云计算与大数据入门实验二 —— 熟悉常用的 HDFS(Hadoop) 操作
云计算与大数据入门实验二 —— 熟悉常用的 HDFS(Hadoop) 操作
实验目的
理解HDFS在Hadoop体系结构中的角色
熟练使用HDFS操作常用的Shell命令
熟悉HDFS操作常用的Java API
实验平台
操作系统:Linux(建议Ubuntu16.04)
Hadoop版本:2.10.2
JDK版本:1.7或以上版本
Java IDE:IDEA
实验步骤
- 编程实现以下功能,并利用Hadoop提供的Shell命令完成相同任务
-
向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,则由用户来指定是追加到原有文件末尾还是覆盖原有的文件
-
从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名
-
将HDFS中指定文件的内容输出到终端中
-
显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息
-
给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息
-
提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录
-
提供一个HDFS的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在,则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录
-
向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾
-
删除HDFS中指定的文件
-
在HDFS中,将文件从源路径移动到目的路径
-
编程实现一个类“MyFSDataInputStream”,该类继承“org.apache.hadoop.fs.FSDataInputStream”,要求如下:实现按行读取HDFS中指定文件的方法“readLine()”,如果读到文件末尾,则返回空,否则返回文件一行的文本
-
查看Java帮助手册或其它资料,用“java.net.URL”和“org.apache.hadoop.fs.FsURLStreamHandlerFactory”编程完成输出HDFS中指定文件的文本到终端中
实验内容
编程实现以下功能,并利用Hadoop提供的Shell命令完成相同任务
向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,则由用户来指定是追加到原有文件末尾还是覆盖原有的文件
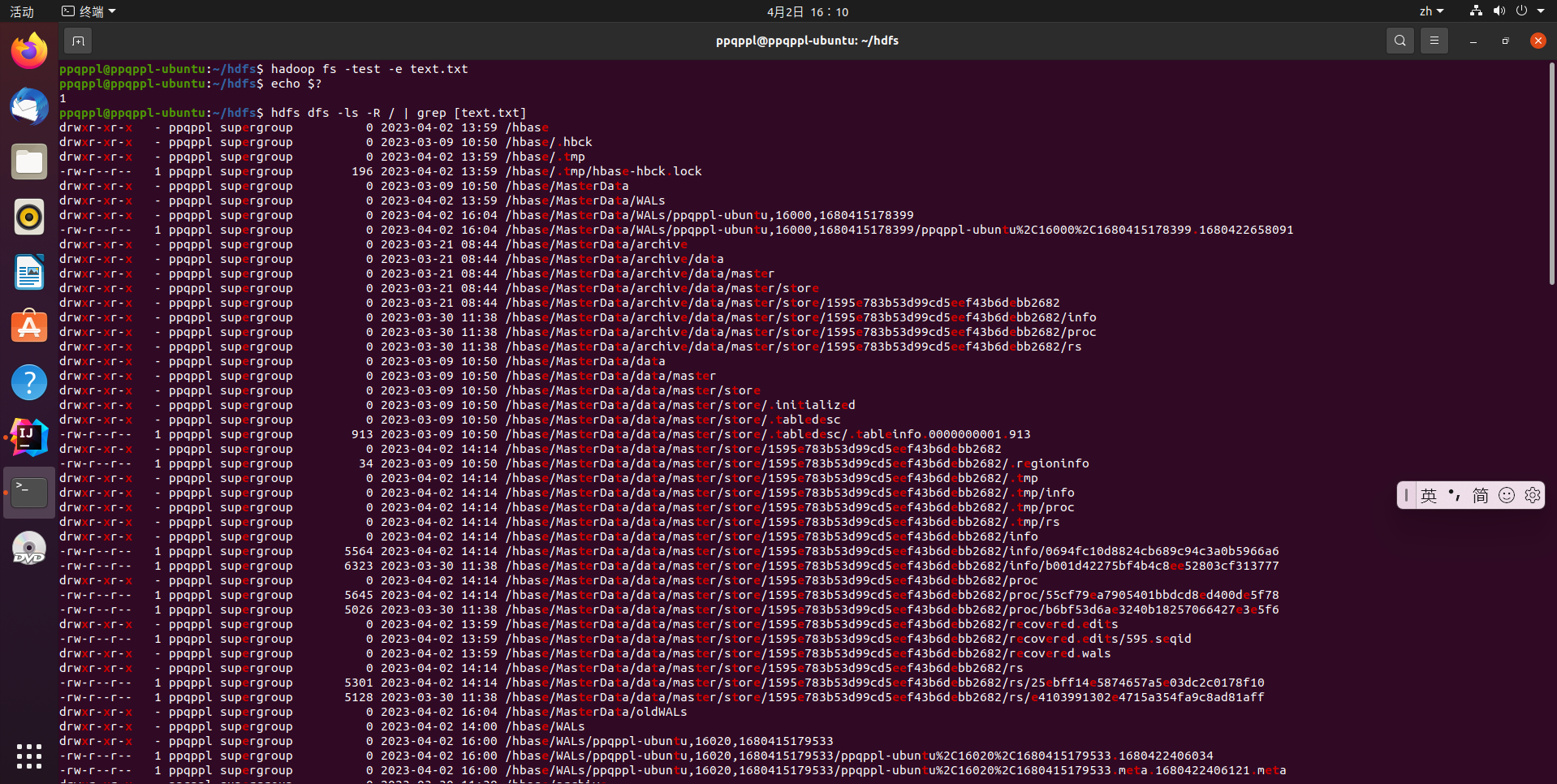
# 检查文件是否存在
hadoop fs -test -e text.txt
# 执行完上述命令不会输出结果,需要继续输入命令查看结果,这里结果为 0 就表示已经存在
echo $?
# 查看文件位置,这里选择匹配字符串
hdfs dfs -ls -R / | grep [text.txt]
文件不存在:
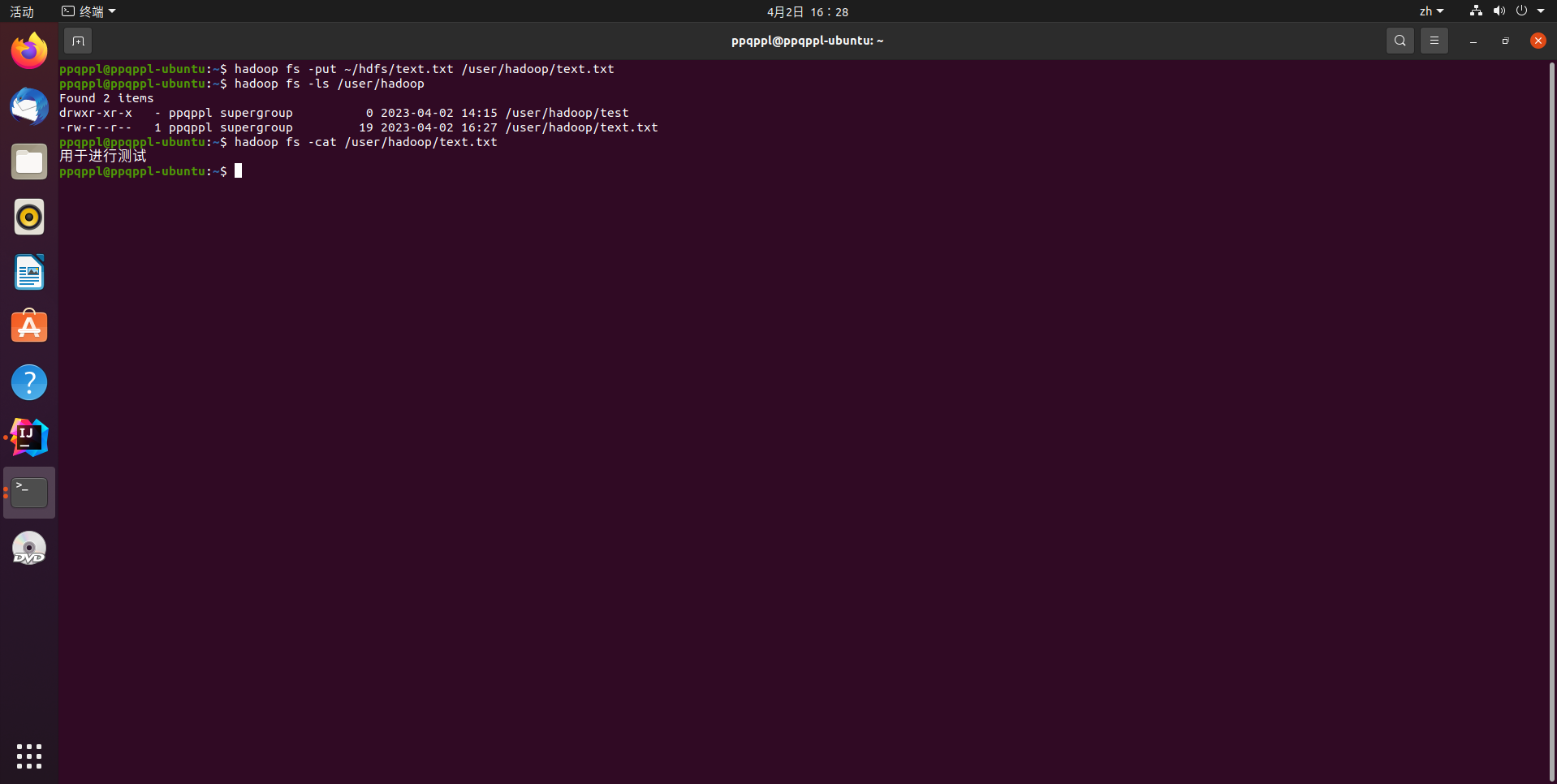
# 直接上传文件
hadoop fs -put ~/hdfs/text.txt /user/hadoop/text.txt
# 检索文件是否存在
hadoop fs -ls /user/hadoop
# 查看文件内容
hadoop fs -cat /user/hadoop/text.txt
文件已经存在:
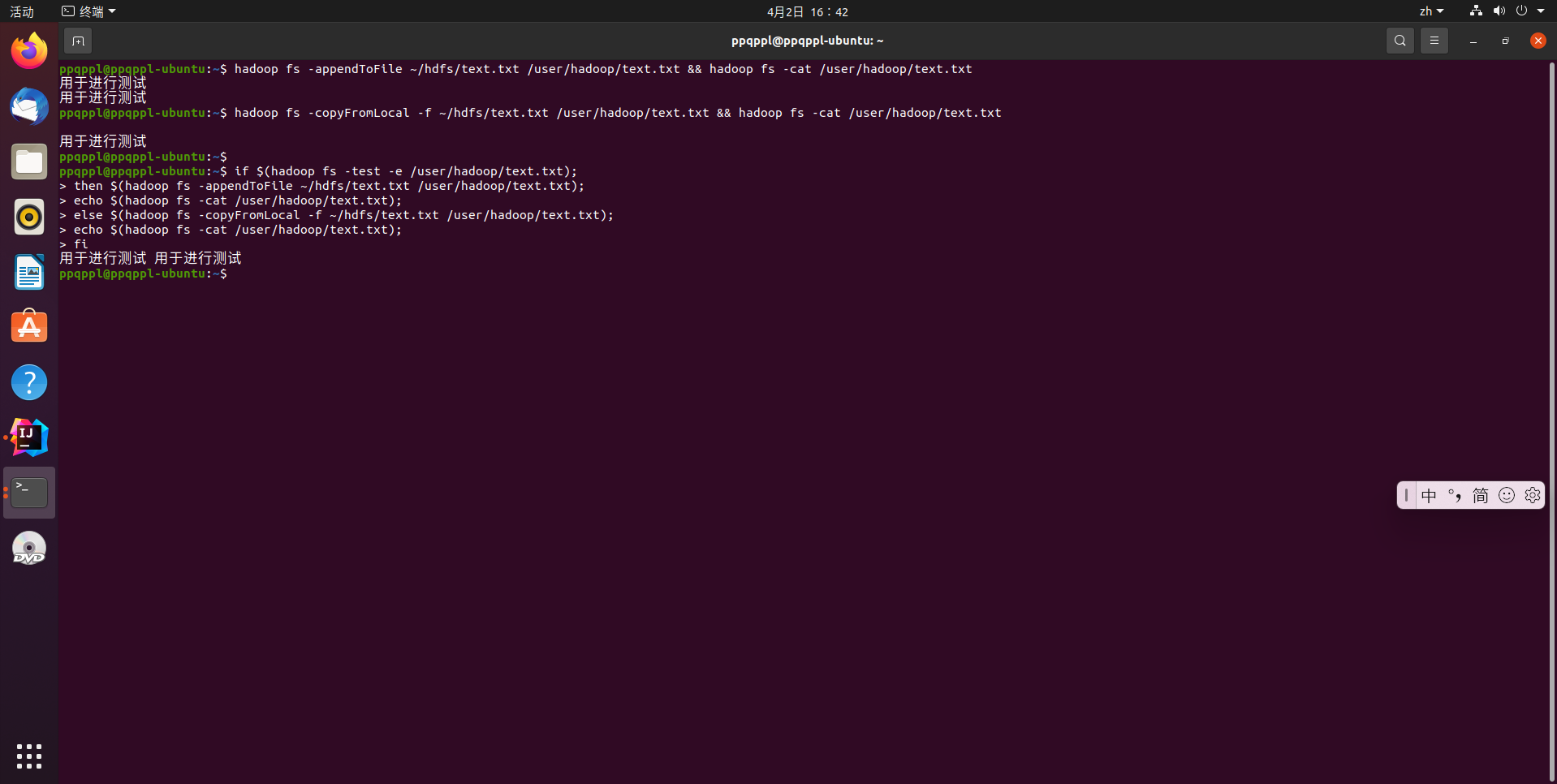
# 方法1 通过命令执行
# 将文件内容追加到源文件末尾
hadoop fs -appendToFile ~/hdfs/text.txt /user/hadoop/text.txt
hadoop fs -cat /user/hadoop/text.txt
# 覆盖源文件
hadoop fs -copyFromLocal -f ~/hdfs/text.txt /user/hadoop/text.txt
hadoop fs -cat /user/hadoop/text.txt
# 方法2 通过 shell 脚本语言执行
if $(hadoop fs -test -e /user/hadoop/text.txt);
then $(hadoop fs -appendToFile ~/hdfs/text.txt /user/hadoop/text.txt);
echo $(hadoop fs -cat /user/hadoop/text.txt);
else $(hadoop fs -copyFromLocal -f ~/hdfs/text.txt /user/hadoop/text.txt);
echo $(hadoop fs -cat /user/hadoop/text.txt);
fi
完整代码如下:
Hadoop.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
public class Hadoop {
/**
* 判断路径是否存在
*/
public static boolean test(Configuration conf, String path) throws IOException {
FileSystem fs = FileSystem.get(conf);
return fs.exists(new Path(path));
}
/**
* 复制文件到指定路径
* 若路径已存在,则进行覆盖
*/
public static void copyFromLocalFile(Configuration conf, String localFilePath, String
remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path localPath = new Path(localFilePath);
Path remotePath = new Path(remoteFilePath);
/* fs.copyFromLocalFile 第一个参数表示是否删除源文件,第二个参数表示是否覆
盖 */
