论文阅读:Deformable ConvNets v2
论文地址:http://arxiv.org/abs/1811.11168
作者:pprp
时间:2019年5月11日
0. 摘要
DCNv1引入了可变形卷积,能更好的适应目标的几何变换。但是v1可视化结果显示其感受野对应位置超出了目标范围,导致特征不受图像内容影响(理想情况是所有的对应位置分布在目标范围以内)。
为了解决该问题:提出v2, 主要有
- 扩展可变形卷积,增强建模能力
- 提出了特征模拟方案指导网络培训:feature mimicking scheme
结果:性能显著提升,目标检测和分割效果领先。
1. 简介
Geometric variations due to scale, pose, viewpoint and part deformation present a major challenge in object recognition and detection.
目标检测一个主要挑战:尺度,姿势,视角和部件变形引起的几何变化
v1 引入两个模块:
- Deformable Convolution : 可变形卷积
- 通过相对普通卷积基础上添加的偏移解决
- Deformable RoI pooling : 可变形 RoI pooling
- 在RoI pooling 中的bin学习偏移
为了理解可变形卷积,进行了可视化操作:
-
samples for an activation unit tend to cluster around the object on which it lies.
-
激活单元样本点聚集在目标附近
-
但是覆盖范围不够精确,超出the area of interest
由此提出DCNv2, 具有增强建模的能力,可用于学习可变形卷积
with enhanced modeling power for learning deformable convolutions.
添加了两种互补的模式:
- 更广泛应用可变形卷积,在更多层上使用可变形卷积
- 在原有基础上不仅加上偏移(offset),而且加上幅值(amplitude)的控制
为了充分利用可变形卷积提取的信息,吸取知识蒸馏的手段,进行培训。
- 教师网络:R-CNN, 针对裁剪内容进行分类的一个网络,防止学习不在目标范围以外的内容
- 学生网络:Faster R-CNN
2. 可变形卷积行为分析
2.1 空间支持可视化
可视化三个内容:
- 有效感受野 : 可视化感受野
- 有效采样位置: 对采样点求梯度,然后可视化
- 误差界限显著性区域 : 参考显著性分析理论,进行可视化
2.2 可变形网络空间支持
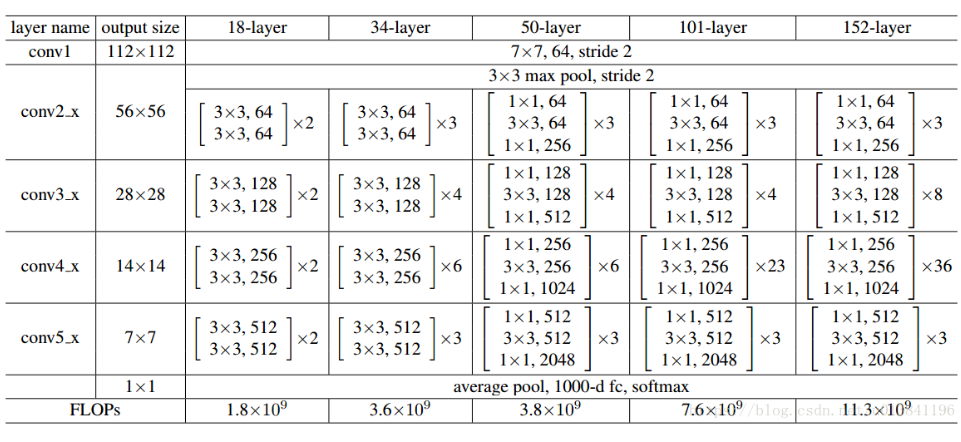
Faster R-CNN中Conv1-Conv4使用在Head中的,Conv5使用在Classification network上

ResNet-50 Conv5里边的3$\times$3的卷积层都使用可变形卷积替换。Aligned RoI pooling 由 Deformable RoI Pooling取代,当offset学习率设置为0,那么Deformable RoI Pooling就退化为Aligned RoI Pooling。 ps: 这是V1中的操作。

从中观察到:
- 常规卷积可以一定程度上模拟几何变化,通过网络权重做到的
- 可变形卷积模拟几何变化能力显著提升,但是不够精确。
3. 更多可变形卷积层
v2 中进行改进的部分主要有三点
3.1 使用更多的可变形卷积
在Conv3, Conv4, Conv5中所有的3$\times$3的卷积层全部被替换掉。对于pascal voc简单数据集,堆叠三层以上就会饱和。
3.2 在DCNv1基础(添加offset)上添加幅值参数
回顾一下DCNv1:

