知识蒸馏综述:网络结构搜索应用
【GiantPandaCV导语】知识蒸馏将教师网络中的知识迁移到学生网络,而NAS中天然的存在大量的网络,使用KD有助于提升超网整体性能。两者结合出现了许多工作,本文收集了部分代表性工作,并进行总结。
1. 引言
知识蒸馏可以看做教师网络通过提供soft label的方式将知识传递到学生网络中,可以被视为一种更高级的label smooth方法。soft label与hard label相比具有以下优点:
- 模型泛化能力更强
- 降低过拟合的风险
- 一定程度上降低了学生网络学习的难度。
- 对噪声更加鲁棒。
- 具有更多的信息量。
那么知识蒸馏在网络结构搜索中有什么作用呢?总结如下:
- 降低子网络收敛难度 ,在权重共享的NAS中,子网之间参数耦合,如果单纯用hard label训练,会导致互相冲突,导致子网络训练不足的情况。
- 如果引入额外的教师网络,可以带来更多的监督信息,加快网络的收敛速度 。
- 一些工作通过知识蒸馏引入评判子网的指标 ,比如与教师网络越接近的,认为其性能越好。
知识蒸馏在很多工作中作为训练技巧来使用,比如OFA中使用渐进收缩训练策略,使用最大的网络指导小网络的学习,采用inplace distillation进行蒸馏。BigNAS中则使用三明治法则,让最大的网络指导剩下网络的蒸馏。
2. KD+NAS
2.1 Cream of the Crop Distilling Prioritized Paths For One-Shot Neural Architecture Search
目标:解决教师网络和学生网络的匹配问题(知识蒸馏中教师网络和学生网络匹配的情况下效果更好)。
在知识蒸馏中,选择不同的教师网络、不同的学生网络的情况下,最终学生网络的性能千差万别。如果学生网络和教师网络的容量相差过多,会导致学生难以学习的情况。Cream这篇文章就是为了解决两者匹配问题。

普通的SPOS方法如左图所示,通过采样单路径子网络进行训练。右图则是结合了知识蒸馏的方法,Cream提出了两个模块:
- Prioritized Path Board : 这个模块中维护了一组优先路径,所谓优先路径就是性能表现较好的子网络,Cream将优先路径Board中的网络作为教师网络,引导知识的蒸馏。
- Meta Network: 这个模块是一个匹配模块,每当采样一个子网络,就会从优先路径Board中计算一个最匹配的网络作为教师网络,完成蒸馏的过程。
Cream中心思想是,子网络可以在整个训练过程中协作学习并相互教导,目的是提高单个模型的收敛性。
消融实验如下:

