【神经网络搜索】Efficient Neural Architecture Search
【GiantPandaCV导语】本文介绍的是Efficient Neural Architecture Search方法,主要是为了解决之前NAS中无法完成权重重用的问题,首次提出了参数共享Parameter Sharing的方法来训练网络,要比原先标准的NAS方法降低了1000倍的计算代价。从一个大的计算图中挑选出最优的子图就是ENAS的核心思想,而子图之间都是共享权重的。

1. 摘要
ENAS是一个快速、代价低的自动网络设计方法。在ENAS中,控制器controller通过在大的计算图中搜索挑选一个最优的子图来得到网络结构。
- controller使用Policy Gradient算法进行训练,通过最大化验证集上的期望准确率作为奖励reward。
- 被挑选的子图将使用经典的CrossEntropy Loss进行训练。
子网络之间的权重共享可以让ENAS性能更强大的性能,同时要比经典的NAS方法降低了约1000倍的计算代价。
2. 简介
NAS-RL使用了450个GPU训练了3-4天,花费了32,400-43,200个GPU hours才可以训练出一个合适的网络,需要大量的计算资源。NAS的计算瓶颈就在于需要让每个子模型从头开始收敛,训练完成后就废弃掉其训练好的权重。
本文主要贡献是通过让所有子模型共享权重、避免从头开始训练,从而有效提升了NAS的训练效率。随后的子模型可以通过迁移学习的方法加速收敛速度、从而加速训练。
ENAS可以做到使用单个NVIDIA GTX 1080Ti显卡,只需要花费16个小时。同时在CIFAR10上可以达到2.89%的test error。
3. 方法
3.1 一个例子
ENAS可以看作是从一个超网中得到一个自网络,如下图所示。6个节点相互连接得到的就是超网(是一个有向无环图),通过controller得到红色的路径就是其中的一个子网络。
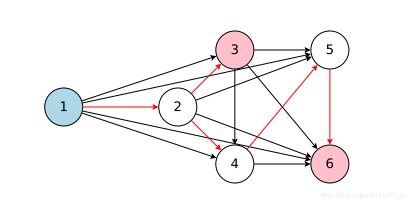
举一个具体的例子,假设当前有4个节点:
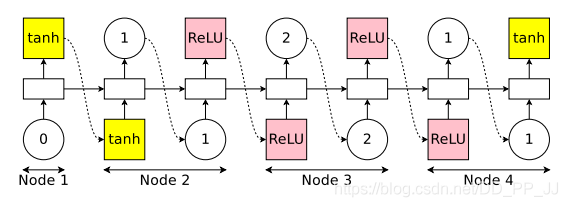
上图是controller,具体实现是一个LSTM,需要做出以下决策:
- 激活哪个边
- 对应Node选择什么操作
第一个Node,controller首先采样一个激活函数,这里采用的是tanh,然后这个激活会接收x和h作为输入。
第二个Node,先采样上一个index=1,说明Node2应该和Node1相连接;然后再采样一个激活函数relu。
第三个Node,先采样上一个index=2,说明Node3应该和Node2相连接;然后采样一个激活函数Relu。
第四个Node,先采样上一个index=1,说明Node4应该和Node1相连接,然后采样一个激活函数tanh。
结束后发现有两个节点是loose end, ENAS的做法是将两者结果做一个平均,得到最终输出。
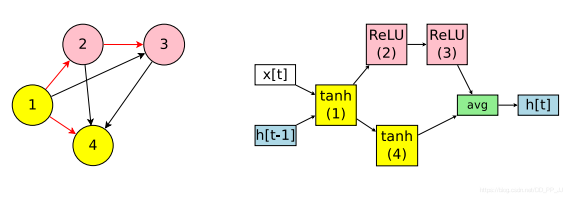
在上述例子中,假设节点数量为N,一共使用了4个激活函数可选。搜索空间大小为:\(4^N\times N!\)
其中\(4^N\)代表N个节点可选的4个激活函数组成的空间,\(N!\) 代表节点的连接情况,之所以是阶乘也很容易理解,因为随后的Node只能连接之前出现过的Node。
3.2 ENAS训练流程
在ENAS中,有两组可学习参数,Controller LSTM中的参数\(\theta\) 和 子模型共享的权重参数\(w\)。具体流程是:
- LSTM sample出一个子模型,然后训练模型\(w\), 通过标准的反向传播算法进行训练,训练完成以后在验证集上进行测试。
- 通过验证集上结果反馈给LSTM,计算\(\theta\)的梯度,更新LSTM的参数。
- 如此反复,可以训练出一个LSTM能够让模型在验证集上的性能最佳。
第一步:训练共享参数w
首先固定住controller的参数,然后使用蒙特卡洛估计来计算梯度,更新w权重:
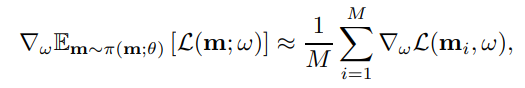
m是从\(\pi(m;\theta)\) 中采样得到的模型,对于所有的模型计算模型损失函数的期望。右侧公式是梯度的无偏估计。
第二步:训练controller 参数\(\theta\)
这一步固定住w,更新controller参数,希望可以得到的Reward值(也就是验证集准确率)尽可能大。
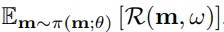
这里使用的是REINFORCE算法来进行计算的,具体内容可以查看NAS-RL那篇文章中的讲解。
3.3 marco search space

有了上边的例子做铺垫,卷积的这部分就很好理解了,区别有几点:
- 节点操作不同,这里可以是3x3卷积、5x5卷积、平均池化、3x3最大池化、3x3深度可分离卷积,5x5深度可分离卷积 一共六个操作。
- 上图Node3输出了两个值,代表先将node1和node2的输出tensor合并,然后在经过maxpool操作。