R 是相当于3$\times$3的kernel, \(p_0\)是当前中心点,\(p_n\)枚举每一个点。
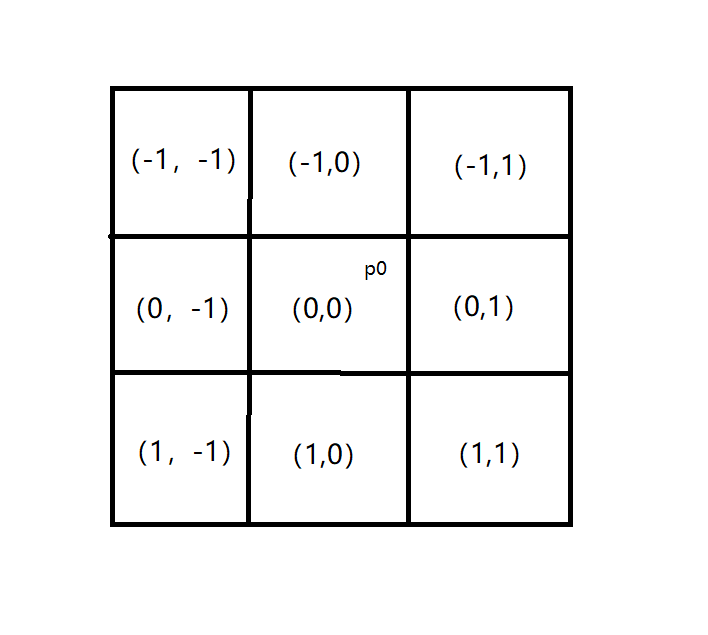
可见,在普通卷积基础上,offset \(\Delta p_n\)是主要改进点。
那DCNv2主要改了哪些地方?
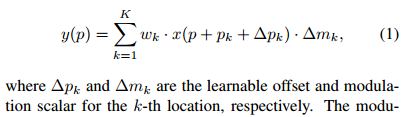
在v1基础上,添加了\(\Delta m_k\), 一个控制幅值变化的量。
ROI pooling是如何改进的?
先看Faster R-CNN中的ROI Pooling:
然后先看DCNv1的Deformable RoI Pooling


主要是添加了offset fields \(\Delta p_{ij}\) 来控制偏移部分。
DCNv2的Deformable RoI Pooling也是将幅值引入,如下图:

类似的也添加了幅值变量,在训练的过程中进行学习。
3.3 R-CNN Feature Mimicking
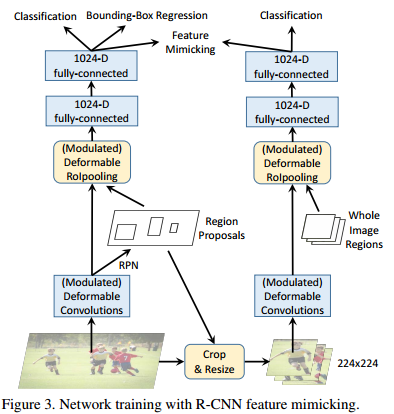
采用了类似知识蒸馏的方法,用一个R-CNN分类网络作为teacher network 帮助Faster R-CNN更好收敛到目标区域内。
得到ROI之后,在原图中抠出这个ROI,resize到224x224,再送到一个RCNN中进行分类,这个RCNN只分类,不回归。然后,主网络fc2的特征去模仿RCNN fc2的特征,实际上就是两者算一个余弦相似度,1减去相似度作为loss即可
代码
GitHub几个源码
-
https://github.com/msracver/Deformable-ConvNets 官方提供的版本,有DeepLab, Faster R-CNN, FPN, R-FCN等。源码使用的是mxnet。
-
https://github.com/open-mmlab/mmdetection 集成了可变形卷积,源码使用的是pytorch。
-
https://github.com/ChunhuanLin/deform_conv_pytorch 测试deform_conv_V1的准确度的demo.py,源码使用的是pytorch。
-
https://github.com/4uiiurz1/pytorch-deform-conv-v2一个简单版本的DCNv2 ,源码使用的是pytorch
-
https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0 Pytorch 1.0 最新的完整的DCNv2
参考文献
https://blog.csdn.net/u013841196/article/details/80713314
http://arxiv.org/abs/1811.11168

 浙公网安备 33010602011771号
浙公网安备 33010602011771号