

python基础篇(一)
PYTHON基础篇(一)
- 变量
- 赋值
- 输入,输出和导入
- A:输入
- B:输出
- C:导入
- 运算符
- A:算数运算符
- B:比较运算符
- C:赋值运算符
- D:位运算符
- E:逻辑运算符
- F:成员运算符
- G:身份运算符
- 数据类型
- A:数字
- B:字符串
- C:布尔
- D:列表
- E:元祖
- F:字典
- 文件基础操作
♣一;变量
在任何语言中都有变量和赋值这种最基础的操作,也是入门接触改语言的第一件事情。
变量,很多人从字面上理解成变化的量,这个定义不会有太大问题,总的来说变量就是不固定的,可变化的数值或者字符等。
变量我们只需要记住主要作用就四个字【赋值传参】
为什么要赋值传参,可以想象下,在军队或者校园里面排队组成了很大面积的方阵,要怎么去定位一个你需要去找到的人了,就需要通过扩音器等设备来叫你需要找的那个人的名字,那么这个时候名字就代表了变量名,对应的人就是变量,当然对应的人不会变化,这个也就引出了我们机器内部处理的简单方式,当你代码有上百上千行,都需要在特定的位置来引用到这个变量,来加以判断,这个时候变量就显得很重要的。
变量命名规则3大条:
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
只需要记住两种变量命令方式,如果一开始就使用一种命令方式后面代码就一直使用:
- 一 ;hello_python 带下划线方式
- 二;HelloPython 驼峰状
♣二;赋值
x = 1 #x是变量名,1是变量,‘=’号就是赋值式【注:#号开头后面的内容都是注释行】
#号开头是单行注释,多行请使用'''被注释内容'''。
x上面也解释到是变量名,但是实际在我们计算机里面就是一个存储单元地址,1就是该存储单元地址里面的内容。
任何程序和数据都是存储在存储器上面的,而且,无论是对数据而言,还是程序指令而言,都是要通过控制器去存储器上面去读取对应的存储单元的地址,拿到对应的内容,然后通过运算器进行运算,然后得到结果。上面的方式也只是临时的存储,存储在我们机器的内存当中,当我们去调用的时候就可以通过找到存储单元地址来找到存储的内容。
变量赋值规则:
x = 1 #【注:数字是不需要加引号】
x1 = "name" #【注:字符一定要加引号】
x2="name1" #【等号左右两边有没有有空格,效果是一样的】
x3 = name
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
x3=name
NameError: name 'name' is not defined
#【如果字符不加引号会报“name 'name' is not defined”name字段没有定义的错误】
说到了内存地址,还有一个也是和变量赋值息息相关的点,查询是通过给出的变量名来查找内存地址所在变量内容,那么就会产生一个误区,就是变量名和变量是一一对应的,有了变量名就能找到你相应的变量,其实不然,变量是活动的。
>>> a1 = 1 #【变量赋值为1】
>>> a2 = a1 #【变量a2等于变量名a1】
>>> a2 #【可以看到结果也是符合我们预期的值】
1
>>> a1
1
>>> a1 = 2 #【再将变量a1重新赋值,a2并没有做任何变化,那么得到的结果应该是a2是a1所在的值】
>>> a2 #【但是结果a2还是等于第一次a1的值,并没有跟随a1变化而变化】
1
>>> a1 #【a1的值是正确的,并不是没有赋值成功等误解】
2
那这个是什么原因了,其实原因很简单,回归到上面的内存地址话题,其实变量名是申明我在内存中这个地址放了一个值,后面我会通过输入内存地址对应的标识{也就是变量名}来显示内容。
查看内存地址:
>>> id (a1) #【可以通过id命令和你要查询的标识{变量名}来查看内存地址】
1350411392
>>> id(a2) #【可以看到内存地址两次是不一样的,这个查询方法可以在后面你代码量大了,出现传参错误,就可以通过此方法首先来判断内存地址是否正确,再做判断】
1350411360
>>>
其实在上述可以得出一个逻辑图:
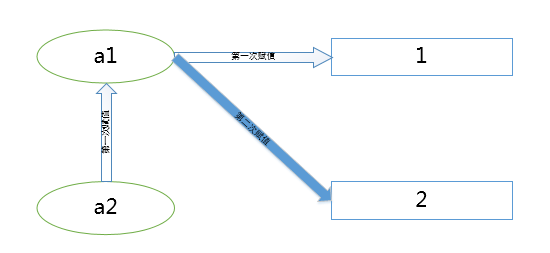
上面逻辑图是错误的理解方式,正确的如下:

上面我们也看到了要想取变量值的方法就是输入变量值对应的变量名就能得到,其实真正写代码的时候是不会使用直接输入变量名的方式来获取变量值的,是需要通过print来打印出相应的结果内容。
这部分的print我们叫做输出,在讲输出之前还是先讲输入。
♣三;输入,输出和导入
A:输入
python提供了input()可以接受用户输入的字符串并存放到变量里,例如你想存你的名字。
