

12.0 Disruptor&Future&CompletableFuture
Disruptor&Future&CompletableFuture
一、Disruptor
Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题(在性能测试中发现竟然与I/O操作处于同样的数量级)。基于Disruptor开发的系统单线程能支撑每秒600万订单,2010年在QCon演讲后,获得了业界关注。2011年,企业应用软件专家Martin Fowler专门撰写长文介绍。同年它还获得了Oracle官方的Duke大奖。目前,包括Apache Storm、Camel、Log4j 2在内的很多知名项目都应用了Disruptor以获取高性能。注意,这里所说的队列是系统内部的内存队列,而不是Kafka这样的分布式队列。
Github:https://github.com/LMAX-Exchange/disruptor
Disruptor实现了队列的功能并且是一个有界队列,可以用于生产者-消费者模型。
1.1 juc下队列存在的问题
| 队列 | 描述 |
|---|---|
| ArrayBlockingQueue | 基于数组结构实现的一个有界阻塞队列 |
| LinkedBlockingQueue | 基于链表结构实现的一个无界阻塞队列,指定容量为有界阻塞队列 |
| PriorityBlockingQueue | 支持按优先级排序的无界阻塞队列 |
| DelayQueue | 基于优先级队列(PriorityBlockingQueue)实现的无界阻塞队列 |
| SynchronousQueue | 不存储元素的阻塞队列 |
| LinkedTransferQueue | 基于链表结构实现的一个无界阻塞队列 |
| LinkedBlockingDeque | 基于链表结构实现的一个双端阻塞队列 |
https://www.processon.com/view/link/618ce3941e0853689b0818e2
-
juc下的队列大部分采用加ReentrantLock锁方式保证线程安全。在稳定性要求特别高的系统中,为了防止生产者速度过快,导致内存溢出,只能选择有界队列。
-
加锁的方式通常会严重影响性能。线程会因为竞争不到锁而被挂起,等待其他线程释放锁而唤醒,这个过程存在很大的开销,而且存在死锁的隐患。
-
有界队列通常采用数组实现。但是采用数组实现又会引发另外一个问题false sharing(伪共享)。
1.2 Disruptor的设计方案
Disruptor通过以下设计来解决队列速度慢的问题:
- 环形数组结构
为了避免垃圾回收,采用数组而非链表。同时,数组对处理器的缓存机制更加友好(空间局部性原理)。
- 元素位置定位
数组长度2^n,通过位运算,加快定位的速度。下标采取递增的形式。不用担心index溢出的问题。index是long类型,即使100万QPS的处理速度,也需要30万年才能用完。
- 无锁设计
每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据。
- 利用缓存行填充解决了伪共享的问题
- 实现了基于事件驱动的生产者消费者模型(观察者模式)
消费者时刻关注着队列里有没有消息,一旦有新消息产生,消费者线程就会立刻把它消费
1.3 RingBuffer数据结构
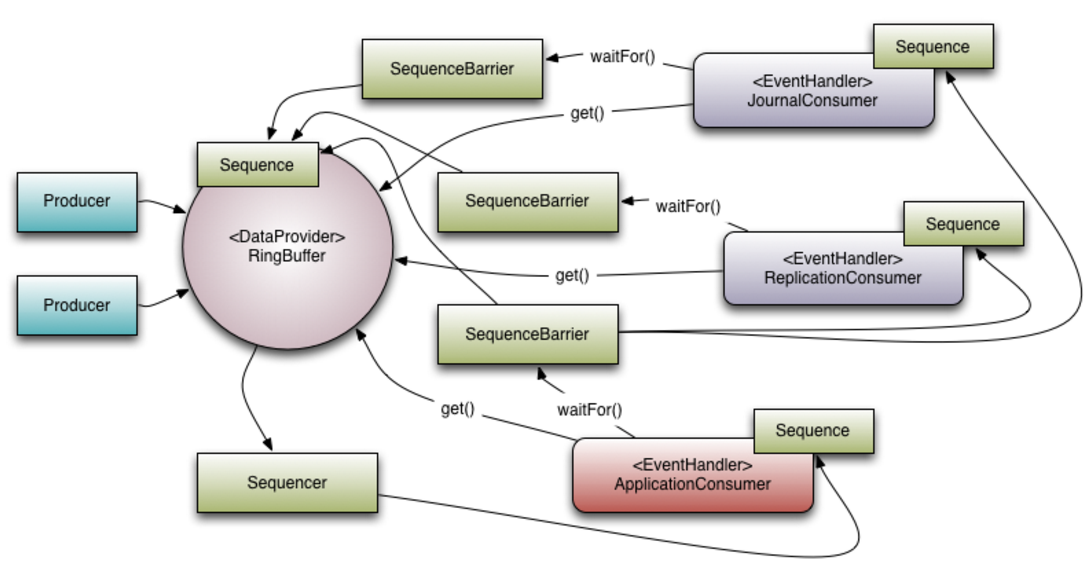
使用RingBuffer来作为队列的数据结构,RingBuffer就是一个可自定义大小的环形数组。除数组外还有一个序列号(sequence),用以指向下一个可用的元素,供生产者与消费者使用。原理图如下所示:
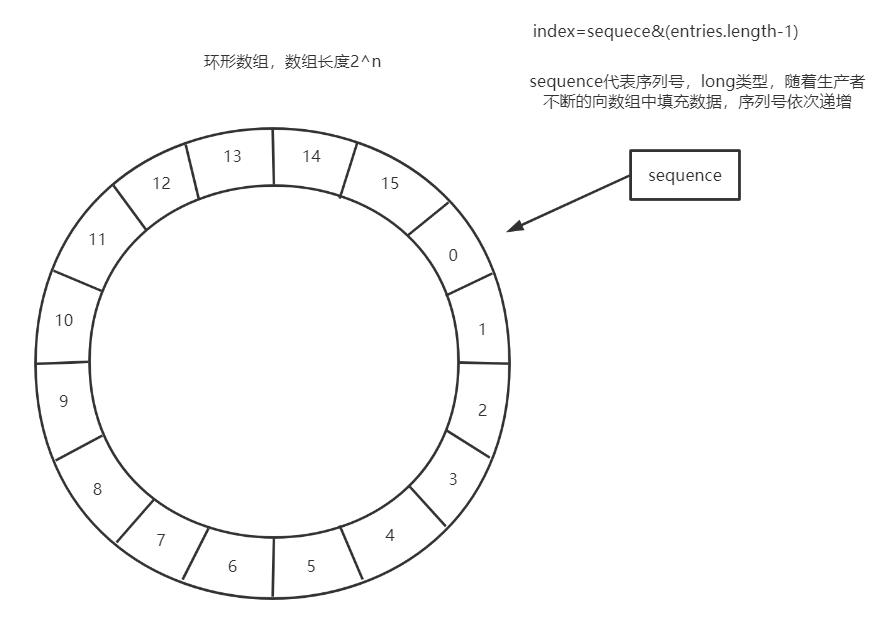
- Disruptor要求设置数组长度为2的n次幂。在知道索引(index)下标的情况下,存与取数组上的元素时间复杂度只有O(1),而这个index我们可以通过序列号与数组的长度取模来计算得出,index=sequence % entries.length。也可以用位运算来计算效率更高,此时array.length必须是2的幂次方,index=sequece&(entries.length-1)
- 当所有位置都放满了,再放下一个时,就会把0号位置覆盖掉
思考:能覆盖数据是否会导致数据丢失呢?
