基于情感词典的文本情感分析 (snownlp)
目前情感分析在中文自然语言处理中比较火热,很多场景下,我们都需要用到情感分析。比如,做金融产品量化交易,需要根据爬取的舆论数据来分析政策和舆论对股市或者基金期货的态度;电商交易,根据买家的评论数据,来分析商品的预售率等等。
下面我们通过以下几点来介绍中文自然语言处理情感分析:
- 中文情感分析方法简介;
- SnowNLP 快速进行评论数据情感分析;
- 基于标注好的情感词典来计算情感值;
- pytreebank 绘制情感树;
- 股吧数据情感分类。
中文情感分析方法简介
情感倾向可认为是主体对某一客体主观存在的内心喜恶,内在评价的一种倾向。它由两个方面来衡量:一个情感倾向方向,一个是情感倾向度。
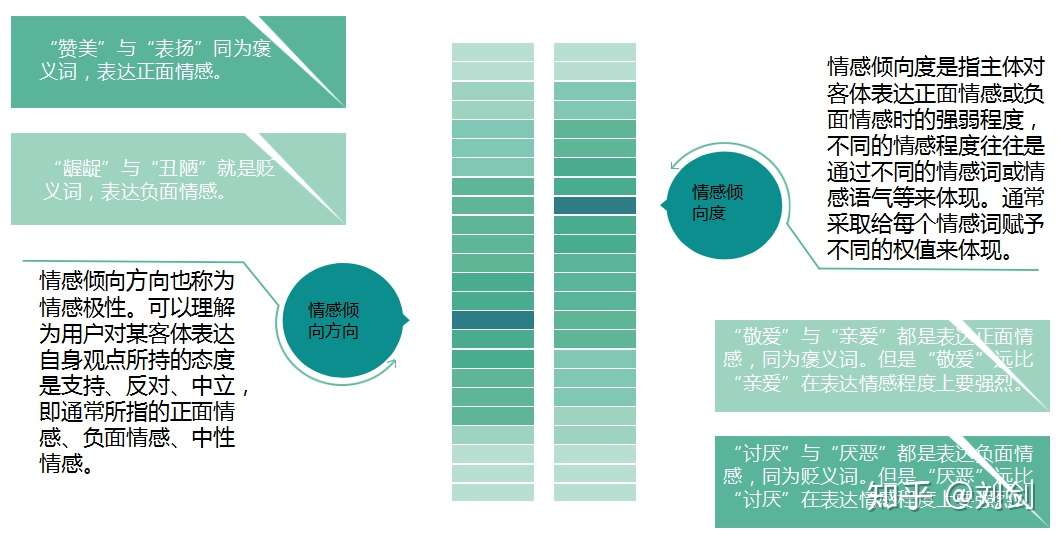
目前,情感倾向分析的方法主要分为两类:一种是基于情感词典的方法;一种是基于机器学习的方法,如基于大规模语料库的机器学习。前者需要用到标注好的情感词典;后者则需要大量的人工标注的语料作为训练集,通过提取文本特征,构建分类器来实现情感的分类。
文本情感分析的分析粒度可以是词语、句子、段落或篇章。
段落篇章级情感分析主要是针对某个主题或事件进行情感倾向判断,一般需要构建对应事件的情感词典,如电影评论的分析,需要构建电影行业自己的情感词典,这样效果会比通用情感词典更好;也可以通过人工标注大量电影评论来构建分类器。句子级的情感分析大多通过计算句子里包含的所有情感词的值来得到。
篇章级的情感分析,也可以通过聚合篇章中所有的句子的情感倾向来计算得出。因此,针对句子级的情感倾向分析,既能解决短文本的情感分析,同时也是篇章级文本情感分析的基础。
中文情感分析的一些难点,比如句子是由词语根据一定的语言规则构成的,应该把句子中词语的依存关系纳入到句子情感的计算过程中去,不同的依存关系,进行情感倾向计算是不一样的。文档的情感,根据句子对文档的重要程度赋予不同权重,调整其对文档情感的贡献程度等。
SnowNLP 快速进行评论数据情感分析
如果有人问,有没有比较快速简单的方法能判断一句话的情感倾向,那么 SnowNLP 库就是答案。
SnowNLP 主要可以进行中文分词、词性标注、情感分析、文本分类、转换拼音、繁体转简体、提取文本关键词、提取摘要、分割句子、文本相似等。
需要注意的是,用 SnowNLP 进行情感分析,官网指出进行电商评论的准确率较高,其实是因为它的语料库主要是电商评论数据,但是可以自己构建相关领域语料库,替换单一的电商评论语料,准确率也挺不错的。
1. SnowNLP 安装。
(1) 使用 pip 安装:
pip install snownlp==0.11.1(2)使用 Github 源码安装。
首先,下载 SnowNLP 的 Github 源码并解压,在解压目录,通过下面命令安装:
python setup.py install以上方式,二选一安装完成之后,就可以引入 SnowNLP 库使用了。
from snownlp import SnowNLP(1) 测试一条京东的好评数据:
SnowNLP(u'本本已收到,体验还是很好,功能方面我不了解,只看外观还是很不错很薄,很轻,也有质感。').sentiments得到的情感值很高,说明买家对商品比较认可,情感值为:
0.999950702449061 (2)测试一条京东的中评数据:
SnowNLP(u'屏幕分辨率一般,送了个极丑的鼠标。').sentiments 得到的情感值一般,说明买家对商品看法一般,甚至不喜欢,情感值为:
0.03251402883400323 (3)测试一条京东的差评数据:
SnowNLP(u'很差的一次购物体验,细节做得极差了,还有发热有点严重啊,散热不行,用起来就是烫得厉害,很垃圾!!!').sentiments 得到的情感值一般,说明买家对商品不认可,存在退货嫌疑,情感值为:
0.0036849517156107847 以上就完成了简单快速的情感值计算,对评论数据是不是很好用呀!!!
