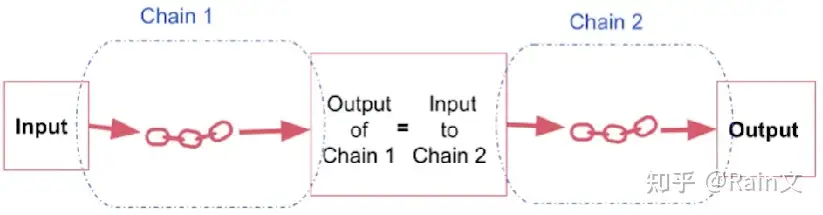
实现简单的顺序链
from langchain.chains import SimpleSequentialChain # 导入简单顺序链
from langchain.prompts import ChatPromptTemplate # 导入聊天提示模板
from langchain.chat_models import ChatOpenAI # 导入大语言模型
from langchain.chains import LLMChain # 导入llm链
# 1.实例化大语言模型
llm = ChatOpenAI(temperature=0.9)
# 2.声明两个llm链,都是有一个输入和一个输出,其中llm链1的输出正好是链2的输入
first_prompt = ChatPromptTemplate.from_template(
"对于一家生产{product}的公司,为其取一个最合适的名字")
chain_one = LLMChain(llm=llm, prompt=first_prompt)
second_prompt = ChatPromptTemplate.from_template("为{company_name}公司写一篇50字的描述")
chain_two = LLMChain(llm=llm, prompt=second_prompt)
# 3.声明简单顺序链
overall_simple_chain = SimpleSequentialChain(chains=[chain_one, chain_two], verbose=True)
# 4.设置product
product = "Queen Size Sheet Set" # 产品名字
# 4.运行链
response = overall_simple_chain.run(product)
print(response)(2) Sequential Chains
常规顺序链:当有多个输入和多个输出时,使用常规顺序链来实现。这里需要精确的指定输入键和输出键
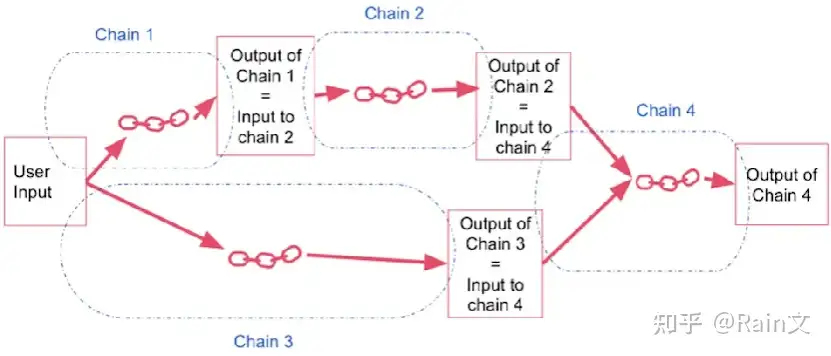
实现常规的顺序链
from langchain.chains import SequentialChain # 导入顺序链
from langchain.prompts import ChatPromptTemplate # 导入聊天提示模板
from langchain.chat_models import ChatOpenAI # 导入大语言模型
from langchain.chains import LLMChain # 导入llm链
# 1.实例化大语言模型
llm = ChatOpenAI(temperature=0.9)
# 2.声明四个llm链,注意,此时需要指定链的输出键output_key
# 2.1 链1 输入变量是Review,指定output_key="English_Review"
first_prompt = ChatPromptTemplate.from_template("将{Review}翻译为英文")
chain_one = LLMChain(llm=llm, prompt=first_prompt, output_key="English_Review")
# 2.2 链2 输入变量是English_Review,指定output_key=Summary
second_prompt = ChatPromptTemplate.from_template("一句话概括{English_Review}")
chain_two = LLMChain(llm=llm, prompt=second_prompt, output_key="Summary")
# 2.3 链3 输入变量是Review,指定output_key=Language
third_prompt = ChatPromptTemplate.from_template("判断{Review}是什么语言?")