当需要覆盖数据时,会执行一个策略,Disruptor给提供多种策略,比较常用的:
- BlockingWaitStrategy策略,常见且默认的等待策略,当这个队列里满了,不执行覆盖,而是阻塞等待。使用ReentrantLock+Condition实现阻塞,最节省cpu,但高并发场景下性能最差。适合CPU资源紧缺,吞吐量和延迟并不重要的场景
- SleepingWaitStrategy策略,会在循环中不断等待数据。先进行自旋等待如果不成功,则使用Thread.yield()让出CPU,并最终使用LockSupport.parkNanos(1L)进行线程休眠,以确保不占用太多的CPU资源。因此这个策略会产生比较高的平均延时。典型的应用场景就是异步日志。
- YieldingWaitStrategy策略,这个策略用于低延时的场合。消费者线程会不断循环监控缓冲区变化,在循环内部使用Thread.yield()让出CPU给别的线程执行时间。如果需要一个高性能的系统,并且对延时比较有严格的要求,可以考虑这种策略。
- BusySpinWaitStrategy策略: 采用死循环,消费者线程会尽最大努力监控缓冲区的变化。对延时非常苛刻的场景使用,cpu核数必须大于消费者线程数量。推荐在线程绑定到固定的CPU的场景下使用
1.4 读写的规则
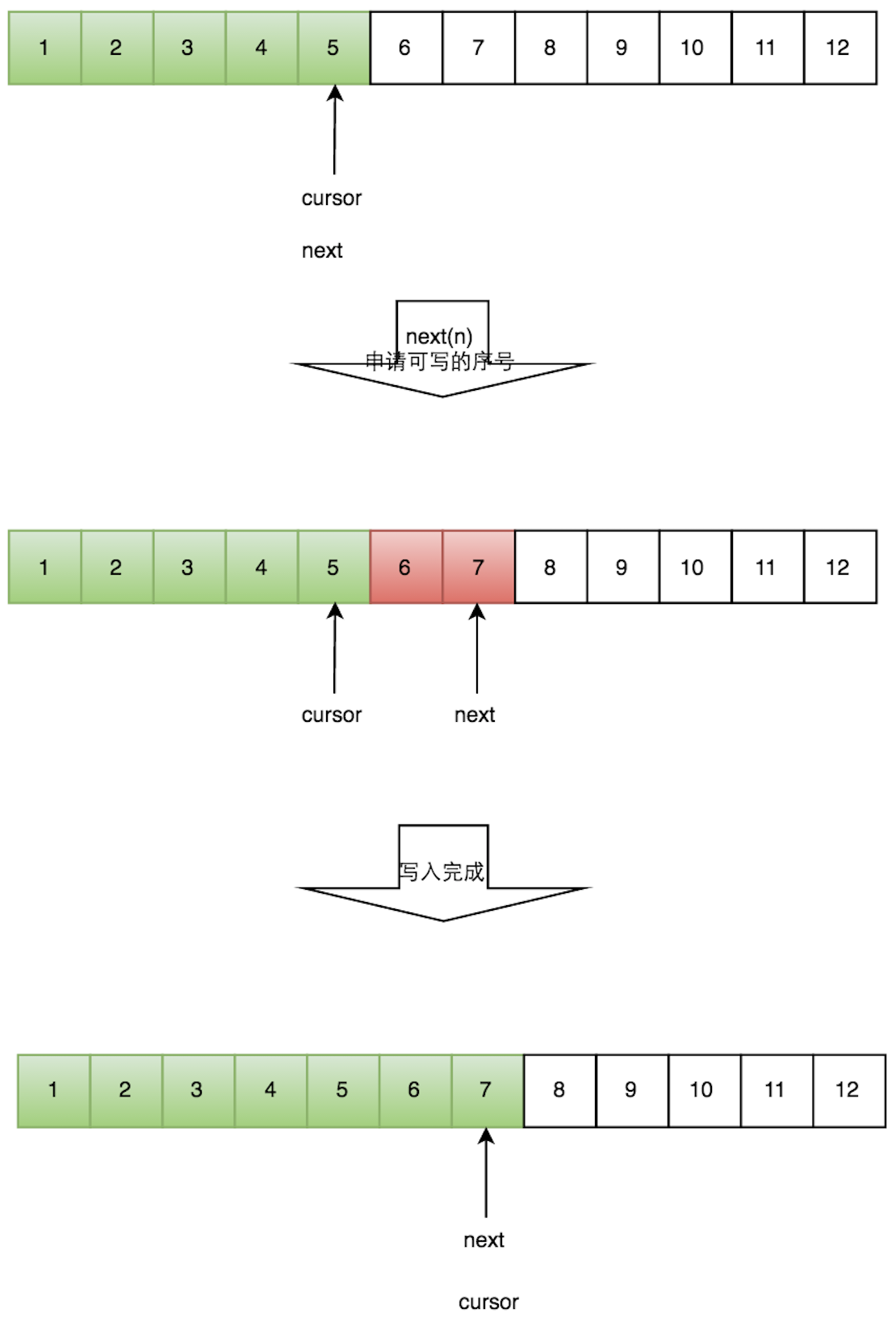
1.4.1 一个生产者单线程写数据的流程
- 申请写入m个元素;
- 若是有m个元素可以写入,则返回最大的序列号。这里主要判断是否会覆盖未读的元素;
- 若是返回的正确,则生产者开始写入元素。
1.4.2 多个生产者写数据的流程
多个生产者的情况下,会遇到“如何防止多个线程重复写同一个元素”的问题。Disruptor的解决方法是每个线程获取不同的一段数组空间进行操作。这个通过CAS很容易达到。只需要在分配元素的时候,通过CAS判断一下这段空间是否已经分配出去即可。
但是会遇到一个新问题:如何防止读取的时候,读到还未写的元素。Disruptor在多个生产者的情况下,引入了一个与Ring Buffer大小相同的buffer:available Buffer。当某个位置写入成功的时候,便把availble Buffer相应的位置置位,标记为写入成功。读取的时候,会遍历available Buffer,来判断元素是否已经就绪。
1.4.3 消费者读数据
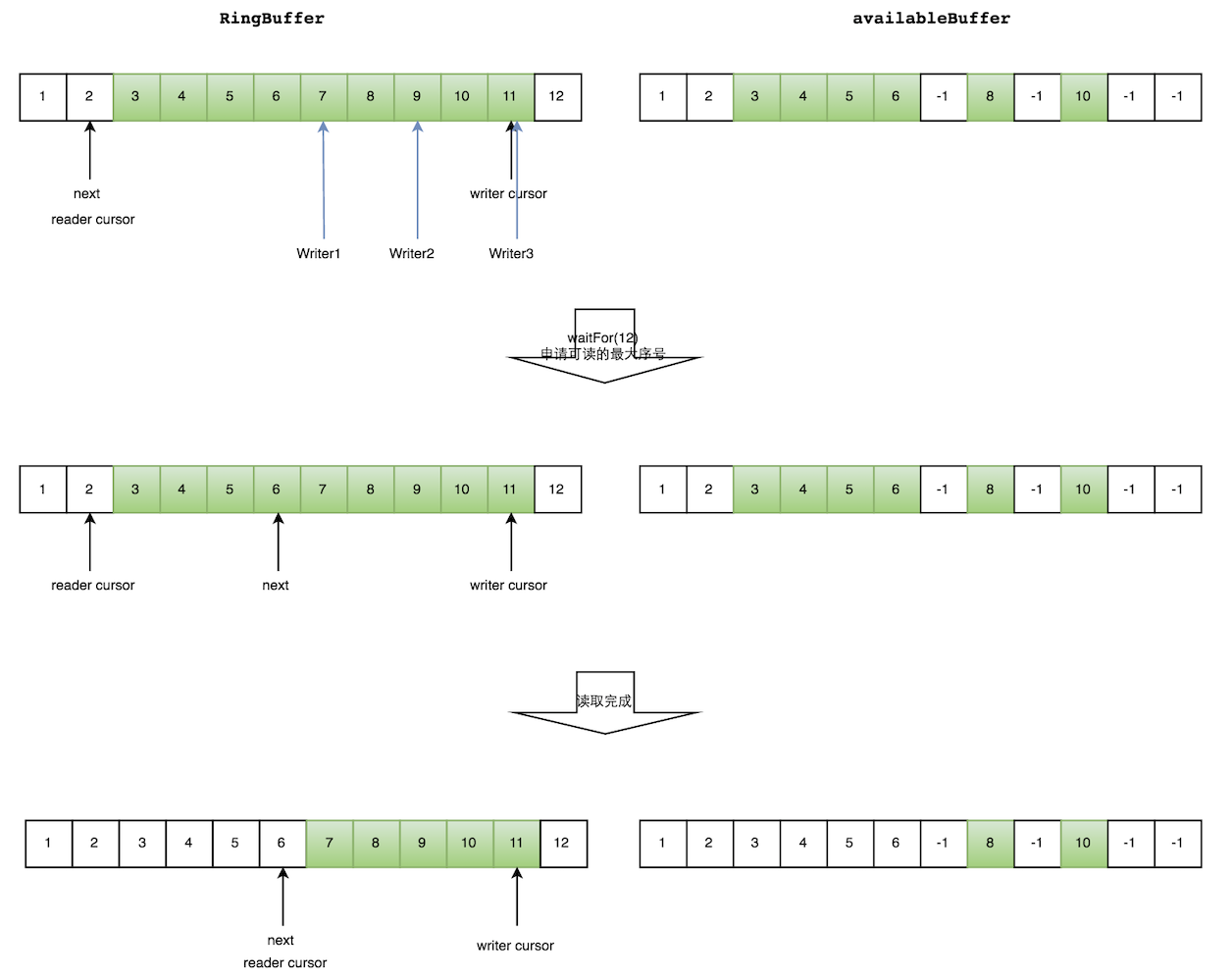
生产者多线程写入的情况下读数据会复杂很多:
- 申请读取到序号n;
- 若writer cursor >= n,这时仍然无法确定连续可读的最大下标。从reader cursor开始读取available Buffer,一直查到第一个不可用的元素,然后返回最大连续可读元素的位置;
- 消费者读取元素。
如下图所示,读线程读到下标为2的元素,三个线程Writer1/Writer2/Writer3正在向RingBuffer相应位置写数据,写线程被分配到的最大元素下标是11。读线程申请读取到下标从3到11的元素,判断writer cursor>=11。然后开始读取availableBuffer,从3开始,往后读取,发现下标为7的元素没有生产成功,于是WaitFor(11)返回6。然后,消费者读取下标从3到6共计4个元素。
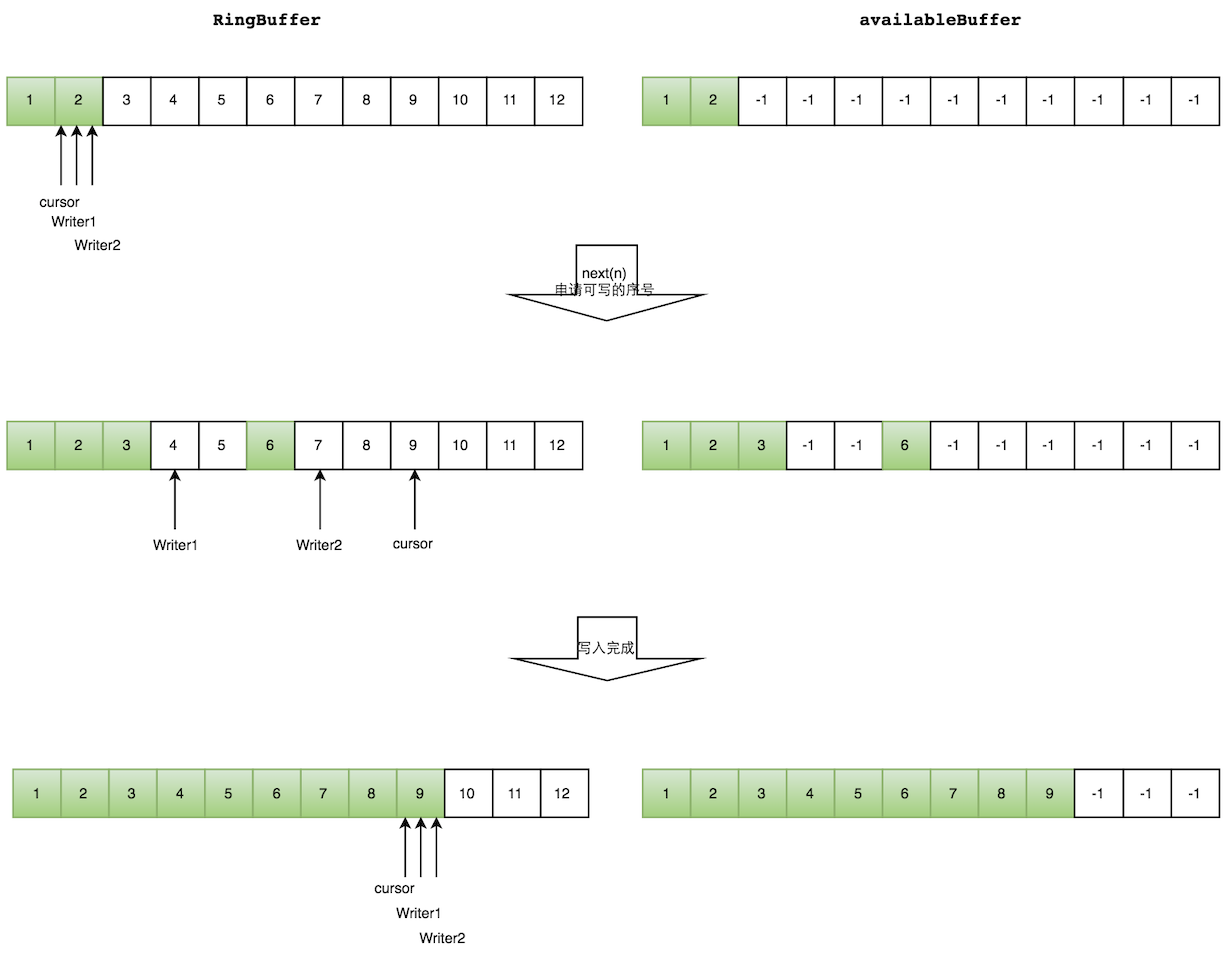
1.4.4 多个生产者写数据
多个生产者写入的时候:
- 申请写入m个元素;
- 若是有m个元素可以写入,则返回最大的序列号。每个生产者会被分配一段独享的空间;
- 生产者写入元素,写入元素的同时设置available Buffer里面相应的位置,以标记自己哪些位置是已经写入成功的。
如下图所示,Writer1和Writer2两个线程写入数组,都申请可写的数组空间。Writer1被分配了下标3到下表5的空间,Writer2被分配了下标6到下标9的空间。Writer1写入下标3位置的元素,同时把available Buffer相应位置置位,标记已经写入成功,往后移一位,开始写下标4位置的元素。Writer2同样的方式。最终都写入完成。
1.5 Disruptor核心概念
-
RingBuffer(环形缓冲区):基于数组的内存级别缓存,是创建sequencer(序号)与定义WaitStrategy(拒绝策略)的入口。
-
Disruptor(总体执行入口):对RingBuffer的封装,持有RingBuffer、消费者线程池Executor、消费之集合ConsumerRepository等引用。
-
Sequence(序号分配器):对RingBuffer中的元素进行序号标记,通过顺序递增的方式来管理进行交换的数据(事件/Event),一个Sequence可以跟踪标识某个事件的处理进度,同时还能消除伪共享。
-
Sequencer(数据传输器):Sequencer里面包含了Sequence,是Disruptor的核心,Sequencer有两个实现类:SingleProducerSequencer(单生产者实现)、MultiProducerSequencer(多生产者实现),Sequencer主要作用是实现生产者和消费者之间快速、正确传递数据的并发算法
-
SequenceBarrier(消费者屏障):用于控制RingBuffer的Producer和Consumer之间的平衡关系,并且决定了Consumer是否还有可处理的事件的逻辑。
-
WaitStrategy(消费者等待策略):决定了消费者如何等待生产者将Event生产进Disruptor,WaitStrategy有多种实现策略
-
Event:从生产者到消费者过程中所处理的数据单元,Event由使用者自定义。
-
EventHandler:由用户自定义实现,就是我们写消费者逻辑的地方,代表了Disruptor中的一个消费者的接口。
-
EventProcessor:这是个事件处理器接口,实现了Runnable,处理主要事件循环,处理Event,拥有消费者的Sequence
1.6 Disruptor的使用
引入依赖
<!-- disruptor -->
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.3.4</version>
</dependency>
Disruptor构造器
public Disruptor(
final EventFactory<T> eventFactory,
final int ringBufferSize,
final ThreadFactory threadFactory,
final ProducerType producerType,
final WaitStrategy waitStrategy)
- EventFactory:创建事件(任务)的工厂类。
- ringBufferSize:容器的长度。
- ThreadFactory :用于创建执行任务的线程。
- ProductType:生产者类型:单生产者、多生产者。
- WaitStrategy:等待策略。
1.6.1 单生产者单消费者模式
1.创建Event(消息载体/事件)和EventFactory(事件工厂)
创建 OrderEvent 类,这个类将会被放入环形队列中作为消息内容。创建OrderEventFactory类,用于创建OrderEvent事件
@Data
public class OrderEvent {
private long value;
private String name;
}
public class OrderEventFactory implements EventFactory<OrderEvent> {
@Override
public OrderEvent newInstance() {
return new OrderEvent();
}
2. 创建消息(事件)生产者
创建 OrderEventProducer 类,它将作为生产者使用
public class OrderEventProducer {
//事件队列
private RingBuffer<OrderEvent> ringBuffer;
public OrderEventProducer(RingBuffer<OrderEvent> ringBuffer) {
