

1.0 Redis核心数据结构与高性能原理
Redis核心数据结构与高性能原理
一、安装和使用
1.1 redis安装
下载地址:http://redis.io/download
安装步骤:
# 安装gcc
yum install gcc
# 把下载好的redis-5.0.3.tar.gz放在/usr/local文件夹下,并解压
wget http://download.redis.io/releases/redis-5.0.3.tar.gz
tar -zxvf redis-5.0.3.tar.gz
cd redis-5.0.3
# 进入到解压好的redis-5.0.3目录下,进行编译与安装
make
# 修改配置
daemonize yes #后台启动
protected-mode no #关闭保护模式,开启的话,只有本机才可以访问redis
# 需要注释掉bind
#bind 127.0.0.1(bind绑定的是自己机器网卡的ip,如果有多块网卡可以配多个ip,代表允许客户端通过机器的哪些网卡ip去访问,内网一般可以不配置bind,注释掉即可)
# 启动服务
src/redis-server redis.conf
# 验证启动是否成功
ps -ef | grep redis
# 进入redis客户端
src/redis-cli
# 退出客户端
quit
# 退出redis服务:
(1)pkill redis-server
(2)kill 进程号
(3)src/redis-cli shutdown
1.2 redis数据类型常用操作和应用类型
https://redis.io/commands/?group=string
1.2.1 字符串
字符串常用操作
SET key value //存入字符串键值对
MSET key value [key value ...] //批量存储字符串键值对
SETNX key value //存入一个不存在的字符串键值对
GET key //获取一个字符串键值
MGET key [key ...] //批量获取字符串键值
DEL key [key ...] //删除一个键
EXPIRE key seconds //设置一个键的过期时间(秒)
原子操作
INCR key //将key中储存的数字值加1
DECR key //将key中储存的数字值减1
INCRBY key increment //将key所储存的值加上increment
DECRBY key decrement //将key所储存的值减去decrement
应用场景
// 单值缓存
SET key value
GET key
// 对象缓存
SET user:1 value(json格式数据)
MSET user:1:name zhuge user:1:balance 1888
MGET user:1:name user:1:balance
// 分布式锁
SETNX product:10001 true //返回1代表获取锁成功
SETNX product:10001 true //返回0代表获取锁失败
执行业务操作
DEL product:10001 //执行完业务释放锁
SET product:10001 true ex 10 nx //防止程序意外终止导致死锁
// 计数器
INCR article:readcount:{文章id}
GET article:readcount:{文章id}
// Web集群session共享
spring session + redis实现session共享
// 分布式系统全局序列号
INCRBY orderId 1000 //redis批量生成序列号提升性能
1.2.2 Hash表
HSET key field value //存储一个哈希表key的键值
HSETNX key field value //存储一个不存在的哈希表key的键值
HMSET key field value [field value ...] //在一个哈希表key中存储多个键值对
HGET key field //获取哈希表key对应的field键值
HMGET key field [field ...] //批量获取哈希表key中多个field键值
HDEL key field [field ...] //删除哈希表key中的field键值
HLEN key //返回哈希表key中field的数量
HGETALL key //返回哈希表key中所有的键值
HINCRBY key field increment //为哈希表key中field键的值加上增量increment
应用场景
// 对象缓存
HMSET user {userId}:name zhuge {userId}:balance 1888
HMSET user 1:name zhuge 1:balance 1888
