k8s遇到的坑
换源之后出现数字签名错误
W: GPG 错误:https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial InRelease: 由于没有公钥,无法验证下列签名: NO_PUBKEY B53DC80D13EDEF05
E: 仓库 “https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial InRelease” 没有数字签名。
N: 无法安全地用该源进行更新,所以默认禁用该源。
N: 参见 apt-secure(8) 手册以了解仓库创建和用户配置方面的细节。
使用apt-key adv --keyserver keyserver.ubuntu.com --recv-keys B53DC80D13EDEF05失败
解决办法:apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys B53DC80D13EDEF05

{
"registry-mirrors": ["https://mk1a3ruz.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
使用cri-dockerd
https://github.com/Mirantis/cri-dockerd/tags
下载最新的cri-dockerd,注意要选择跟cpu内核匹配的版本
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.20.113:6443 --token wen4ff.7d0ugqdkw5w8ionz \
--discovery-token-ca-cert-hash sha256:65141e1664c9a50071645af71bb01230702cb36dd2b3312dcea6c69238477528
root@lxt-master:~# cd /usr/lib/systemd/system
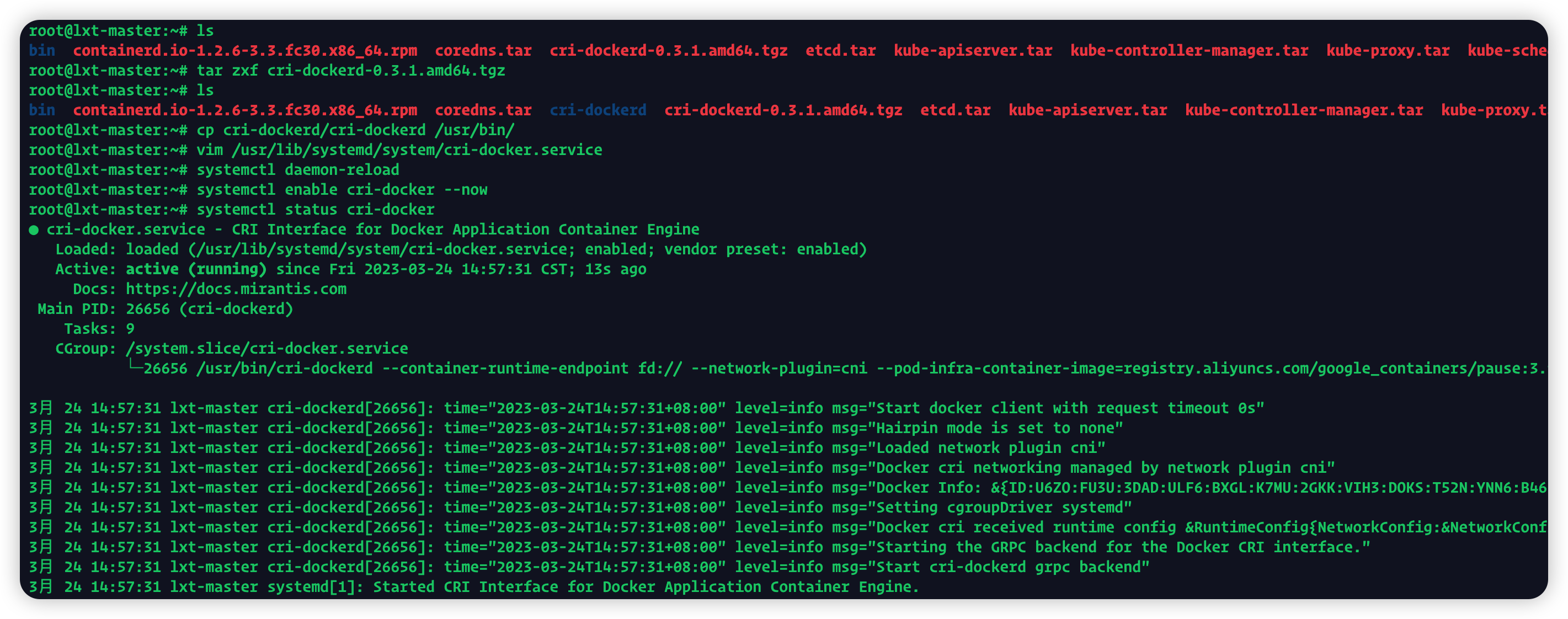
