如何更好地调整学习率?
【GiantPandaCV导读】learning rate对模型调优重要性不言而喻,想到超参数调优第一个可能想到的方法就是网格搜索Grid Search,但是这种方法需要大量的计算资源。之前使用fastai的时候发现其集成了一个功能叫lr_finder(), 可以快速找到合适的学习率,本文就主要分析这个15年就提出来的技术Cyclical Learning Rates。
链接:https://arxiv.org/abs/1506.01186

1. 前言
一般学习率可以人工设置,根据经验进行设置。通常会尝试初始学习率为0.1 0.01 0.001 0.0001等来观察初始阶段loss收敛情况。
-
lr过大会导致loss爆炸
-
lr过小会导致loss下降过于缓慢
-
warmup可以防止模型过于震荡,在小学习率的warmup下可以让模型趋于稳定,这样可以使模型收敛速度变快、模型效果更佳。
-
finetune时候需要用到的learning rate往往比较小,因为backbone部分的权重已经固定,所以微调部分权重不需要太大的学习率。
除了人工设置learning rate还可以用以下方法:
-
grid search: 网格搜索最合适的learning rate,这种方法代价比较大,比如旧版的yolov3中就使用了这种grid search的策略,如果计算资源不够的情况下往往很难找到最好的参数。
-
random search:采用随机的方法进行搜索,在一定区间内产生随机点,找到最优解的近似解。
-
heuristically search:启发搜索可以通过利用启发信息来引导搜索,减少搜索范围,降低问题复杂度,从而可以减少对计算资源的需求,提高了搜索效率。启发式搜索有模拟退火算法、遗传算法、进化规划、蚁群算法、贝叶斯优化。
一些推荐的调参包:
Hyperopt: https://github.com/hyperopt/hyperopt
Optunity: https://github.com/claesenm/optunity
Advisor: https://github.com/tobegit3hub/advisor
NNI: https://github.com/microsoft/nni
2. CLR 选择一个合适的初始学习率
使用CLR可以在CIFAR10数据集上达到一下效果:
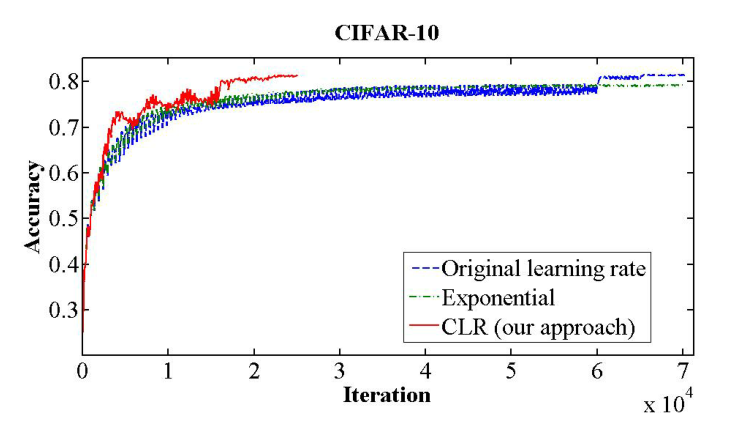
可以看出CLR可以让模型收敛速度加快,在更少的迭代下收敛到更高的精度,并且集成到了fastai中,可见这种方法得到了认可。
learning rate在很多scheduler中并不是一直不变的,而是不断上升和下降,虽然这种调整方法短期内来看对模型性能有不利影响,但是长期来看对最终性能是有帮助的。
一般来说,学习率会被设置在一个最大值、最小值的范围内,并且学习率在这些边界之间进行循环变化,变化方式有以下几种:
-
triangular window,即线性的变换learning rate
-
Welch window,即抛物线状变换learning rate
-
Hann window,即正弦变换learning rate
实验发现这几种方法并没有差异非常明显,所以本文以最简单的triangular window作为基准,如下图所示:
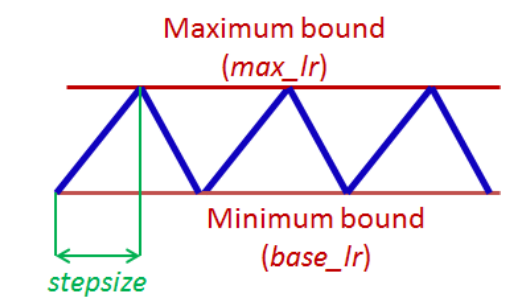
通常认为loss优化最困难的地方在于鞍点,而不是局部最小值,鞍点梯度过小所以会让学习的过程变慢。这个时候增大学习率可以让模型越过鞍点。 以上理论就是CLR的一个直观的理解,为此需要不断动态调整learning rate的大小。
代码实现:
cycle = np.floor(1+iterations/(2*step_size))
x = np.abs(iterations/step_size - 2*cycle + 1)
lr= base_lr + (max_lr-base_lr)*np.maximum(0, (1-x))*scale_fn(x)
对CLR有一个直观理解以后,还有一个关键问题需要解决:** 如何确定learning rate最大值和最小值?**
LR range test 可以用来解决这个问题,即通过增加学习率观察结果的方式来判断最大值和最小值。通过不断增加学习率以及对应的结果可以得到accuracy vs learning rate图或者loss vs learning rate图。
这里借用:https://blog.csdn.net/m0_37477175/article/details/89395050 中的图示。
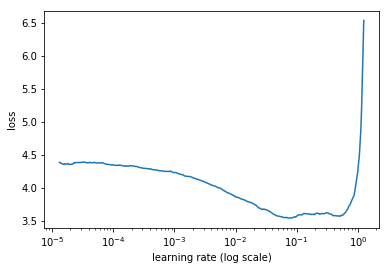
-
base_lr的设置:base_lr要选择loss图刚开始下降的点,上图就是0.001。
-
max_lr的设置:max_lr要选择loss图开始上升的位置,上图就是0.1。
再举一个例子,来自https://github.com/bckenstler/CLR 这个库提供的例子。
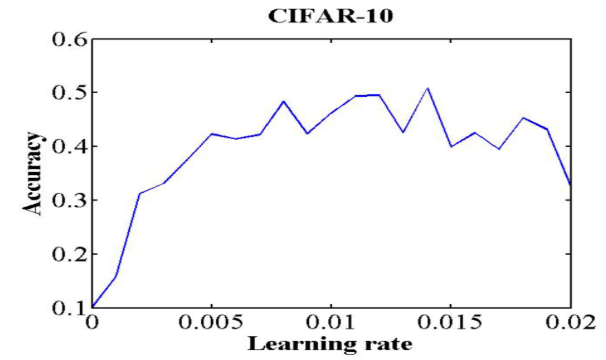
这个图展示的是accuracy vs learning rate,和loss正好相反:
-
base_lr:选择acc刚开始上升的点,这里选择0.001
-
max_lr:选择acc刚开始缓和的点,这里选择0.006
3. 代码实现
keras 版本实现详见:https://github.com/bckenstler/CLR
pytorch版本实现:https://github.com/weiaicunzai/pytorch-cifar100
笔者使用pytorch版跑的结果如下,通过一下图可以判断base_lr=1e-5 max_lr=1e-3
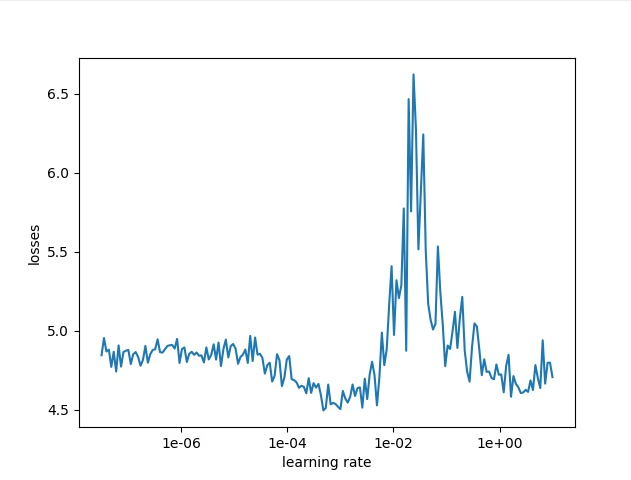
最后推荐一个可玩性很高的网站:https://losslandscape.com/explorer 你可以选取一个初始点,然后进行随机梯度下降,通过调整learning rate可以看到收敛情况,也就是下图黄色的线。

4. Reference
https://www.fast.ai/2020/02/13/fastai-A-Layered-API-for-Deep-Learning/#ref-lrfinder
https://arxiv.org/abs/1506.01186
https://zhuanlan.zhihu.com/p/29779000

 浙公网安备 33010602011771号
浙公网安备 33010602011771号