fs.copyFromLocalFile(false, true, localPath, remotePath);
fs.close();
}
/**
* 追加文件内容
*/
public static void appendToFile(Configuration conf, String localFilePath, String
remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
/* 创建一个文件读入流 */
FileInputStream in = new FileInputStream(localFilePath);
/* 创建一个文件输出流,输出的内容将追加到文件末尾 */
FSDataOutputStream out = fs.append(remotePath);
/* 读写文件内容 */
byte[] data = new byte[1024];
int read = -1;
while ((read = in.read(data)) > 0) {
out.write(data, 0, read);
}
out.close();
in.close();
fs.close();
}
}
Main.java
import org.apache.hadoop.conf.Configuration;
public class Main {
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:8088");
String localFilePath = "/home/ppqppl/hdfs/test.txt"; // 本地路径
String remoteFilePath = "/user/hadoop/test.txt"; // HDFS 路径
String choice = "append"; // 若文件存在则追加到文件末尾
// String choice = "overwrite"; // 若文件存在则覆盖
try {
/* 判断文件是否存在 */
Boolean fileExists = false;
if (Hadoop.test(conf, remoteFilePath)) {
fileExists = true;
System.out.println(remoteFilePath + " 已存在.");
} else {
System.out.println(remoteFilePath + " 不存在.");
}
/* 进行处理 */
if ( !fileExists) { // 文件不存在,则上传
Hadoop.copyFromLocalFile(conf, localFilePath, remoteFilePath);
System.out.println(localFilePath + " 已上传至 " + remoteFilePath);
} else if ( choice.equals("overwrite") ) { // 选择覆盖
Hadoop.copyFromLocalFile(conf, localFilePath, remoteFilePath);
System.out.println(localFilePath + " 已覆盖 " + remoteFilePath);
} else if ( choice.equals("append") ) { // 选择追加
Hadoop.appendToFile(conf, localFilePath, remoteFilePath);
System.out.println(localFilePath + " 已追加至 " + remoteFilePath);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
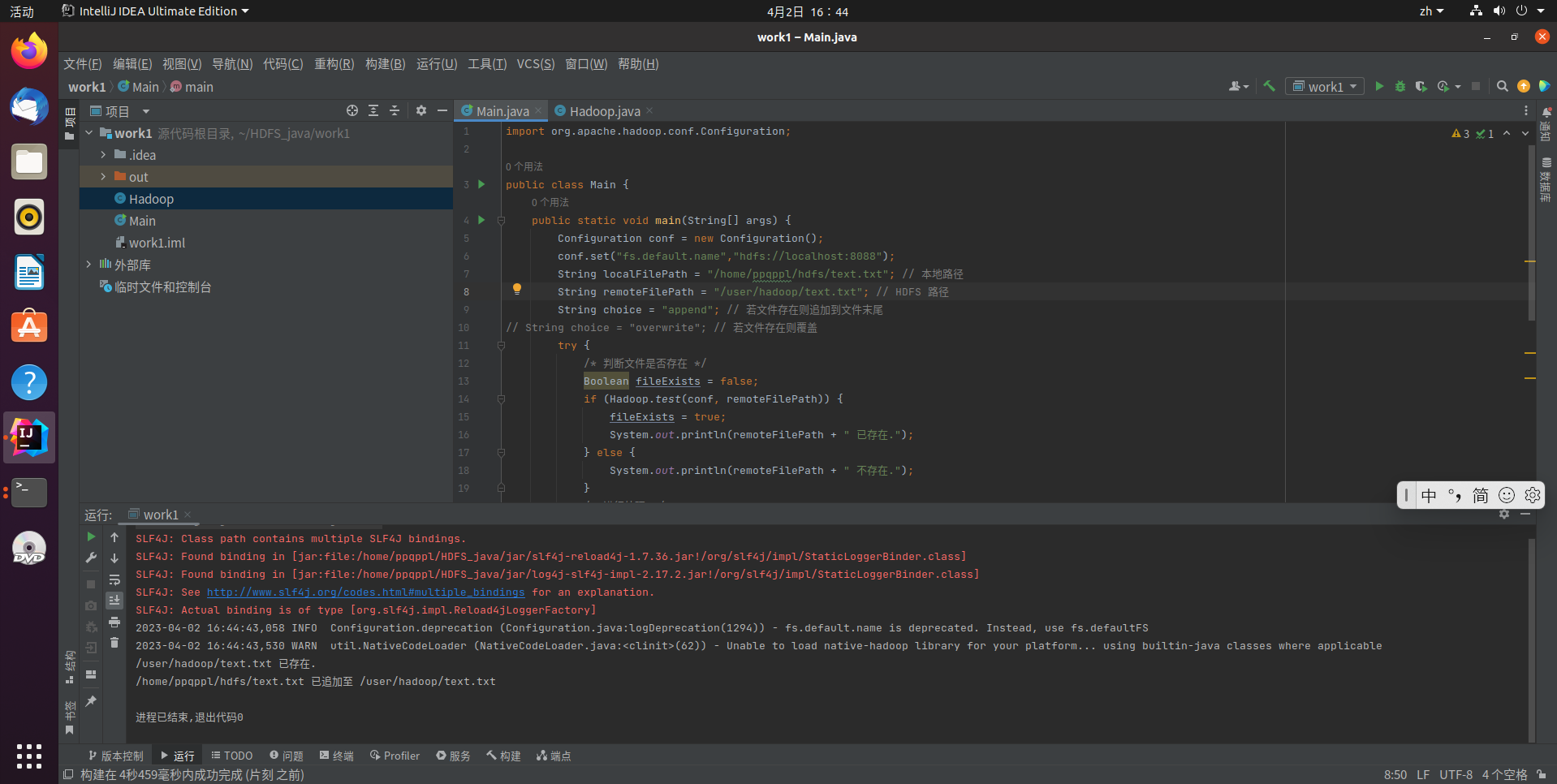
代码运行结果:
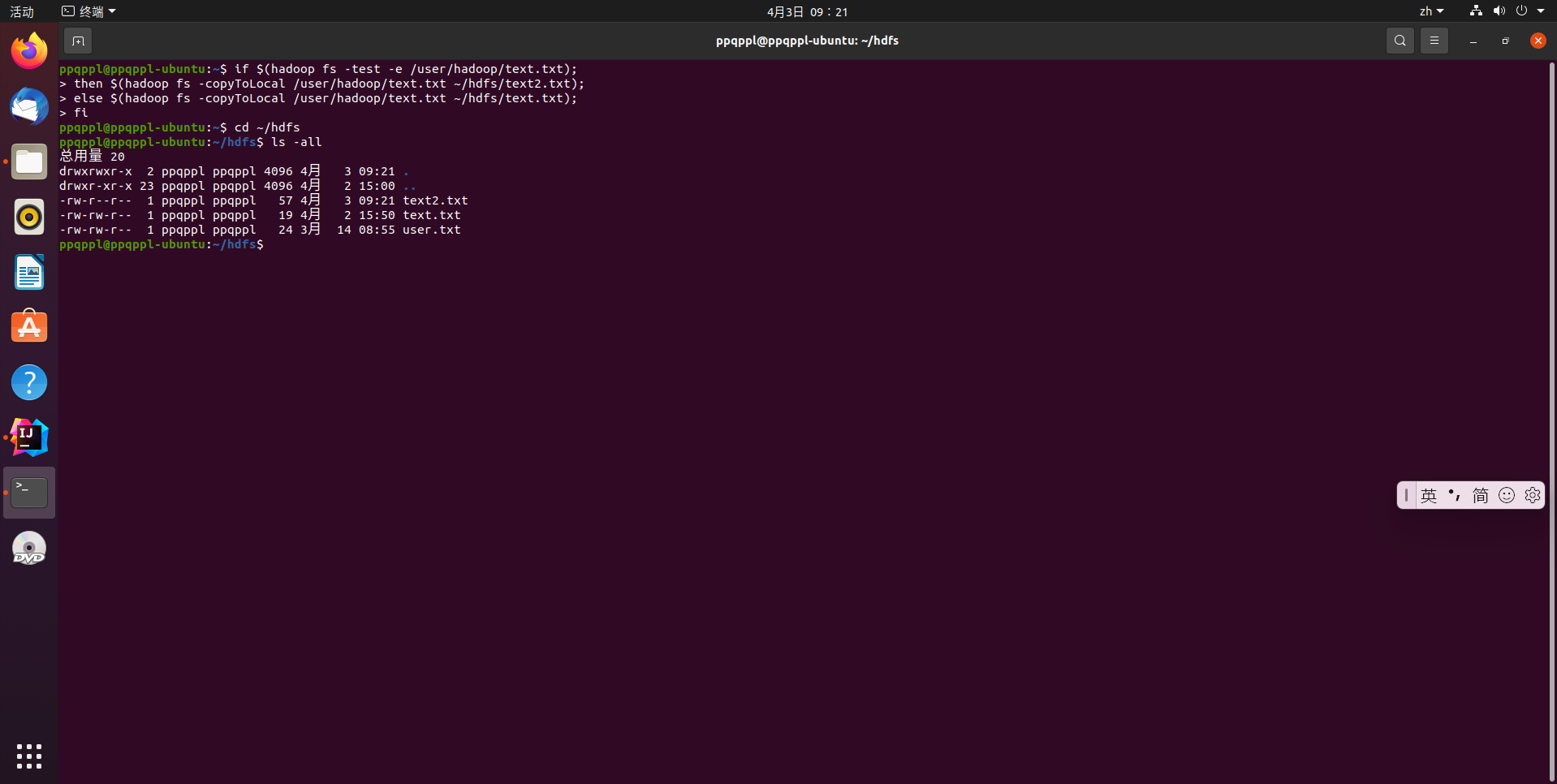
从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名
# 这里使用shell脚本的方法
if $(hadoop fs -test -e /user/hadoop/text.txt);
then $(hadoop fs -copyToLocal /user/hadoop/text.txt ~/hdfs/text2.txt);
else $(hadoop fs -copyToLocal /user/hadoop/text.txt ~/hdfs/text.txt);
fi
完整代码如下:
Hadoop.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
public class Hadoop {
/**
* 下载文件到本地
* 判断本地路径是否已存在,若已存在,则自动进行重命名
*/
public static void copyToLocal(Configuration conf, String remoteFilePath, String
localFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
File f = new File(localFilePath);
/* 如果文件名存在,自动重命名(在文件名后面加上 _0, _1 ...) */
if (f.exists()) {
System.out.println(localFilePath + " 已存在.");
Integer i = 0;
while (true) {
f = new File(localFilePath + "_" + i.toString());
if (!f.exists()) {
localFilePath = localFilePath + "_" + i.toString();
break;
}
}
System.out.println("将重新命名为: " + localFilePath);
}
// 下载文件到本地
Path localPath = new Path(localFilePath);
fs.copyToLocalFile(remotePath, localPath);
fs.close();
}
}
Main.java