chain_three = LLMChain(llm=llm, prompt=third_prompt, output_key="Language")
# 2.4 链4 输入变量是summary和Language,指定output_key=Followup_Message
fourth_prompt = ChatPromptTemplate.from_template(
"使用下边指定的语言类型,对下边的总结写一个后续的回应。"
"\nSummary:{Summary}\n\nLanguage:{Language}")
chain_four = LLMChain(llm=llm, prompt=fourth_prompt, output_key="Followup_Message")
# 3.实例化传统顺序链
overall_chain = SequentialChain(
chains=[chain_one, chain_two, chain_three, chain_four],
input_variables=["Review"], # 初始的输入变量
output_variables=["English_Review", "Summary", "Followup_Message"], # 中间的输出变量
verbose=True
)
# 4.设置Review
review = "我喜欢吃苹果"
# 5.运行链
response = overall_chain(review)
print(response)3.Router Chain
根据输入的内容,将其路由到不同的链中。
即存在多个子链,每个子链专门处理特定类型的输入。设置一个路由链,该链决定将输入的内容传递给哪个子链,然后由那个子链来进行处理。
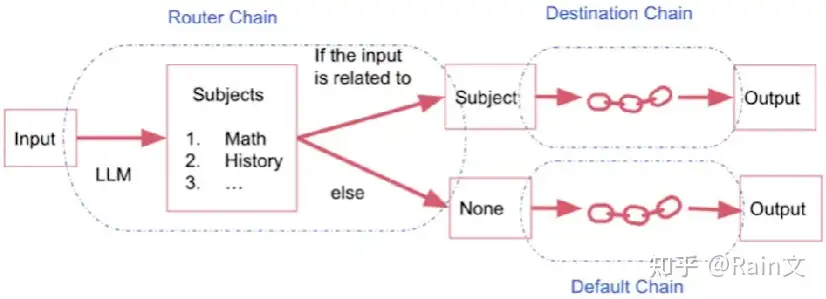
实现路由链
from langchain.chains.router import MultiPromptChain # 导入多提示链
from langchain.chains.router.llm_router import LLMRouterChain, RouterOutputParser # 导入LLM路由链,路由输出解释器
from langchain.prompts import PromptTemplate # 导入提示模板
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
# 1.声明多个template
physics_template = """你是一个聪明的物理学教授\
你很擅长用简单易懂的语言回答有关物理的问题\
当你不知道问题的答案时,你承认你不知道。
这里是问题{input}
"""
math_template = """你是一个很好的数学家。\
你很擅长回答数学问题。\
你是如此的优秀,因为你能够把难题分解成各个组成部分,并回答各个组成部分,\
然后把他们组合在一起,从而回答更广泛的问题。
这里是问题{input}
"""
history_template = """你是一个非常好的历史学家。\
你对各个时期的人物、事件以及背景都有很深入的了解。\
你有思考、反思、辩论、讨论和评价过去的能力。\
你尊重历史证据,以及利用这些证据来支持你的解释和判断能力。
这里是问题{input}
"""
computerscience_template = """你是一个成功的计算机科学家。\
你有创造力,协作精神,前瞻性思维,自信,有很强的解决问题的能力,\
对理论和算法的理解,以及出色的沟通能力。\
你很擅长回答编程问题。\
你是如此优秀,因为你知道如何通过描述一个机器可以很容易理解的命令步骤来解决问题,\
你知道如何选择一个解决方案,在时间复杂性和空间复杂性之间取得良好的平衡。
这里是问题{input}
"""
# 2.声明prompt_infos
prompt_infos = [
{
"name": "physics",
"description": "很适合回答关于物理的问题",
"prompt_template": physics_template
},
{
"name": "math",
"description": "很适合回答关于数学的问题",
"prompt_template": physics_template
},
{
"name": "physics",
"description": "很适合回答关于物理的问题",
"prompt_template": physics_template
},
{
"name": "physics",
"description": "很适合回答关于物理的问题",
"prompt_template": physics_template
}
]
# 3.实例化大语言模型
llm = ChatOpenAI(temperature=0.9)
# 4.按正常方式设置好每一条子链,和声明简单的llm链一样
destination_chains = {} # 声明字典,用来存储每个子链
for p_info in prompt_infos:
name = p_info["name"]
prompt_template = p_info["prompt_template"]
prompt = ChatPromptTemplate.from_template(template=prompt_template)
chain = LLMChain(llm=llm, prompt=prompt)
destination_chains[name] = chain # 将子链添加到字典中
destinations = [f"{p['name']}: {p['description']}" for p in prompt_infos]
destinations_str = "\n".join(destinations)
# 5.设置默认prompt和默认llm链
default_prompt = ChatPromptTemplate.from_template("{input}")
default_chain = LLMChain(llm=llm, prompt=default_prompt)
# 6.设置multi_prompt_router_template,本质上还是一个template
MULTI_PROMPT_ROUTER_TEMPLATE = """
给定语言模型的原始文本输入,选择最适合该输入的模型提示符。\
你将获得可用提示符的名称以及该提示符最适合的描述。\
如果您认为修改原始输入将最终从语言模型中获得更好的响应,那么您也可以修改原始输入。
<< FORMATTING >>
返回一个带有JSON对象的标记代码片段,格式如下:
```json
{{{{
"destination": string \ name of the prompt to use or "DEFAULT"
"next_inputs": string \ a potentially modified version of the original input
}}}}
```
REMEMBER:"destination"必须是下边指定的候选提示名之一,\
或者如果输入不适合任何候选提示,它可以是"DEFAULT".