2.2 DNA : Block-wisely Supervised Neural Architecture Search with Knowledge Distillation
目标:通过教师引导各个block特征层的学习,根据loss大小评判各子网的性能。
这是一篇将NAS和KD融合的非常深的一个工作,被CVPR20接收。之前写过一篇文章进行讲解,这里简单回顾一下。
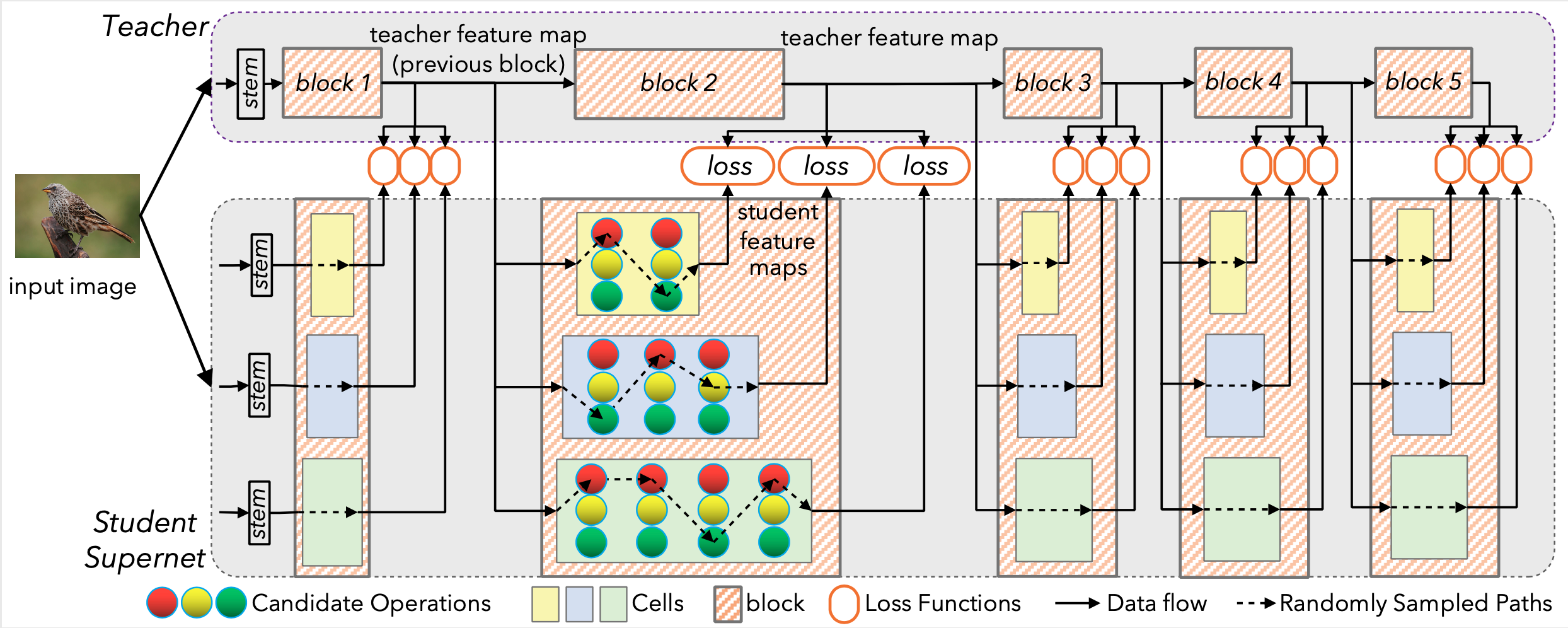
DNA是两阶段的one-shot NAS方法,因此其引入蒸馏也是为了取代普通的acc指标,提出了使用子网络与教师网络接近程度作为衡量子网性能的指标。
在训练的过程中,进行了分块蒸馏,学生网络某一层的输入来自教师网络上一层的输出,并强制学生网络这一层的输出与教师网络输出一致(使用MSELoss)。在搜索过程结束后,通过计算各子网络与教师网络的接近程度来衡量子网络。
2.3 AlphaNet :Improved Training of Supernet with Alpha-Divergence
目标:通过改进KL divergence防止学生over estimate或者under estimate教师网络。

上图展示了OFA,BigNAS等搜索算法中常用到的蒸馏方法,子网使用的是KL divergence进行衡量,文中分析了KL 散度存在的局限性:即避零性以及零强制性。如下公式所示,p是教师的逻辑层输出,q是学生逻辑层输出。
- 避零性:zero avoiding 当p>0的时候,为了保证KL为正,q必须大于0。如果p=0的时候,q大于0也不会被惩罚。会导致下图所示的过估计问题over estimate。

- 零强制性:zero forcing 当p=0的时候,会强制q=0,因为如果q>0会导致KL divergence趋于无穷。会导致下图所示的低估问题under-estimate

AlphaNet提出了一个新的散度衡量损失函数,防止出现过估计或者低估的问题。如下所示,引入了\(\alpha\)。
其中\(\alpha\)不为0或者1,这样如下图所示:

蓝色线对应example 2表示,当\(\alpha\)为负值,如果q过估计了p中的不确定性,\(D_\alpha(p||q)\)的值会变大。
紫色线对应example 1表示,当$\alpha
\(为正数,如果q低估了p中的不确定性,\)D_\alpha(p||q)$的值会变大
同时考虑两种情况,取两者中最大值作为散度:
2.4 TGSA: Teacher guided architecture search
目标:提出了衡量学生网络和教师网络内部激活相似度 衡量指标,通过表征匹配可以用来加速网络结构搜索。
这部分其实是属于知识蒸馏分类中基于关系的知识,构建的知识由不同样本之间的互作用构成。

具体的指标构成如上图所示,是一个bsxbs大小的矩阵,这个在文中被称为Representational Dissmilarity Matrix,其功能是构建了激活层内部的表征,可以通过评估RDM的相似度通过计算上三角矩阵的关系系数,比如皮尔逊系数。