root@lxt-master:~# cp cri-dockerd/cri-dockerd /usr/bin/
root@lxt-master:~# vim /usr/lib/systemd/system/cri-docker.service
root@lxt-master:~# systemctl daemon-reload
root@lxt-master:~# systemctl enable cri-docker --now
root@lxt-master:~# systemctl status cri-docker
Cri-dockerd需要配置两个文件
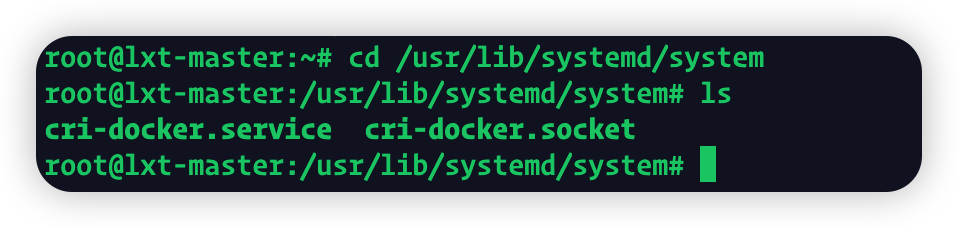
如果没有system文件夹,新建一个就行了
这两个文件也需要手动创建
Cri-dockerd.service
[Unit]
Description=CRI Interface for Docker Application Container Engine
Documentation=https://docs.mirantis.com
After=network-online.target firewalld.service docker.service
Wants=network-online.target
Requires=cri-docker.socket
[Service]
Type=notify
ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
# Note that StartLimit* options were moved from "Service" to "Unit" in systemd 229.
# Both the old, and new location are accepted by systemd 229 and up, so using the old location
# to make them work for either version of systemd.
StartLimitBurst=3
