ECCV20 BigNAS无需后处理直接部署
【GiantPandaCV导语】这篇是Slimmable Network三部曲之后的续作,提出了Single-Stage的超网训练方法,在更大的搜索空间中,提出了很多训练的Trick来提升训练效果以及稳定训练过程。
0. Info
Title: BigNAS: Scaling Up Neural Architecture Search with Big Single-Stage Models
Author: Jiahui Yu, Pengchong Jin, Hanxiao Liu, Gabriel Bender, Pieter-Jan Kindermans, Mingxing Tan, Thomas Huang, Xiaodan Song, Ruoming Pang, Quoc Le Google Brain
Link: https://arxiv.org/pdf/2003.11142v3.pdf
Date: ECCV20
Code: https://github.com/JiahuiYu/slimmable_networks
1. Motivation
目前NAS的一个非常受欢迎的研究分支是one-shot NAS,即用一个超网包含所有的搜索空间,子网络通过共享超网络的参数来加速训练流程。超网的作用可以看作一个评估器,用于通过评估子网在验证集上的准确率来代表该网络在测试集的效果。
One-Shot NAS在这里被划分为Two-Stage NAS,包含了搜索阶段和评估阶段。
- 在搜索阶段,通过使用某些算法进行训练超网络,找到最有希望的子网;
- 在评估阶段,将搜索阶段找到的子网从头进行训练,得到最终在测试集上的准确率。
之所以需要评估阶段是因为一个实验现象 ,即通过超网共享得到的子网的准确率是远低于从头训练该子网的准确率的。所以之前的大部分工作都存在评估阶段,通常会在搜索阶段结束以后采用重新训练、微调或者其他后处理发方法提升准确率。