HMGET user 1:name 1:balance
举例
电商购物车
1)以用户id为key
2)商品id为field
3)商品数量为value
购物车操作
添加商品 hset cart:1001 10088 1
增加数量 hincrby cart:1001 10088 1
商品总数 hlen cart:1001
删除商品 hdel cart:1001 10088
获取购物车所有商品 hgetall cart:1001
优点
- 同类数据归类整合储存,方便数据管理
- 相比string操作消耗内存与cpu更小
- 相比string储存更节省空间
缺点
- 过期功能不能使用在field上,只能用在key上
- Redis集群架构下不适合大规模使用
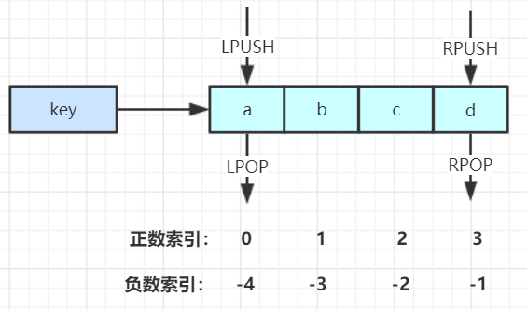
1.2.3 List
LPUSH key value [value ...] //将一个或多个值value插入到key列表的表头(最左边)
RPUSH key value [value ...] //将一个或多个值value插入到key列表的表尾(最右边)
LPOP key //移除并返回key列表的头元素
RPOP key //移除并返回key列表的尾元素
LRANGE key start stop //返回列表key中指定区间内的元素,区间以偏移量start和stop指定
BLPOP key [key ...] timeout //从key列表表头弹出一个元素,若列表中没有元素,阻塞等待 timeout秒,如果timeout=0,一直阻塞等待
BRPOP key [key ...] timeout //从key列表表尾弹出一个元素,若列表中没有元素,阻塞等待 timeout秒,如果timeout=0,一直阻塞等待
可用数据结构
Stack(栈) = LPUSH + LPOP
Queue(队列)= LPUSH + RPOP
Blocking MQ(阻塞队列)= LPUSH + BRPOP
应用场景
// 微信公众号,微博,QQ空间等消息流推送
MacTalk发微博,消息ID为10018 LPUSH msg:{用户ID} 10018
备胎说车发微博,消息ID为10086 LPUSH msg:{用户ID} 10086
查看最新微博消息 LRANGE msg:{用户ID} 0 4
1.2.4 Set
// Set常用操作
SADD key member [member ...] //往集合key中存入元素,元素存在则忽略,若key不存在则新建
SREM key member [member ...] //从集合key中删除元素
SMEMBERS key //获取集合key中所有元素
SCARD key //获取集合key的元素个数
SISMEMBER key member //判断member元素是否存在于集合key中
SRANDMEMBER key [count] //从集合key中选出count个元素,元素不从key中删除
SPOP key [count] //从集合key中选出count个元素,元素从key中删除
// Set运算操作
SINTER key [key ...] //交集运算
SINTERSTORE destination key [key ..] //将交集结果存入新集合destination中
SUNION key [key ..] //并集运算
SUNIONSTORE destination key [key ...] //将并集结果存入新集合destination中
SDIFF key [key ...] //差集运算
SDIFFSTORE destination key [key ...] //将差集结果存入新集合destination中
应用场景
// 微信公众号的抽奖系统
点击参与抽奖加入集合 SADD key {userlD}
查看参与抽奖所有用户 SMEMBERS key
抽取count名中奖者 SRANDMEMBER key [count] / SPOP key [count]
// 微信点赞系统/收藏
点赞 SADD like:{消息ID} {用户ID}
取消点赞 SREM like:{消息ID} {用户ID}
检查用户是否点过赞 SISMEMBER like:{消息ID} {用户ID}
获取点赞的用户列表 SMEMBERS like:{消息ID}
获取点赞用户数 SCARD like:{消息ID}
// 微博微信关注模型
1) 诸葛关注的人:
zhugeSet-> {guojia, xushu}
2) 杨过关注的人:
yangguoSet--> {zhuge, baiqi, guojia, xushu}
3) 郭嘉关注的人:
guojiaSet-> {zhuge, yangguo, baiqi, xushu, xunyu)
4) 诸葛和杨过共同关注:
SINTER zhugeSet yangguoSet--> {guojia, xushu}
5) 诸葛关注的人也关注他(杨过):
SISMEMBER guojiaSet yangguo
SISMEMBER xushuSet yangguo
6) 诸葛可能认识的人:
SDIFF yangguoSet zhugeSet->(zhuge, baiqi}
// 集合操作实现电商商品筛选
SADD brand:huawei P40
SADD brand:xiaomi mi-10
SADD brand:iPhone iphone12
SADD os:android P40 mi-10
SADD cpu:brand:intel P40 mi-10
SADD ram:8G P40 mi-10 iphone12
SINTER os:android cpu:brand:intel ram:8G {P40,mi-10}
1.2.5 ZSet
// 常用操作
ZADD key score member [[score member]…] //往有序集合key中加入带分值元素
ZREM key member [member …] //从有序集合key中删除元素
ZSCORE key member //返回有序集合key中元素member的分值
ZINCRBY key increment member //为有序集合key中元素member的分值加上increment
ZCARD key //返回有序集合key中元素个数
ZRANGE key start stop [WITHSCORES] //正序获取有序集合key从start下标到stop下标的元素
ZREVRANGE key start stop [WITHSCORES] //倒序获取有序集合key从start下标到stop下标的元素
// 集合操作
ZUNIONSTORE destkey numkeys key [key ...] //并集计算
ZINTERSTORE destkey numkeys key [key …] //交集计算
应用场景
// Zset集合操作实现排行榜
点击新闻 ZINCRBY hotNews:20190819 1 守护香港
展示当日排行前十 ZREVRANGE hotNews:20190819 0 9 WITHSCORES
七日搜索榜单计算 ZUNIONSTORE hotNews:20190813-20190819 7 hotNews:20190813 ... hotNews:20190819
展示七日排行前十 ZREVRANGE hotNews:20190813-20190819 0 9 WITHSCORES
1.2.6 bitmap
bitmap 存储的是连续的二进制数字(0 和 1),通过 bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 bitmap 本身会极大的节省储存空间。
setbit 、getbit 、bitcount、bitop
1.2.7 HyperLogLogs基数统计
基数并不一定准确,是一个带有 0.81% 标准错误的近似值
这个结构可以非常省内存的去统计各种计数,比如注册 IP 数、每日访问 IP 数、页面实时UV、在线用户数,共同好友数等
少量固定的内存去存储并识别集合中的唯一元素
pfadd,pfcount,pfmerge
1.2.8 geospatial 地理位置
经度从-180度到180度。
纬度从-85.05112878度到85.05112878度
// 添加经纬度
geoadd china:city 118.76.32.04 manjing 112.55 37.86 taiyuan
// 获取经纬度
geopos china:city taiyuan manjing
// 获取俩地位置,不存在返回空(m km mi 英里 ft 英尺)附近的人(定位, 通过半径来查询)
geodist china:city taiyuan shenyang km
// 参数 key 经度 纬度 半径 单位 [显示结果的经度和纬度] [显示结果的距离] [显示的结果的数量]
georadius china:city 110 30 1000 km withcoord withdist count 2
// 显示与指定成员一定半径范围内的其他成员(参数同georadius)
georadiusbymember china:city taiyuan 1000 km withcoord withdist count 2
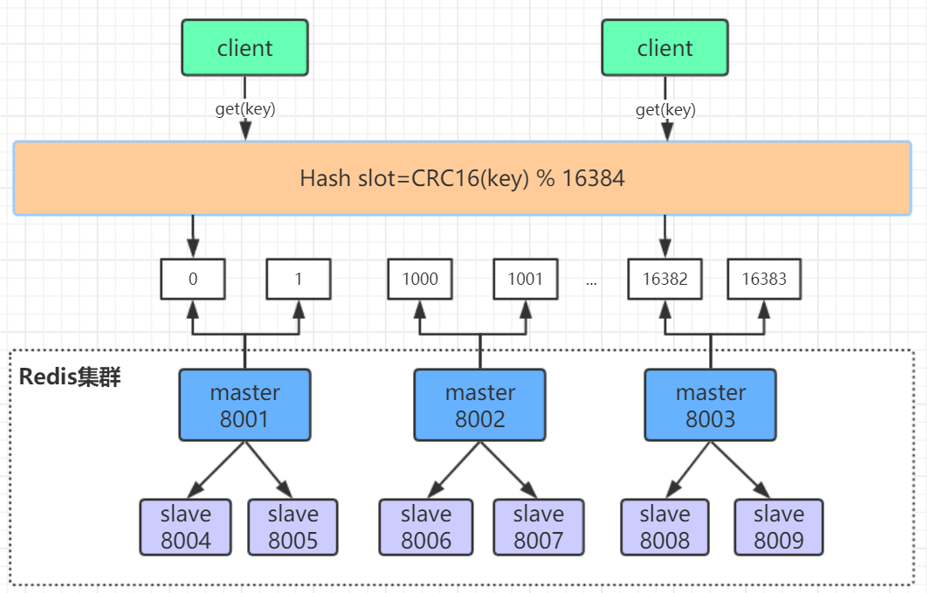
二、 Redis的单线程和高性能
Redis是单线程吗?