REMEMBER:如果你认为不需要任何修改,"next_inputs"可以只是原始输入。
<< CANDIDATE PROMPTS >>
{destinations}
<< INPUT >>
{{input}}
<< OUTPUT (remember to include the ```json)>>
"""
# 7.声明路由模板router_template
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(
destinations=destinations_str
)
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser(),
)
# 8.声明路由链
router_chain = LLMRouterChain.from_llm(llm, router_prompt)
# 9.声明最终链
chain = MultiPromptChain(router_chain=router_chain,
destination_chains=destination_chains,
default_chain=default_chain, verbose=True)
# 10.运行链
response = chain.run("什么是黑体辐射")
print(response)六、基于本地文档的QA程序
给定一段文本,可能是pdf文件、网页或某个公司内部文档集合中提取出来的,可以使用LLM来回答关于这些文档内容的问题。这可以将语言模型同未经训练的数据结合起来。这可以在语言模型,提示和输出解析器之外,引入一些链环的关键组件,如嵌入模型和向量模型。
# 基于VectorstoreIndexCreator创建的Q&A over Documents
from langchain.chains import RetrievalQA # 检索问答
from langchain.chat_models import ChatOpenAI # 大语言模型
from langchain.document_loaders import CSVLoader # csv加载器
from langchain.vectorstores import DocArrayInMemorySearch # 向量存储
from IPython.display import display, Markdown # 显示工具
from langchain.indexes import VectorstoreIndexCreator # 向量存储索引创建器
# 1.讲csv文件放到文档加载器中
file = 'OutdoorClothingCatalog_1000.csv'
loader = CSVLoader(file_path=file, encoding='utf-8')
# 2.创建向量索引对象
index = VectorstoreIndexCreator(
vectorstore_cls = DocArrayInMemorySearch # 可以选择其他向量存储器
# embedding=embeddings,
).from_loaders([loader])
# 3.设置一个问题
query = """Please list all your shirts with sun protection \
in a table in markdown and summarize each one."""
# 4.讲问题放到向量索引中,得到基于文档的回答
response = index.query(query)
print(response)基于QA检索链实现基于本地文档的QA程序
from langchain.document_loaders import CSVLoader # csv加载器
from langchain.embeddings import OpenAIEmbeddings # OpenAIEmbeddings
from langchain.vectorstores import DocArrayInMemorySearch # 向量存储
from langchain.chat_models import ChatOpenAI # 大语言模型
from IPython.display import display, Markdown # 可视化工具
from langchain.chains import RetrievalQA # 检索问题回答链
"""1.为文档创建加载器->2.提取加载器中的内容到docs->3.实例化嵌入对象->4.使用embeddings和docs创建向量数据库db
->5.为db创建检索器->6.实例化大语言模型->7.创建一个检索问题回答链->8.设置问题->9.将问题传入链中->10.可视化显示
"""
# 1.使用CSVLoader加载给定的文档,从而实例化一个加载器loader
loader = CSVLoader(file_path='OutdoorClothingCatalog_1000.csv', encoding='utf-8')
# 2.提取加载器中的内容到docs,实际上这里得到一个列表
docs = loader.load()
# 3.实例化一个嵌入对象,该嵌入对象可以为特定文本创建嵌入
embeddings = OpenAIEmbeddings()
# 4.基于embeddings和docs来创建一个向量存储DocArrayInMemorySearch,将其实例化为db
db = DocArrayInMemorySearch.from_documents(docs, embeddings)
# 5.为向量存储db创建检索器
retriever = db.as_retriever()
# 6.实例化一个大语言模型
llm = ChatOpenAI(temperature=0.9)
# 7.创建一个检索问题回答链,该链首先对问题文档进行检索,然后对检索到的文档进行问题回答
qa_stuff = RetrievalQA.from_chain_type(
llm=llm, # 传入语言模型,用于最后文本生成
chain_type='stuff', # 使用stuff的链类型,该方法将所有文档放入上下文中,并对语言模型进行一次调用
retriever=retriever, # 传入检索器,用于获取文档,并将其传递给语言模型
verbose=True
)
# 8.设置一个问题
query = "Please list all your shirts with sun protection in a table \
in markdown and summarize each one."