import org.apache.hadoop.conf.Configuration;
public class Main {
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:8088");
String localFilePath = "~/hdfs/text.txt"; // 本地路径
String remoteFilePath = "/user/hadoop/text.txt"; // HDFS 路径
try {
Hadoop2.copyToLocal(conf, remoteFilePath, localFilePath);
System.out.println("下载完成");
} catch (Exception e) {
e.printStackTrace();
}
}
}
代码运行结果:
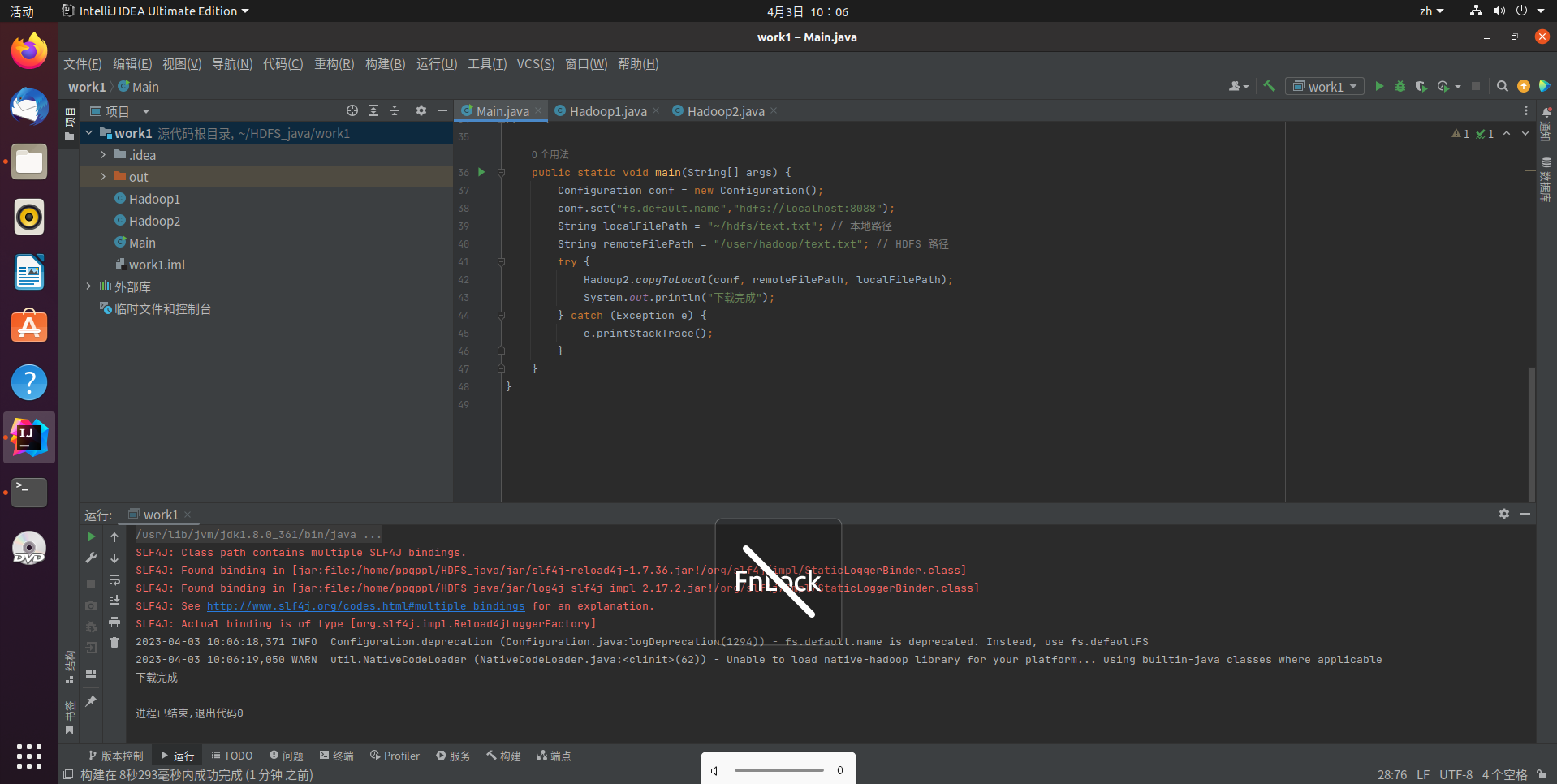
将HDFS中指定文件的内容输出到终端中
hadoop fs -cat /user/hadoop/text.txt
完整代码如下:
Hadoop3.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
public class Hadoop3 {
/**
* 读取文件内容
*/
public static void cat(Configuration conf, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
FSDataInputStream in = fs.open(remotePath);
BufferedReader d = new BufferedReader(new InputStreamReader(in));
String line = null;
while ((line = d.readLine()) != null) {
System.out.println(line);
}
d.close();
in.close();
fs.close();
}
}
Main.java
import org.apache.hadoop.conf.Configuration;
public class Main {
public static void main(String[] args) { // Hadoop3
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://localhost:8088");
String remoteFilePath = "/user/hadoop/text.txt"; // HDFS 路径
try {
System.out.println("读取文件: " + remoteFilePath);
Hadoop3.cat(conf, remoteFilePath);
System.out.println("\n 读取完成");
} catch (Exception e) {
e.printStackTrace();
}
}
}
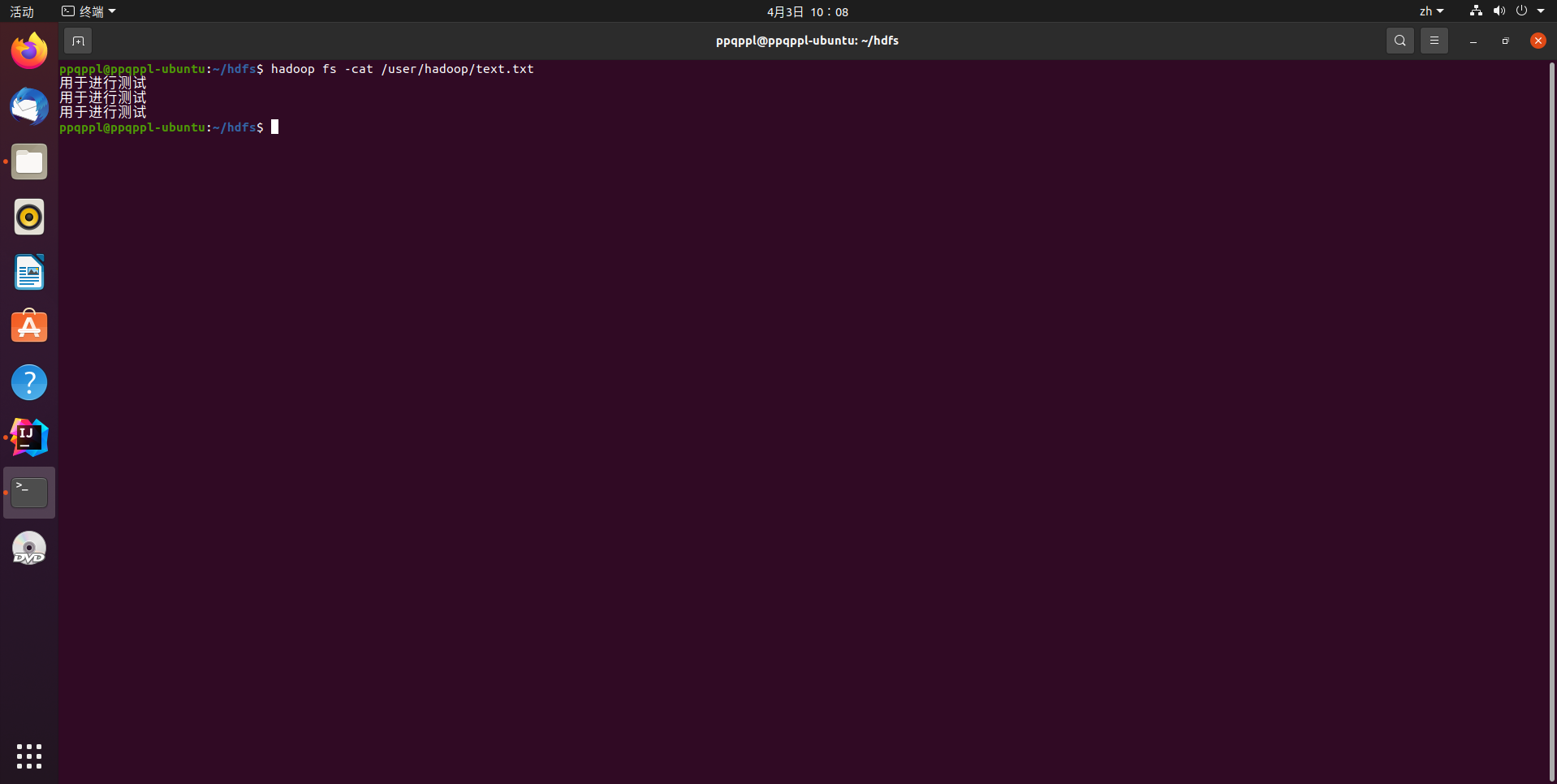
代码运行结果:
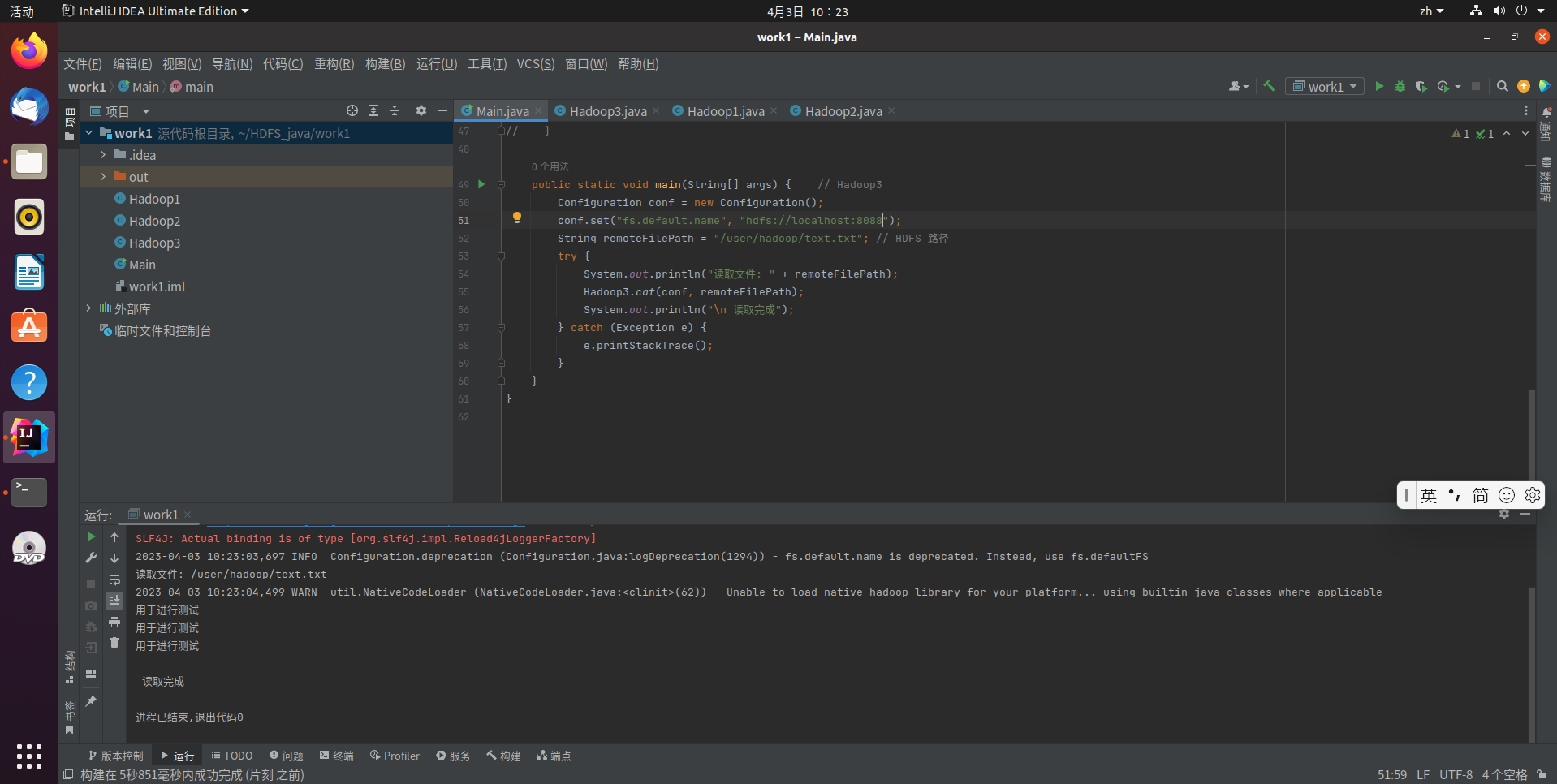
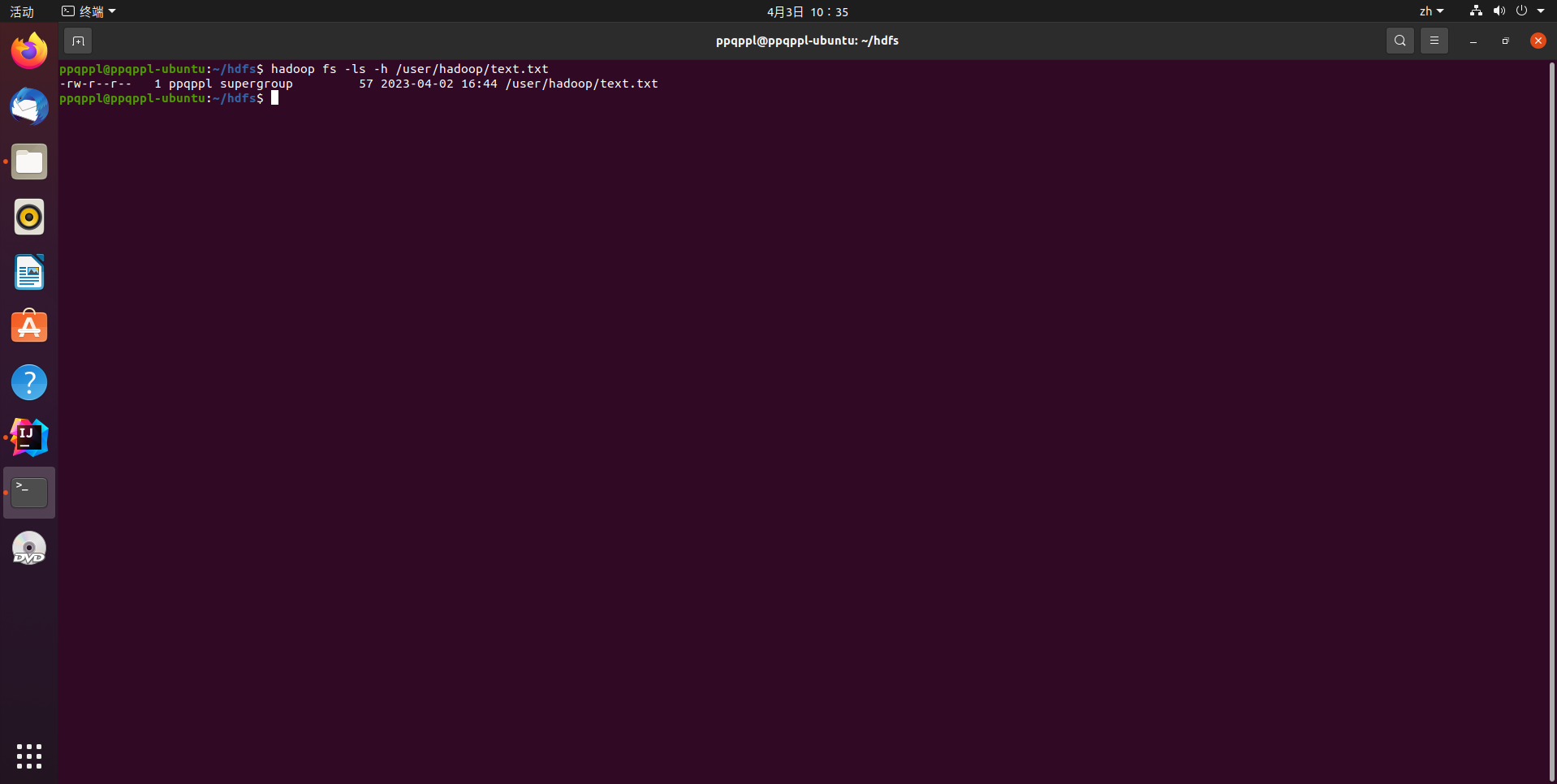
显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息
hadoop fs -ls -h /user/hadoop/text.txt
完整代码如下:
Hadoop4.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
import java.text.SimpleDateFormat;
public class Hadoop4 {
/**
* 显示指定文件的信息
*/
public static void ls(Configuration conf, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
FileStatus[] fileStatuses = fs.listStatus(remotePath);
for (FileStatus s : fileStatuses) {
System.out.println("路径: " + s.getPath().toString());
System.out.println("权限: " + s.getPermission().toString());
System.out.println("大小: " + s.getLen());
/* 返回的是时间戳,转化为时间日期格式 */
Long timeStamp = s.getModificationTime();
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String date = format.format(timeStamp);
System.out.println("时间: " + date);
}
fs.close();
}
}
Main.java
import org.apache.hadoop.conf.Configuration;
public class Main {
public static void main(String[] args) { // Hadoop4
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://localhost:8088");
String remoteFilePath = "/user/hadoop/text.txt"; // HDFS 路径
try {
System.out.println("读取文件信息: " + remoteFilePath);
Hadoop4.ls(conf, remoteFilePath);
System.out.println("\n 读取完成");
} catch (Exception e) {
e.printStackTrace();
}
}
}
代码运行结果:
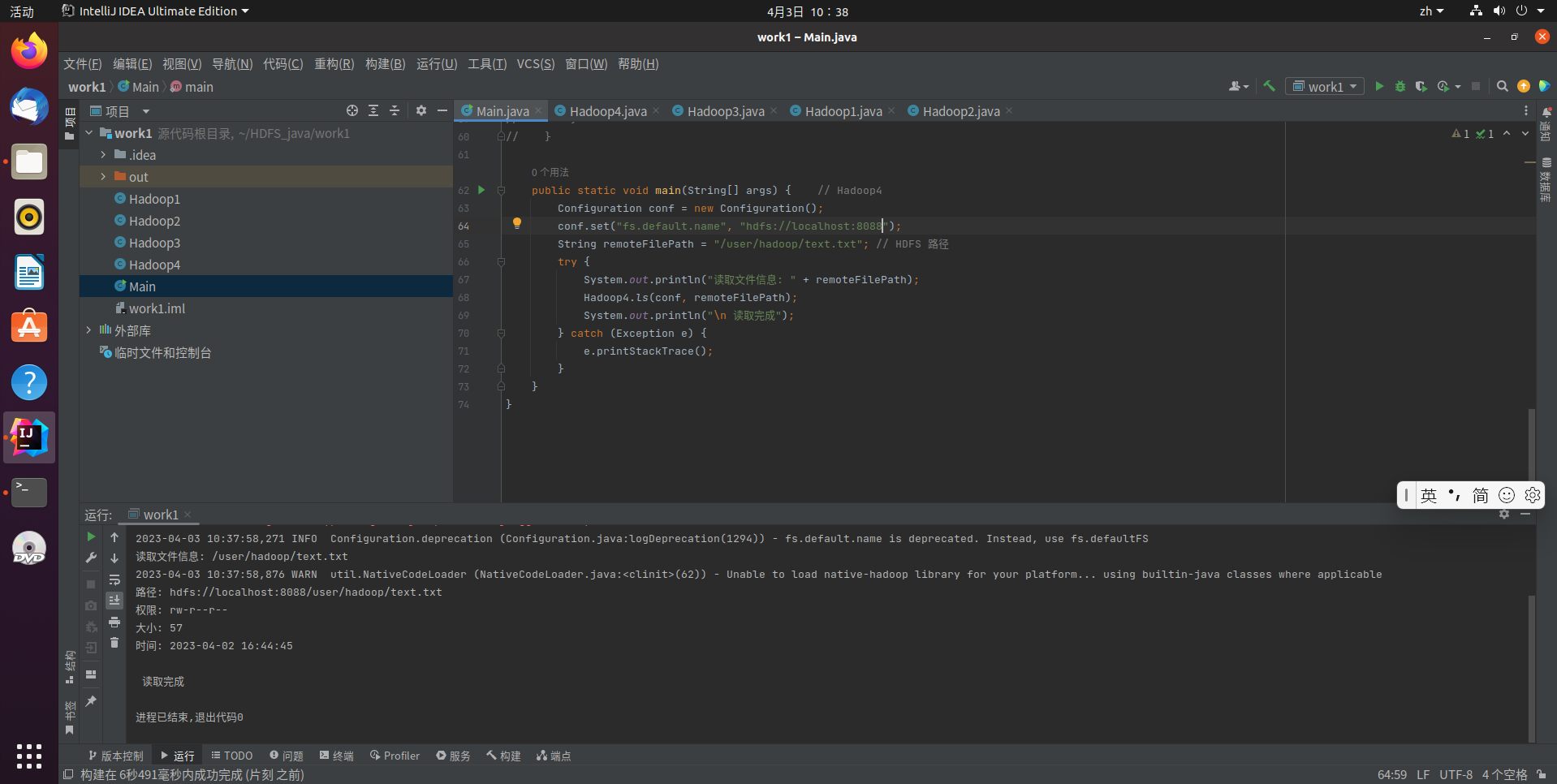