使用 SnowNLP 来计算情感值,官方推荐的是电商评论数据计算准确度比较高,难道非评论数据就不能使用 SnowNLP 来计算情感值了吗?当然不是,虽然 SnowNLP 默认提供的模型是用评论数据训练的,但是它还支持我们根据现有数据训练自己的模型。
首先我们来看看自定义训练模型的源码 Sentiment 类,代码定义如下:
class Sentiment(object):
def __init__(self):
self.classifier = Bayes()
def save(self, fname, iszip=True):
self.classifier.save(fname, iszip)
def load(self, fname=data_path, iszip=True):
self.classifier.load(fname, iszip)
def handle(self, doc):
words = seg.seg(doc)
words = normal.filter_stop(words)
return words
def train(self, neg_docs, pos_docs):
data = []
for sent in neg_docs:
data.append([self.handle(sent), 'neg'])
for sent in pos_docs:
data.append([self.handle(sent), 'pos'])
self.classifier.train(data)
def classify(self, sent):
ret, prob = self.classifier.classify(self.handle(sent))
if ret == 'pos':
return prob
return 1-prob通过源代码,我们可以看到,可以使用 train方法训练数据,并使用 save 方法和 load 方法保存与加载模型。下面训练自己的模型,训练集 pos.txt 和 neg.txt 分别表示积极和消极情感语句,两个 TXT 文本中每行表示一句语料。
下面代码进行自定义模型训练和保存:
from snownlp import sentiment
sentiment.train('neg.txt', 'pos.txt')
sentiment.save('sentiment.marshal')基于标注好的情感词典来计算情感值
这里我们使用一个行业标准的情感词典——玻森情感词典,来自定义计算一句话、或者一段文字的情感值。
整个过程如下:
加载玻森情感词典; jieba 分词; 获取句子得分。 首先引入包:
import pandas as pd
import jieba接下来加载情感词典:
df = pd.read_table("bosonnlp//BosonNLP_sentiment_score.txt",sep= " ",names=['key','score'])查看一下情感词典前5行:
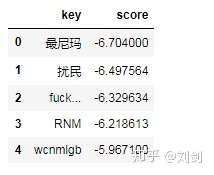
将词 key 和对应得分 score 转成2个 list 列表,目的是找到词 key 的时候,能对应获取到 score 值:
key = df['key'].values.tolist()
score = df['score'].values.tolist()定义分词和统计得分函数:
def getscore(line):
segs = jieba.lcut(line) #分词
score_list = [score[key.index(x)] for x in segs if(x in key)]
return sum(score_list) #计算得分最后来进行结果测试:
line = "今天天气很好,我很开心"
print(round(getscore(line),2))
line = "今天下雨,心情也受到影响。"
print(round(getscore(line),2))获得的情感得分保留2位小数:
5.26
-0.96
pytreebank 绘制情感树
1. 安装 pytreebank。
在 Github 上下载 pytreebank 源码,解压之后,进入解压目录命令行,执行命令:
python setup.py install最后通过引入命令,判断是否安装成功:
import pytreebank提示,如果在 Windows 下安装之后,报错误:
UnicodeDecodeError: 'gbk' codec can't decode byte 0x92 in position 24783: illegal multibyte sequence这是由于编码问题引起的,可以在安装目录下报错的文件中报错的代码地方加个 encoding='utf-8' 编码:
import_tag( "script", contents=format_replacements(open(scriptname,encoding='utf-8').read(), replacements), type="text/javascript" )- 绘制情感树。
首先引入 pytreebank 包:
import pytreebank然后,加载用来可视化的 JavaScript 和 CSS 脚本:
pytreebank.LabeledTree.inject_visualization_javascript()绘制情感树,把句子首先进行组合再绘制图形:
line = '(4 (0 你) (3 (2 是) (3 (3 (3 谁) (2 的)) (2 谁))))'
pytreebank.create_tree_from_string(line).display()得到的情感树如下:
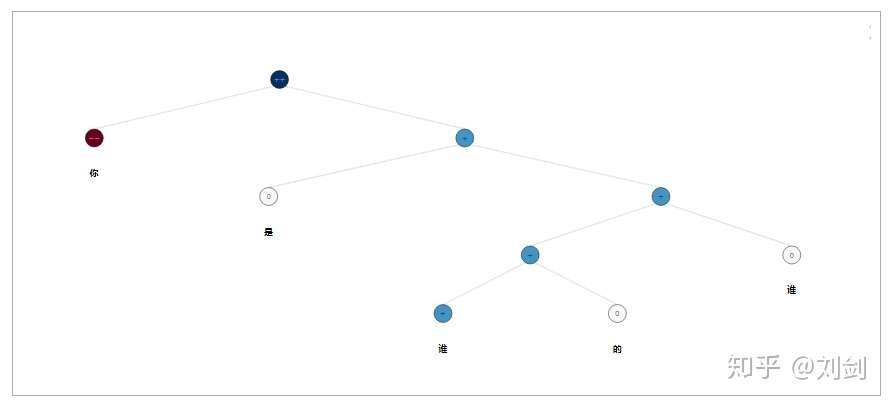
股吧数据情感分类
历经89天的煎熬之后,7月15日中兴终于盼来了解禁,在此首先恭喜中兴,解禁了,希望再踏征程。