# 9.将问题传入链中
response = qa_stuff.run(query)
# 10.可视化显示
display(Markdown(response))1.QA检索相关功能
实现为特定文本创建嵌入的功能
from langchain.embeddings import OpenAIEmbeddings
# 1.实例化一个嵌入对象,该嵌入对象可以为特定文本创建嵌入
embeddings = OpenAIEmbeddings()
# 2.使用该嵌入对象,就可以为特定的文本创建嵌入
embed = embeddings.embed_query("请问,什么是苹果")
# 输出该嵌入的详细信息
print(len(embed))
print(embed[:5])实现在向量存储中的相似搜索功能
# 1.基于embeddings和docs来创建一个向量存储DocArrayInMemorySearch,将其实例化为db
db = DocArrayInMemorySearch.from_documents(docs, embeddings)
# 2.# 设置一个问题query
query = 'Please suggest a shirt with sunblocking'
# 3.使用向量存储的相似搜索, 将相似的文本内容返回给docs
docs = db.similarity_search(query)实现基于文档上下文的llm调用
# 将qdocs直接传递给大语言模型,让其根据这个qdocs来回答
response = llm.call_as_llm(f"""{qdocs} Question: Please list all your \
shirts with sun protection in a table in markdown and summarize each one.""")几种不同的文档检索方式
# stuff method
stuff的使用方法非常简单,只需要将所有内容放入到一个提示中,发送到语言模型并获得一个响应
# Map_reduce
Map_reduce首先将所有片段连同问题一起传递给语言模型,分别对每个片段都单独得到一个回答,然后使用另
一个语言模型调用所有的单独回答汇总成最终答案。
# Refine
Refine用于循环处理多个文档,它是迭代进行的,它基于前一个文档的答案进行构建,这对于合并信息和逐步
构建答案非常有用。调用速度很慢,它依赖于前一个调用的结果。
# Map_rerank
Map_rerank首先为每个文档执行一次语言模型调用,并分别返回一个分数,然后选择最高分的回答输出。2.Embedding
- embedding可以按语义含义为文本创建数值表示,即可以将这些文本片段放入到向量空间表示,即相似的文本片段将具有相似的向量。
3.Vector Database
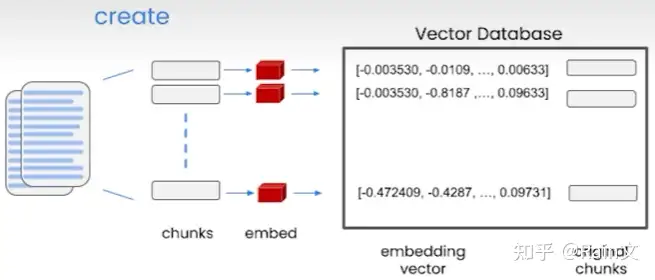
- 向量数据库可以存储使用Embedding创建的向量。
- 创建向量数据库的方式:1.将大的输入文档分解成较小的块。2.为每个块创建embedding,并将其存储在向量数据库中。
- 创建完向量数据库,我们就有了index
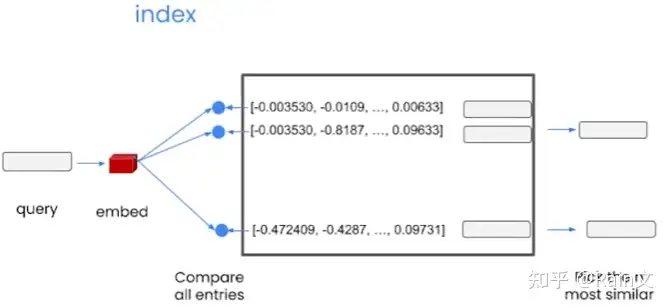
- 索引向量数据库的方式:1.为我们的查询创建一个嵌入。2.将其与向量数据库的所有向量进行比较,并选择最相似的前n个。3.将这n个结果返回,可以将其作为提示词传递给语言模型。4.获得最终答案。
七、模型评估
使用语言模型本身和链式本身来评估其他语言模型、其他链式和其他应用程序。用语言模型评估完美的解决了正则表达式等不能正确匹配的问题,因为语言模型比较的是语义的相关性。
# 基于文档创建一个QA链
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import CSVLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain.vectorstores import DocArrayInMemorySearch
# 1.加载csv文档
file = 'OutdoorClothingCatalog_1000.csv'
loader = CSVLoader(file_path=file, encoding='utf-8')
data = loader.load()
# 2.创建基于DocArrayInMemorySearch向量存储方式的索引
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch
).from_loaders([loader])
# 3.实例化大语言模型
llm = ChatOpenAI(temperature=0.9)
# 4.创建qa链
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type='stuff',
retriever=index.vectorstore.as_retriever(),
verbose=True,
chain_type_kwargs={
"document_separator": "<<<<>>>>>"
}
)第一种方法:手动创建一组好的数据示例 (query-answer)
# 第一种方法,我们自己提出一组好的数据点,即提供示例正确的答案,以便之后用于评估
examples = [
{
"query": "Do the Cozy Comfort Pullover Set\
have side pockets?",
"answer": "Yes"
},
{
"query": "What collection is the Ultra-Lofty \
850 Stretch Down Hooded Jacket from?",
"answer": "The DownTek collection"