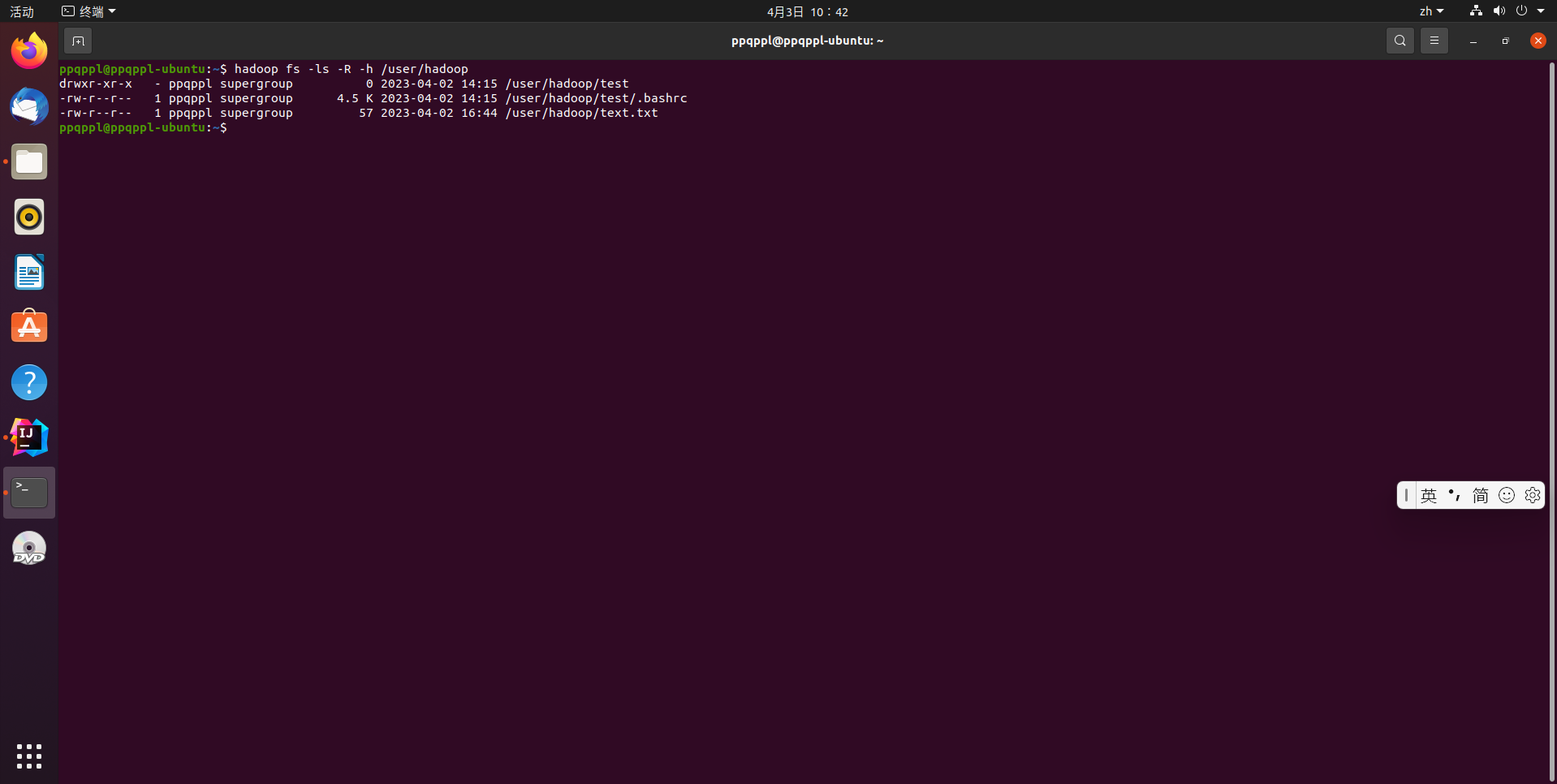
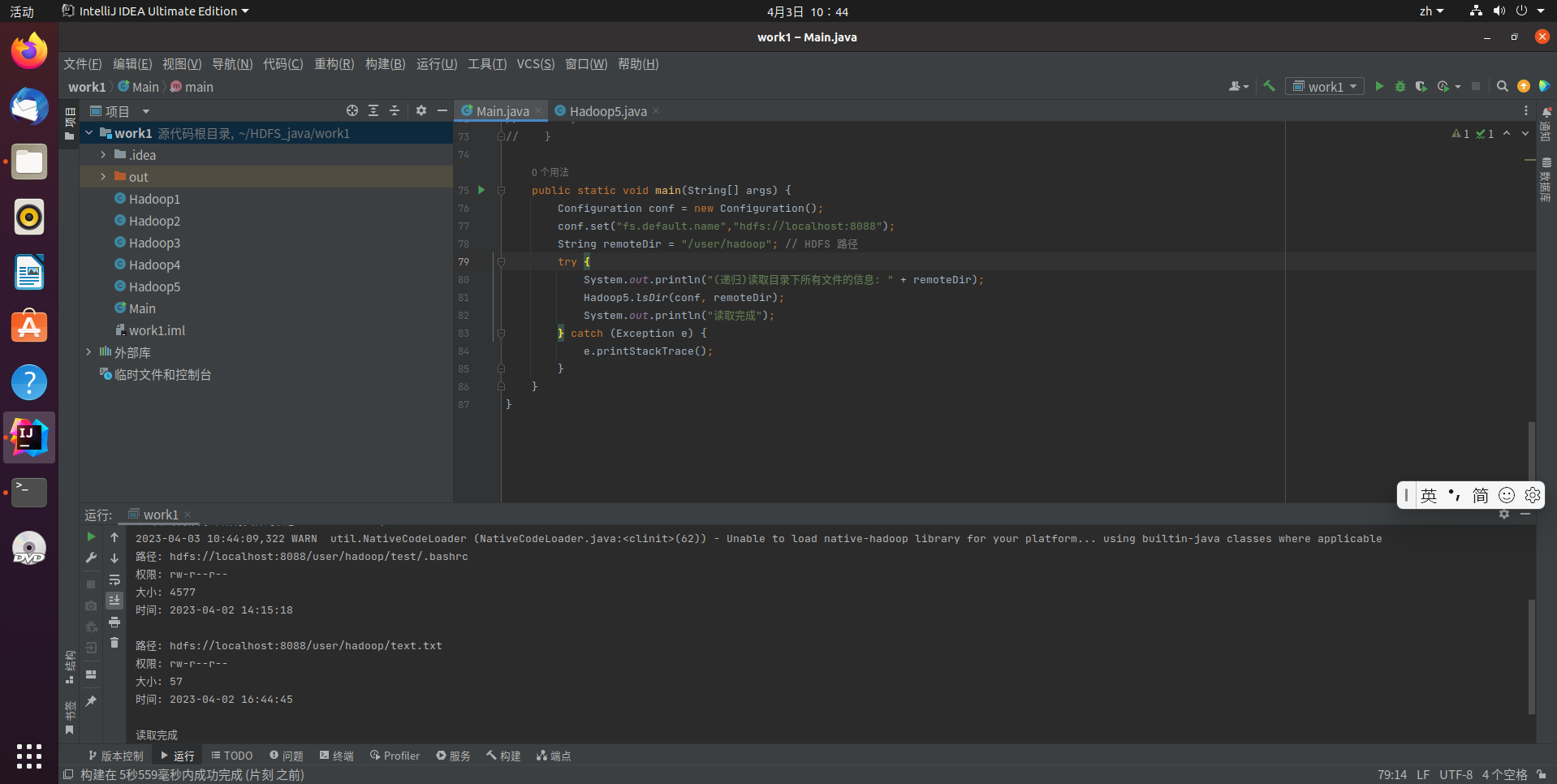
给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息
hadoop fs -ls -R -h /user/hadoop
完整代码如下:
Hadoop5.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
import java.text.SimpleDateFormat;
public class Hadoop5 {
/**
* 显示指定文件夹下所有文件的信息(递归)
*/
public static void lsDir(Configuration conf, String remoteDir) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path dirPath = new Path(remoteDir);
/* 递归获取目录下的所有文件 */
RemoteIterator<LocatedFileStatus> remoteIterator = fs.listFiles(dirPath, true);
/* 输出每个文件的信息 */
while (remoteIterator.hasNext()) {
FileStatus s = remoteIterator.next();
System.out.println("路径: " + s.getPath().toString());
System.out.println("权限: " + s.getPermission().toString());
System.out.println("大小: " + s.getLen());
/* 返回的是时间戳,转化为时间日期格式 */
Long timeStamp = s.getModificationTime();
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String date = format.format(timeStamp);
System.out.println("时间: " + date);
System.out.println();
}
fs.close();
}
}
Main.java
import org.apache.hadoop.conf.Configuration;
public class Main {
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:8088");
String remoteDir = "/user/hadoop"; // HDFS 路径
try {
System.out.println("(递归)读取目录下所有文件的信息: " + remoteDir);
Hadoop5.lsDir(conf, remoteDir);
System.out.println("读取完成");
} catch (Exception e) {
e.printStackTrace();
}
}
}
代码运行结果:
提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录
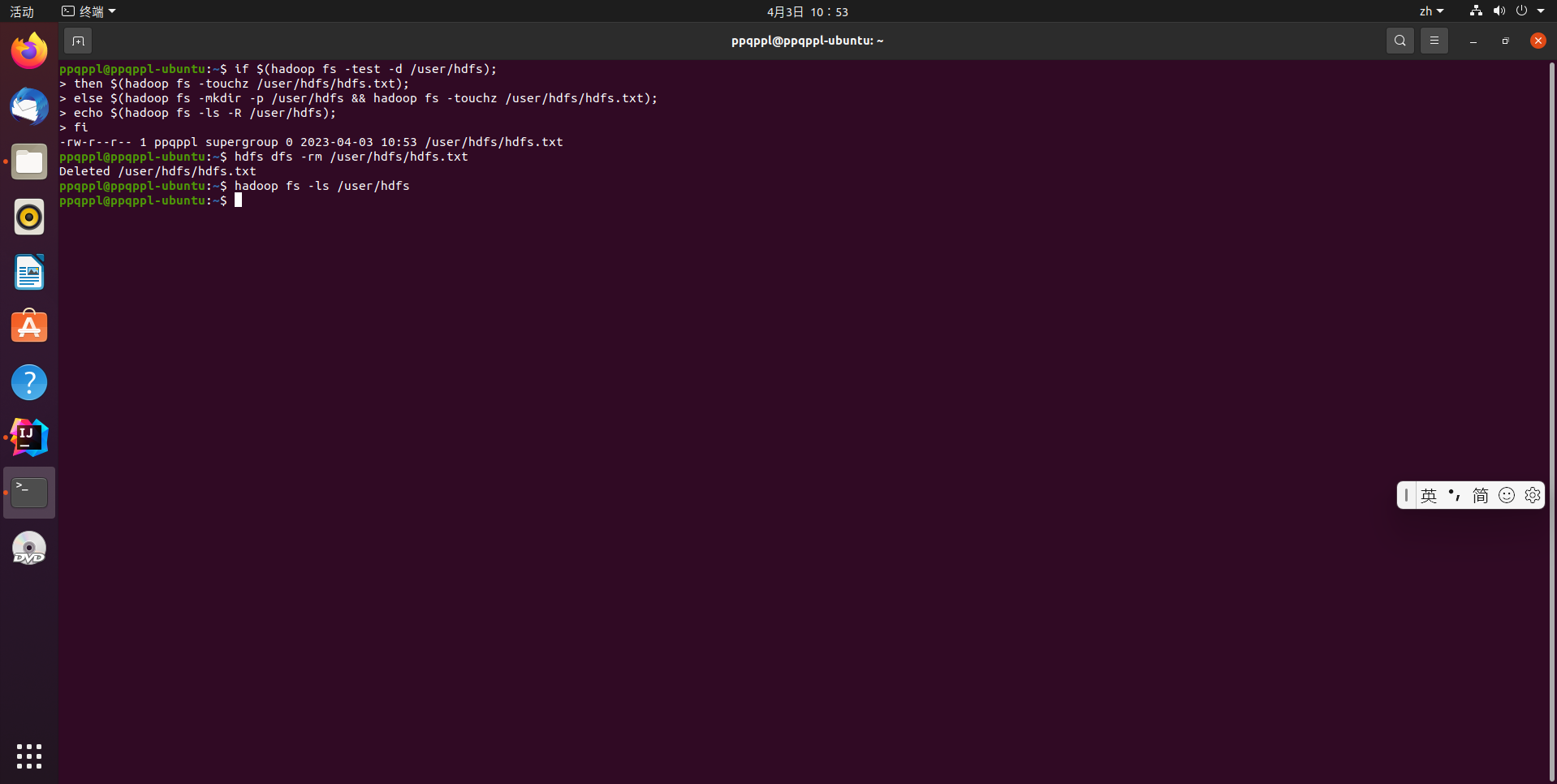
if $(hadoop fs -test -d /user/hdfs);
then $(hadoop fs -touchz /user/hdfs/hdfs.txt);
else $(hadoop fs -mkdir -p /user/hdfs && hadoop fs -touchz /user/hdfs/hdfs.txt);
echo $(hadoop fs -ls -R /user/hdfs);
fi
hdfs dfs -rm /user/hdfs/hdfs.txt
hadoop fs -ls /user/hdfs
完整代码如下:
Hadoop6.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
public class Hadoop6 {
/**
* 判断路径是否存在
*/
public static boolean test(Configuration conf, String path) throws IOException {
FileSystem fs = FileSystem.get(conf);
return fs.exists(new Path(path));
}
/**
* 创建目录
*/
public static boolean mkdir(Configuration conf, String remoteDir) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path dirPath = new Path(remoteDir);
boolean result = fs.mkdirs(dirPath);
fs.close();
return result;
}
/**
* 创建文件
*/
public static void touchz(Configuration conf, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
FSDataOutputStream outputStream = fs.create(remotePath);
outputStream.close();
fs.close();
}
/**
* 删除文件
*/
public static boolean rm(Configuration conf, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
boolean result = fs.delete(remotePath, false);
fs.close();
return result;
}
}
Main.java
import org.apache.hadoop.conf.Configuration;
public class Main {