this.ringBuffer = ringBuffer;
}
public void onData(long value,String name) {
// 获取事件队列 的下一个槽
long sequence = ringBuffer.next();
try {
//获取消息(事件)
OrderEvent orderEvent = ringBuffer.get(sequence);
// 写入消息数据
orderEvent.setValue(value);
orderEvent.setName(name);
} catch (Exception e) {
// TODO 异常处理
e.printStackTrace();
} finally {
System.out.println("生产者发送数据value:"+value+",name:"+name);
//发布事件
ringBuffer.publish(sequence);
}
}
3.创建消费者
创建 OrderEventHandler 类,并实现 EventHandler ,作为消费者。
public class OrderEventHandler implements EventHandler<OrderEvent> {
@Override
public void onEvent(OrderEvent event, long sequence, boolean endOfBatch) throws Exception {
// TODO 消费逻辑
System.out.println("消费者获取数据value:"+ event.getValue()+",name:"+event.getName());
}
4. 测试
public class DisruptorDemo {
public static void main(String[] args) throws Exception {
//创建disruptor
Disruptor<OrderEvent> disruptor = new Disruptor<>(
new OrderEventFactory(),
1024 * 1024,
Executors.defaultThreadFactory(),
ProducerType.SINGLE, //单生产者
new YieldingWaitStrategy() //等待策略
);
//设置消费者用于处理RingBuffer的事件
disruptor.handleEventsWith(new OrderEventHandler());
disruptor.start();
//创建ringbuffer容器
RingBuffer<OrderEvent> ringBuffer = disruptor.getRingBuffer();
//创建生产者
OrderEventProducer eventProducer = new OrderEventProducer(ringBuffer);
//发送消息
for(int i=0;i<100;i++){
eventProducer.onData(i,"Fox"+i);
}
disruptor.shutdown();
}
1.6.2 单生产者多消费者模式
如果消费者是多个,只需要在调用 handleEventsWith 方法时将多个消费者传递进去。
- disruptor.handleEventsWith(new OrderEventHandler());
上面传入的两个消费者会重复消费每一条消息,如果想实现一条消息在有多个消费者的情况下,只会被一个消费者消费,那么需要调用 handleEventsWithWorkerPool 方法。
注意:消费者要实现WorkHandler接口
public class OrderEventHandler implements EventHandler<OrderEvent>, WorkHandler<OrderEvent> {
@Override
public void onEvent(OrderEvent event, long sequence, boolean endOfBatch) throws Exception {
// TODO 消费逻辑
System.out.println("消费者"+ Thread.currentThread().getName()
+"获取数据value:"+ event.getValue()+",name:"+event.getName());
}
@Override
public void onEvent(OrderEvent event) throws Exception {
// TODO 消费逻辑
System.out.println("消费者"+ Thread.currentThread().getName()
+"获取数据value:"+ event.getValue()+",name:"+event.getName());
}
1.6.3 多生产者多消费者模式
在实际开发中,多个生产者发送消息,多个消费者处理消息才是常态。
public class DisruptorDemo2 {
public static void main(String[] args) throws Exception {
//创建disruptor
Disruptor<OrderEvent> disruptor = new Disruptor<>(
new OrderEventFactory(),
1024 * 1024,
Executors.defaultThreadFactory(),
ProducerType.MULTI, //多生产者
new YieldingWaitStrategy() //等待策略
);
//设置消费者用于处理RingBuffer的事件
//disruptor.handleEventsWith(new OrderEventHandler());
//设置多消费者,消息会被重复消费
//disruptor.handleEventsWith(new OrderEventHandler(),new OrderEventHandler());
//设置多消费者,消费者要实现WorkHandler接口,一条消息只会被一个消费者消费
disruptor.handleEventsWithWorkerPool(new OrderEventHandler(), new OrderEventHandler());
//启动disruptor
disruptor.start();
//创建ringbuffer容器
RingBuffer<OrderEvent> ringBuffer = disruptor.getRingBuffer();
new Thread(()->{
//创建生产者
OrderEventProducer eventProducer = new OrderEventProducer(ringBuffer);
// 发送消息
for(int i=0;i<100;i++){
eventProducer.onData(i,"Fox"+i);
}
},"producer1").start();
new Thread(()->{
//创建生产者
OrderEventProducer eventProducer = new OrderEventProducer(ringBuffer);
// 发送消息
for(int i=0;i<100;i++){
eventProducer.onData(i,"monkey"+i);
}
},"producer2").start();
//disruptor.shutdown();
}
1.6.4 消费者优先级模式
在实际场景中,我们通常会因为业务逻辑而形成一条消费链。比如一个消息必须由 消费者A -> 消费者B -> 消费者C 的顺序依次进行消费。在配置消费者时,可以通过 .then 方法去实现顺序消费。
disruptor.handleEventsWith(new OrderEventHandler())
.then(new OrderEventHandler())
handleEventsWith 与 handleEventsWithWorkerPool 都是支持 .then 的,它们可以结合使用。比如可以按照 消费者A -> (消费者B 消费者C) -> 消费者D 的消费顺序