BigNAS则试图挑战以上观点,认为评估阶段可以不必要存在的,无需额外的重新训练或者后处理步骤,从超网中直接得到的子网络就可以直接部署,也即提出了One-Stage NAS。
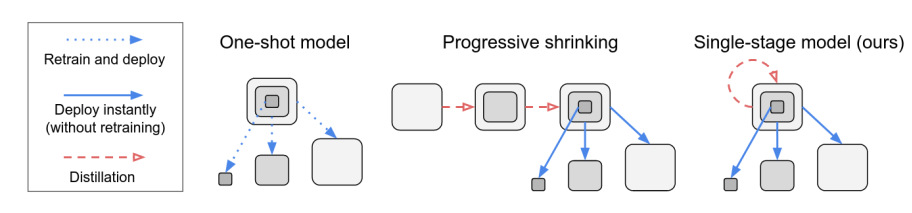
如上图所示:普通的One-Shot模型使用训练好的超网得到对应子网,然后经过retrain才可以进行部署。
Once for all中则提出了Progressive Shrinking的方法,先训练大的网络,然后大的网络作为教师网络指导小网络进行训练,最终可以可以无需retrain直接部署。
BigNAS则提出使用了Single-Stage的范式,同时训练所有的子网络,并且可以无需retrain直接部署。
2. Contribution
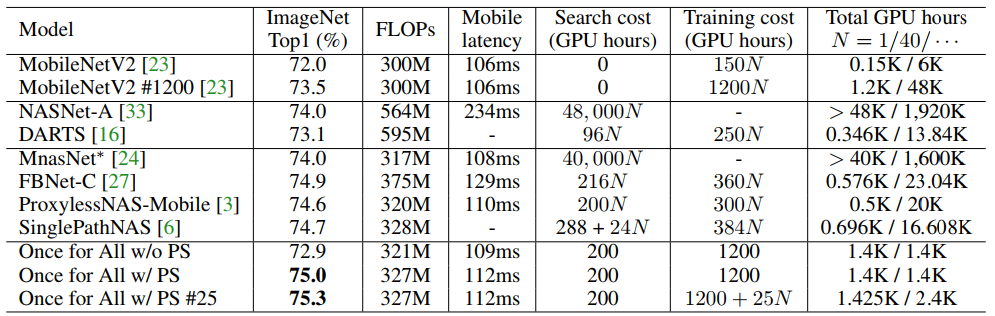
Once for all并没有完全抛弃后处理过程,根据OFA提供的试验结果,其在ImageNet上继续finetune了25个epoch,也会带来一定的提升。
BigNAS的核心贡献就是:
-
无需重新训练和后处理,可以训练一个Single-Stage模型,直接从超网中就可以切分子网用于部署。
-
提出了一些技巧来弥补不同的初始化和大小模型的学习率调整的差距。
笔者个人感觉,超网络作为一个过参数的网络,相当于集成了成千上万个子网络进行共享,每个子网络的梯度优化方向不同,可能会带来冲突,这可能是weight sharing nas效果不如stand alone nas的原因。那为何BigNAS可以做到无需retrain直接部署呢?笔者觉得这与超网络的模型容量有一定的关系,同时也和训练优化的技巧有一定的关系。OFA得到的模型的FLOPS在230M的量级,BigNAS的FLOPS则是从200M到1G都有,可以说模型容量比较大,如果能够承载非常多的子网,那么可能准确率本身确实可以达到比较高的水平。再配合上一些探索得到的训练技巧,将超网性能提升到一个非常高的水平。廖哥认为inplace distillation起到了比较重要的作用。鑫哥认为超网模型的参数冗余度非常高,所以OFA这种类型是可行的。也欢迎添加笔者微信进行讨论~