}
]第二种方法:使用QA生成链实现自动化创建数据示例(query-answer)
# 第二种方法,使用qa生成链,自动化生成示例:查询-答案对
from langchain.evaluation.qa import QAGenerateChain # qa生成链
from langchain.document_loaders import CSVLoader
from langchain.chat_models import ChatOpenAI
# 1.加载csv文档
file = 'OutdoorClothingCatalog_1000.csv'
loader = CSVLoader(file_path=file, encoding='utf-8')
data = loader.load()
# 2.实例化qa生成链,该链可以接收文档,并从每个文档中创建一个问题答案对,它使用语言模型本身来完成这个过程
example_gen_chain = QAGenerateChain.from_llm(ChatOpenAI())
new_examples = example_gen_chain.apply_and_parse([{"doc": t} for t in data[:5]])
print(new_examples[0])一个完整的llm应用正确性评估程序
# 完整的llm应用正确性评估程序
from langchain.chat_models import ChatOpenAI # 大语言模型
from langchain.document_loaders import CSVLoader # csv文档加载器
from langchain.indexes import VectorstoreIndexCreator # 向量存储索引创建器
from langchain.vectorstores import DocArrayInMemorySearch # 向量存储
from langchain.chains import RetrievalQA # qa检索链
from langchain.evaluation.qa import QAGenerateChain # qa生成链
from langchain.evaluation.qa import QAEvalChain # qa评估链
"""第一部分: 构建一个qa检索链"""
# 1.加载csv文档
file = 'OutdoorClothingCatalog_1000.csv'
loader = CSVLoader(file_path=file, encoding='utf-8')
data = loader.load()
# 2.创建基于DocArrayInMemorySearch向量存储方式的索引
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch
).from_loaders([loader])
# 3.实例化大语言模型
llm = ChatOpenAI(temperature=0.9)
# 4.创建qa检索链,这里就可以基于文档进行问答了
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type='stuff',
retriever=index.vectorstore.as_retriever(),
verbose=True,
chain_type_kwargs={
"document_separator": "<<<<>>>>>"
}
)
"""第二部分: 构建示例 查询-答案对"""
# 5.提供示例:查询-答案对
examples = [
{
"query": "Do the Cozy Comfort Pullover Set have side pockets?",
"answer": "Yes"
},
{
"query": "What collection is the Ultra-Lofty 850 Stretch Down Hooded Jacket from?",
"answer": "The DownTek collection"
}
]
# 6.实例化一个qa生成链,该链可以接收文档,并从每个文档中创建一个问题-答案对,它使用语言模型本身来完成这个过程
example_gen_chain = QAGenerateChain.from_llm(ChatOpenAI())
new_examples = example_gen_chain.apply([{"doc": t} for t in data[:5]]) # apply和apply_and_parse在这里的效果是一样的
# new_examples = example_gen_chain.apply_and_parse([{"doc": t} for t in data[:5]])
new_examples = [new_examples[i]['qa_pairs'] for i in range(len(new_examples))]
# 7.将我们自己的示例和qa生成链得到的示例结合起来
examples += new_examples
"""第三部分: 应用qa检索链来对示例的所有查询进行预测"""
# 8.为所有不同示例创建预测,即应用qa检索链得到所有实例中查询的预测答案
predictions = qa.apply(examples)
"""第四部分: 对预测值和真实值之间进行正确性评估"""
# 10.实例化qa评估链
eval_chain = QAEvalChain.from_llm(llm)
# 11.对模型进行评估
graded_outputs = eval_chain.evaluate(examples, predictions)
"""第五部分: 可视化评估结果"""