disruptor.handleEventsWith(new OrderEventHandler())
.thenHandleEventsWithWorkerPool(new OrderEventHandler(), new OrderEventHandler())
.then(new OrderEventHandler());
二、Callable&Future&FutureTask
直接继承Thread或者实现Runnable接口都可以创建线程,但是这两种方法都有一个问题就是:没有返回值,也就是不能获取执行完的结果。因此java1.5就提供了Callable接口来实现这一场景,而Future和FutureTask就可以和Callable接口配合起来使用。
2.1 Callable和Runnable的区别
思考:为什么需要 Callable?
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
@FunctionalInterface
public interface Callable<V> {
V call() throws Exception;
}
Runnable 的缺陷:
- 不能返回一个返回值
- 不能抛出 checked Exception
Callable解决了上面的问题
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("通过Runnable方式执行任务");
}
}).start();
FutureTask task = new FutureTask(new Callable() {
@Override
public Object call() throws Exception {
System.out.println("通过Callable方式执行任务");
Thread.sleep(3000);
return "返回任务结果";
}
});
new Thread(task).start();
2.2 Future
Future就是对于具体的Runnable或者Callable任务的执行结果进行取消、查询是否完成、获取结果。必要时可以通过get方法获取执行结果,该方法会阻塞直到任务返回结果。
// 取消任务的执行。参数指定是否立即中断任务执行,或者等等任务结束
boolean cancel (boolean mayInterruptIfRunning)
// 任务是否已经取消,任务正常完成前将其取消,则返回 true
boolean isCancelled ()
// 任务是否已经完成。需要注意的是如果任务正常终止、异常或取消,都将返回true
boolean isDone ()
// 等待任务执行结束,然后获得V类型的结果。InterruptedException 线程被中断异常, ExecutionException任务执行异常,如果任务被取消,还会抛出CancellationException
V get () throws InterruptedException, ExecutionException
// 同上面的get功能一样,多了设置超时时间。参数timeout指定超时时间,uint指定时间的单位,在枚举类TimeUnit中有相关的定义。如果计算超时,将抛出TimeoutException
V get (long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException
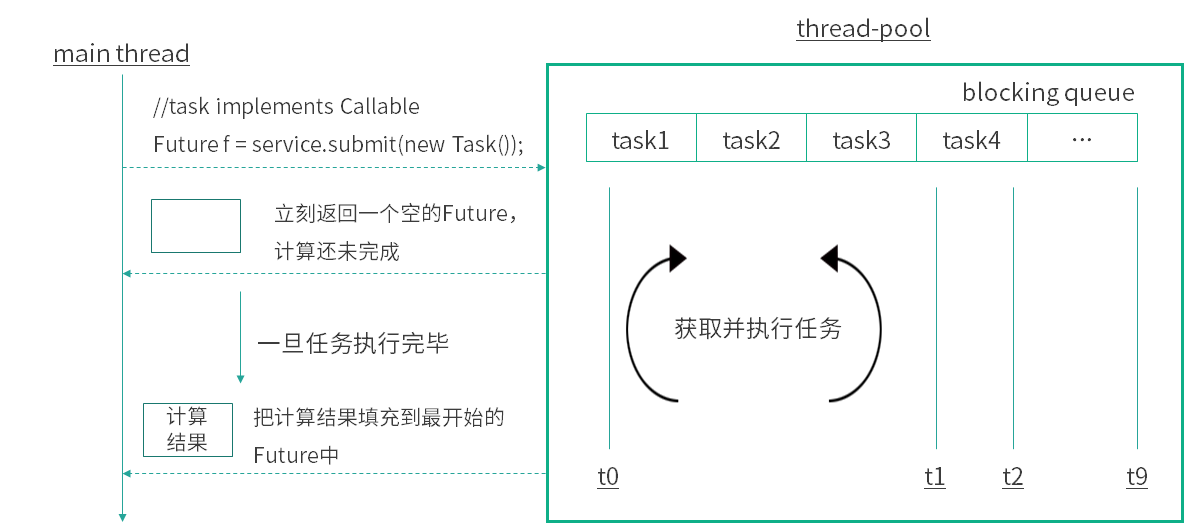
2.2.1 利用 FutureTask 创建 Future
Future实际采用FutureTask实现,该对象相当于是消费者和生产者的桥梁,消费者通过 FutureTask 存储任务的处理结果,更新任务的状态:未开始、正在处理、已完成等。而生产者拿到的 FutureTask 被转型为 Future 接口,可以阻塞式获取任务的处理结果,非阻塞式获取任务处理状态。
FutureTask既可以被当做Runnable来执行,也可以被当做Future来获取Callable的返回结果。
2.2.2 使用FutureTask
把 Callable 实例当作 FutureTask 构造函数的参数,生成 FutureTask 的对象,然后把这个对象当作一个 Runnable 对象,放到线程池中或另起线程去执行,最后还可以通过 FutureTask 获取任务执行的结果。
public class FutureTaskDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Task task = new Task();
//构建futureTask
FutureTask<Integer> futureTask = new FutureTask<>(task);
//作为Runnable入参
new Thread(futureTask).start();
System.out.println("task运行结果:"+futureTask.get());
}
static class Task implements Callable<Integer> {
@Override
public Integer call() throws Exception {
System.out.println("子线程正在计算");
int sum = 0;
for (int i = 0; i < 100; i++) {
sum += i;
}
return sum;
}
}
使用案例:促销活动中商品信息查询
在维护促销活动时需要查询商品信息(包括商品基本信息、商品价格、商品库存、商品图片、商品销售状态等)。这些信息分布在不同的业务中心,由不同的系统提供服务。如果采用同步方式,假设一个接口需要50ms,那么一个商品查询下来就需要200ms-300ms,这对于我们来说是不满意的。如果使用Future改造则需要的就是最长耗时服务的接口,也就是50ms左右。
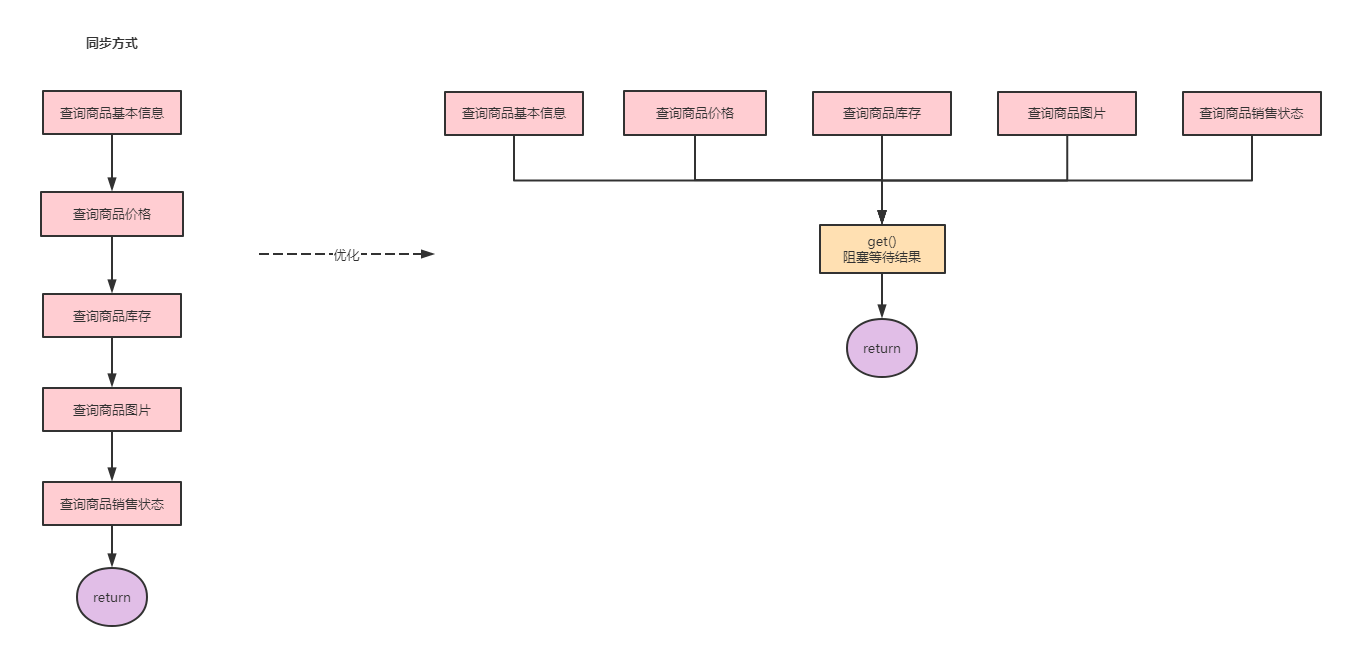
public class FutureTaskDemo2 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<String> ft1 = new FutureTask<>(new T1Task());
FutureTask<String> ft2 = new FutureTask<>(new T2Task());
FutureTask<String> ft3 = new FutureTask<>(new T3Task());
FutureTask<String> ft4 = new FutureTask<>(new T4Task());
FutureTask<String> ft5 = new FutureTask<>(new T5Task());
//构建线程池
ExecutorService executorService = Executors.newFixedThreadPool(5);
executorService.submit(ft1);
executorService.submit(ft2);
executorService.submit(ft3);
executorService.submit(ft4);
executorService.submit(ft5);
//获取执行结果
System.out.println(ft1.get());
System.out.println(ft2.get());
System.out.println(ft3.get());
System.out.println(ft4.get());
System.out.println(ft5.get());
executorService.shutdown();
}
static class T1Task implements Callable<String> {
@Override
public String call() throws Exception {
System.out.println("T1:查询商品基本信息...");
TimeUnit.MILLISECONDS.sleep(50);
return "商品基本信息查询成功";
}
}