该文章实际上也是构建了一个指标P+TG来衡量子网的性能,挑选出最优子网络。
- TG代表Teacher Guidance 计算的对象时所有RDM的均值。
- P代表Performance 也就是传统的准确率
如上图所示,RDM的计算是通过衡量教师网络的feature以及学生网络的feature的相似度,并选择选取其中最高的RDM相似度。通过构建了一组指标,随着epoch的进行,排序一致性很快就可以提高。

2.5 Search for Better Students to Learn Distilled Knowledge
目标:固定教师网络,搜索最合适的学生网络。
对于相同的教师网络来说,不同的架构的学生网络,即便具有相同的flops或者参数,其泛化能力也有所区别。在这个工作中选择固定教师网络,通过网络搜索的方法找到最优的学生网络,使用L1 Norm优化基础上,选择出与教师网络KL散度差距最小的学生网络。
- 学生网络结构搜索 :类似模型剪枝的方法,优化scale factor,然后剪枝的时候将该值较小的通道删除。
- 损失函数构建 :下面与KD的区别是增加了对scale factor g的L1 Norm约束。

2.6 Search to Distill: Pearls are Everywhere but not the Eyes
目标:在给定教师网络情况下,搜索最合适的学生网络。
神经网络中的知识不仅蕴含于参数,还受到网络结构影响。KD普遍方法是将教师网络知识提炼到学生网络中,本文提出了一种架构感知的知识蒸馏方法Architecture-Aware KD (AKD),能够找到最合适提炼给特定教师模型的学生网络。

Motivation: 先做了一组实验,发现不同的教师网络会倾向于不同的学生网络,因此在NAS中,使用不同的教师网络会导致模型倾向于选择不同的网络结构。

AKD做法是选择使用强化学习的方法指导搜索过程, 使用的是ENAS那种通过RNN采样的方法。

2.7 Towards Oracle Knowledge Distillation with NAS
目标:从集成的教师网络中学习,并使用NAS调整学生网络模型的容量。NAS+KD+集成。
这篇文章之前也进行了讲解,是网络结构搜索,知识蒸馏,模型集成的大杂烩。
- 网络结构搜索 可以说占非常小的比重,因为搜索空间几乎属于微调,并不是从头搜索,而是大部分的结构都固定下来,只调整某些层的参数,用于控制模型容量。
- 知识蒸馏+模型集成 :提出了动态选择待集成的模型,选择对应的教师网络进行蒸馏。
详见: https://blog.csdn.net/DD_PP_JJ/article/details/121268840
2.8 AdaNAS: Improving neural architecture search image classifiers via ensemble learning
这篇文章比较有意思,使用上一步中得到的多个子网络进行集成,可以得到教师网络,然后使用知识蒸馏的方法来引导新的子网络的学习。关注重点在于:
- 使用集成的模型性能是否会提升
- 通过先前集成的模型指导模型蒸馏能否生效
- 能否得到一种自动化的集成模型的方式。
AdaNAS受Born Again Network(BAN)启发, 提出Adaptive Knowledge Distillation(AKD)的方法以辅助子网络的训练。
集成模型选择 :

从左到右代表四次迭代,每个迭代中从搜索空间中选择三个模型。绿色线框出的模型代表每个迭代中最优的模型,AdaNAS选择将每个迭代中最优subnet作为集成的对象。
最终集成的时候还添加了额外的weight参数w1-w4:

最终输出逻辑层如下所示:(这个w权重也会被训练,此时各个集成网络的权重是固定的,只优化w)
2.9 Differentiable Feature Aggregation Search for
Knowledge Distillation
目标:解决知识蒸馏的效率和有效性,通过使用特征聚合来引导教师网络与学生网络的学习,网络结构搜索则是体现在特征聚合的过程,使用了类似darts的方法进行自适应调整放缩系数。ECCV20
文章总结了几种蒸馏范式:

最后一种是本文提出的方法,普通的特征蒸馏都是每个block的最后feature map进行互相蒸馏,本文认为可以让教师网络的整个block都引导学生网络。

具体如何将教师网络整个block中所有feature map进行聚合,本文使用的是darts的方法进行动态聚合信息。(a) 图展示的是对group i进行的可微分搜索过程。(b)表示从教师到学生的路径loss构建,使用的是CE loss。(c)表示从学生到教师网络的路径loss构建,使用的是L2 Loss。其中connector实际上是一个1x1 卷积层。

(ps: connector让人想到VID这个工作)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号