【从零开始学CenterNet】1. pytorch版CenterNet训练自己的数据集
CenterNet(Objects as points)已经有一段时间了,之前这篇文章-【目标检测Anchor-Free】CVPR 2019 Object as Points(CenterNet)中讲解了CenterNet的原理,可以回顾一下。
这篇文章是基于非官方的CenterNet实现,https://github.com/zzzxxxttt/pytorch_simple_CenterNet_45,这个版本的实现更加简单,基于官方版本(https://github.com/xingyizhou/CenterNet)进行修改,要比官方代码更适合阅读和理解,dataloader、hourglass、训练流程等原版中比较复杂的部分都进行了重写,最终要比官方的速度更快。
这篇博文主要讲解如何用这个版本的CenterNet训练自己的VOC数据集,环境的配置。
1. 环境配置
环境要求:
- python>=3.5
- pytorch==0.4.1or 1.1.0 or 1.0.0(笔者用的1.0.0也可以)
- tensorboardX(可选)
配置:
- 将cudnn的batch norm关闭。打开torch/nn/functional.py文件,找到torch.batch_norm这一行,将
torch.backends.cudnn.enabled选项更改为False。 - 克隆项目
CenterNet_ROOT=/path/to/clone/CenterNet
git clone https://github.com/zzzxxxttt/pytorch_simple_CenterNet_45 $CenterNet_ROOT
- 安装cocoAPI
cd $CenterNet_ROOT/lib/cocoapi/PythonAPI
make
python setup.py install --user
- 编译可变形卷积DCN
- 如果使用的是pytorch0.4.1, 将
$CenterNet_ROOT/lib/DCNv2_old复制为$CenterNet_ROOT/lib/DCNv2 - 如果使用的是pytorch1.1.0 or 1.0.0, 将
$CenterNet_ROOT/lib/DCNv2_new复制为$CenterNet_ROOT/lib/DCNv2. - 然后开始编译
cd $CenterNet_ROOT/lib/DCNv2
./make.sh
- 编译NMS
cd $CenterNet_ROOT/lib/nms
make
-
对于COCO格式的数据集,下载链接在:http://cocodataset.org/#download。将annotations, train2017, val2017, test2017放在
$CenterNet_ROOT/data/coco -
对于Pascal VOC格式的数据集,下载VOC转为COCO以后的数据集:
百度网盘链接:https://pan.baidu.com/share/init?surl=z6BtsKPHh2MnbfT25Y4wYw 密码:4iu2
下载以后将annotations, images, VOCdevkit放在$CenterNet_ROOT/data/voc
PS:以上两者是官方数据集,如果制作自己的数据集的话可以往下看。
- 如果选择Hourglass-104作为骨干网络,下载CornerNet预训练模型:
百度网盘链接:https://pan.baidu.com/s/1tp9-5CAGwsX3VUSdV276Fg 密码: y1z4
将下载的权重checkpoint.t7放到$CenterNet_ROOT/ckpt/pretrain中。
2. 配置自己的数据集
这个版本提供的代码是针对官方COCO或者官方VOC数据集进行配置的,所以有一些细节需要修改。
由于笔者习惯VOC格式数据集,所以以Pascal VOC格式为例,修改自己的数据集。
笔者只有一个类,‘dim target’,所以按照一个类来修改,其他的类别也很容易修改。
2.1 VOC类别修改
- 将datasets/pascal.py中16行内容:
VOC_NAMES = ['__background__', "aeroplane", "bicycle", "bird", "boat",
"bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog",
"horse", "motorbike", "person", "pottedplant", "sheep", "sofa",
"train", "tvmonitor"]
修改为自己类别的名称:
VOC_NAMES = ['__background__', 'dim target']
- 将datasets/pascal.py中第33行内容:
num_classes=20修改为自己对应的类别个数num_classes=1
- 将datasets/pascal.py中的第35行内容:
self.valid_ids = np.arange(1, 21, dtype=np.int32)中的21修改为类别数目+1
2.2 annotations
VOC格式数据集中没有annotations中所需要的json文件,这部分需要重新构建。
下面是一个VOC转COCO格式的脚本,需要改xml path和json file的名称。
import xml.etree.ElementTree as ET
import os
import json
coco = dict()
coco['images'] = []
coco['type'] = 'instances'
coco['annotations'] = []
coco['categories'] = []
category_set = dict()
image_set = set()
category_item_id = 0
image_id = 20200000000
annotation_id = 0
def addCatItem(name):
global category_item_id
category_item = dict()
category_item['supercategory'] = 'none'
category_item_id += 1
category_item['id'] = category_item_id
category_item['name'] = name
coco['categories'].append(category_item)
category_set[name] = category_item_id
return category_item_id
def addImgItem(file_name, size):
global image_id
if file_name is None:
raise Exception('Could not find filename tag in xml file.')
if size['width'] is None:
raise Exception('Could not find width tag in xml file.')