static class T2Task implements Callable<String> {
@Override
public String call() throws Exception {
System.out.println("T2:查询商品价格...");
TimeUnit.MILLISECONDS.sleep(50);
return "商品价格查询成功";
}
}
static class T3Task implements Callable<String> {
@Override
public String call() throws Exception {
System.out.println("T3:查询商品库存...");
TimeUnit.MILLISECONDS.sleep(50);
return "商品库存查询成功";
}
}
static class T4Task implements Callable<String> {
@Override
public String call() throws Exception {
System.out.println("T4:查询商品图片...");
TimeUnit.MILLISECONDS.sleep(50);
return "商品图片查询成功";
}
}
static class T5Task implements Callable<String> {
@Override
public String call() throws Exception {
System.out.println("T5:查询商品销售状态...");
TimeUnit.MILLISECONDS.sleep(50);
return "商品销售状态查询成功";
}
}
}
2.2.3 Future的问题
Future 注意事项
- 当 for 循环批量获取 Future 的结果时容易 block,get 方法调用时应使用 timeout 限制
- Future 的生命周期不能后退。一旦完成了任务,它就永久停在了“已完成”的状态,不能从头再来
思考: 使用Callable 和Future 产生新的线程了吗?没有还是底层的Thread
Future的局限性
从本质上说,Future表示一个异步计算的结果。它提供了isDone()来检测计算是否已经完成,并且在计算结束后,可以通过get()方法来获取计算结果。在异步计算中,Future确实是个非常优秀的接口。但是,它的本身也确实存在着许多限制:
- 并发执行多任务:Future只提供了get()方法来获取结果,并且是阻塞的。所以,除了等待你别无他法;
- 无法对多个任务进行链式调用:如果你希望在计算任务完成后执行特定动作,比如发邮件,但Future却没有提供这样的能力;
- 无法组合多个任务:如果你运行了10个任务,并期望在它们全部执行结束后执行特定动作,那么在Future中这是无能为力的;
- 没有异常处理:Future接口中没有关于异常处理的方法;
2.3 CompletionService
Callable+Future 可以实现多个task并行执行,但是如果遇到前面的task执行较慢时需要阻塞等待前面的task执行完后面task才能取得结果。而CompletionService的主要功能就是一边生成任务,一边获取任务的返回值。让两件事分开执行,任务之间不会互相阻塞,可以实现先执行完的先取结果,不再依赖任务顺序了。

2.3.1 CompletionService原理
内部通过阻塞队列+FutureTask,实现了任务先完成可优先获取到,即结果按照完成先后顺序排序,内部有一个先进先出的阻塞队列,用于保存已经执行完成的Future,通过调用它的take方法或poll方法可以获取到一个已经执行完成的Future,进而通过调用Future接口实现类的get方法获取最终的结果
使用案例
询价应用:向不同电商平台询价,并保存价格
- 采用“ThreadPoolExecutor+Future”的方案:异步执行询价然后再保存
// 创建线程池
ExecutorService executor = Executors.newFixedThreadPool(3);
// 异步向电商S1询价
Future<Integer> f1 = executor.submit(()->getPriceByS1());
// 异步向电商S2询价
Future<Integer> f2= executor.submit(()->getPriceByS2());
// 获取电商S1报价并异步保存
executor.execute(()->save(f1.get()));
// 获取电商S2报价并异步保存
executor.execute(()->save(f2.get())
如果获取电商S1报价的耗时很长,那么即便获取电商S2报价的耗时很短,也无法让保存S2报价的操作先执行,因为这个主线程都阻塞 在了f1.get()操作上。
- 使用CompletionService实现先获取的报价先保存到数据库
//创建线程池
ExecutorService executor = Executors.newFixedThreadPool(10);
//创建CompletionService
CompletionService<Integer> cs = new ExecutorCompletionService<>(executor);
//异步向电商S1询价
cs.submit(() -> getPriceByS1());
//异步向电商S2询价
cs.submit(() -> getPriceByS2());
//异步向电商S3询价
cs.submit(() -> getPriceByS3());
//将询价结果异步保存到数据库
for (int i = 0; i < 3; i++) {
Integer r = cs.take().get();
executor.execute(() -> save(r));
实现类似 Dubbo 的 Forking Cluster场景
Dubbo 中有一种叫做 Forking 的集群模式,这种集群模式下,支持并行地调用多个服务实例,只要有一个成功就返回结果。
geocoder(addr) {
//并行执行以下3个查询服务,
r1=geocoderByS1(addr);
r2=geocoderByS2(addr);
r3=geocoderByS3(addr);
//只要r1,r2,r3有一个返回
//则返回
return r1|r2|r3;
// 创建线程池
ExecutorService executor = Executors.newFixedThreadPool(3);
// 创建CompletionService
CompletionService<Integer> cs = new ExecutorCompletionService<>(executor);
// 用于保存Future对象
List<Future<Integer>> futures = new ArrayList<>(3);
//提交异步任务,并保存future到futures
futures.add(cs.submit(()->geocoderByS1()));
futures.add(cs.submit(()->geocoderByS2()));
futures.add(cs.submit(()->geocoderByS3()));
// 获取最快返回的任务执行结果
Integer r = 0;
try {
// 只要有一个成功返回,则break
for (int i = 0; i < 3; ++i) {
r = cs.take().get();
//简单地通过判空来检查是否成功返回
if (r != null) {
break;
}
}
} finally {
//取消所有任务
for(Future<Integer> f : futures)
f.cancel(true);
}
// 返回结果
2.3.1 应用场景总结
- 当需要批量提交异步任务的时候建议你使用CompletionService。CompletionService将线程池Executor和阻塞队列BlockingQueue的功能融合在了一起,能够让批量异步任务的管理更简单。