计算卷积网络设计的空间复杂度,对于第k个节点,顶多可以选取k-1个层,所以在第k层就有\(2^{k-1}\)种选择,而这里假设一共有L个层需要做从6个候选操作中做选择。那么在不考虑连线的情况下就有\(6^L\)可能被挑选的操作,由于所有连线都是独立事件,那复杂度计算就是:\(6^L\times 2^{L(L-1)/2}\)(除以2是因为连线具有对称性,采样1,2和2,1结果是一致的)。
3.4 micro search space
ENAS中首次提出了搜索一个一个单元,然后将单元组合拼接成整个网络。其中单元分为两种类型,一种是Conv Cell 该单元不改变特征图的空间分辨率;另外一种是Reduction Cell 该单元会将空间分辨率降低为原来的一半。
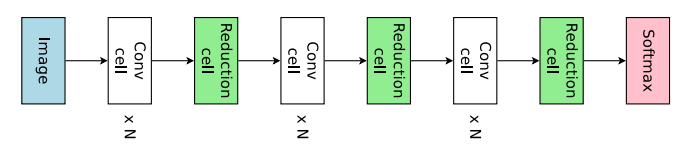
假定每个cell里边有B个节点,由于网络设定是node1和node2是单元的输入,所以刚开始这部分需要特殊处理,固定两个单元,搜索随后的单元,即还剩下B-2个节点需要搜索。
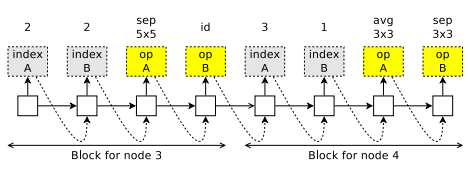
如上图所示,从node3开始生成,首先生成两个需要连接的两个对象,indexA和indexB; 然后生成两个op, 分别是sep 5x5和直连id。将操作sep 5x5施加到indexA对应节点上;将操作直连施加到indexB对应节点上,然后通过add的方式融合特征。
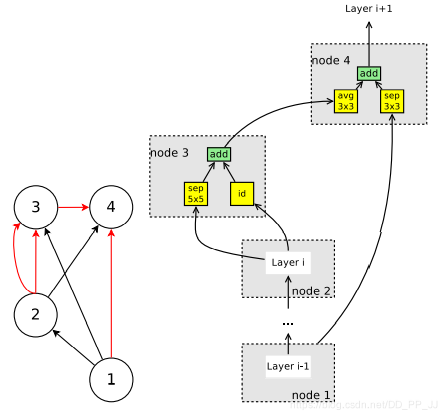
搜索空间复杂度计算:首先分为Conv Cell和Reduction Cell,由于他们并没有本质不同,只是所有的操作的stride设置为2,复杂度也是一样的。
假定当前是第i个节点,可以选择来自先前i-1个节点中的两个节点,并且可选操作有5个。假设只选择一个节点,那么复杂度是\(5\times (B-2)!\), 由于要选择两个节点,两个节点的选择是互相独立的,所以复杂度计算变为:\((5\times (B-2)!)^2\) 。而又有Reduction Cell和Conv Cell也是互相独立的,所以复杂度变为\((5\times (B-2)!)^4\) ,计算完毕。
4. 实验结果
主要是在NLP中常用的语料库Penn Treebank和CV中经典的数据集CIFAR-10上进行了实验。
4.1 语言模型
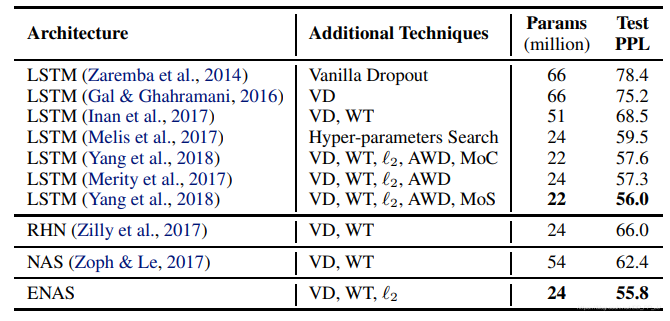
在单个GTX 1080Ti上训练了10个小时,达到了55.8的test perplexity, 下图是通过ENAS找到的RNN单元。
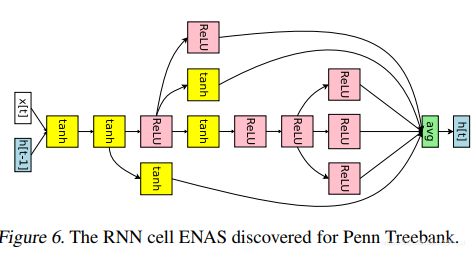
结果如下:
4.2 图像分类
数据集:CIFAR10有5w张训练图片和1w张测试图片,使用标准的数据预处理和数据增强方法:如将训练图片padding到40x40大小,然后随机裁剪到32x32,水平随机反转。
训练细节: 共享权重w使用Nesterov momentum来训练,使用cosine schedule调整lr,lr最大设置为0.05,最小设置为0.001,T0=10, Tmul=2。每个子网络设置运行310个epoch。权重初始化使用He initialization。weight decay设置为\(10^{-4}\)。
controller的设置细节,policy gradient的权重\(\theta\)使用均匀的从[-0.1,0.1]初始化,使用0.00035的学习率,使用Adam优化器,设置tanh常数为2.5 temerature 设置为5.0; 给controller 得到的熵添加0.1的权重。
在macro搜索空间中,通过在skip connection两层之间添加KL 散度来增加稀疏性, KL散度项对应的权重设置为0.8.
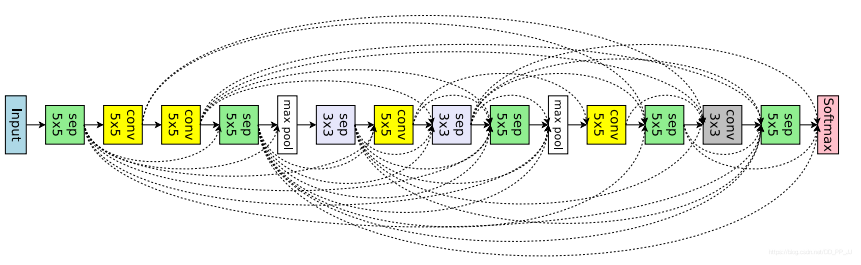
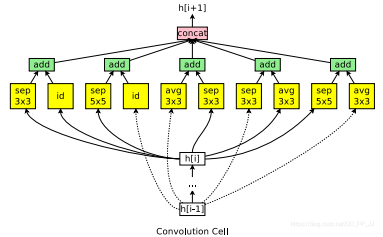
实验结果对比如下:

5. 代码实现
代码这里参考NNI中的实现,以macro为例,ENASLayer实现如下:
class ENASLayer(mutables.MutableScope):
def __init__(self, key, prev_labels, in_filters, out_filters):
super().__init__(key)
self.in_filters = in_filters
self.out_filters = out_filters
self.mutable = mutables.LayerChoice([
ConvBranch(in_filters, out_filters, 3, 1, 1, separable=False),
ConvBranch(in_filters, out_filters, 3, 1, 1, separable=True),
ConvBranch(in_filters, out_filters, 5, 1, 2, separable=False),