public static void main(String[] args) { // Hadoop6
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:8088");
String remoteFilePath = "/user/hadoop/input/text.txt"; // HDFS 路径
String remoteDir = "/user/hadoop/input"; // HDFS 路径对应的目录
try {
/* 判断路径是否存在,存在则删除,否则进行创建 */
if ( Hadoop6.test(conf, remoteFilePath) ) {
Hadoop6.rm(conf, remoteFilePath); // 删除
System.out.println("删除路径: " + remoteFilePath);
} else {
if ( !Hadoop6.test(conf, remoteDir) ) { // 若目录不存在,则进行创建
Hadoop6.mkdir(conf, remoteDir);
System.out.println("创建文件夹: " + remoteDir);
}
Hadoop6.touchz(conf, remoteFilePath);
System.out.println("创建路径: " + remoteFilePath);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
代码运行结果:
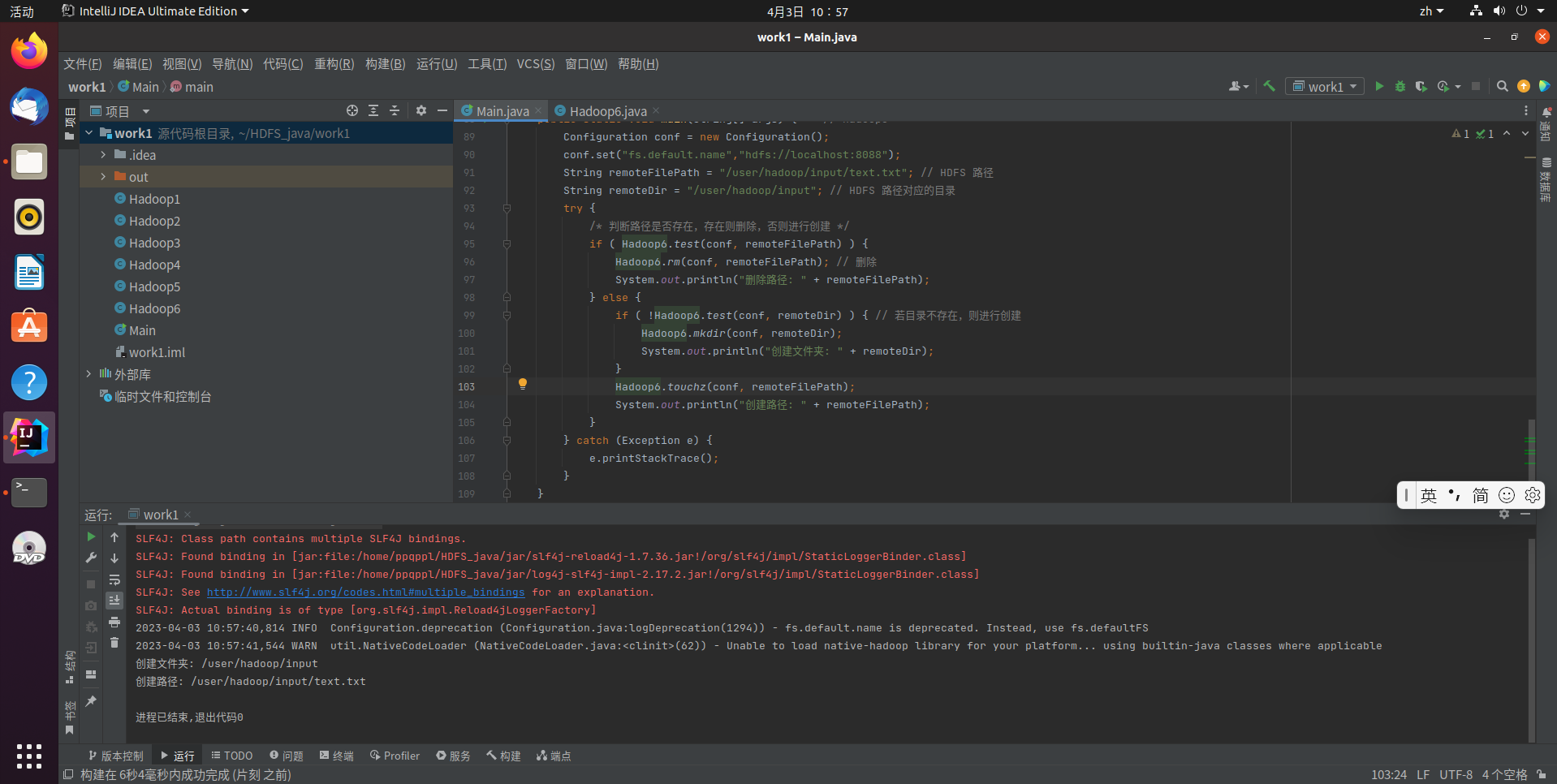
提供一个HDFS的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在,则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录
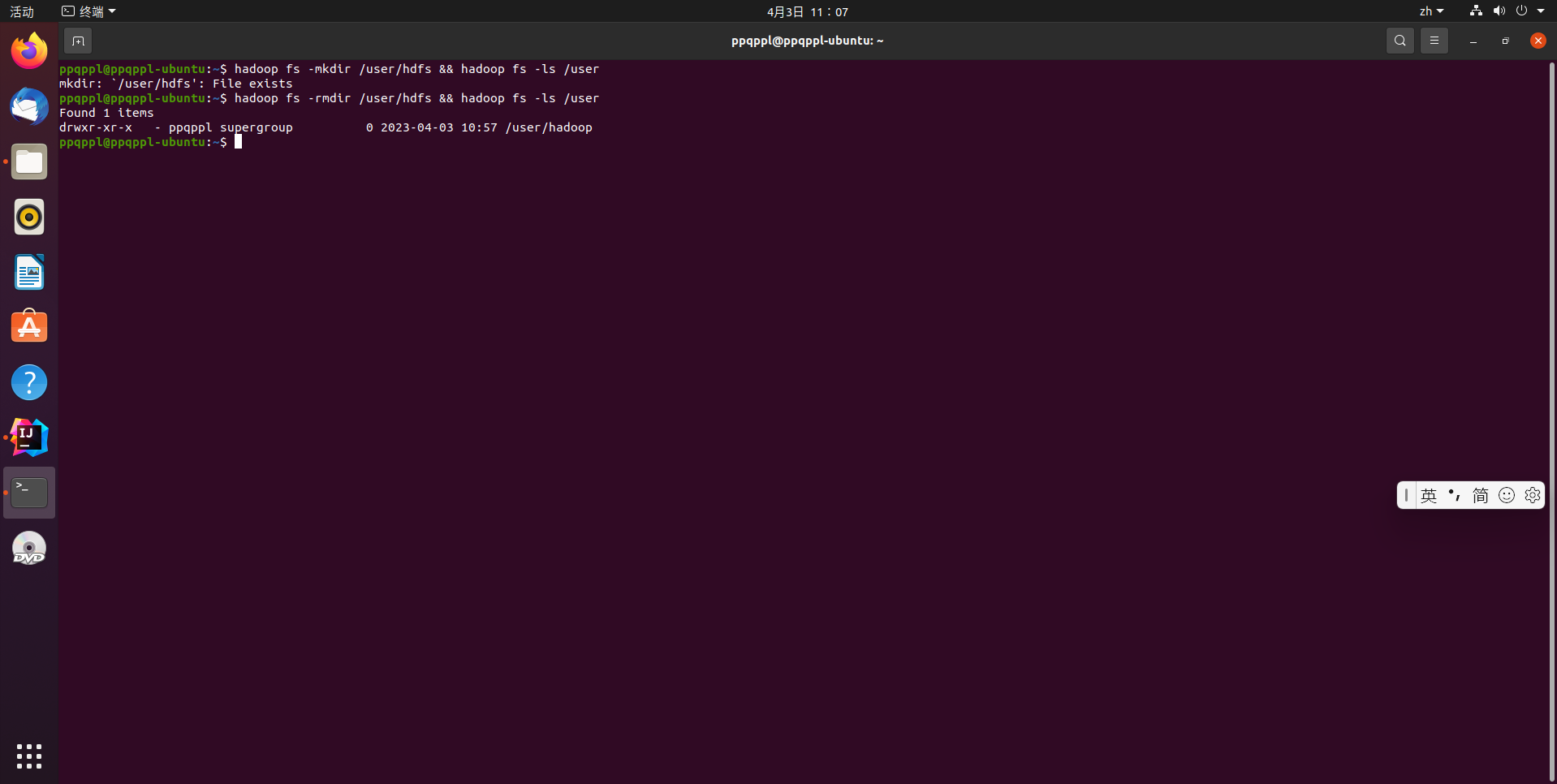
# 创建目录
hadoop fs -mkdir /user/hdfs
hadoop fs -ls /user
# 删除目录
hadoop fs -rkdir /user/hdfs
hadoop fs -ls /user
# 强制删除目录命令
hadoop fs -rm -R dir1/dir2
完整代码如下:
Hadoop7.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
public class Hadoop7 {
/**
* 判断路径是否存在
*/
public static boolean test(Configuration conf, String path) throws IOException {
FileSystem fs = FileSystem.get(conf);
return fs.exists(new Path(path));
}
/**
* 判断目录是否为空
* true: 空, false: 非空
*/
public static boolean isDirEmpty(Configuration conf, String remoteDir) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path dirPath = new Path(remoteDir);
RemoteIterator<LocatedFileStatus> remoteIterator = fs.listFiles(dirPath, true);
return !remoteIterator.hasNext();
}
/**
* 创建目录
*/
public static boolean mkdir(Configuration conf, String remoteDir) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path dirPath = new Path(remoteDir);
boolean result = fs.mkdirs(dirPath);
fs.close();
return result;
}
/**
* 删除目录
*/
public static boolean rmDir(Configuration conf, String remoteDir) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path dirPath = new Path(remoteDir);
/* 第二个参数表示是否递归删除所有文件 */
boolean result = fs.delete(dirPath, true);
fs.close();
return result;
}
}
Main.java
import org.apache.hadoop.conf.Configuration;
public class Main {
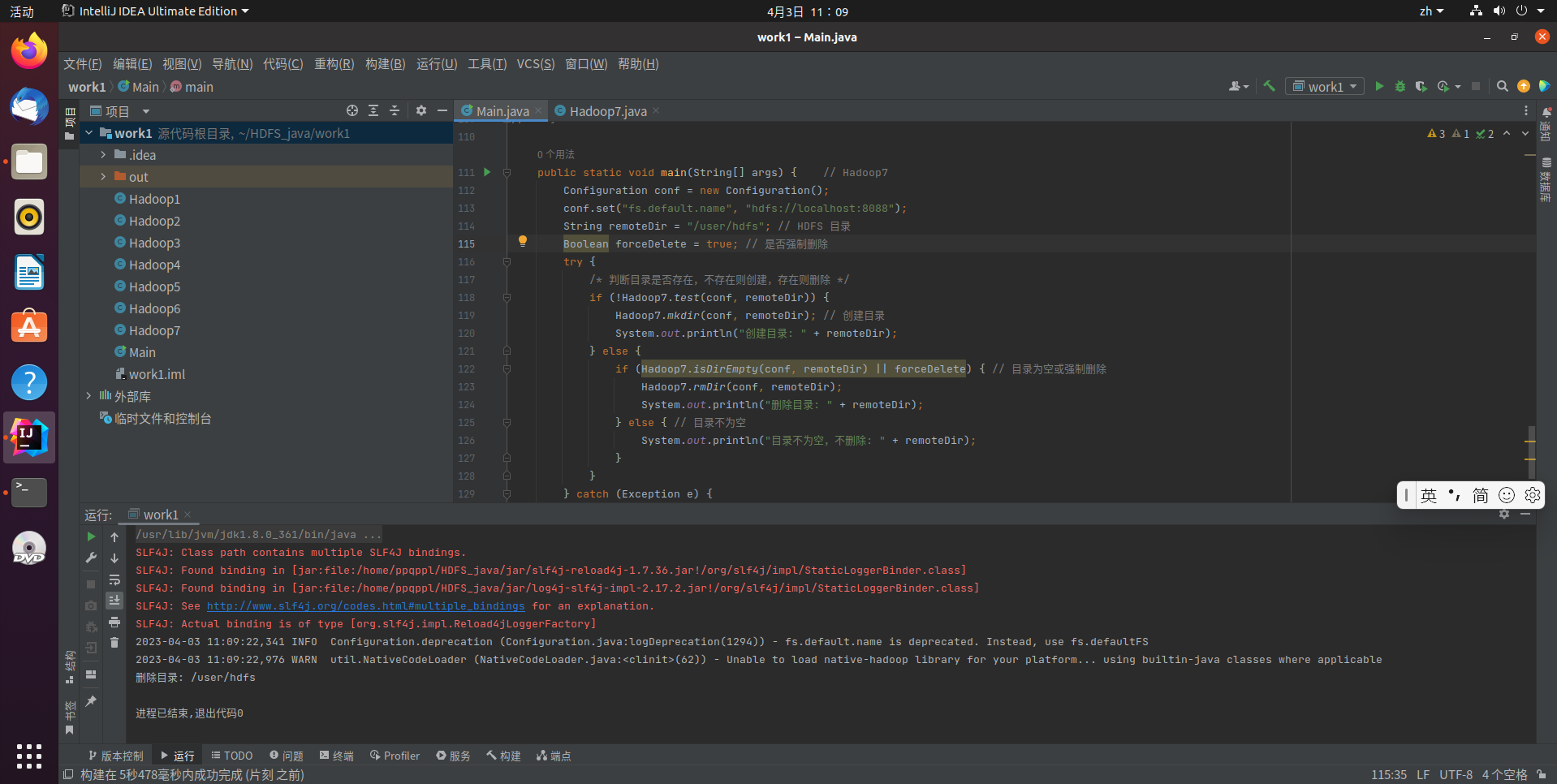
public static void main(String[] args) { // Hadoop7
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://localhost:8088");
String remoteDir = "/user/hadoop/input"; // HDFS 目录
Boolean forceDelete = false; // 是否强制删除
try {
/* 判断目录是否存在,不存在则创建,存在则删除 */
if (!Hadoop7.test(conf, remoteDir)) {
Hadoop7.mkdir(conf, remoteDir); // 创建目录
System.out.println("创建目录: " + remoteDir);
} else {
if (Hadoop7.isDirEmpty(conf, remoteDir) || forceDelete) { // 目录为空或强制删除
Hadoop7.rmDir(conf, remoteDir);
System.out.println("删除目录: " + remoteDir);
} else { // 目录不为空