3. Method
方法部分主要介绍了几种训练技巧以及选择模型的方式。
笔者之间训练过一个简单的超网,可以说超网训练难度要比训练普通的网络高很多倍,由于其每次是动态采样,可能会出现训练不稳定,大模型过拟合小模型欠拟合的问题。
3.1 Tricks
Trick1: 三明治法则
每一步训练,找到最大模型和最小模型,然后无偏均匀采样N(N=2)个中间大小的模型。训练以上所有模型,累积梯度,然后进行一次更新。
最小的模型代表了整体的最低水平,最大的模型代表整体最高水平,BigNAS目标就是同时推高lower bound和upper bound,实现整个超网性能的提升。
Trick2: Inplace Distillation
使用最大模型提供的soft label对其他小网络进行蒸馏也是一种常用的trick(OFA中就用到了这种策略)。
值得一提的是,BigNAS中的小网络只使用inplace distillation进行训练,并没有直接根据label进行训练。
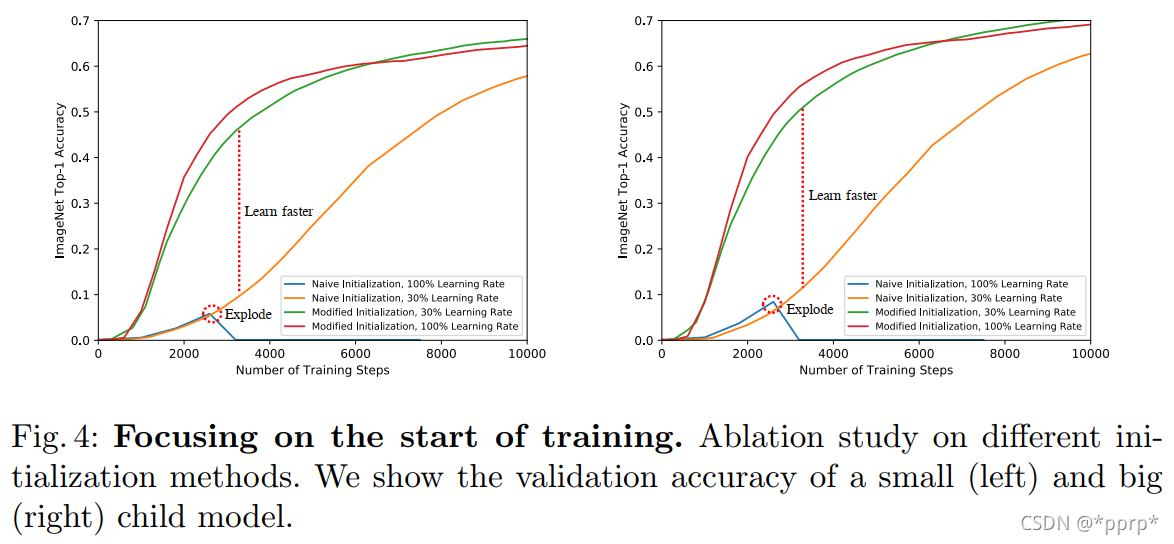
Trick3: Initialization
训练超网时候的learning rate选取不能和普通网络一致,需要将learning rate调整为原来的30%左右,这样训练loss才不会爆炸。
这样做虽然loss不会爆炸,但是也降低了最终的性能,这就需要另外一个方法来稳定训练。由于本文搜索空间中是包含残差网络的,使用zero-initialize每个残差块的最后一个BN的缩放系数为0,不仅可以稳定训练还能提升最终模型准确率。
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
for m in self.modules():
if isinstance(m, MaskedBlock):
# type: ignore[arg-type]
nn.init.constant_(m.shortcut.convbn.bn.weight, 0)