# Note that StartLimitInterval was renamed to StartLimitIntervalSec in systemd 230.
# Both the old, and new name are accepted by systemd 230 and up, so using the old name to make
# this option work for either version of systemd.
StartLimitInterval=60s
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
# Comment TasksMax if your systemd version does not support it.
# Only systemd 226 and above support this option.
TasksMax=infinity
Delegate=yes
KillMode=process
[Install]
WantedBy=multi-user.target
~
Cri-dockerd.socket
[Unit]
Description=CRI Docker Socket for the API
PartOf=cri-docker.service
[Socket]
ListenStream=%t/cri-dockerd.sock
SocketMode=0660
SocketUser=root
SocketGroup=docker
[Install]
WantedBy=sockets.target
配置完成后重新加载并设置为开机启动
systemctl daemon-reload ; systemctl enable cri-docker --now
Kubeadm init启动时添加指定cri-dockerd的参数
kubeadm init --apiserver-advertise-address=192.168.20.126 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.26.3 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16 --ignore-preflight-errors=all --cri-socket /var/run/cri-dockerd.sock
这个操作在node上也要做一遍,但是和master上不同的是,node上是从join加入的时候加上--cri-socket及之后的内容
kubectl get nodes 失败

原因是kubeadm初始化时master没有与本机绑定
解决办法:设置环境变量
root@lxt-master:# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> /etc/profile
root@lxt-master:# source /etc/profile
root@lxt-master:# kubectl get nodes
NAME STATUS ROLES AGE VERSION
lxt-master NotReady control-plane 23m v1.26.3
问题解决
kubeadm token失效
因为init之后一直没有将node加入到集群中,隔几天再加入进去的时候发现报错

报错信息
error execution phase preflight: couldn't validate the identity of the API Server: could not find a JWS signature in the cluster-info ConfigMap for token ID "wen4ff"
原因是token失效,在master上通过kubeadm token list命令查看当前有效的token

list下无结果,通过kubeadm token create创建一个token
因为加入集群的时候还要指定一个sha256,这个一般是init成功之后会直接显示,如果忘记这个值,使用openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'查看

kubernetes dashboard 授权/权限/角色绑定问题导致页面报错
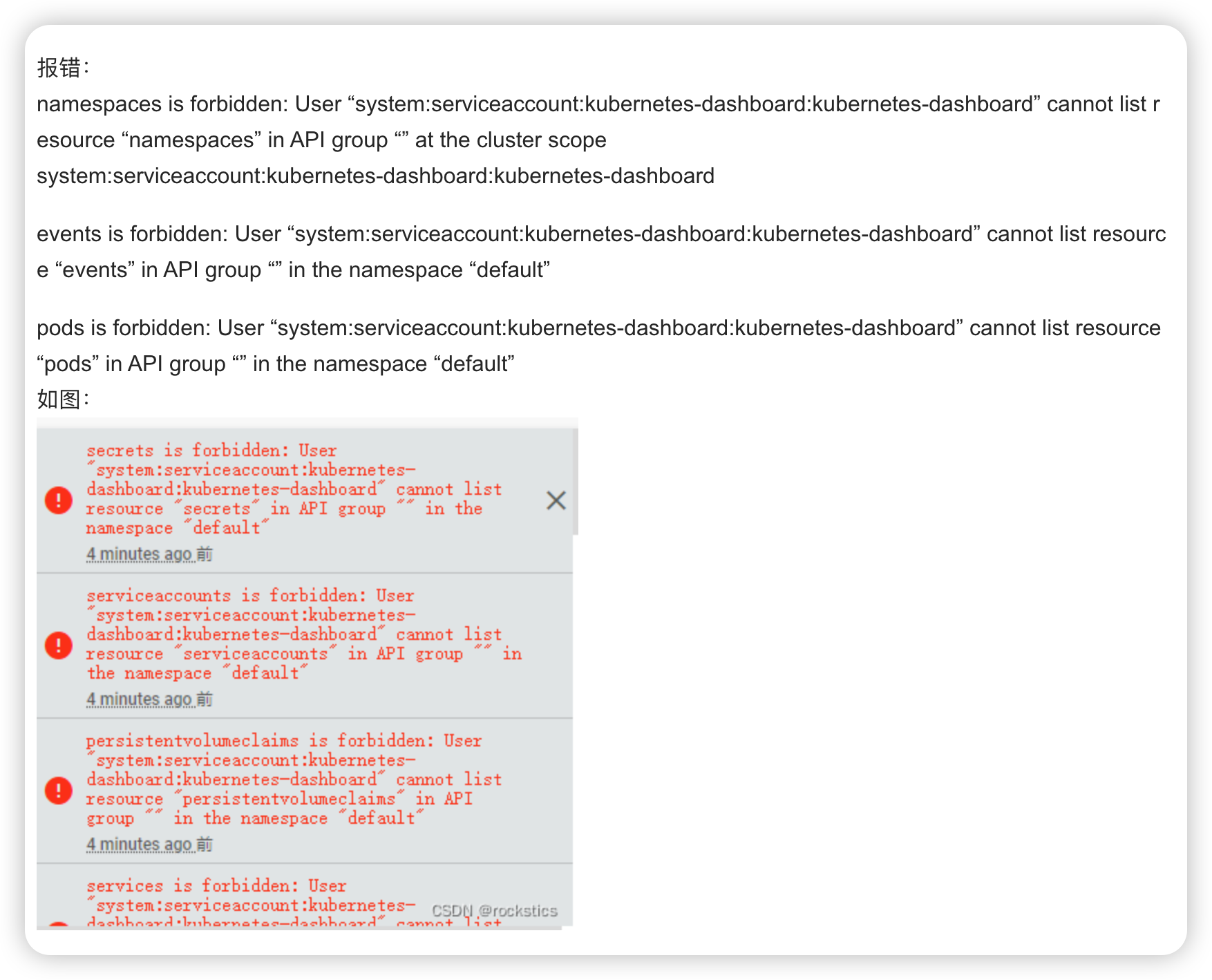