System.out.println("目录不为空,不删除: " + remoteDir);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
代码运行结果:
向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾
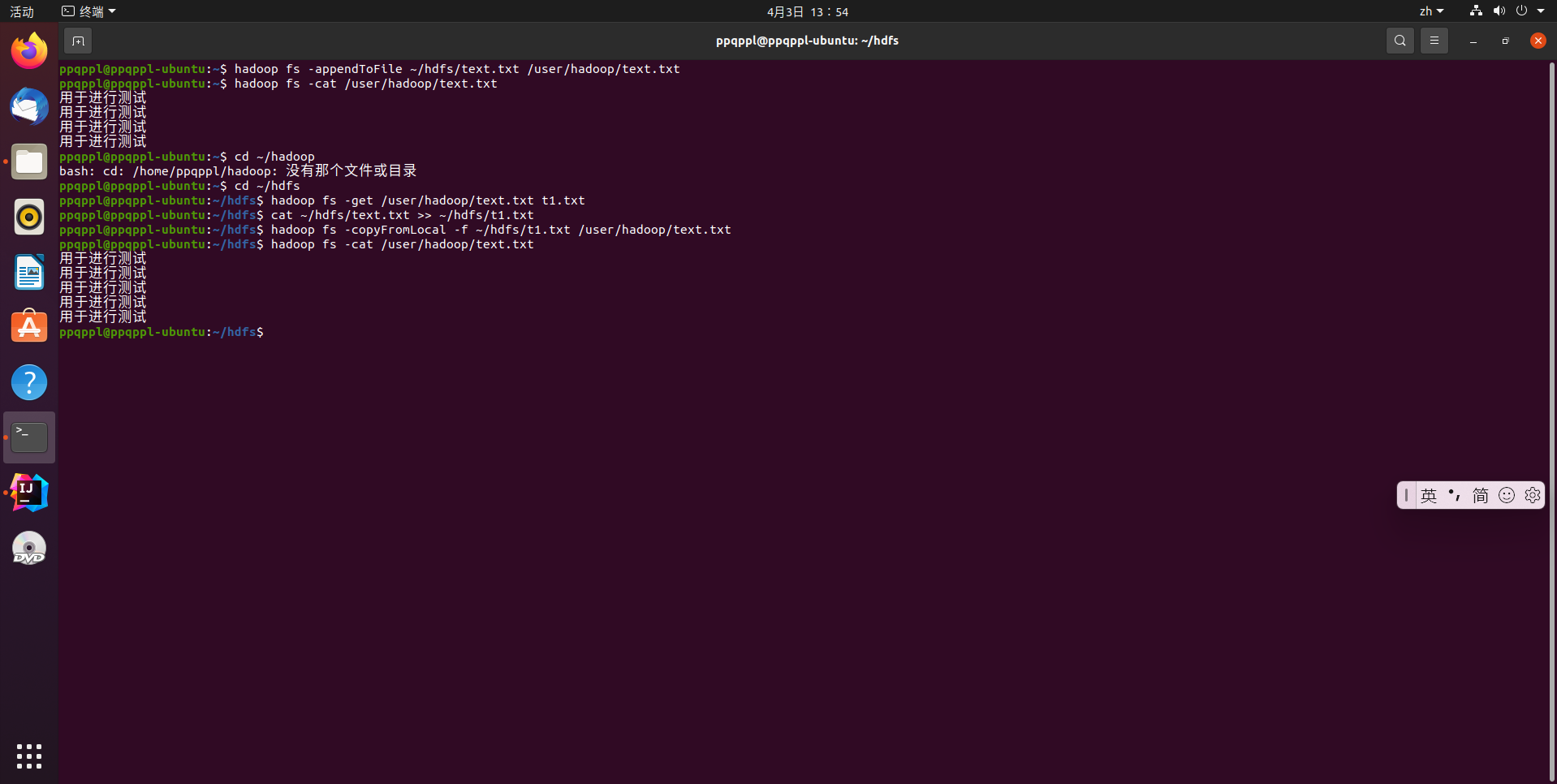
# 追加到文件末尾
hadoop fs -appendToFile ~/hdfs/text.txt /user/hadoop/text.txt
# 追加到文件开头,这里我们直接把文件拉去到本地,然后经过修改后再次上传
hadoop fs -get /user/hadoop/text.txt
cat ~/hdfs/text.txt >> text.txt
hadoop fs -copyFromLocal -f ~/hdfs/text.txt /user/hadoop/text.txt
完整代码如下:
Hadoop8.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
public class Hadoop8 {
/**
* 判断路径是否存在
*/
public static boolean test(Configuration conf, String path) throws IOException {
FileSystem fs = FileSystem.get(conf);
return fs.exists(new Path(path));
}
/**
* 追加文本内容
*/
public static void appendContentToFile(Configuration conf, String content, String
remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
/* 创建一个文件输出流,输出的内容将追加到文件末尾 */
FSDataOutputStream out = fs.append(remotePath);
out.write(content.getBytes());
out.close();
fs.close();
}
/**
* 追加文件内容
*/
public static void appendToFile(Configuration conf, String localFilePath, String
remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
/* 创建一个文件读入流 */
FileInputStream in = new FileInputStream(localFilePath);
/* 创建一个文件输出流,输出的内容将追加到文件末尾 */
FSDataOutputStream out = fs.append(remotePath);
/* 读写文件内容 */
byte[] data = new byte[1024];
int read = -1;
while ((read = in.read(data)) > 0) {
out.write(data, 0, read);
}
out.close();
in.close();
fs.close();
}
/**
* 移动文件到本地
* 移动后,删除源文件
*/
public static void moveToLocalFile(Configuration conf, String remoteFilePath, String
localFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
Path localPath = new Path(localFilePath);
fs.moveToLocalFile(remotePath, localPath);
}
/**
* 创建文件
*/
public static void touchz(Configuration conf, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
FSDataOutputStream outputStream = fs.create(remotePath);
outputStream.close();
fs.close();
}
}
Main.java
import org.apache.hadoop.conf.Configuration;
public class Main {
public static void main(String[] args) { // Hadoop8
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:8088");
String remoteFilePath = "/user/hadoop/text.txt"; // HDFS 文件
String content = "新追加的内容\n";
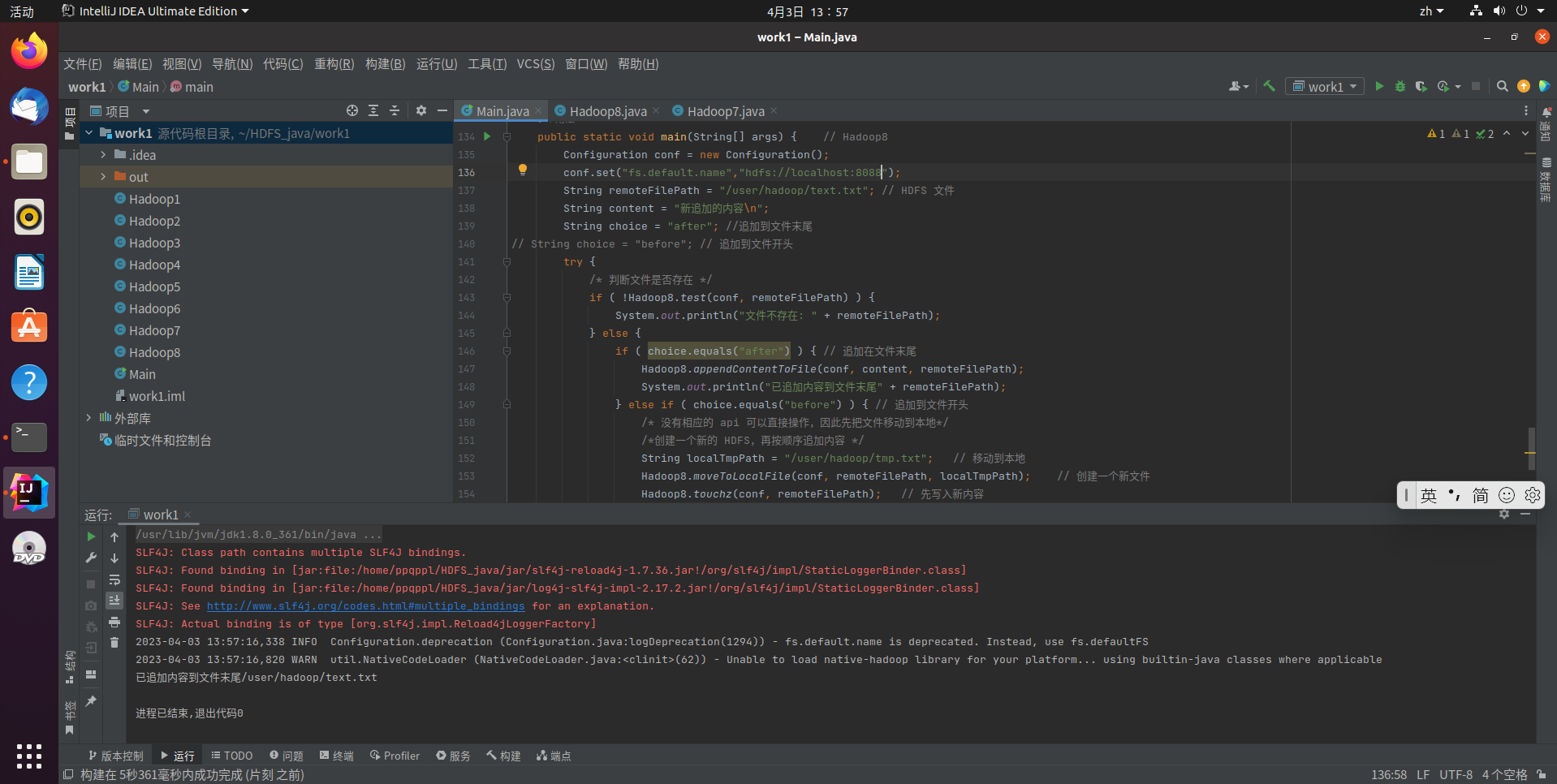
String choice = "after"; //追加到文件末尾
// String choice = "before"; // 追加到文件开头
try {
/* 判断文件是否存在 */
if ( !Hadoop8.test(conf, remoteFilePath) ) {
System.out.println("文件不存在: " + remoteFilePath);
} else {
if ( choice.equals("after") ) { // 追加在文件末尾
Hadoop8.appendContentToFile(conf, content, remoteFilePath);
System.out.println("已追加内容到文件末尾" + remoteFilePath);
} else if ( choice.equals("before") ) { // 追加到文件开头
/* 没有相应的 api 可以直接操作,因此先把文件移动到本地*/
/*创建一个新的 HDFS,再按顺序追加内容 */
String localTmpPath = "/user/hadoop/tmp.txt"; // 移动到本地