但在7月15日之前,随着中美贸易战不断升级,中兴股价又上演了一场“跌跌不休”的惨状,我以中美贸易战背景下中兴通讯在股吧解禁前一段时间的评论数据,来进行情感数据人工打标签和分类。其中,把消极 、中性 、积极分别用0、1、2来表示。
整个文本分类流程主要包括以下6个步骤:
- 中文语料;
- 分词;
- 复杂规则;
- 特征向量;
- 算法建模;
- 情感分析。

本次分类算法采用 CNN,首先引入需要的包:
import pandas as pd
import numpy as np
import jieba
import random
import keras
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.layers import Embedding
from keras.layers import Conv1D, GlobalMaxPooling1D
from keras.datasets import imdb
from keras.models import model_from_json
from keras.utils import np_utils
import matplotlib.pyplot as plt继续引入停用词和语料文件:
dir = "D://ProgramData//PythonWorkSpace//chat//chat8//"
stopwords=pd.read_csv(dir +"stopwords.txt",index_col=False,quoting=3,sep="\t",names=['stopword'], encoding='utf-8')
stopwords=stopwords['stopword'].values
df_data1 = pd.read_csv(dir+"data1.csv",encoding='utf-8')
df_data1.head()下图展示数据的前5行:

接着进行数据预处理,把消极、中性、积极分别为0、1、2的预料分别拿出来:
#把内容有缺失值的删除
df_data1.dropna(inplace=True)
#抽取文本数据和标签
data_1 = df_data1.loc[:,['content','label']]
#把消极 中性 积极分别为0、1、2的预料分别拿出来
data_label_0 = data_1.loc[data_1['label'] ==0,:]
data_label_1 = data_1.loc[data_1['label'] ==1,:]
data_label_2 = data_1.loc[data_1['label'] ==2,:]接下来,定义中文分词函数:
#定义分词函数
def preprocess_text(content_lines, sentences, category):
for line in content_lines:
try:
segs=jieba.lcut(line)
segs = filter(lambda x:len(x)>1, segs)
segs = [v for v in segs if not str(v).isdigit()]#去数字
segs = list(filter(lambda x:x.strip(), segs)) #去左右空格
segs = filter(lambda x:x not in stopwords, segs)
temp = " ".join(segs)
if(len(temp)>1):
sentences.append((temp, category))
except Exception:
print(line)
continue生成训练的分词数据,并进行打散,使其分布均匀:
#获取数据
data_label_0_content = data_label_0['content'].values.tolist()
data_label_1_content = data_label_1['content'].values.tolist()
data_label_2_content = data_label_2['content'].values.tolist()
#生成训练数据
sentences = []
preprocess_text(data_label_0_content, sentences, 0)
preprocess_text(data_label_1_content, sentences, 1)
preprocess_text(data_label_2_content, sentences,2)
#我们打乱一下顺序,生成更可靠的训练集
random.shuffle(sentences)对数据集进行切分,按照训练集合测试集7:3的比例:
#所以把原数据集分成训练集的测试集,咱们用sklearn自带的分割函数。
from sklearn.model_selection import train_test_split
x, y = zip(*sentences)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3,random_state=1234)#所以把原数据集分成训练集的测试集,咱们用sklearn自带的分割函数。
from sklearn.model_selection import train_test_split
x, y = zip(*sentences)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3,random_state=1234)然后,对特征构造词向量:
#抽取特征,我们对文本抽取词袋模型特征
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer(
analyzer='word', #tokenise by character ngrams
max_features=4000, #keep the most common 1000 ngrams
)
vec.fit(x_train)定义模型参数:
# 设置参数
max_features = 5001