Redis 的单线程主要是指 Redis 的网络 IO 和键值对读写是由一个线程来完成的,这也是 Redis 对外提供键值存储服务的主要流程。但 Redis 的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的。
Redis 单线程为什么还能这么快?
因为它所有的数据都在内存中,所有的运算都是内存级别的运算,而且单线程避免了多线程的切换性能损耗问题。正因为 Redis 是单线程,所以要小心使用 Redis 指令,对于那些耗时的指令(比如keys),一定要谨慎使用,一不小心就可能会导致 Redis 卡顿。
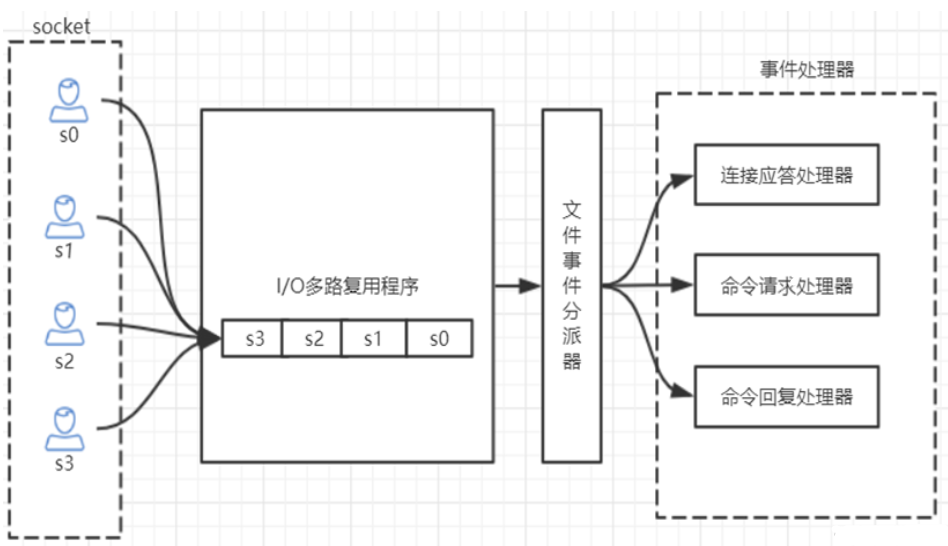
Redis 单线程如何处理那么多的并发客户端连接?