ConvBranch(in_filters, out_filters, 5, 1, 2, separable=True),
PoolBranch('avg', in_filters, out_filters, 3, 1, 1),
PoolBranch('max', in_filters, out_filters, 3, 1, 1),
SEConvBranch(in_filters, out_filters, 3, 1, 1, reduction=4)
])
if len(prev_labels) > 0:
self.skipconnect = mutables.InputChoice(
choose_from=prev_labels, n_chosen=None)
else:
self.skipconnect = None
self.batch_norm = nn.BatchNorm2d(out_filters, affine=False)
def forward(self, prev_layers):
out = self.mutable(prev_layers[-1])
if self.skipconnect is not None:
connection = self.skipconnect(prev_layers[:-1])
if connection is not None:
out += connection
return self.batch_norm(out)
其中的mutables是NNI中的一个核心类,可以从LayerChoice所提供的选择中挑选一个操作,其中最后一个SEConvBranch是笔者自己补充上去的。
- mutable LayerChoice就是从备选选项中选择其中一个操作
- mutable InputChoice是选择前几层节点进行连接。
主干网络如下:
class GeneralNetwork(nn.Module):
def __init__(self, num_layers=6, out_filters=12, in_channels=3, num_classes=10,
dropout_rate=0.0):
super().__init__()
self.num_layers = num_layers
self.num_classes = num_classes
self.out_filters = out_filters
self.dropout_rate = dropout_rate
self.stem = nn.Sequential(
nn.Conv2d(in_channels, out_filters, 3, 1, 1, bias=False),
nn.BatchNorm2d(out_filters)
)
pool_distance = self.num_layers // 3
# 进行pool操作是num_layers // 3
self.pool_layers_idx = [pool_distance - 1, 2 * pool_distance - 1]
self.dropout = nn.Dropout(self.dropout_rate)
self.layers = nn.ModuleList() # convolutional
self.pool_layers = nn.ModuleList() # reduction
labels = []
for layer_id in range(self.num_layers): # 设置12个layer
labels.append("layer_{}".format(layer_id))
if layer_id in self.pool_layers_idx: # 如果使用pool
self.pool_layers.append(FactorizedReduce(
self.out_filters, self.out_filters))
self.layers.append( # 相当于Node节点
ENASLayer(labels[-1], labels[:-1], self.out_filters, self.out_filters))
self.gap = nn.AdaptiveAvgPool2d(1)
self.dense = nn.Linear(self.out_filters, self.num_classes)
def forward(self, x):
bs = x.size(0)
cur = self.stem(x)
layers = [cur]
for layer_id in range(self.num_layers):
cur = self.layers[layer_id](layers)
layers.append(cur)
if layer_id in self.pool_layers_idx:
# 如果轮到了池化层
for i, layer in enumerate(layers):