serviceaccount kubernetes-dashboard 权限问题,源文件namespace与当前环境namespace不一致
kubectl create clusterrolebinding kubernetes-dashboard --clusterrole=cluster-admin --serviceaccount=kubernetes-dashboard:kubernetes-dashboard
问题解决
rook部署时PodSecurityPolicy找不到的错误
error: resource mapping not found for name: "00-rook-privileged" namespace: "" from "common.yaml": no matches for kind "PodSecurityPolicy" in version "policy/v1beta1"
原因是PodSecurityPolicy在k8s后续版本中已经被移除,无法使用
解决办法:下载rook最新压缩包,把最新的common.yaml文件传到master上(传不传都一样,能访问到就行)
然后再执行kubectl apply -f common.yaml
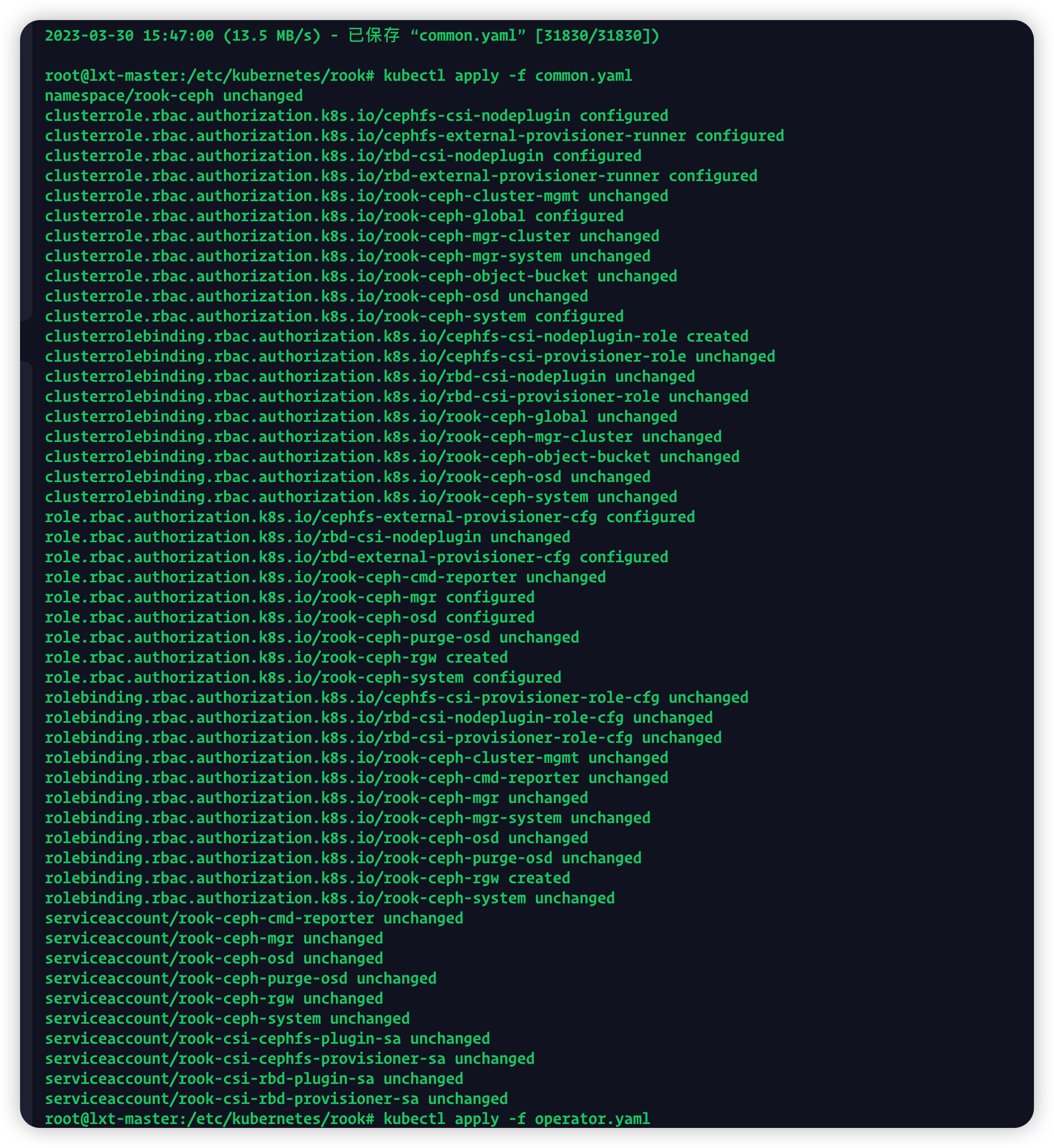
kubectl apply -f operator.yaml
kubectl apply -f cluster.yaml
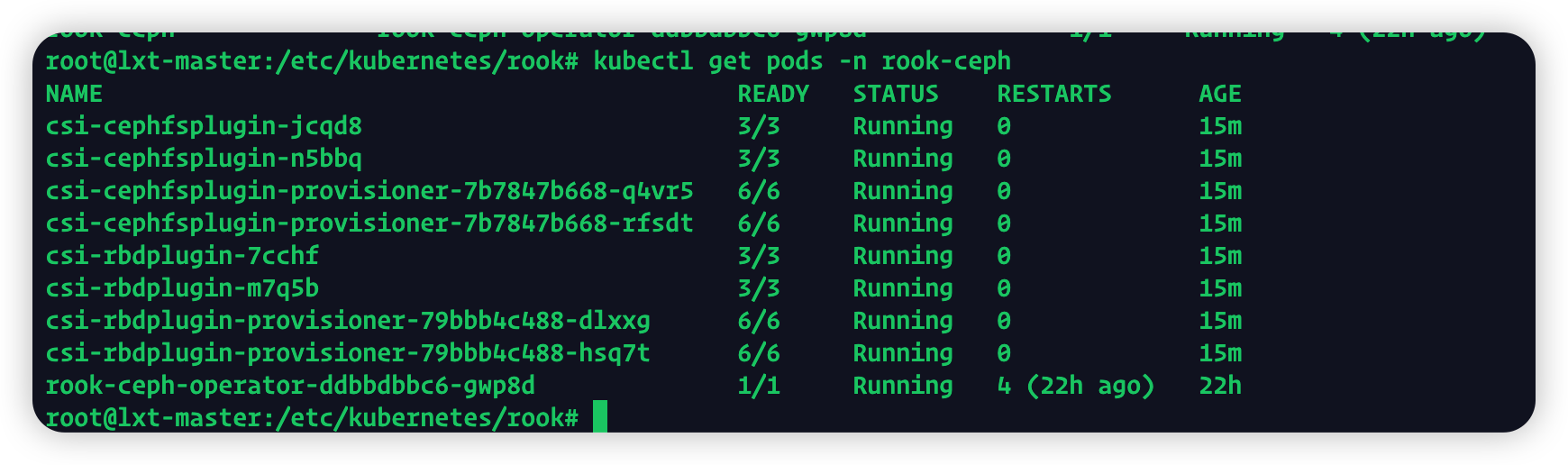
成功部署
默安
CSCASI=csc-qh-C1AB8CAA6566B73CBF4FDC818BEA0F249858357CA72D6DD3.1685945103099; CSCSID=GdTfZfvax2IkcZghR5fRfeyHNtSlRtYn;
蚁迅
CSCASI=csc-qh-C1AB8CAA6566B73CBF4FDC818BEA0F249858357CA72D6DD3.1685945103099; CSCSID=GdTfZfvax2IkcZghR5fRfeyHNtSlRtYn;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号