
python学习笔记,视频day16-函数作用域,匿名函数,map,filter,reduce
总结
全局变量:顶头写的
局部变量
name="alex" def change_name(): global name name="1hf" print(name) def foo(): name="wu" print(name) foo() change_name() # 结果 # 1hf # wu name="alex" def change_name(): name="1hf" print(name) def foo(): nonlocal name name="bbb" print(name) print(name) foo() print(name) change_name() # 结果 # 1hf # 1hf # bbb # bbb
递归:函数自己调用自己;特性,要有明确的结束条件,问题规模应减少,效率不高
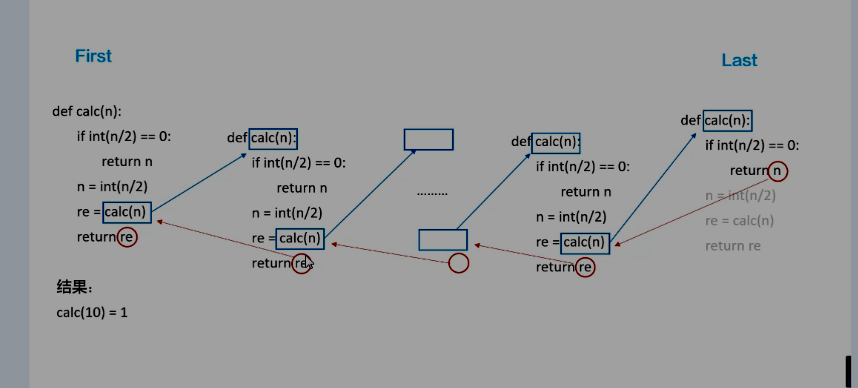
函数作用域
def test1(): print("test1") def test(): print("test") return test1 res=test() print(res) # 结果 # test # <function test at 0x02B4AA98> def test1(): print("test1") def test(): print("test") return test1 res=test() print(res()) # 结果 # test # test1 # None
# 不管在哪个位置调用函数,函数在运行中的作用域,跟定义时有关,跟在哪个位置调用无关 #如下,在全局时调用函数,跟声明时的作用域有关,与调用位置无关 name ="alex" def foo(): name="linhaifeng" def bar(): name="wupeiqi" print(name) return bar res=foo() print(res) res() # 结果 # <function foo.<locals>.bar at 0x007DCA98> # wupeiqi
name="alex" def foo(): name="1hf" def bar(): name="wupeiqi" def tt(): print(name) return tt return bar
foo()()()
# 结果 #wupeiqi
匿名函数
lambda x:x+1
# 匿名就是没有名字,直接lambda x:x+1使用,一般和其他函数一起使用,若单独存在,python直接回收 # lambda没有return,lambda x:x+1相当于定义一个值1,没有命名门牌号,立马被回收 func=lambda x:x+1 print(func(10)) func=lambda x:x+"_sb" print(func("alex")) # # 结果 # # 11 # # alex_sb
# 形参的数量任意 func=lambda x,y,z:x+y+z print(func(1,2,3)) # # 结果 # # 6 func=lambda x,y,z:(x+1,y+1,z+1) print(func(1,2,3)) # # 结果 # # (2, 3, 4)
编程方法论:
面向过程:对过程细分,每次都从头运行,比函数式易读
def cal(x):
res=2*x
res+=1
return res
面向对象
函数式:
def cal(x):
return 2*x+1
特性:
1、无赋值
2、不可变,不修改变量
函数式编程
高阶函数:
满足以下两个条件之一
函数的参数是一个函数名
函数的返回值是一个函数名
def cal(x): return x+1 # 把函数当作一个参数传给另一个函数 def foo(n): print(n) def bar(name): print("my name is %s" %name) # bar没有返回值,故传none给foo foo(bar("alex")) # # 结果 # # my name is alex # # None def foo(n): print(n) def bar(name): print("my name is %s" %name) return name foo(bar("alex")) # # 结果 # # my name is alex # # Nalex
# 返回值中包含函数 def bar(): print("from bar") def foo(): print("from foo") return bar n=foo() n() # # 结果 #from foo #from bar def bar(): print("from bar") def foo(): print("from foo") return bar foo() # # 结果 # #from foo # 返回值是自己 def handle(): print("from handle") return handle#return handle()为递归 h=handle() h() # 结果 # from handle # from handle
#
def test1():
print("from test1")
def test2():
print("from test2")
return test1()#test1()运行不完,test3函数就没法执行;代表return函数test1的返回值
test2()
# 结果
# from test2
# from test1
尾调用优化:在函数的最后一步递归函数
#第一层的状态不需要保存
def test():
print("test")
test()
#函数未执行完,在第一次时保存
def test():
print("test")
test()
print("test2")
#不是尾调用
def bar(n):
return n
def foo(x):
res=bar(x)
return res+1
#是尾调用
def bar(n):
return n
def foo(x):
res=bar(x)
return res
# 非尾递归 def cal(seq): if len(seq)==1: return seq[0] head,*tail=seq return head+cal(tail) print(cal(range(10))) # # 结果 # # 45 # 尾递归---------------报错 def cal(l): print(l) if len(l) == 1: return l[0] first, second, *args = l l[0] = first + second l.pop(1) return cal(l) x = cal([i for i in range(10)]) print(x)
函数式编程
1、map是函数式编程的一个
“列表”的个数不会改变,只会对元素相应调整
- 逻辑简单用lambda,逻辑复杂必须定义函数;
- 后者是可迭代对象即可,不一定是列表
#内置函数(lambda)、有名函数(自己写的函数)
#终极版
num_1=[1,2,3,100,6,5]
res=map(lambda x:x+1,num_1)#map(lambda x:x+1,num_1)lambda x:x+1逻辑,num_1可迭代对象
# for i in res:
# print(i)#不能使用循环
print("内置函数map,处理结果:",list(res))
# 结果
# 内置函数map,处理结果: [2, 3, 4, 101, 7, 6]
num_1=[1,2,3,100,6,5] def reduce_one(x): return x-1 print("传的是有名函数",map(reduce_one,num_1)) print("传的是有名函数",list(map(reduce_one,num_1))) # 结果 # 传的是有名函数 <map object at 0x018D33B0> # 传的是有名函数 [0, 1, 2, 99, 5, 4]