layers[i] = self.pool_layers[self.pool_layers_idx.index(
layer_id)](layer)
cur = layers[-1]
cur = self.gap(cur).view(bs, -1)
cur = self.dropout(cur)
logits = self.dense(cur)
return logits
需要注意有几个点:
- self.stem是第一个node,手动设置的。
- 池化是强制设置的,在某些层规定进行下采样。
搜索过程调用了NNI提供的API:
model = GeneralNetwork()
trainer = enas.EnasTrainer(model,
loss=criterion,
metrics=accuracy,
reward_function=reward_accuracy,
optimizer=optimizer,
callbacks=[LRSchedulerCallback(lr_scheduler), ArchitectureCheckpoint("./checkpoints")],
batch_size=args.batch_size,
num_epochs=num_epochs,
dataset_train=dataset_train,
dataset_valid=dataset_valid,
log_frequency=args.log_frequency,
mutator=mutator)
mutator是NNI提供的一个类,就是上述提到的controller,这里具体调用的是EnasMutator。
def _sample_layer_choice(self, mutable):
# 选择 某个层 只需要选一个就可以了
self._lstm_next_step() # 让_inputs在lstm中进行一次前向传播
logit = self.soft(self._h[-1]) # linear 从隐藏层embedd得到可选的层的逻辑评分
if self.temperature is not None:
logit /= self.temperature # 一个常量 貌似是RL中的trick
if self.tanh_constant is not None:
# tanh_constant * tanh(logits) 用tanh再激活一次(可选)
logit = self.tanh_constant * torch.tanh(logit)
if mutable.key in self.bias_dict:
logit += self.bias_dict[mutable.key]
# 对卷积层进行了偏好处理,如果是卷积层,那就在对应的值加上一个0.25,增大被选中的概率
# softmax, view(-1),
branch_id = torch.multinomial(F.softmax(logit, dim=-1), 1).view(-1)
# 依据概率来选下角标,如果数量不为1,选择的多个中没有重复的
# eg: [100,1,1] 最有可能选择100对应的下标0
log_prob = self.cross_entropy_loss(logit, branch_id) # 交叉熵损失函数 - 判断logit和branchid分布是否相似程度
self.sample_log_prob += self.entropy_reduction(log_prob) # 求和或者求平均
entropy = (log_prob * torch.exp(-log_prob)).detach() # pylint: disable=invalid-unary-operand-type ??
self.sample_entropy += self.entropy_reduction(entropy) # 样本熵?
self._inputs = self.embedding(branch_id) # 得到对应id的embedding, 从选择空间 - 映射到 - 隐空间
return F.one_hot(branch_id, num_classes=self.max_layer_choice).bool().view(-1) # 将选择变成one_hot向量
这部分是EnasMutator中一个核心函数,实现的是REINFORCE算法。
if self.entropy_weight: # 交叉熵权重
reward += self.entropy_weight * self.mutator.sample_entropy.item() # 得到样本熵
6. 总结
ENAS核心就是提出了一个超网,每次从超网中采样一个小的网络进行训练。所有的子网络都是共享超网中的一套参数,这样每次训练就不是从头开始训练,而是进行了迁移学习,加快了训练速度。
有注释代码链接如下:https://github.com/pprp/SimpleCVReproduction/tree/master/nni

 浙公网安备 33010602011771号
浙公网安备 33010602011771号