Hadoop8.moveToLocalFile(conf, remoteFilePath, localTmpPath); // 创建一个新文件
Hadoop8.touchz(conf, remoteFilePath); // 先写入新内容
Hadoop8.appendContentToFile(conf, content, remoteFilePath); // 再写入原来内容
Hadoop8.appendToFile(conf, localTmpPath, remoteFilePath);
System.out.println("已追加内容到文件开头: " + remoteFilePath);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
代码运行结果:
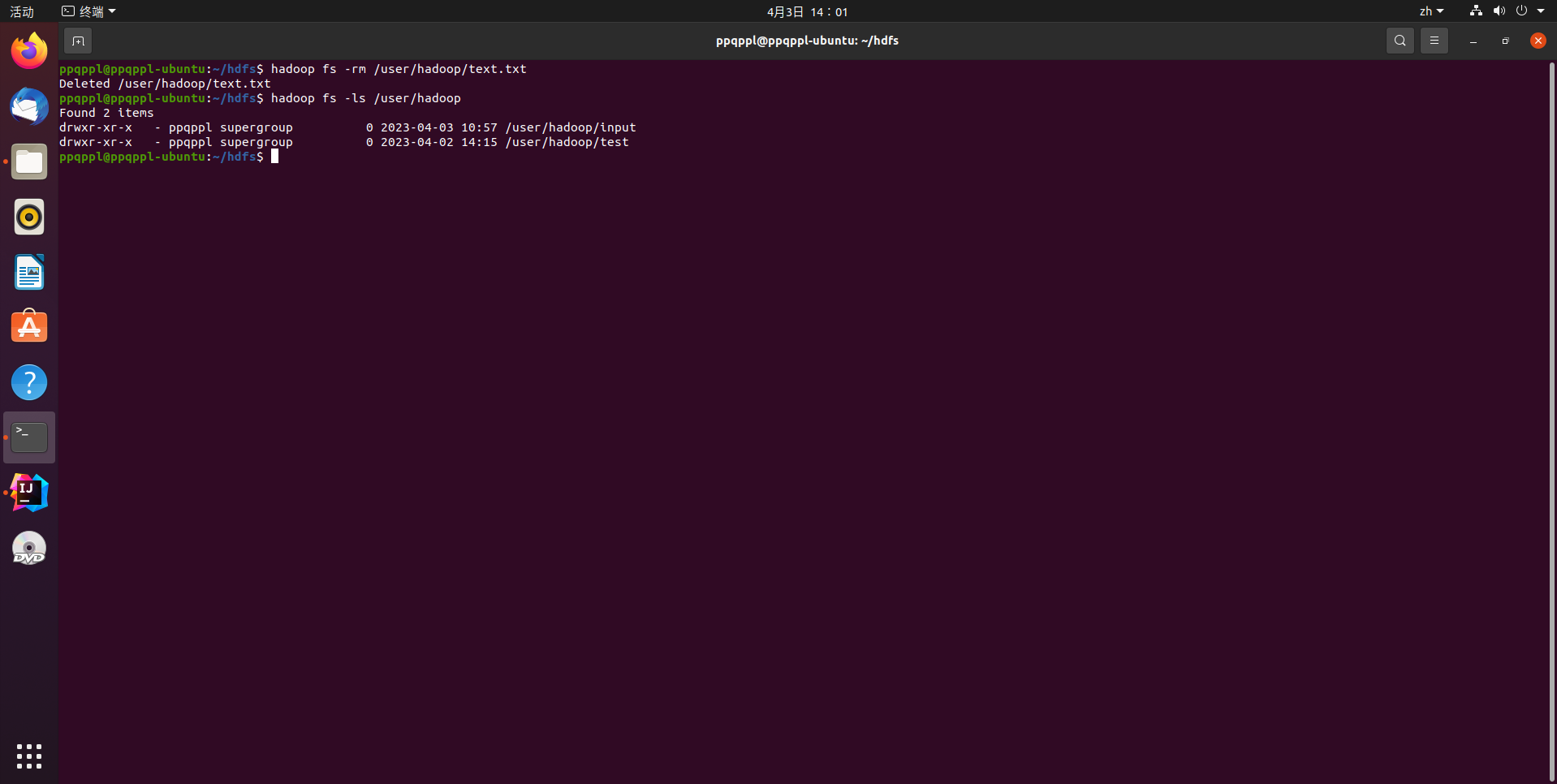
删除HDFS中指定的文件
hadoop fs -rm /user/hadoop/text.txt
hadoop fs -ls /user/hadoop
完整代码如下:
Hadoop9.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
public class Hadoop9 {
/**
* 删除文件
*/
public static boolean rm(Configuration conf, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
boolean result = fs.delete(remotePath, false);
fs.close();
return result;
}
}
Main.java
import org.apache.hadoop.conf.Configuration;
public class Main {
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:8088");
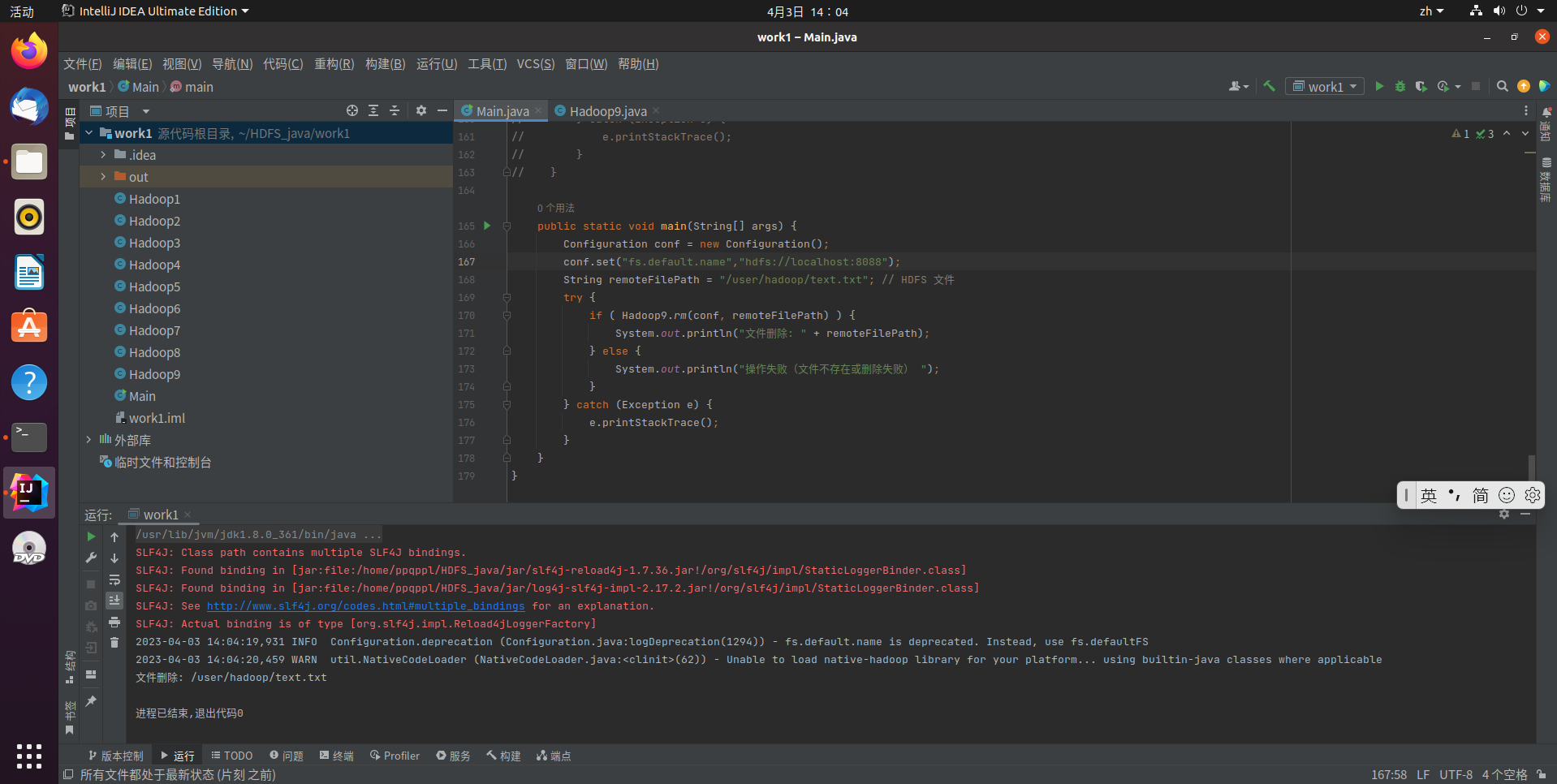
String remoteFilePath = "/user/hadoop/text.txt"; // HDFS 文件
try {
if ( Hadoop9.rm(conf, remoteFilePath) ) {
System.out.println("文件删除: " + remoteFilePath);
} else {
System.out.println("操作失败(文件不存在或删除失败) ");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
代码运行结果:
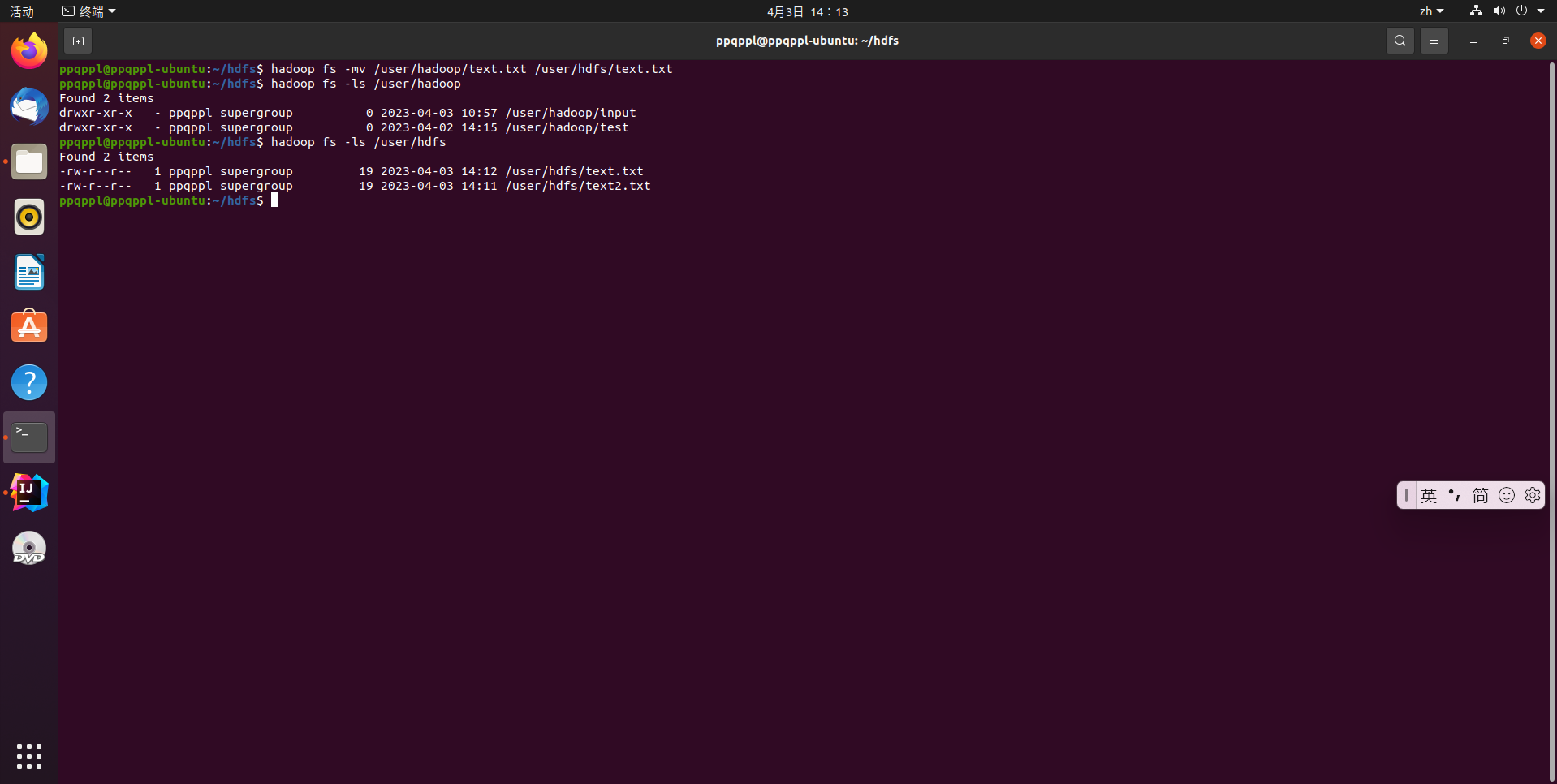
在HDFS中,将文件从源路径移动到目的路径
hadoop fs -mv /user/hadoop/text.txt /user/hdfs/text2.txt
完整代码如下:
Hadoop10.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
public class Hadoop10 {
/**
* 移动文件
*/
public static boolean mv(Configuration conf, String remoteFilePath, String
remoteToFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path srcPath = new Path(remoteFilePath);
Path dstPath = new Path(remoteToFilePath);
boolean result = fs.rename(srcPath, dstPath);
fs.close();
return result;
}
}
Main.java
import org.apache.hadoop.conf.Configuration;
public class Main {
public static void main(String[] args) { // Hadoop10
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:8088");
String remoteFilePath = "hdfs:///user/hadoop/text.txt"; // 源文件 HDFS 路径
String remoteToFilePath = "hdfs:///user/hadoop/new.txt"; // 目的 HDFS 路径
try {
if ( Hadoop10.mv(conf, remoteFilePath, remoteToFilePath) ) {
System.out.println(" 将 文 件 " + remoteFilePath + " 移 动 到 " +
remoteToFilePath);
} else {
System.out.println("操作失败(源文件不存在或移动失败)");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
代码运行结果:
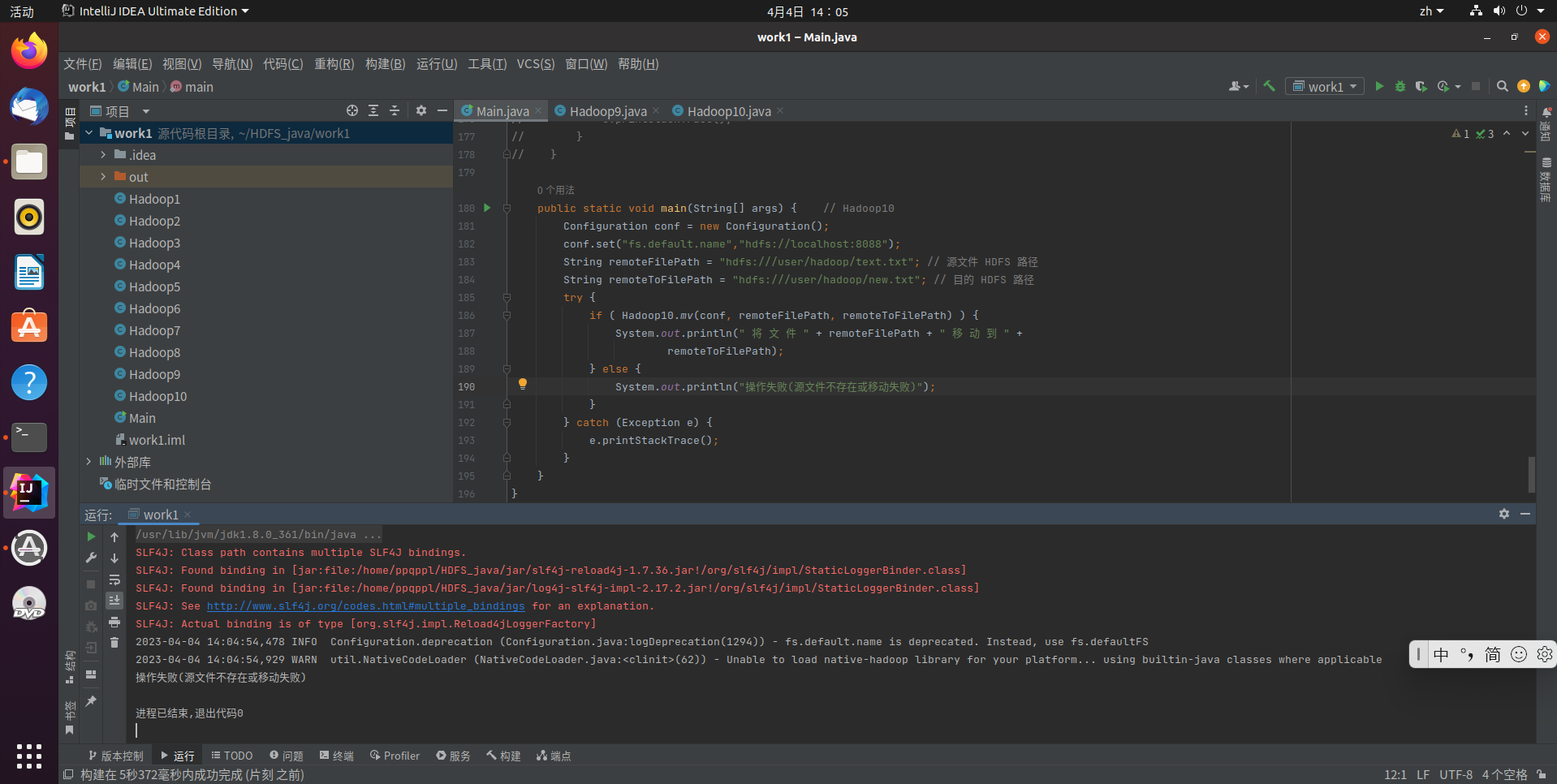
编程实现一个类“MyFSDataInputStream”,该类继承“org.apache.hadoop.fs.FSDataInputStream”,要求如下:实现按行读取HDFS中指定文件的方法“readLine()”,如果读到文件末尾,则返回空,否则返回文件一行的文本
完整代码如下:
MyFSDataInputStream.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.*;
public class MyFSDataInputStream extends FSDataInputStream {
public MyFSDataInputStream(InputStream in) {
super(in);
}
/**
* 实现按行读取
* 每次读入一个字符,遇到"\n"结束,返回一行内容
*/