- CompletionService能够让异步任务的执行结果有序化。先执行完的先进入阻塞队列,利用这个特性,你可以轻松实现后续处理的有序性,避免无谓的等待,同时还可以快速实现诸如Forking Cluster这样的需求。
- 线程池隔离。CompletionService支持自己创建线程池,这种隔离性能避免几个特别耗时的任务拖垮整个应用的风险。
2.4 CompletableFuture
简单的任务,用Future获取结果还好,但我们并行提交的多个异步任务,往往并不是独立的,很多时候业务逻辑处理存在串行[依赖]、并行、聚合的关系。如果要我们手动用 Fueture 实现,是非常麻烦的。
CompletableFuture是Future接口的扩展和增强。CompletableFuture实现了Future接口,并在此基础上进行了丰富地扩展,完美地弥补了Future上述的种种问题。更为重要的是,CompletableFuture实现了对任务的编排能力。借助这项能力,我们可以轻松地组织不同任务的运行顺序、规则以及方式。从某种程度上说,这项能力是它的核心能力。而在以往,虽然通过CountDownLatch等工具类也可以实现任务的编排,但需要复杂的逻辑处理,不仅耗费精力且难以维护。
jdk8 API文档:https://docs.oracle.com/javase/8/docs/api/
CompletionStage接口: 执行某一个阶段,可向下执行后续阶段。异步执行,默认线程池是ForkJoinPool.commonPool()
2.4.1 应用场景
描述依赖关系:
- thenApply() 把前面异步任务的结果,交给后面的Function
- thenCompose()用来连接两个有依赖关系的任务,结果由第二个任务返回
描述and聚合关系:
- thenCombine:任务合并,有返回值
- thenAccepetBoth:两个任务执行完成后,将结果交给thenAccepetBoth消耗,无返回值。
- runAfterBoth:两个任务都执行完成后,执行下一步操作(Runnable)。
描述or聚合关系:
- applyToEither:两个任务谁执行的快,就使用那一个结果,有返回值。
- acceptEither: 两个任务谁执行的快,就消耗那一个结果,无返回值。
- runAfterEither: 任意一个任务执行完成,进行下一步操作(Runnable)。
并行执行:
CompletableFuture类自己也提供了anyOf()和allOf()用于支持多个CompletableFuture并行执行
2.4.2 创建异步操作
CompletableFuture 提供了四个静态方法来创建一个异步操作:
// 没有返回值,非阻塞
public static CompletableFuture<Void> runAsync(Runnable runnable)
public static CompletableFuture<Void> runAsync(Runnable runnable, Executor executor)
// 有返回值,阻塞
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier)
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor)
这四个方法区别在于:
- runAsync 方法以Runnable函数式接口类型为参数,没有返回结果,supplyAsync 方法Supplier函数式接口类型为参数,返回结果类型为U;Supplier 接口的 get() 方法是有返回值的(会阻塞)
- 没有指定Executor的方法会使用ForkJoinPool.commonPool() 作为它的线程池执行异步代码。如果指定线程池,则使用指定的线程池运行。
- 默认情况下 CompletableFuture 会使用公共的 ForkJoinPool 线程池,这个线程池默认创建的线程数是 CPU 的核数(也可以通过 JVM option:-Djava.util.concurrent.ForkJoinPool.common.parallelism 来设置 ForkJoinPool 线程池的线程数)。如果所有 CompletableFuture 共享一个线程池,那么一旦有任务执行一些很慢的 I/O 操作,就会导致线程池中所有线程都阻塞在 I/O 操作上,从而造成线程饥饿,进而影响整个系统的性能。所以,强烈建议你要根据不同的业务类型创建不同的线程池,以避免互相干扰
runAsync&supplyAsync
Runnable runnable = () -> System.out.println("执行无返回结果的异步任务");
CompletableFuture.runAsync(runnable);
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
System.out.println("执行有返回值的异步任务");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "Hello World";
});
String result = future.get();
执行无返回结果的异步任务
执行有返回值的异步任务
2.4.3 获取结果
join&get
join()和get()方法都是用来获取CompletableFuture异步之后的返回值。join()方法抛出的是uncheck异常(即未经检查的异常),不会强制开发者抛出。get()方法抛出的是经过检查的异常,ExecutionException, InterruptedException 需要用户手动处理(抛出或者 try catch)
2.4.4 结果处理
当CompletableFuture的计算结果完成,或者抛出异常的时候,我们可以执行特定的 Action。主要是下面的方法:
public CompletableFuture<T> whenComplete(BiConsumer<? super T,? super Throwable> action)
public CompletableFuture<T> whenCompleteAsync(BiConsumer<? super T,? super Throwable> action)
public CompletableFuture<T> whenCompleteAsync(BiConsumer<? super T,? super Throwable> action, Executor executor)
- Action的类型是BiConsumer,它可以处理正常的计算结果,或者异常情况。
- 方法不以Async结尾,意味着Action使用相同的线程执行,而Async可能会使用其它的线程去执行(如果使用相同的线程池,也可能会被同一个线程选中执行)。
- 这几个方法都会返回CompletableFuture,当Action执行完毕后它的结果返回原始的CompletableFuture的计算结果或者返回异常
whenComplete&exceptionally
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
}
if (new Random().nextInt(10) % 2 == 0) {
int i = 12 / 0;
}
System.out.println("执行结束!");
return "test";
});
future.whenComplete(new BiConsumer<String, Throwable>() {
@Override
public void accept(String t, Throwable action) {
System.out.println(t+" 执行完成!");
}
});
future.exceptionally(new Function<Throwable, String>() {
@Override
public String apply(Throwable t) {
System.out.println("执行失败:" + t.getMessage());
return "异常xxxx";
}
执行结束!
test 执行完成!
或者
执行失败:java.lang.ArithmeticException: / by zero
null 执行完成!
