
解决加载GPT2(Tensorflow预训练模型)的Linear权重到PyTorch的Linear权重 形状不匹配(互为转置)问题
解决报错内容:
RuntimeError: Error(s) in loading state_dict for PyTorchBasedGPT2:
size mismatch for transformer.h.0.attn.c_attn.weight: copying a param with shape torch.Size([768, 2304]) from checkpoint, the shape in current model is torch.Size([2304, 768])......
一、错误原因分析
Pytorch中,Linear层的权重存储形状为[out_features, in_features]。而Tensorflow中Linear权重的存储形状为[in_features, out_features]。
这是由于两个库使用不同的数学运算表示 (参考https://www.null123.com/question/detail-2816063.html):
Pytorch: y = Wx + B
Tensorflow: y = xW + B
当直接使用pytorch实现的GPT2架构模型去加载GPT2的预训练参数时会发生:
1 PyTorchBasedGPT2.from_pretrained("openai-community/gpt2")


1 RuntimeError: Error(s) in loading state_dict for PyTorchBasedGPT2: 2 size mismatch for transformer.h.0.attn.c_attn.weight: copying a param with shape torch.Size([768, 2304]) from checkpoint, the shape in current model is torch.Size([2304, 768]). 3 size mismatch for transformer.h.0.mlp.c_fc.weight: copying a param with shape torch.Size([768, 3072]) from checkpoint, the shape in current model is torch.Size([3072, 768]). 4 size mismatch for transformer.h.0.mlp.c_proj.weight: copying a param with shape torch.Size([3072, 768]) from checkpoint, the shape in current model is torch.Size([768, 3072]). 5 size mismatch for transformer.h.1.attn.c_attn.weight: copying a param with shape torch.Size([768, 2304]) from checkpoint, the shape in current model is torch.Size([2304, 768]). 6 size mismatch for transformer.h.1.mlp.c_fc.weight: copying a param with shape torch.Size([768, 3072]) from checkpoint, the shape in current model is torch.Size([3072, 768]). 7 size mismatch for transformer.h.1.mlp.c_proj.weight: copying a param with shape torch.Size([3072, 768]) from checkpoint, the shape in current model is torch.Size([768, 3072]). 8 size mismatch for transformer.h.2.attn.c_attn.weight: copying a param with shape torch.Size([768, 2304]) from checkpoint, the shape in current model is torch.Size([2304, 768]). 9 size mismatch for transformer.h.2.mlp.c_fc.weight: copying a param with shape torch.Size([768, 3072]) from checkpoint, the shape in current model is torch.Size([3072, 768]). 10 size mismatch for transformer.h.2.mlp.c_proj.weight: copying a param with shape torch.Size([3072, 768]) from checkpoint, the shape in current model is torch.Size([768, 3072]). 11 size mismatch for transformer.h.3.attn.c_attn.weight: copying a param with shape torch.Size([768, 2304]) from checkpoint, the shape in current model is torch.Size([2304, 768]). 12 size mismatch for transformer.h.3.mlp.c_fc.weight: copying a param with shape torch.Size([768, 3072]) from checkpoint, the shape in current model is torch.Size([3072, 768]). 13 size mismatch for transformer.h.3.mlp.c_proj.weight: copying a param with shape torch.Size([3072, 768]) from checkpoint, the shape in current model is torch.Size([768, 3072]). 14 size mismatch for transformer.h.4.attn.c_attn.weight: copying a param with shape torch.Size([768, 2304]) from checkpoint, the shape in current model is torch.Size([2304, 768]). 15 size mismatch for transformer.h.4.mlp.c_fc.weight: copying a param with shape torch.Size([768, 3072]) from checkpoint, the shape in current model is torch.Size([3072, 768]). 16 size mismatch for transformer.h.4.mlp.c_proj.weight: copying a param with shape torch.Size([3072, 768]) from checkpoint, the shape in current model is torch.Size([768, 3072]). 17 size mismatch for transformer.h.5.attn.c_attn.weight: copying a param with shape torch.Size([768, 2304]) from checkpoint, the shape in current model is torch.Size([2304, 768]). 