Redis的IO多路复用:redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到文件事件分派器,事件分派器将事件分发给事件处理器。
# 查看redis支持的最大连接数,在redis.conf文件中可修改,# maxclients 10000
127.0.0.1:6379> CONFIG GET maxclients
##1) "maxclients"
##2) "10000"
2.1 高级命令
2.1.1 keys
全量遍历键,用来列出所有满足特定正则字符串规则的key,当redis数据量比较大时,性能比较差,要避免使用
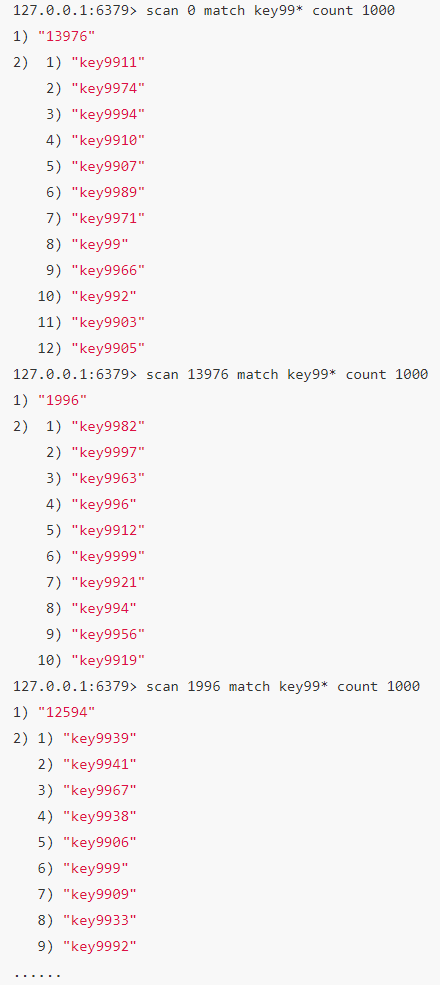
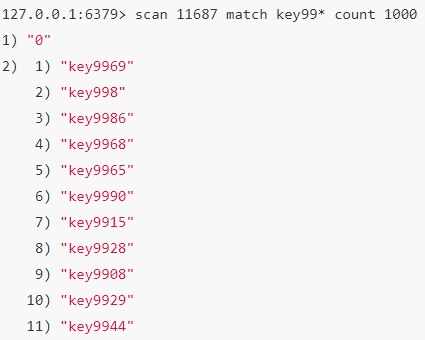
2.1.2 scan
渐进式遍历键
SCAN cursor [MATCH pattern] [COUNT count]
scan 参数提供了三个参数,第一个是 cursor 整数值(hash桶的索引值),第二个是 key 的正则模式,第三个是一次遍历的key的数量(参考值,底层遍历的数量不一定),并不是符合条件的结果数量。第一次遍历时,cursor 值为 0,然后将返回结果中第一个整数值作为下一次遍历的 cursor。一直遍历到返回的 cursor 值为 0 时结束。
注意:但是scan并非完美无瑕, 如果在scan的过程中如果有键的变化(增加、 删除、 修改) ,那么遍历效果可能会碰到如下问题: 新增的键可能没有遍历到, 遍历出了重复的键等情况, 也就是说scan并不能保证完整的遍历出来所有的键, 这些是我们在开发时需要考虑的。
2.1.3 Info
查看redis服务运行信息,分为 9 大块,每个块都有非常多的参数,这 9 个块分别是:
Server 服务器运行的环境参数
Clients 客户端相关信息
Memory 服务器运行内存统计数据
Persistence 持久化信息
Stats 通用统计数据
Replication 主从复制相关信息
CPU CPU 使用情况
Cluster 集群信息
KeySpace 键值对统计数量信息
connected_clients:2 # 正在连接的客户端数量
instantaneous_ops_per_sec:789 # 每秒执行多少次指令
used_memory:929864 # Redis分配的内存总量(byte),包含redis进程内部的开销和数据占用的内存
used_memory_human:908.07K # Redis分配的内存总量(Kb,human会展示出单位)
used_memory_rss_human:2.28M # 向操作系统申请的内存大小(Mb)(这个值一般是大于used_memory的,因为Redis的内存分配策略会产生内存碎片)
used_memory_peak:929864 # redis的内存消耗峰值(byte)
used_memory_peak_human:908.07K # redis的内存消耗峰值(KB)
maxmemory:0 # 配置中设置的最大可使用内存值(byte),默认0,不限制,一般配置为机器物理内存的百分之七八十,需要留一部分给操作系统
maxmemory_human:0B # 配置中设置的最大可使用内存值
maxmemory_policy:noeviction # 当达到maxmemory时的淘汰策略

 浙公网安备 33010602011771号
浙公网安备 33010602011771号