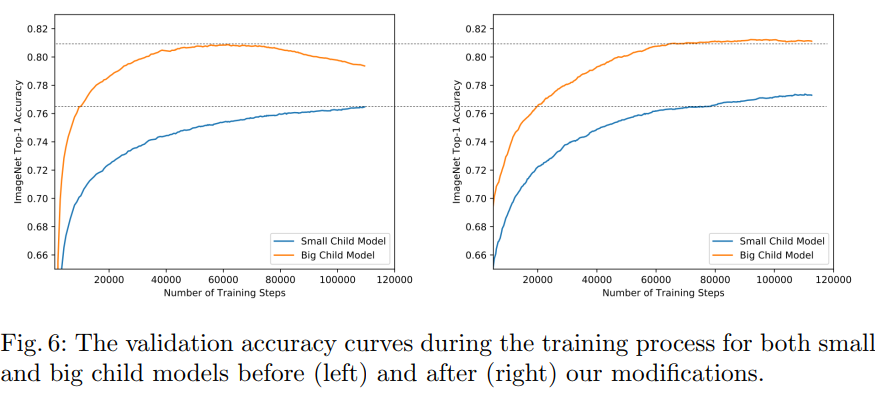
Trick4: Convergence Behavior
使用三明治法则进行训练会带来一个问题,随着训练的进行,在小网络还处于欠拟合的时候,大网络就已经过拟合了。
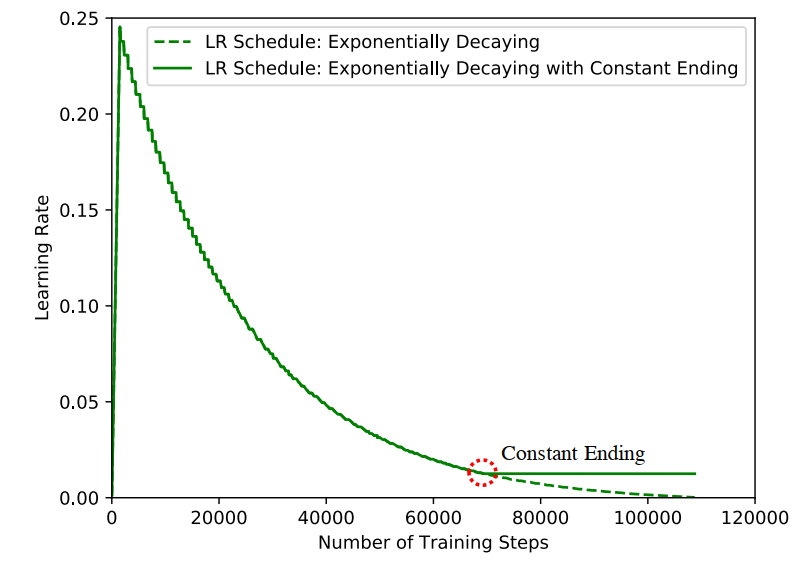
BigNAS提出修改学习率策略来解决这个问题,使用指数衰减策略降低学习率的时候,当学习率达到初始设定的5%, 将学习率保持恒定。
这种做法的理由是,大模型达到精度峰值以后用恒定学习率可以梯度震荡,缓解过拟合线性,而这个时候欠拟合的小模型可以继续进行训练。
Trick5: Regularization
正则化方法,也是为了解决以上问题,只给最大的子网施加正则,包括weight decay、Dropout等正则化方法。
Trick6: BN Calibration
BN矫正技术在one-shot nas中非常常见,single path one shot、FairNAS等工作中都使用到了这个技术。采样得到的子网通常需要在训练集上重新计算BN的值,这样模型性能才不会大幅降低。
3.2 Coarse-to-fine Architecture Selection
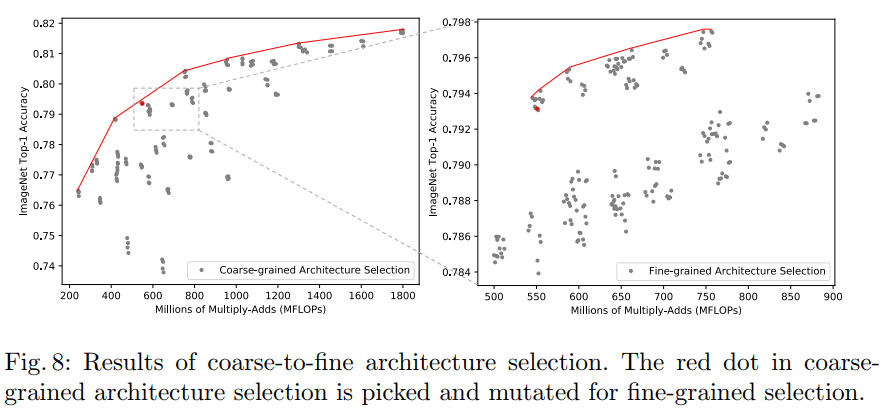
由于现在搜索空间中的候选网络数量非常多,如何从这些候选网络中选择出合适的网络呢?BigNAS提出了由粗到细的搜索方法:
-
粗略搜索阶段:找到一个大致满足约束的粗粒度空间,
-
细粒度搜索阶段:然后再这个子空间中进行细粒度网格搜索查找模型。
4. Experiment
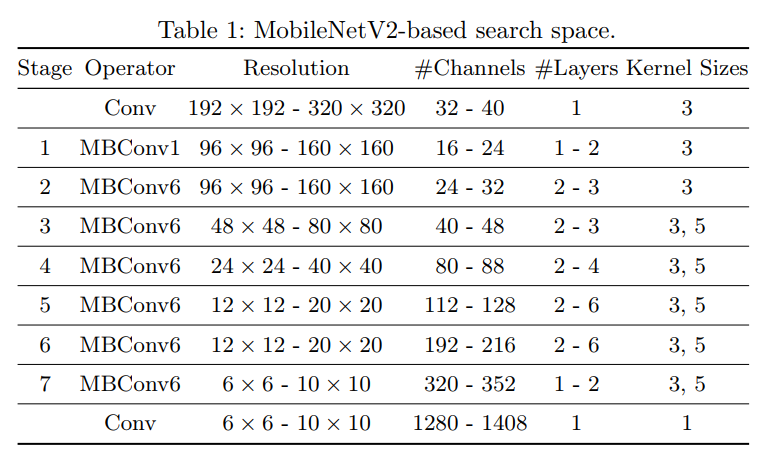
- 搜索空间展示:使用的是MobileNetV2的搜索空间。
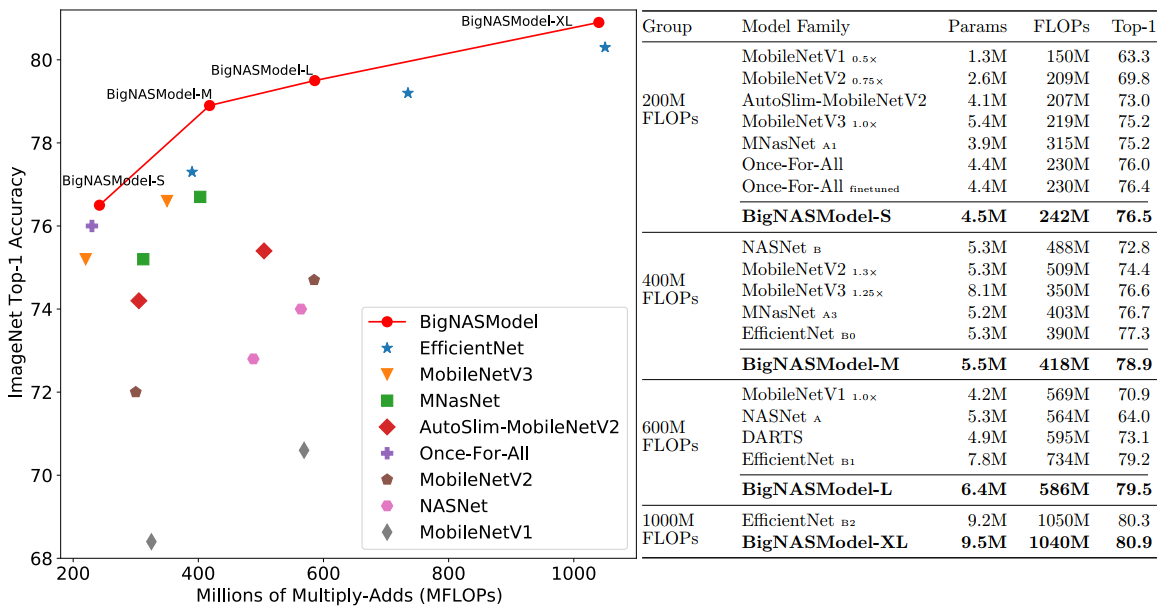
- 在不同量级下与其他方法进行对比:
- 验证学习率设置以及初始化方法对模型训练的影响。
- 验证学习率策略的有效性
- 验证正则方法的有效性
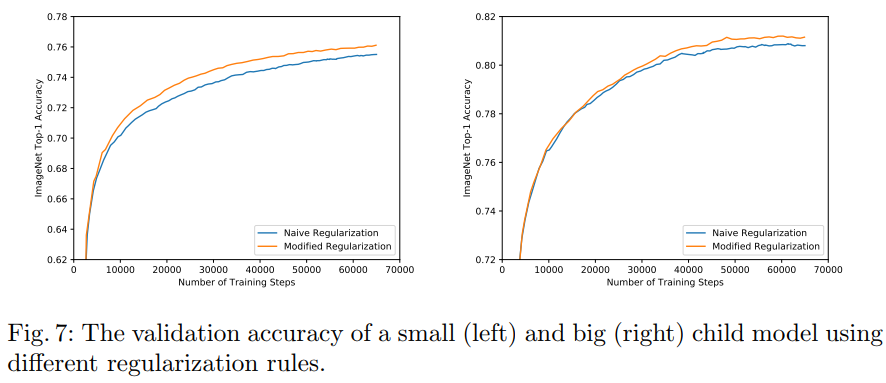
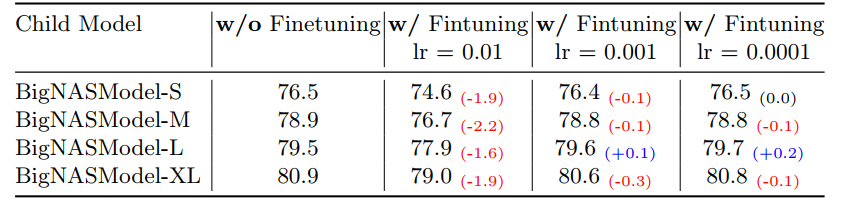
- 验证继续finetune是否会带来提升?
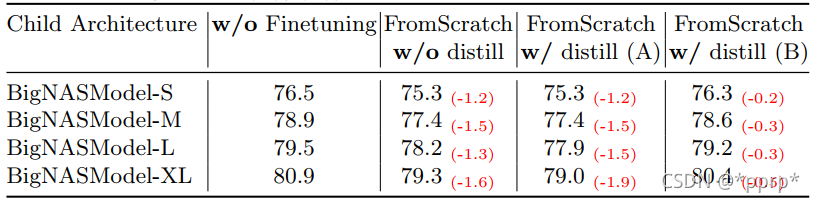
- 验证从头训练会不会带来提升?
5. Revisiting
看这篇文章很容易把BigNAS看作是Trick的合集,不得不承认,BigNAS的效果确实很好,少不了这些Trick的功劳。后期笔者会对这些trick进行验证,看看是否真的和论文中一样work。
其中比较令人在意的一个问题就是为何这样可以work,即直接从超网中采样得到子网就能直接部署,无需finetune,retrain等操作。
可能的解释有:
-
模型容量足够大,之前的two stage nas算法容量不足,参数冗余度不够。
-
之前的two-stage nas没有充分训练
-
训练技巧的功劳,比如Progressive Shrinking方法或者Inplace Distillation的功劳。
此外,OFA在MobileNetV3, ProxylessNAS, ResNet三种空间进行搜索;BigNAS在MobileNet,ResNet,MNasNet进行的搜索;这几种空间其实差不太多,都是ResNet-like的类型,其他two-stage nas的空间,比如DARTS-like,NASNet-like搜索空间中是否可行呢?
6. Take Away
BigNAS追随了Once for all的工作,提出了One-Stage NAS,无需retrain就直接部署的方案,使用一系列技巧来提升模型训练的效果,得到了非常广泛的BigNAS族群,FLOPS从200M到1G都广泛存在。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号