# 12.可视化评估结果
for i, eg in enumerate(examples):
print("Example {}".format(i))
print("Question: " + predictions[i]['query'])
print("Real Answer: " + predictions[i]['answer'])
print("Predicted Answer: " + predictions[i]['result'])
print()一些功能函数的含义
apply_and_parse:会对结果应用一个输出解析器,从而得到一个包含查询和答案的字典,而不仅仅是字符串
langchain.debug=True:链条调试工具
qa.run(query):运行qa检索链,得到查询query的答案
qa.apply(examples):运行qa检索链,得到所有实例的预测答案八、核心功能Agents
将大语言模型视作一个推理引擎。使用语言模型作为Agents的推理引擎,它将连接到其他数据源和计算资源。
# 用于llm-math和wikipedia的代理
from langchain.agents import load_tools, initialize_agent
from langchain.agents import AgentType
from langchain.chat_models import ChatOpenAI
# 1.实例化一个大语言模型
llm = ChatOpenAI(temperature=0.0)
# 2.选择语言模型要接入的工具
tools = load_tools(["llm-math", "wikipedia"], llm=llm)
# 3.使用tools,llm,代理类型来初始化agent
agent = initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION,
handle_parsing_errors=True,
verbose=True
)
# 4.使用代理来解决我们提出的数学问题
result = agent("计算99的5次方模12的结果.")
print(result)
# 5.使用代理来解决我们提出的关于维基百科上的问题
question = """Tom M. Mitchell is an American computer scientist \
and the Founders University Professor at Carnegie Mellon University (CMU)\
what book did he write?"""
result = agent(question)
print(result)python代理:实现大语言模型和python代码的交互
# python-agent
from langchain.agents.agent_toolkits import create_python_agent
from langchain.tools.python.tool import PythonREPLTool
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
# 1.实例化一个大语言模型
llm = ChatOpenAI(temperature=0.0)
# 2.创建一个python代理,传入大语言模型,PythonREPL工具
agent = create_python_agent(
llm=llm,
tool=PythonREPLTool(),
verbose=True
)
# 3.设置想要解决的问题,这里是想要实现一个对人名排序的问题,并生成该message
customer_list = [["Harrison", "Chase"],
["Lang", "Chain"],
["Dolly", "Too"],
["Elle", "Elem"],
["Geoff", "Fusion"],
["Trance", "Former"],
["Jen", "Ayai"]]
template = """按姓氏和名字对这些客户排序,然后打印输出:{customer_list}"""
prompt = ChatPromptTemplate.from_template(template)
message = prompt.format_messages(customer_list=customer_list)
# 4.将message传给代理,得到代理的回答
result = agent.run(message)
print(result)创建自定义的工具,使得agents可以连接到我们想要的任何内容
# 创建自定义工具,以便可以将agents连接到我们想要的任何内容
from langchain.agents import tool # 导入工具修饰符,它可以应用于任何函数,并将其转换为链式连接可以使用的工具
from datetime import date
from langchain.agents import initialize_agent
from langchain.chat_models import ChatOpenAI
from langchain.agents import AgentType
from langchain.agents import load_tools
# 1. 首先使用langchain.agents中的tool工具修饰符,来修饰一个我们自定义的函数
@tool
def time(text: str) -> str: # 除了函数的名称外,还应该编写一个详细的文档说明,以便代理知道何时何地使用这个函数
"""返回今天的日期,用于任何与查询今天日期有关的问题.输入应该始终是一个空字符串,
并且这个函数将始终返回今天的日期---任何日期计算都应该在这个函数之外进行."""