if size['height'] is None:
raise Exception('Could not find height tag in xml file.')
image_id += 1
image_item = dict()
image_item['id'] = image_id
image_item['file_name'] = file_name
image_item['width'] = size['width']
image_item['height'] = size['height']
coco['images'].append(image_item)
image_set.add(file_name)
return image_id
def addAnnoItem(object_name, image_id, category_id, bbox):
global annotation_id
annotation_item = dict()
annotation_item['segmentation'] = []
seg = []
#bbox[] is x,y,w,h
#left_top
seg.append(bbox[0])
seg.append(bbox[1])
#left_bottom
seg.append(bbox[0])
seg.append(bbox[1] + bbox[3])
#right_bottom
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1] + bbox[3])
#right_top
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1])
annotation_item['segmentation'].append(seg)
annotation_item['area'] = bbox[2] * bbox[3]
annotation_item['iscrowd'] = 0
annotation_item['ignore'] = 0
annotation_item['image_id'] = image_id
annotation_item['bbox'] = bbox
annotation_item['category_id'] = category_id
annotation_id += 1
annotation_item['id'] = annotation_id
coco['annotations'].append(annotation_item)
def parseXmlFiles(xml_path):
for f in os.listdir(xml_path):
if not f.endswith('.xml'):
continue
real_file_name = f.split(".")[0] + ".jpg"
bndbox = dict()
size = dict()
current_image_id = None
current_category_id = None
file_name = None
size['width'] = None
size['height'] = None
size['depth'] = None
xml_file = os.path.join(xml_path, f)
print(xml_file)
tree = ET.parse(xml_file)
root = tree.getroot()
if root.tag != 'annotation':
raise Exception(
'pascal voc xml root element should be annotation, rather than {}'
.format(root.tag))
#elem is <folder>, <filename>, <size>, <object>
for elem in root:
current_parent = elem.tag
current_sub = None
object_name = None
if elem.tag == 'folder':
continue
if elem.tag == 'filename':
file_name = real_file_name #elem.text
if file_name in category_set:
raise Exception('file_name duplicated')
#add img item only after parse <size> tag
elif current_image_id is None and file_name is not None and size[
'width'] is not None:
# print(file_name, "===", image_set)
if file_name not in image_set:
current_image_id = addImgItem(file_name, size)
print('add image with {} and {}'.format(file_name, size))
else:
pass
# raise Exception('duplicated image: {}'.format(file_name))
#subelem is <width>, <height>, <depth>, <name>, <bndbox>
for subelem in elem:
bndbox['xmin'] = None
bndbox['xmax'] = None
bndbox['ymin'] = None
bndbox['ymax'] = None
current_sub = subelem.tag
if current_parent == 'object' and subelem.tag == 'name':
object_name = subelem.text
if object_name not in category_set:
current_category_id = addCatItem(object_name)
else:
current_category_id = category_set[object_name]
elif current_parent == 'size':
if size[subelem.tag] is not None:
raise Exception('xml structure broken at size tag.')
size[subelem.tag] = int(subelem.text)
#option is <xmin>, <ymin>, <xmax>, <ymax>, when subelem is <bndbox>
for option in subelem:
if current_sub == 'bndbox':
if bndbox[option.tag] is not None:
raise Exception(
'xml structure corrupted at bndbox tag.')
bndbox[option.tag] = int(option.text)
#only after parse the <object> tag
if bndbox['xmin'] is not None:
if object_name is None:
raise Exception('xml structure broken at bndbox tag')
if current_image_id is None:
raise Exception('xml structure broken at bndbox tag')
if current_category_id is None:
raise Exception('xml structure broken at bndbox tag')
bbox = []
#x
bbox.append(bndbox['xmin'])
#y
bbox.append(bndbox['ymin'])
#w
bbox.append(bndbox['xmax'] - bndbox['xmin'])
#h
bbox.append(bndbox['ymax'] - bndbox['ymin'])
print('add annotation with {},{},{},{}'.format(
object_name, current_image_id, current_category_id,
bbox))
addAnnoItem(object_name, current_image_id,
current_category_id, bbox)
if __name__ == '__main__':
xml_path = './annotations/test'
json_file = './pascal_test2020.json'
#'./pascal_trainval0712.json'
parseXmlFiles(xml_path)
json.dump(coco, open(json_file, 'w'))
注意这里json文件的命名要通过datasets/pascal.py中第44到48行的内容确定的。
self.data_dir = os.path.join(data_dir, 'voc')
self.img_dir = os.path.join(self.data_dir, 'images')
_ann_name = {'train': 'trainval0712', 'val': 'test2007'}
self.annot_path = os.path.join(self.data_dir, 'annotations', 'pascal_%s.json' % _ann_name[split])
这里笔者为了方便命名对这些字段进行了修改:
self.data_dir = os.path.join(data_dir, 'voc') # ./data/voc
self.img_dir = os.path.join(self.data_dir, 'images') # ./data/voc/images
_ann_name = {'train': 'train2020', 'val': 'test2020'}
# 意思是需要json格式数据集
self.annot_path = os.path.join(
self.data_dir, 'annotations', 'pascal_%s.json' % _ann_name[split])
所以要求json的命名可以按照以下格式准备:
# ./data/voc/annotations
# - pascal_train2020
# - pascal_test2020
数据集总体格式为:
- data
- voc
- annotations
- pascal_train2020.json
- pascal_test2020.json
- images
- *.jpg
- VOCdevkit(这个文件夹主要是用于测评)
- VOC2007
- Annotations
- *.xml
- JPEGImages
- *.jpg
- ImageSets
- Main
- train.txt
- val.txt
- trainval.txt
- test.txt
2.3 其他
在datasets/pascal.py中21-22行,标准差和方差最好替换为自己的数据集的标准差和方差。
VOC_MEAN = [0.485, 0.456, 0.406]
VOC_STD = [0.229, 0.224, 0.225]
3. 训练和测试
3.1 训练命令
训练命令比较多,可以写一个shell脚本来完成。
python train.py --log_name pascal_resdcn18_384_dp \
--dataset pascal \
--arch resdcn_18 \
--img_size 384 \
--lr 1.25e-4 \
--lr_step 45,60 \
--batch_size 32 \
--num_epochs 70 \
--num_workers 10
log name代表记录的日志的名称。
dataset设置pascal代表使用的是pascal voc格式。
arch代表选择的backbone的类型,有以下几种:
- large_hourglass
- small_hourglass
- resdcn_18
- resdcn_34
- resdcn_50
- resdcn_101
- resdcn_152
img size控制图片长和宽。
lr和lr_step控制学习率大小及变化。
batch size是一个批次处理的图片个数。
num epochs代表学习数据集的总次数。
num workers代表开启多少个线程加载数据集。
3.2 测试命令
测试命令很简单,需要注意的是img size要和训练的时候设置的一致。
python test.py --log_name pascal_resdcn18_384_dp \
--dataset pascal \
--arch resdcn_18 \
--img_size 384
flip test属于TTA(Test Time Augmentation),可以一定程度上提高mAP。
# flip test
python test.py --log_name pascal_resdcn18_384_dp \
--dataset pascal \
--arch resdcn_18 \
--img_size 384 \
--test_flip
4. 结果
以下是作者在COCO和VOC数据集上以不同的图片分辨率和TTA方法得到的结果。
COCO:
| Model | Training image size | mAP |
|---|---|---|
| Hourglass-104 (DP) | 512 | 39.9/42.3/45.0 |
| Hourglass-104 (DDP) | 512 | 40.5/42.6/45.3 |
PascalVOC:
| Model | Training image size | mAP |
|---|---|---|
| ResDCN-18 (DDP) | 384 | 71.19/72.99 |
| ResDCN-18 (DDP) | 512 | 72.76/75.69 |
笔者在自己的数据集上进行了训练,训练log如下:
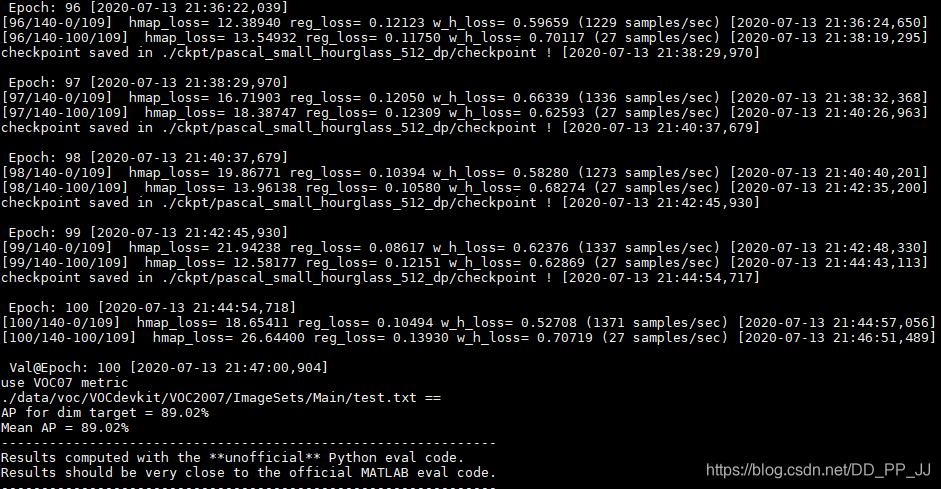
每隔5个epoch将进行一次eval,在自己的数据集上最终可以得到90%左右的mAP。
笔者将已经改好的单类的CenterNet放在Github上:https://github.com/pprp/SimpleCVReproduction/tree/master/Simple_CenterNet
5. 参考
https://github.com/pprp/SimpleCVReproduction/tree/master/Simple_CenterNet

 浙公网安备 33010602011771号
浙公网安备 33010602011771号