>>> subjects1=input() #让用户输入选择的科目1 java >>> subjects2 = input() #让用户输入选择的科目2 python >>> print(subjects1, subjects2) #可以连起来打印 java python >>> print(subjects1,subjects2) #可以省略空格,但是必须是要,号的,不然就不能区分变量名而报错
java python
>>> subjects1 #可以直接通过输入变量名来查看内容
'java'
当你输入subjects1=input()并按下回车的时候,python的交互命令行就在等待你的输入了,这个时候不管你输入什么字符,直到回车完成输入过程,这个输入过程完毕之后,python并不会有任何提示,命令交互模式又回到了>>>模式,等待你继续操作,那么上面的你在交互模式下输入的内容就保存到了subjects1变量里面去了,可以通过print(subjects1)变量名来查看,或者直接subjects1变量名来查看。
在没有任何提示下,直接subjects1=input(),用户会不理解你的用意,这个时候就需要通过一定的提示用语来告知客户,“请输入您选择的科目名:”等等之类的提示语,这样显得更加人性化。input提供了通过添加提示语来告知用户需要填写的内容。
>>> subjects3=input('嗨!朋友,请输入您选择的科目名:') #通过在‘’号之内写入用户提示语,可以让用户知道你的用意
嗨!朋友,请输入您选择的科目名:php #在增加提示语句之后,显得更加人性化
>>> subjects3
'php'
在外面存入的变量很多了,但是你不清楚你之前某一个变量存的变量值是多少了,就可以使用一些内置办法evel('变量名')来找到变量值,其实evel的方法也很简单,就是取到变量名去内存里找有没有变量名是你要查询的,如果有就把其变量值取出来。
B:输出
输入可以增加提示语,那么输出也是可以增加提示语句的。
>>> print('欢迎您选择',subjects3,'科目') #只要保证提示语在‘’号之内,在后面通过输出变量名来衔接提示内容,就可以和input一样人性化
欢迎您选择 php 科目
>>> print('现在您选择的',subjects3,'科目有200人') #假设用户通过网址登陆网页查看到第一个内容就是让用户选择科目,可以将此类的提示语句存储起来,每次当用户选择就可以提示用户当前情况
现在您选择的 php 科目有200人
>>>
C:导入
在很多情况下提示语句都是很有必要的,但是有一种情况,是万万不能让用户的信息随着提示语和输入的时候一起出现的,那就是密码。可以通过python的模块来实现,import导入模块。
>>> import getpass #通过import就可以导入你想要的模块,调用该模块里面的功能
>>> password = getpass.getpass("请输入密码:") #通过getpass.getpass功能就可以屏蔽键盘字符的输出
请输入密码:
>>> print(password) #【此方法只能在python shell和windows的cmd窗口下密码才不会显示,如果是在python自带的IDIE环境下是会显示密码输入的,而且还会抛出警告语句‘Warning: Password input may be echoed.’】
123456
>>> user = getpass.getuser() #getpass.getuser的功能就是返回当前登录的用户名,该函数会去检查本机的环境变量LOCNAME,USER,LNAME和USERNAME,返回非空字符串。
>>> print(user) #当前我本机的用户名就是ypc
ypc
上述就是print,input和import的基本用法,还有很多好玩的用法等待你的探索。
例如:print(100 * 2177),直接得到结果可能比较不友好,可以改一下代码为:print('100 * 2177 =',100 * 2177),这样输出的既有题目,又有结果。
例如:import sys模块,后面会大量的来解释python的模块的功能。
♣四;运算符
计算机本质的工作就是运算(百度计算机的定义:计算机(computer)俗称电脑,是现代一种用于高速计算的电子计算机器,可以进行数值计算,又可以进行逻辑计算,还具有存储记忆功能。是能够按照程序运行,自动、高速处理海量数据的现代化智能电子设备),计算机需要通过指定运算符号才能进行基础运算。
A:算数运算符
定义变量a = 10,b = 66, c = -9


a = 10 b = 66 c = -9 print("a + b + c =",(a + b +c)) #执行结果: a + b + c = 67
a = 10 b = 66 c = -9 print("a - b - c =",(a - b - c)) print("(b - a) + c =", (b - a) + c) #执行结果: a - b - c = -47 (b - a) + c = 47