return str(date.today())
# 2.实例化大语言模型
llm = ChatOpenAI(temperature=0.0)
# 3.声明工具tools
tools = load_tools(['llm-math'], llm=llm)
# 4.使用tools,llm,AgentType来初始化代理,注意在tools上加上我们自定义的工具
agent = initialize_agent(
tools=tools + [time],
llm=llm,
agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION,
handle_parsing_errors=True,
verbose=True
)
# 5.运行代理
result = agent("whats the date today?")
print(result)关于agents的一些功能函数
# 一些功能函数
llm-math工具:是一个链,它使用语言模型和计算器来解决数学问题
wikipedia工具:是一个可以连接到维基百科的API,允许用户对维基百科进行搜索并返回查询结果
handle_parsing_errors=True:当语言模型输出为无法解析的输出内容时,它会将格式错误的文本传递回语言模型,并要求它进行更正
verbose=True:打印详细信息,以便我们知道当前发生了什么
PythonREPL:是一种可以与用户进行交互的工具,代理可以使用这个工具执行代码,然后将得到的结果,回传给代理,以便它决定接下来该做什么九、Agent+Tools+Chains+Chroma
1.chromadb的创建和加载
(1) 直接调用chromadb库文件
import chromadb
from chromadb.utils.embedding_functions import SentenceTransformerEmbeddingFunction
from chromadb.config import Settings
# 1.创建客户端
client = chromadb.Client(Settings(
persist_directory='../save/to/'
))
# 2.创建嵌入
embedding = SentenceTransformerEmbeddingFunction(model_name='all-MiniLM-L6-v2')
# 3.创建集合
collection = client.create_collection(name='collection', embedding_function=embedding)
# 4.添加元素
doc1 = "白雪公主和七个小矮人的故事"
doc2 = "三国演义诸葛亮和司马懿的故事"
doc3 = "红楼梦中贾宝玉和林黛玉的故事"
doc4 = "皇帝的新装"
collection.add(
ids=["1", "2", "3", "4"],
documents=[doc1, doc2, doc3, doc4],
metadatas=[{"source": "一千零一夜"}, {"source": "三国演义"}, {"source": "红楼梦"}, {"source": "安徒生童话"}],
)
result = collection.get()
print(result)
# 5.更新元素
doc5 = "西游记孙悟空和哪吒的故事"
collection.update(
ids=["1"],
documents=[doc5],
metadatas=[{"source": "西游记"}]
)
result = collection.get()
print(result)
# 6.更新已存在元素,或不存在时插入元素
doc6 = "水浒传中武松和林冲的故事"
collection.upsert(
ids=["3", "6"],
documents=[doc1, doc6],
metadatas=[{"source": "一千零一夜"}, {"source": "水浒传"}]
)
result = collection.get()
print(result)
# 7.删除元素
collection.delete(
ids=["4"],
where={"source": "安徒生童话"}
)
result = collection.get()
print(result)
# 8.查询chroma中的数据
results = collection.query(
query_texts=["三国演义"],
n_results=1
)
print(results)(2) 在langchain框架中创建chromadb
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.document_loaders import CSVLoader
# 1.加载文档
loader = CSVLoader(file_path='../docs/csv/product.csv', encoding='utf-8')
data = loader.load()
# 2.创建嵌入
embedding = OpenAIEmbeddings()
# 3.在指定位置创建矢量数据库
vector_db = Chroma.from_documents(
documents=data,
collection_name='Product',
embedding=embedding,
persist_directory="../save/product",
)
print(vector_db._collection.count())
# 4.加载已有的矢量数据库,注意创建的时候指定的参数,加载时也要指定才行
load_vectordb = Chroma(
collection_name='Product',
persist_directory="../save/product/",
embedding_function=embedding
)
# 4.数据库相关操作
print(load_vectordb._collection.count())
result = load_vectordb.similarity_search('你的query')
print(result)2.Chains
(1) LLMChain的声明
from langchain.chains import LLMChain
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
# 1.实例化大语言模型
llm = ChatOpenAI(temperature=0.7)
# 2.实例化prompt
template = """
你将获得一些英文文本,你需要去判断,并且将相对应的问题关联起来。
{format_instructions}
{input}
"""
prompt = PromptTemplate(
input_variables=["input", "format_instructions"],
template=template
)