2.4.5 结果转换
所谓结果转换,就是将上一段任务的执行结果作为下一阶段任务的入参参与重新计算,产生新的结果。
thenApply
thenApply 接收一个函数作为参数,使用该函数处理上一个CompletableFuture 调用的结果,并返回一个具有处理结果的Future对象。
public <U> CompletableFuture<U> thenApply(Function<? super T,? extends U> fn)
public <U> CompletableFuture<U> thenApplyAsync(Function<? super T,? extends U> fn)
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {
int result = 100;
System.out.println("一阶段:" + result);
return result;
}).thenApply(number -> {
int result = number * 3;
System.out.println("二阶段:" + result);
return result;
});
一阶段:100
二阶段:300
最终结果:300
thenCompose
thenCompose 的参数为一个返回 CompletableFuture 实例的函数,该函数的参数是先前计算步骤的结果。
public <U> CompletableFuture<U> thenCompose(Function<? super T, ? extends CompletionStage<U>> fn);
public <U> CompletableFuture<U> thenComposeAsync(Function<? super T, ? extends CompletionStage<U>> fn) ;
CompletableFuture<Integer> future = CompletableFuture
.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(30);
System.out.println("第一阶段:" + number);
return number;
}
})
.thenCompose(new Function<Integer, CompletionStage<Integer>>() {
@Override
public CompletionStage<Integer> apply(Integer param) {
return CompletableFuture.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = param * 2;
System.out.println("第二阶段:" + number);
return number;
}
});
}
});
第一阶段:10
第二阶段:20
最终结果: 20
thenApply 和 thenCompose的区别
- thenApply 转换的是泛型中的类型,返回的是同一个CompletableFuture;
- thenCompose 将内部的 CompletableFuture 调用展开来并使用上一个CompletableFutre 调用的结果在下一步的 CompletableFuture 调用中进行运算,是生成一个新的CompletableFuture。
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> "Hello");
CompletableFuture<String> result1 = future.thenApply(param -> param + " World");
CompletableFuture<String> result2 = future
.thenCompose(param -> CompletableFuture.supplyAsync(() -> param + " World"));
System.out.println(result1.get());
Hello World
Hello World
2.4.6 结果消费
与结果处理和结果转换系列函数返回一个新的 CompletableFuture 不同,结果消费系列函数只对结果执行Action,而不返回新的计算值。
根据对结果的处理方式,结果消费函数又分为:
- thenAccept系列:对单个结果进行消费
- thenAcceptBoth系列:对两个结果进行消费
- thenRun系列:不关心结果,只对结果执行Action
thenAccept
通过观察该系列函数的参数类型可知,它们是函数式接口Consumer,这个接口只有输入,没有返回值。
public CompletionStage<Void> thenAccept(Consumer<? super T> action);
public CompletionStage<Void> thenAcceptAsync(Consumer<? super T> action);
CompletableFuture<Void> future = CompletableFuture
.supplyAsync(() -> {
int number = new Random().nextInt(10);
System.out.println("第一阶段:" + number);
return number;
}).thenAccept(number ->
System.out.println("第二阶段:" + number * 5));
第一阶段:8
第二阶段:40
最终结果:null
thenAcceptBoth
thenAcceptBoth 函数的作用是,当两个 CompletionStage 都正常完成计算的时候,就会执行提供的action消费两个异步的结果。
public <U> CompletionStage<Void> thenAcceptBoth(CompletionStage<? extends U> other,BiConsumer<? super T, ? super U> action);
public <U> CompletionStage<Void> thenAcceptBothAsync(CompletionStage<? extends U> other,BiConsumer<? super T, ? super U> action);
CompletableFuture<Integer> futrue1 = CompletableFuture.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(3) + 1;
try {
TimeUnit.SECONDS.sleep(number);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第一阶段:" + number);
return number;
}
});
CompletableFuture<Integer> future2 = CompletableFuture.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(3) + 1;
try {
TimeUnit.SECONDS.sleep(number);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第二阶段:" + number);
return number;
}
});
futrue1.thenAcceptBoth(future2, new BiConsumer<Integer, Integer>() {
@Override
public void accept(Integer x, Integer y) {
System.out.println("最终结果:" + (x + y));
}
第二阶段:1
第一阶段:2
最终结果:3
thenRun
thenRun 也是对线程任务结果的一种消费函数,与thenAccept不同的是,thenRun 会在上一阶段 CompletableFuture 计算完成的时候执行一个Runnable,Runnable并不使用该 CompletableFuture 计算的结果。
public CompletionStage<Void> thenRun(Runnable action);
public CompletionStage<Void> thenRunAsync(Runnable action);
CompletableFuture<Void> future = CompletableFuture.supplyAsync(() -> {
int number = new Random().nextInt(10);
System.out.println("第一阶段:" + number);
return number;
}).thenRun(() ->
System.out.println("thenRun 执行"));
第一阶段:2
thenRun 执行
最终结果:null
2.4.7 结果组合
thenCombine
thenCombine 方法,合并两个线程任务的结果,并进一步处理。
public <U,V> CompletionStage<V> thenCombine(CompletionStage<? extends U> other,BiFunction<? super T,? super U,? extends V> fn);
public <U,V> CompletionStage<V> thenCombineAsync(CompletionStage<? extends U> other,BiFunction<? super T,? super U,? extends V> fn);
CompletableFuture<Integer> future1 = CompletableFuture
.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(10);
System.out.println("第一阶段:" + number);
return number;
}
});
CompletableFuture<Integer> future2 = CompletableFuture
.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(10);
System.out.println("第二阶段:" + number);
return number;
}
});
CompletableFuture<Integer> result = future1
.thenCombine(future2, new BiFunction<Integer, Integer, Integer>() {
@Override
public Integer apply(Integer x, Integer y) {
return x + y;
}
});
第一阶段:9
第二阶段:5
最终结果:14
2.7.8 任务交互
所谓线程交互,是指将两个线程任务获取结果的速度相比较,按一定的规则进行下一步处理。
applyToEither
两个线程任务相比较,先获得执行结果的,就对该结果进行下一步的转化操作。
public <U> CompletionStage<U> applyToEither(CompletionStage<? extends T> other,Function<? super T, U> fn);
public <U> CompletionStage<U> applyToEitherAsync(CompletionStage<? extends T> other,Function<? super T, U> fn);
CompletableFuture<Integer> future1 = CompletableFuture
.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(10);
System.out.println("第一阶段start:" + number);
try {
TimeUnit.SECONDS.sleep(number);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第一阶段end:" + number);
return number;
}
});
CompletableFuture<Integer> future2 = CompletableFuture
.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(10);
System.out.println("第二阶段start:" + number);
try {
TimeUnit.SECONDS.sleep(number);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第二阶段end:" + number);
return number;
}
});
future1.applyToEither(future2, new Function<Integer, Integer>() {
@Override
public Integer apply(Integer number) {
System.out.println("最快结果:" + number);
return number * 2;
}
第一阶段start:6
第二阶段start:5
第二阶段end:5
最快结果:5
acceptEither
两个线程任务相比较,先获得执行结果的,就对该结果进行下一步的消费操作。
public CompletionStage<Void> acceptEither(CompletionStage<? extends T> other,Consumer<? super T> action);
public CompletionStage<Void> acceptEitherAsync(CompletionStage<? extends T> other,Consumer<? super T> action);
CompletableFuture<Integer> future1 = CompletableFuture
.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(10) + 1;
try {
TimeUnit.SECONDS.sleep(number);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第一阶段:" + number);
return number;
}
});
CompletableFuture<Integer> future2 = CompletableFuture
.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(10) + 1;
try {
TimeUnit.SECONDS.sleep(number);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第二阶段:" + number);
return number;
}
});
future1.acceptEither(future2, new Consumer<Integer>() {
@Override
public void accept(Integer number) {
System.out.println("最快结果:" + number);
}
第二阶段:3
最快结果:3
runAfterEither
两个线程任务相比较,有任何一个执行完成,就进行下一步操作,不关心运行结果。
public CompletionStage<Void> runAfterEither(CompletionStage<?> other,Runnable action);
public CompletionStage<Void> runAfterEitherAsync(CompletionStage<?> other,Runnable action);
CompletableFuture<Integer> future1 = CompletableFuture
.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(5);
try {
TimeUnit.SECONDS.sleep(number);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第一阶段:" + number);
return number;
}
});
CompletableFuture<Integer> future2 = CompletableFuture
.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(5);
try {
TimeUnit.SECONDS.sleep(number);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第二阶段:" + number);
return number;
}
});
future1.runAfterEither(future2, new Runnable() {
@Override
public void run() {
System.out.println("已经有一个任务完成了");
}
}).join();
第一阶段:3
已经有一个任务完成了
runAfterBoth
两个线程任务相比较,两个全部执行完成,才进行下一步操作,不关心运行结果。
public CompletionStage<Void> runAfterBoth(CompletionStage<?> other,Runnable action);
public CompletionStage<Void> runAfterBothAsync(CompletionStage<?> other,Runnable action);
CompletableFuture<Integer> future1 = CompletableFuture
.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第一阶段:1");
return 1;
}
});
CompletableFuture<Integer> future2 = CompletableFuture
.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第二阶段:2");
return 2;
}
});
future1.runAfterBoth(future2, new Runnable() {
@Override
public void run() {
System.out.println("上面两个任务都执行完成了。");
}
第一阶段:1
第二阶段:2
上面两个任务都执行完成了。
anyOf
anyOf 方法的参数是多个给定的 CompletableFuture,当其中的任何一个完成时,方法返回这个 CompletableFuture。
public static CompletableFuture<Object> anyOf(CompletableFuture<?>... cfs)
Random random = new Random();
CompletableFuture<String> future1 = CompletableFuture
.supplyAsync(() -> {
try {
TimeUnit.SECONDS.sleep(random.nextInt(5));
} catch (InterruptedException e) {
e.printStackTrace();
}
return "hello";
});
CompletableFuture<String> future2 = CompletableFuture
.supplyAsync(() -> {
try {
TimeUnit.SECONDS.sleep(random.nextInt(1));
} catch (InterruptedException e) {
e.printStackTrace();
}
return "world";
});
CompletableFuture<Object> result = CompletableFuture.anyOf(future1, future2);
world
allOf
allOf方法用来实现多 CompletableFuture 的同时返回。
public static CompletableFuture<Void> allOf(CompletableFuture<?>... cfs)
CompletableFuture<String> future1 = CompletableFuture
.supplyAsync(() -> {
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("future1完成!");
return "future1完成!";
});
CompletableFuture<String> future2 = CompletableFuture
.supplyAsync(() -> {
System.out.println("future2完成!");
return "future2完成!";
});
CompletableFuture<Void> combindFuture = CompletableFuture
.allOf(future1, future2);
try {
combindFuture.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
future2完成!