18 size mismatch for transformer.h.5.mlp.c_fc.weight: copying a param with shape torch.Size([768, 3072]) from checkpoint, the shape in current model is torch.Size([3072, 768]). 19 size mismatch for transformer.h.5.mlp.c_proj.weight: copying a param with shape torch.Size([3072, 768]) from checkpoint, the shape in current model is torch.Size([768, 3072]). 20 size mismatch for transformer.h.6.attn.c_attn.weight: copying a param with shape torch.Size([768, 2304]) from checkpoint, the shape in current model is torch.Size([2304, 768]). 21 size mismatch for transformer.h.6.mlp.c_fc.weight: copying a param with shape torch.Size([768, 3072]) from checkpoint, the shape in current model is torch.Size([3072, 768]). 22 size mismatch for transformer.h.6.mlp.c_proj.weight: copying a param with shape torch.Size([3072, 768]) from checkpoint, the shape in current model is torch.Size([768, 3072]). 23 size mismatch for transformer.h.7.attn.c_attn.weight: copying a param with shape torch.Size([768, 2304]) from checkpoint, the shape in current model is torch.Size([2304, 768]). 24 size mismatch for transformer.h.7.mlp.c_fc.weight: copying a param with shape torch.Size([768, 3072]) from checkpoint, the shape in current model is torch.Size([3072, 768]). 25 size mismatch for transformer.h.7.mlp.c_proj.weight: copying a param with shape torch.Size([3072, 768]) from checkpoint, the shape in current model is torch.Size([768, 3072]). 26 size mismatch for transformer.h.8.attn.c_attn.weight: copying a param with shape torch.Size([768, 2304]) from checkpoint, the shape in current model is torch.Size([2304, 768]). 27 size mismatch for transformer.h.8.mlp.c_fc.weight: copying a param with shape torch.Size([768, 3072]) from checkpoint, the shape in current model is torch.Size([3072, 768]). 28 size mismatch for transformer.h.8.mlp.c_proj.weight: copying a param with shape torch.Size([3072, 768]) from checkpoint, the shape in current model is torch.Size([768, 3072]). 29 size mismatch for transformer.h.9.attn.c_attn.weight: copying a param with shape torch.Size([768, 2304]) from checkpoint, the shape in current model is torch.Size([2304, 768]). 30 size mismatch for transformer.h.9.mlp.c_fc.weight: copying a param with shape torch.Size([768, 3072]) from checkpoint, the shape in current model is torch.Size([3072, 768]). 31 size mismatch for transformer.h.9.mlp.c_proj.weight: copying a param with shape torch.Size([3072, 768]) from checkpoint, the shape in current model is torch.Size([768, 3072]). 32 size mismatch for transformer.h.10.attn.c_attn.weight: copying a param with shape torch.Size([768, 2304]) from checkpoint, the shape in current model is torch.Size([2304, 768]). 33 size mismatch for transformer.h.10.mlp.c_fc.weight: copying a param with shape torch.Size([768, 3072]) from checkpoint, the shape in current model is torch.Size([3072, 768]). 34 size mismatch for transformer.h.10.mlp.c_proj.weight: copying a param with shape torch.Size([3072, 768]) from checkpoint, the shape in current model is torch.Size([768, 3072]). 35 size mismatch for transformer.h.11.attn.c_attn.weight: copying a param with shape torch.Size([768, 2304]) from checkpoint, the shape in current model is torch.Size([2304, 768]). 36 size mismatch for transformer.h.11.mlp.c_fc.weight: copying a param with shape torch.Size([768, 3072]) from checkpoint, the shape in current model is torch.Size([3072, 768]). 37 size mismatch for transformer.h.11.mlp.c_proj.weight: copying a param with shape torch.Size([3072, 768]) from checkpoint, the shape in current model is torch.Size([768, 3072]). 38 You may consider adding `ignore_mismatched_sizes=True` in the model `from_pretrained` method.