public static String readline(BufferedReader br) throws IOException {
char[] data = new char[1024];
int read = -1;
int off = 0;
// 循环执行时, br 每次会从上一次读取结束的位置继续读取
//因此该函数里, off 每次都从 0 开始
while ((read = br.read(data, off, 1)) != -1) {
if (String.valueOf(data[off]).equals("\n")) {
off += 1;
break;
}
off += 1;
}
if (off > 0) {
return String.valueOf(data);
} else {
return null;
}
}
/**
* 读取文件内容
*/
public static void cat(Configuration conf, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
FSDataInputStream in = fs.open(remotePath);
BufferedReader br = new BufferedReader(new InputStreamReader(in));
String line = null;
while ((line = MyFSDataInputStream.readline(br)) != null) {
System.out.println(line);
}
br.close();
in.close();
fs.close();
}
}
Main.java
import org.apache.hadoop.conf.Configuration;
public class Main {
public static void main(String[] args) { // MyFSDataInputStream
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:8088");
String remoteFilePath = "/user/hadoop/text.txt"; // HDFS 路径
try {
MyFSDataInputStream.cat(conf, remoteFilePath);
} catch (Exception e) {
e.printStackTrace();
}
}
}
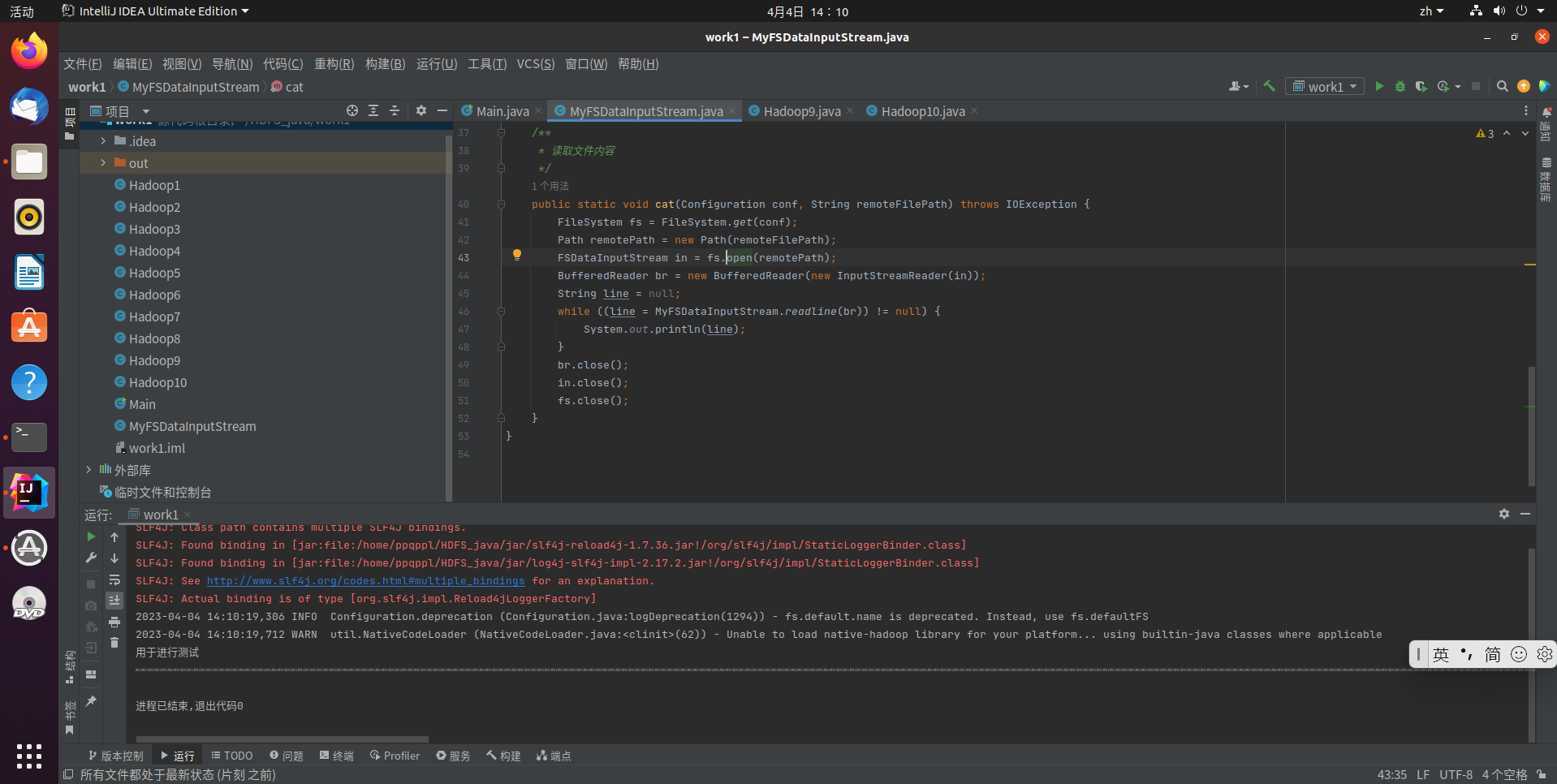
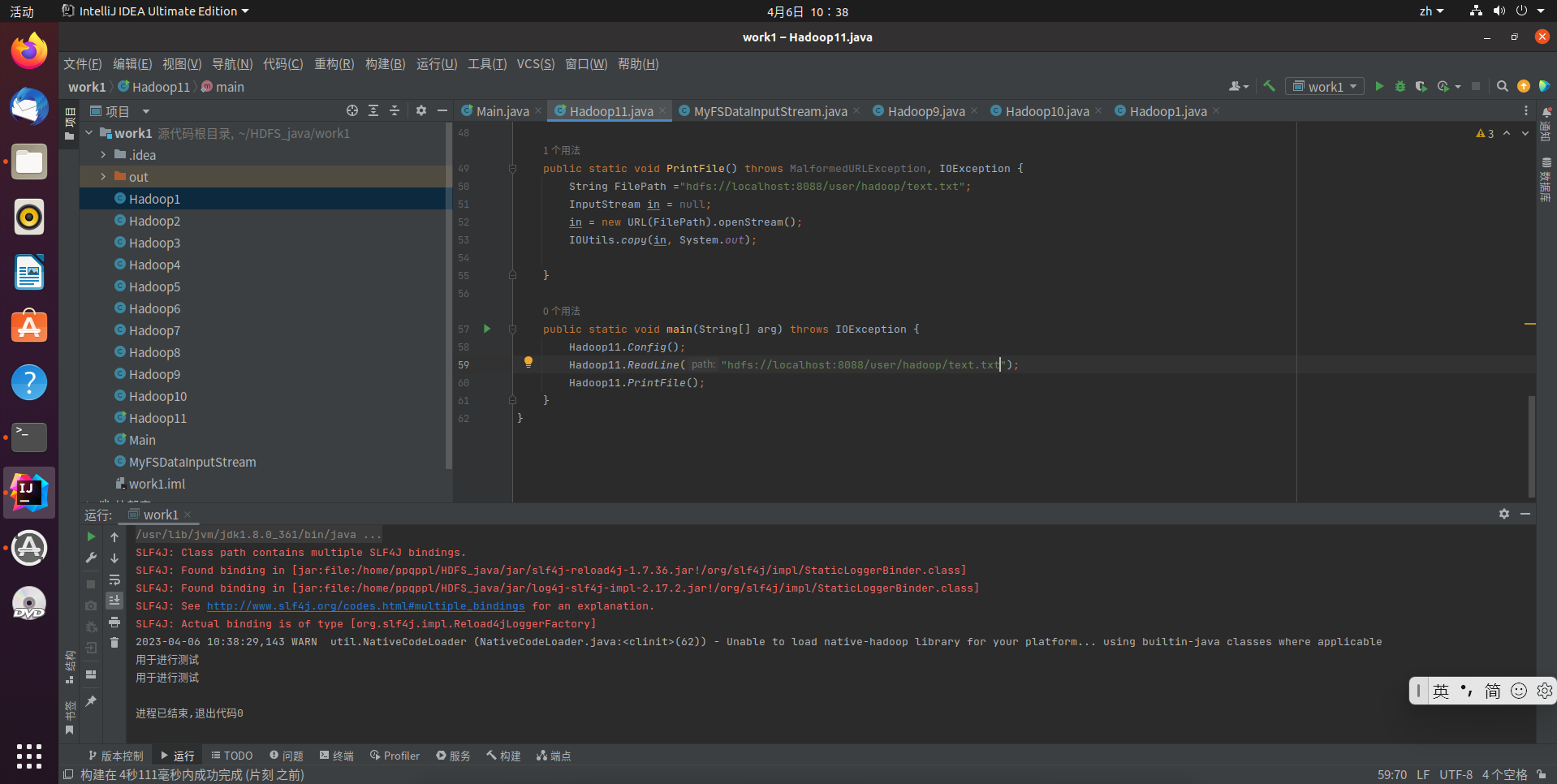
查看Java帮助手册或其它资料,用“java.net.URL”和“org.apache.hadoop.fs.FsURLStreamHandlerFactory”编程完成输出HDFS中指定文件的文本到终端中
完整代码如下:
Hadoop11.java
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.commons.io.IOUtils;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.fs.Path;
public class Hadoop11 extends FSDataInputStream {
private static Configuration conf;
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
Hadoop11(InputStream in) {
super(in);
}
public static void Config() {
conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:8088");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
}
public static int ReadLine(String path) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path file = new Path(path);
FSDataInputStream getIt = fs.open(file);
BufferedReader d = new BufferedReader(new InputStreamReader(getIt));
String content;// = d.readLine();
if ((content = d.readLine()) != null) {
System.out.println(content);
}
// System.out.println(content);
d.close();
fs.close();
return 0;
}
public static void PrintFile() throws MalformedURLException, IOException {
String FilePath ="hdfs://localhost:8088/user/hadoop/text.txt";
InputStream in = null;
in = new URL(FilePath).openStream();
IOUtils.copy(in, System.out);
}
}
Main.java
import org.apache.hadoop.conf.Configuration;
import java.io.IOException;
public class Main {
public static void main(String[] arg) throws IOException { // Hadoop11
Hadoop11.Config();
Hadoop11.ReadLine("hdfs://localhost:8088/user/hadoop/text.txt");
Hadoop11.PrintFile();
}
}
代码运行结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号