future1完成!
future1: true,future2: true
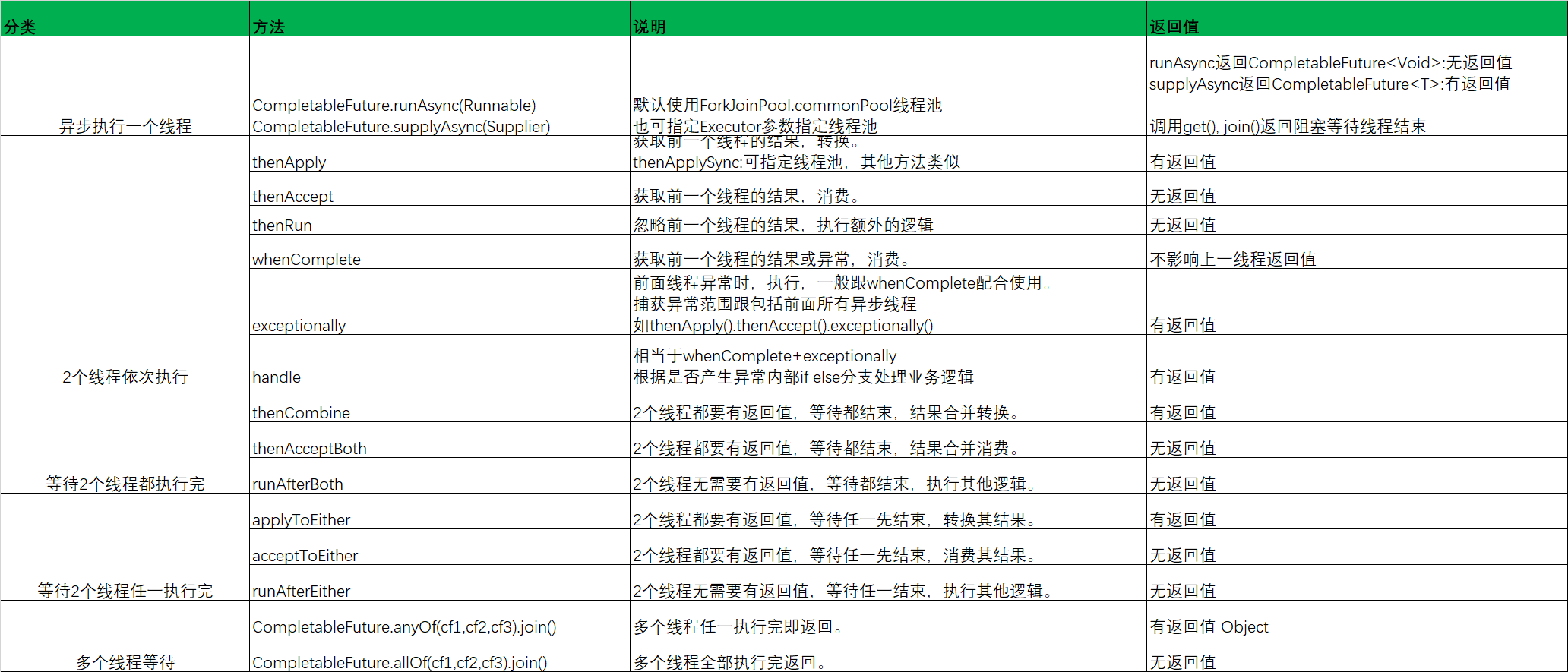
2.7.9 CompletableFuture常用方法总结
2.7.10 使用案例:最优的“烧水泡茶”
著名数学家华罗庚先生在《统筹方法》这篇文章里介绍了一个烧水泡茶的例子,文中提到最优的工序应该是下面这样:
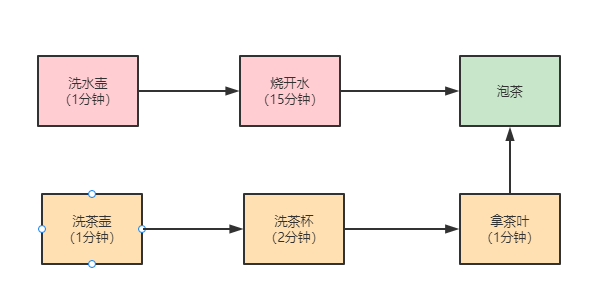
对于烧水泡茶这个程序,一种最优的分工方案:用两个线程 T1 和 T2 来完成烧水泡茶程序,T1 负责洗水壶、烧开水、泡茶这三道工序,T2 负责洗茶壶、洗茶杯、拿茶叶三道工序,其中 T1 在执行泡茶这道工序时需要等待 T2 完成拿茶叶的工序。
基于Future实现
public class FutureTaskDemo3{
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 创建任务T2的FutureTask
FutureTask<String> ft2 = new FutureTask<>(new T2Task());
// 创建任务T1的FutureTask
FutureTask<String> ft1 = new FutureTask<>(new T1Task(ft2));
// 线程T1执行任务ft1
Thread T1 = new Thread(ft1);
T1.start();
// 线程T2执行任务ft2
Thread T2 = new Thread(ft2);
T2.start();
// 等待线程T1执行结果
System.out.println(ft1.get());
}
}
// T1Task需要执行的任务:
// 洗水壶、烧开水、泡茶
class T1Task implements Callable<String> {
FutureTask<String> ft2;
// T1任务需要T2任务的FutureTask
T1Task(FutureTask<String> ft2){
this.ft2 = ft2;
}
@Override
public String call() throws Exception {
System.out.println("T1:洗水壶...");
TimeUnit.SECONDS.sleep(1);
System.out.println("T1:烧开水...");
TimeUnit.SECONDS.sleep(15);
// 获取T2线程的茶叶
String tf = ft2.get();
System.out.println("T1:拿到茶叶:"+tf);
System.out.println("T1:泡茶...");
return "上茶:" + tf;
}
}
// T2Task需要执行的任务:
// 洗茶壶、洗茶杯、拿茶叶
class T2Task implements Callable<String> {
@Override
public String call() throws Exception {
System.out.println("T2:洗茶壶...");
TimeUnit.SECONDS.sleep(1);
System.out.println("T2:洗茶杯...");
TimeUnit.SECONDS.sleep(2);
System.out.println("T2:拿茶叶...");
TimeUnit.SECONDS.sleep(1);
return "龙井";
}
基于CompletableFuture实现
public class CompletableFutureDemo2 {
public static void main(String[] args) {
//任务1:洗水壶->烧开水
CompletableFuture<Void> f1 = CompletableFuture
.runAsync(() -> {
System.out.println("T1:洗水壶...");
sleep(1, TimeUnit.SECONDS);
System.out.println("T1:烧开水...");
sleep(15, TimeUnit.SECONDS);
});
//任务2:洗茶壶->洗茶杯->拿茶叶
CompletableFuture<String> f2 = CompletableFuture
.supplyAsync(() -> {
System.out.println("T2:洗茶壶...");
sleep(1, TimeUnit.SECONDS);
System.out.println("T2:洗茶杯...");
sleep(2, TimeUnit.SECONDS);
System.out.println("T2:拿茶叶...");
sleep(1, TimeUnit.SECONDS);
return "龙井";
});
//任务3:任务1和任务2完成后执行:泡茶
CompletableFuture<String> f3 = f1.thenCombine(f2, (__, tf) -> {
System.out.println("T1:拿到茶叶:" + tf);
System.out.println("T1:泡茶...");
return "上茶:" + tf;
});
//等待任务3执行结果
System.out.println(f3.join());
}
static void sleep(int t, TimeUnit u){
try {
u.sleep(t);
} catch (InterruptedException e) {
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号