二、解决方法
这时需要将原本的权重转置后再使用Model.from_pretrained()加载模型。
1. 从Huggingface上拉模型,model_path为huggingface的repo名
1 model_path = "openai-community/gpt2" 2 model = transformers.AutoModelForCausalLM.from_pretrained(model_path, low_cpu_mem_usage=True, torch_dtype=torch.bfloat16)
2. 转置原始权重中Linear的权重矩阵
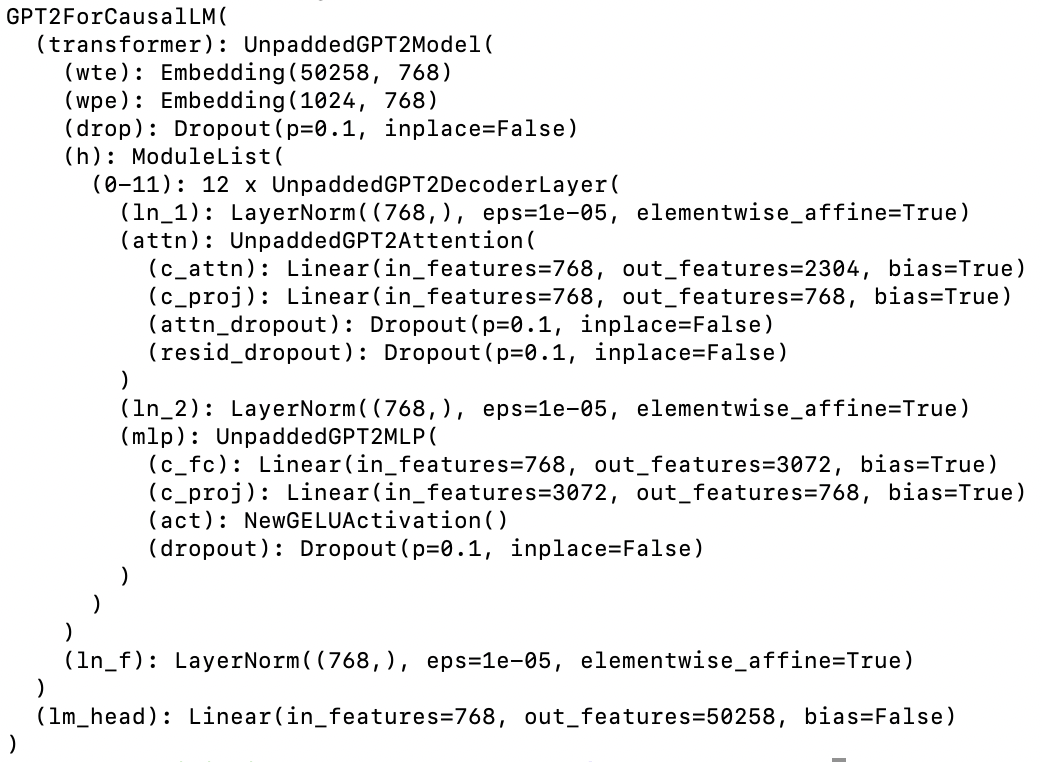
如果不确定如何获取矩阵可以先输出模型查看一下:
1 print(model)

获取权重并转置,在这里需要转置attn中的c_attn和c_proj,mlp中的c_fc和c_proj。(这几层看起来是卷积,但是代码实现实际上就是Linear层)
1 for layer in model.transformer.h: 2 layer.attn.c_attn.weight = torch.nn.Parameter(layer.attn.c_attn.weight.transpose(0, 1).contiguous()) # .contiguous()负责返回一个数据相同但内存布局连续的新张量 3 layer.attn.c_proj.weight = torch.nn.Parameter(layer.attn.c_proj.weight.transpose(0, 1).contiguous()) 4 layer.mlp.c_fc.weight = torch.nn.Parameter(layer.mlp.c_fc.weight.transpose(0, 1).contiguous()) 5 layer.mlp.c_proj.weight = torch.nn.Parameter(layer.mlp.c_proj.weight.transpose(0, 1).contiguous())
3. 最后存储model到指定路径
1 output_dir = "new_gpt2" 2 model.save_pretrained(output_dir)
这样在pytorch实现的类GPT2模型加载参数时就可以顺利从指定路径加载了:
1 model = PyTorchBasedGPT2.from_pretrained("new_gpt2") 2 print(model)
得到模型:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号