# 3.定义链
llmchain = LLMChain(llm=llm, prompt=prompt, verbose=True)
# 4.使用链
format_instructions = ''
input = ''
response = llmchain.run({"format_instructions": format_instructions, "input": input})
print(response)(2)RetrievalQA
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
# 1.实例化大语言模型
llm = ChatOpenAI(temperature=0.7)
# 2.创建嵌入
embedding = OpenAIEmbeddings()
# 3.加载矢量数据库
VectorDB = Chroma(persist_directory='../save/to/', embedding_function=embedding)
# 4.创建检索
retriever = VectorDB.as_retriever()
# 创建QA链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type='stuff',
retriever=retriever,
verbose=True
)
# 使用QA链
response = qa_chain.run('用户的问题')
print(response)3.Tool
(1) 通过类来声明工具
from langchain.tools import BaseTool
from typing import Union
class ServerTool(BaseTool):
name = "Server"
description = """当我让你推荐服务时,使用这个工具
"""
return_direct = True # 仅返回调用这个工具得到的结果
def _run(self, query: Union[str]) -> str:
"""
这里输入自己的代码块,程序会依次执行
:param query: llm重新理解后的问题
:return: 返回
"""
print("ServerTool query: " + query)
response = "这里是代码块运行后得到的结果"
return response
async def _arun(self, query: Union[str]) -> str:
raise NotImplementedError("暂时不支持异步")(2) 调用已有工具
from langchain.agents import load_tools
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0.7)
tools = load_tools(["llm-math"], llm=llm)(3) 调用工具修饰符
from langchain.agents import tool
from langchain.agents import Tool
def search_order(input: str) -> str:
return "订单状态:已发货;发货日期:2023-01-01;预计送达时间:2023-01-10"
def recommend_product(input: str) -> str:
return "iPhone 15 Pro"
@tool
def faq(intput: str) -> str:
return "7天无理由退货"
tools = [
Tool(
name="Search Order",
func=search_order,
description="useful for when you need to answer questions about customers orders"
),
Tool(name="Recommend Product",
func=recommend_product,
description="useful for when you need to answer questions about product recommendations"
),
faq
]4.Agent
Agent使用llm决定什么时候采取什么样的action,以及以什么样的顺序去采用这些action。
from langchain.agents import initialize_agent
from langchain.chat_models import ChatOpenAI
from langchain.chains.conversation.memory import ConversationBufferMemory
from ChatTools import ServerRecommendTool, PetConsultationTool, GenerateNameTool, BehaviorInterpretationTool
from langchain.agents import AgentType
# 1.导入记忆机制
memory = ConversationBufferMemory(memory_key='chat_history', return_messages=True)
# 2.导入大语言模型
llm = ChatOpenAI(temperature=0.0)
# 3.加载工具列表
tools = [ServerRecommendTool(), PetConsultationTool(), GenerateNameTool(), BehaviorInterpretationTool()]
# 4.创建agent
agent = initialize_agent(
agent=AgentType.CHAT_CONVERSATIONAL_REACT_DESCRIPTION, # 不同的agent类型
tools=tools,
llm=llm,
verbose=True,
max_iterations=3, # 查找答案的最高次数
early_stopping_method='generate',
memory=memory
)
# 5.agent的使用
message = input(">>")
try:
response = agent.run(message)
except ValueError as e:
response = '不好意思,请询问我xxxx相关的问题'
print(response)以上就是我学习langchain的一点学习笔记,侵权必删!


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Deepseek官网太卡,教你白嫖阿里云的Deepseek-R1满血版
· 2分钟学会 DeepSeek API,竟然比官方更好用!
· .NET 使用 DeepSeek R1 开发智能 AI 客户端
· DeepSeek本地性能调优
· 一文掌握DeepSeek本地部署+Page Assist浏览器插件+C#接口调用+局域网访问!全攻略
2019-04-18 自然语言处理