maxlen = 100
batch_size = 32
embedding_dims = 50
filters = 250
kernel_size = 3
hidden_dims = 250
epochs = 10
nclasses = 3输入特征转成 Array 和标签处理,打印训练集和测试集的 shape:
x_train = vec.transform(x_train)
x_test = vec.transform(x_test)
x_train = x_train.toarray()
x_test = x_test.toarray()
y_train = np_utils.to_categorical(y_train,nclasses)
y_test = np_utils.to_categorical(y_test,nclasses)
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)定义一个绘制 Loss 曲线的类:
class LossHistory(keras.callbacks.Callback):
def on_train_begin(self, logs={}):
self.losses = {'batch':[], 'epoch':[]}
self.accuracy = {'batch':[], 'epoch':[]}
self.val_loss = {'batch':[], 'epoch':[]}
self.val_acc = {'batch':[], 'epoch':[]}
def on_batch_end(self, batch, logs={}):
self.losses['batch'].append(logs.get('loss'))
self.accuracy['batch'].append(logs.get('acc'))
self.val_loss['batch'].append(logs.get('val_loss'))
self.val_acc['batch'].append(logs.get('val_acc'))
def on_epoch_end(self, batch, logs={}):
self.losses['epoch'].append(logs.get('loss'))
self.accuracy['epoch'].append(logs.get('acc'))
self.val_loss['epoch'].append(logs.get('val_loss'))
self.val_acc['epoch'].append(logs.get('val_acc'))
def loss_plot(self, loss_type):
iters = range(len(self.losses[loss_type]))
plt.figure()
# acc
plt.plot(iters, self.accuracy[loss_type], 'r', label='train acc')
# loss
plt.plot(iters, self.losses[loss_type], 'g', label='train loss')
if loss_type == 'epoch':
# val_acc
plt.plot(iters, self.val_acc[loss_type], 'b', label='val acc')
# val_loss
plt.plot(iters, self.val_loss[loss_type], 'k', label='val loss')
plt.grid(True)
plt.xlabel(loss_type)
plt.ylabel('acc-loss')
plt.legend(loc="upper right")
plt.show()然后,初始化上面类的对象,并作为模型的回调函数输入,训练模型:
history = LossHistory()
print('Build model...')
model = Sequential()
model.add(Embedding(max_features,
embedding_dims,
input_length=maxlen))
model.add(Dropout(0.5))
model.add(Conv1D(filters,
kernel_size,
padding='valid',
activation='relu',
strides=1))
model.add(GlobalMaxPooling1D())
model.add(Dense(hidden_dims))
model.add(Dropout(0.5))
model.add(Activation('relu'))
model.add(Dense(nclasses))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test),callbacks=[history])得到的模型迭代次数为10轮的训练过程:

最后绘制 Loss 图像:
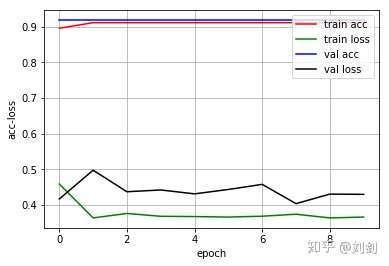
关于本次分类,这里重点讨论的一个知识点就是数据分布不均匀的情况,我们都知道,本次贸易战中兴公司受影响很大,导致整个股票价格处于下跌趋势,所以整个舆论上,大多数评论都是消极的态度,导致数据分布极不均匀。
那数据分布不均匀一般怎么处理呢?从以下几个方面考虑:
- 数据采样,包括上采样、下采样和综合采样;
- 改变分类算法,在传统分类算法的基础上对不同类别采取不同的加权方式,使得模型更看重少数类;
- 采用合理的性能评价指标;
- 代价敏感。
总结,本文通过第三方、基于词典等方式计算中文文本情感值,以及通过情感树来进行可视化,然而这些内容只是情感分析的入门知识,情感分析还涉及句法依存等,最后通过一个 CNN 分类模型,提供一种有监督的情感分类思路。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号