#版本一
#数字 num_1=[1,2,3,100,6,5] def add_one(x): return x+1 def reduce_one(x): return x-1 def pf(x): return x**2 def map_test(func,array): ret=[] for i in array: res=func(i)#调用函数 ret.append(res) return ret print(map_test(add_one,num_1))#处理列表的方法,要处理的列表 print(map_test(reduce_one,num_1))#reduce_one()代表运行,不能这么传 print(map_test(pf,num_1)) # 结果 # [2, 3, 4, 101, 7, 6] # [0, 1, 2, 99, 5, 4] # [1, 4, 9, 10000, 36, 25]
用lambda改写
#版本二,用lambda改写
# 改写成匿名函数 num_1=[1,2,3,100,6,5] def map_test(func,array): ret=[] for i in array: res=func(i)#调用函数 ret.append(res) return ret print(map_test(lambda x:x+1,num_1)) print(map_test(lambda x:x-1,num_1)) print(map_test(lambda x:x**2,num_1)) # 结果 # [2, 3, 4, 101, 7, 6] # [0, 1, 2, 99, 5, 4] # [1, 4, 9, 10000, 36, 25]
# map就是上面写的逻辑
num_1=[1,2,3,100,6,5]
print(map(lambda x:x+1,num_1))
# 结果是一个地址
# <map object at 0x00723310>
#字符串
msg="dsfasdgdh" print(list(map(lambda x:x.upper(),msg)))#x.upper()返回 # 结果 # ['D', 'S', 'F', 'A', 'S', 'D', 'G', 'D', 'H']
2、filter
“列表”的个数会改变,是布尔值,满足条件的元素放在一个“列表中”
# 终极版
li=["ab_alex","wupeiqi","ab_slila","ab_linhaifeng"]
print(list(filter(lambda x:not x.startswith("ab_"),li)))
# 结果
# ['wupeiqi']
li=["ab_alex","wupeiqi","ab_slila","ab_linhaifeng"]
print(filter(lambda x:not x.startswith("ab_"),li))
# 结果
# <filter object at 0x031CAAD0>
#保存结果
li=["ab_alex","wupeiqi","ab_slila","ab_linhaifeng"]
res=filter(lambda x:not x.startswith("ab_"),li)
print(list(res))
# 结果
# ['wupeiqi']
#版本一
li=["ab_alex","wupeiqi","ab_slila","ab_linhaifeng"] ret=[] for i in li: if not i.startswith("ab_"): ret.append(i) print(ret) # 结果 # ['wupeiqi']
#版本二
li=["ab_alex","wupeiqi","ab_slila","ab_linhaifeng"] def dilter_test(array):#li是全局变量,最好不要修改,故定义变量array ret=[] for i in array: if not i.startswith("ab_"): ret.append(i) return ret print(dilter_test(li))#dilter_test(li)相当于一个名字,没有使用,故赋值给res,如下例 # 结果 # ['wupeiqi'] li=["ab_alex","wupeiqi","ab_slila","ab_linhaifeng"] def dilter_test(array): ret=[] for i in array: if not i.startswith("ab_"): ret.append(i) return ret # print(res=dilter_test(li))#打印赋值过程报错 res=dilter_test(li) print(res) # 结果 # ['wupeiqi']
#版本三
def test(n): return n.endswith("ab_") def dilter_test(func,array):#li是全局变量,最好不要修改,故定义变量array ret=[] for i in array: if not func(i): ret.append(i) return ret # print(res=dilter_test(li))#打印赋值过程报错 res=dilter_test(test , li) print(res) # 结果 # ['wupeiqi']
reduce
“列表”的个数会改变,汇总成一个元素
from functools import reduce导入
#终极版 from functools import reduce li=[2,3,45,66] res=reduce(lambda x,y:x+y,li,2) print(res) # 结果 # 118
#版本一 li=[2,3,45,66] res=0 for i in li: res+=i print(res) # 结果 # 116
#版本二 li=[2,3,45,66] def reduce_test(func,array): res=array.pop(0) for i in array: res=func(res,i) return res res=reduce_test(lambda x,y:x*y,li) print(res) # 结果 # 17820
#版本三 li=[2,3,45,66] def reduce_test(func,array,init=None):#定义一个初始值 if init is None: res=array.pop(0) else: res=init for i in array: res=func(res,i) return res res=reduce_test(lambda x,y:x*y,li,100)#100表示初始值 print(res) # 结果 # 1782000
总结
map:处理序列中的每个元素,得到的结果是一个“列表”,该“列表“元素个数及位置与原来一样
filter:遍历序列中的每个元素,判断每个元素得到布尔值,如果是True则留下来
reduce:处理序列,然后将序列进行合并操作
关注:是序列,不仅仅是一个元素
people=[
{"name":"alex","age":100},
{"name": "yangzi", "age": 30},
{"name": "qianyue", "age": 50},
{"name": "brongjing", "age": 10},
]
res=list(filter(lambda p:p["age"]<=18,people))
print(res)
# 结果
# [{'name': 'brongjing', 'age': 10}]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号