云计算与大数据入门 —— 环境配置与一些错误的解决方案
云计算与大数据入门 —— 环境配置与一些错误的解决方案
Hadoop 伪分布式配置
首先我们进入 Hardoop 路径下,然后修改 core-site.xml 配置文件
cd /usr/local/hardoop
gedit core-site.sml
# 修改如下内容
<configuration>
</configuration>
# 修改后的内容
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
# 这里如果有引用在 9000 端口的话,推荐切换到 8088 端口
同样的方式修改 hdfs-site.xml:
cd /usr/local/hardoop
gedit hdfs-site.xml
# 修改如下内容
<configuration>
</configuration>
# 修改后的内容
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
配置完成后,执行 NameNode 的格式化:
cd /usr/local/hadoop
./bin/hdfs namenode -format
显示如下内容,运行成功:
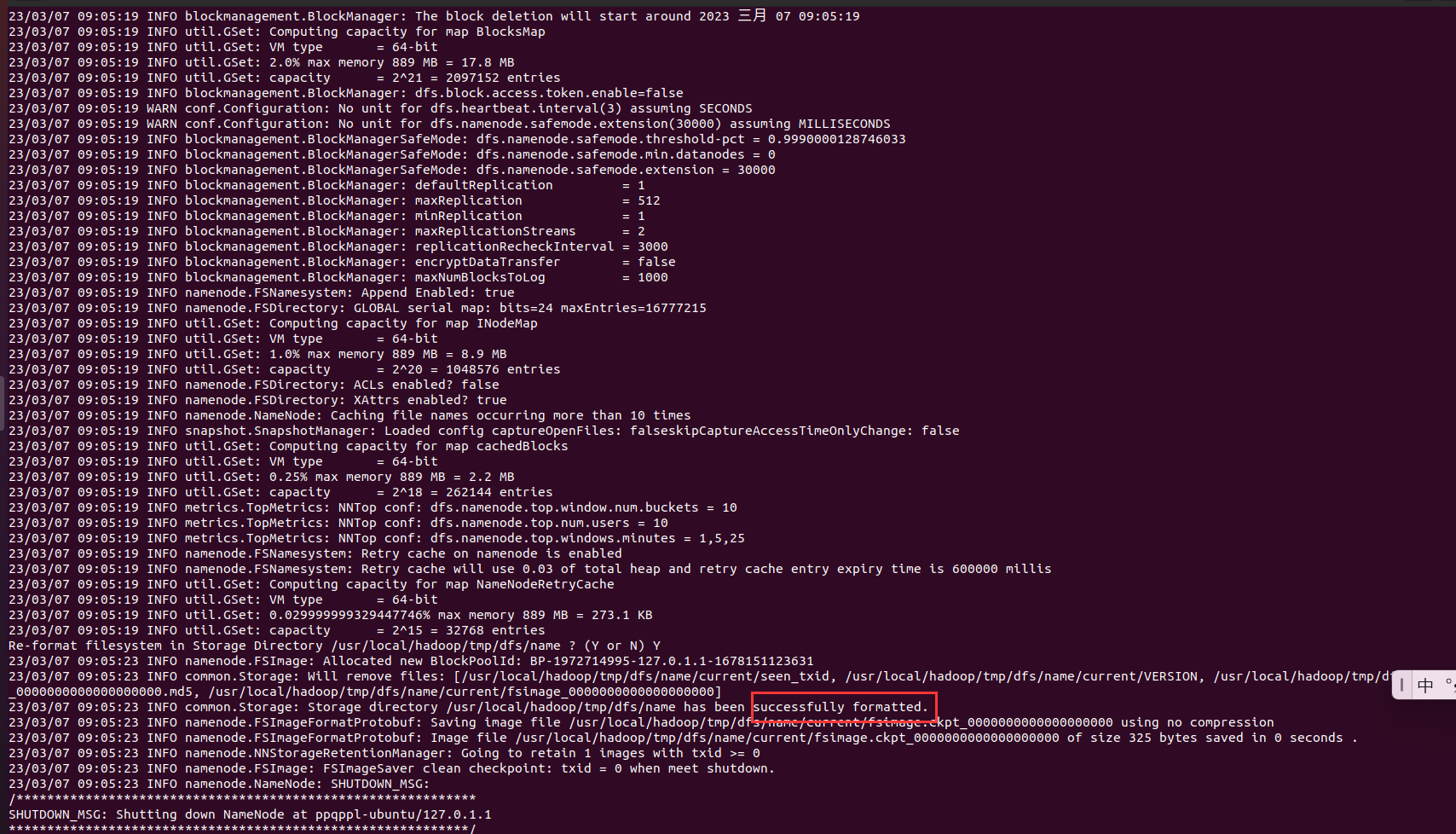
如果这里出现如下警告:
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform...
首先进入这个目录:/usr/local/hadoop/lib/native
然后查看这个目录下存放了什么:

可以看出,libhadoop.so 存放在这个目录下
接下来我们回到 /usr/local/hadoop 目录,紧接着输入以下代码:
grep -R 'java.library.path' *
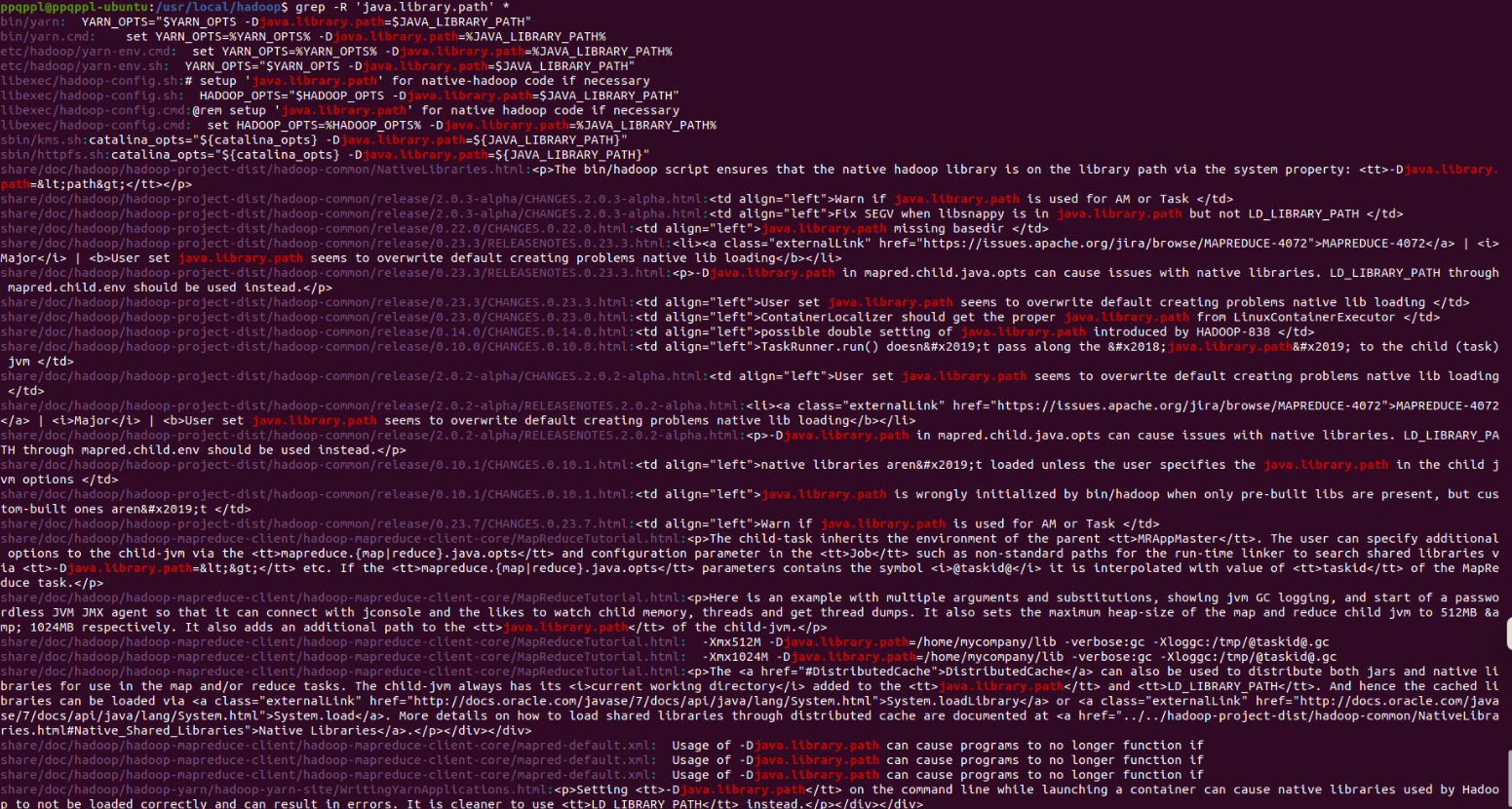
在hadoop包中搜索发现,java.library.path 被定义为 $JAVA_LIBRARY_PATH,但是我们没有定义 JAVA_LIBRARY_PATH
那么问题就好解决了,配置这个环境变量就好啦
在环境变量添加如下:
export JAVA_LIBRARY_PATH=/usr/local/hadoop/lib/native
然后重启环境变量即可
环境变量文件下,我们还有添加瑞啊内容:
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
接着开启 NameNode 和 DataNode 守护进程:
cd /usr/local/hadoop
./sbin/start-dfs.sh
若出现如下 SSH 提示,输入 yes 即可:

最后我们通过 jps 命令来判断是否启用成功,启用成功如图:

Hadoop 无法正常启动的解决方法: 一般可以查看启动日志来排查原因,注意几点:
启动时会提示形如 "DBLab-XMU: starting namenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-namenode-DBLab-XMU.out",其中 DBLab-XMU 对应你的机器名,但其实启动日志信息是记录在 /usr/local/hadoop/logs/hadoop-hadoop-namenode-DBLab-XMU.log 中,所以应该查看这个后缀为 .log 的文件
每一次的启动日志都是追加在日志文件之后,所以得拉到最后面看,对比下记录的时间就知道了
一般出错的提示在最后面,通常是写着 Fatal、Error、Warning 或者 Java Exception 的地方
可以在网上搜索一下出错信息,看能否找到一些相关的解决方法
此外,若是 DataNode 没有启动,可尝试如下的方法(注意这会删除 HDFS 中原有的所有数据,如果原有的数据很重要请不要这样做):
# 针对 DataNode 没法启动的解决方法
cd /usr/local/hadoop
./sbin/stop-dfs.sh # 关闭
rm -r ./tmp # 删除 tmp 文件,注意这会删除 HDFS 中原有的所有数据
./bin/hdfs namenode -format # 重新格式化 NameNode
./sbin/start-dfs.sh # 重启
成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件
HBase 伪分布式模式配置
配置 /usr/local/hbase/conf/hbase-env.sh 命令如下:
配置 JAVA_HOME,HBASE_CLASSPATH,HBASE_MANAGES_ZK
HBASE_CLASSPATH 设置为本机 Hadoop 安装目录下的 conf 目录(即/usr/local/hadoop/conf)
# 在文件末尾添加
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_361
export HBASE_CLASSPATH=/usr/local/hadoop/conf
export HBASE_MANAGES_ZK=true
配置 /usr/local/hbase/conf/hbase-site.xml
修改 hbase.rootdir,指定 HBase 数据在 HDFS 上的存储路径;将属性 hbase.cluter.distributed 设置为 true。假设当前 Hadoop 集群运行在伪分布式模式下,在本机上运行,且 NameNode 运行在 9000 端口(这个端口与前面 Hadoop 配置使用的端口一致)。
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
</configuration>
接下来测试运行 HBase
第一步:首先登陆 ssh,再切换目录至 /usr/local/hadoop ;再启动 hadoop,如果已经启动 hadoop 请跳过此步骤。命令如下:
ssh localhost
cd /usr/local/hadoop
./sbin/start-dfs.sh
输入命令 jps,能看到 NameNode,DataNode 和 SecondaryNameNode 都已经成功启动,表示 hadoop 启动成功,截图如下:

第二步:切换目录至 /usr/local/hbas ,再启动 HBase 命令如下:
cd /usr/local/hbase
bin/start-hbase.sh
启动成功,输入命令 jps ,看到以下界面说明 hbase 启动成功
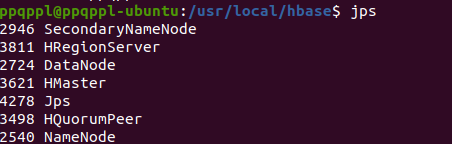
进入 shell 界面:
bin/hbase shell
shell 界面的命令与 MySQL shell 界面的命令相似
停止 HBase 运行,命令如下:
bin/stop-hbase.sh
注意:如果在操作 HBase 的过程中发生错误,可以通过{HBASE_HOME}目录(/usr/local/hbase)下的logs子目录中的日志文件查看错误原因
这里启动关闭 Hadoop 和 HBase 的顺序一定是:
启动 Hadoop—> 启动 HBase—> 关闭 HBase—> 关闭 Hadoop
错误解决方案
首先如果这里报错 hadoop 找不到命令,我们需要打开 /ect/profile,在里面添加如下环境变量:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_361
export HADOOP_HOME=/usr/local/hadoop
export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
然后我们使用 source 命令引入环境便令即可
如果我们这里开启 ssh 后出现 gedit 命令报错:
Unable to init server:无法连接:拒绝连接
我们使用如下命令解决:
xhost local:gedit
如果继续报错如下:
xhost: unable to open display “”
先使用如下命令:
export DISPLAY=:0
然后我们再次执行上述命令,出现下面内容,说明问题解决:
non-network local connections being added to access control list

 浙公网安备 33010602011771号
浙公网安备 33010602011771号