a = 10 b = 66 c = -9 print("(b - a) + c =", (b - a) + c) print("(b - c) * b =", (b - c) * b) #执行结果: (b - a) + c = 47 (b - c) * b = 4950
a = 10 b = 66 c = -9 print("(b - c) * b =", (b - c) * b) print("a ** 2 =", a ** 2) #执行结果: (b - c) * b = 4950 a ** 2 = 100
a = 10 b = 66 c = -9 d = "%.3f" % (b / c) print("b / c =", d) #执行结果: b / c = -7.333
a = 10 b = 66 c = -9 d = b // c print("b // c =", d) #执行结果: b // c = -8 #整除(地板除)就是永远只保留整数部分
a = 10 b = 66 c = -9 d = b % c print("b % c =", d) #执行结果: b % c = -6 #返回商的整数部分
B:比较运算符
定义变量a = 10,b = 66, c = -9
a = 10 b = 66 c = -9 if (a == b): print("a等于b") else: print("a不等于b") #执行结果: a不等于b
a = 10 b = 66 c = -9 if (a != b): print("a不等于b") else: print("a等于b") #执行结果: #a不等于b
a = 10 b = 66 c = -9 if (a < c): print("a小于c") else: print("a不小于c") #执行结果: #a不小于c
a = 10 b = 66 c = -9 if (a > c): print("a大于c") else: print("a不大于c") #执行结果: #a大于c
a = 10 b = 66 c = -9 if (a <= c): print("a小于等于c") else: print("a大于c") #执行结果: #a大于c
a = 10 b = 66 c = -9 if (b >= a): print("b大于等于a") else: print("b小于a") #执行结果: #b大于等于a
C:赋值运算符
a = 10 b = 66 a = b print(a, b) #执行结果: 66 66
a = 10 b = 66 b += a #另外一种写法就是b = a + b等效于b += a print("a + b =", b) #执行结果: #a + b = 76
a = 10 b = 66 b -= a #另外一种写法就是b = b - a等效于b -= a print("b - a =", b) #执行结果: #b - a = 56
a = 10 b = 66 b *= a #另外一种写法就是b = b * a等效于b *= a print("b * a =", b) #执行结果: #b * a = 660
a = 10 b = 66 b /= a #另外一种写法就是b = b / a等效于b /= a print("b / a =", b) #执行结果: #b / a = 6.6
a = 10 b = 66 b %= a #另外一种写法就是b = b % a等效于b %= a print("b % a =", b) #执行结果: #b % a = 6
a = 10 b = 66 b **= a #另外一种写法就是b = b ** a等效于b **= a print("b ** a =", b) #执行结果: #b ** a = 1568336880910795776
a = 10 b = 66 b //= a #另外一种写法就是b = b // a等效于b //= a print("b // a =", b) #执行结果: #b // a = 6
D:位运算符
a = 60 b = 13 #a = 0011 1100 60的二进制表示方法 #b = 0000 1101 13的二进制表示方法 c = a & b print("a & b =", c) #执行结果: #a & b = 12 0011 1100 0000 1101 0000 1100是12的二进制表示方法
a = 60 b = 13 #a = 0011 1100 60的二进制表示方法 #b = 0000 1101 13的二进制表示方法 c = a | b print("a | b =", c) #执行结果: #a | b = 61 0011 1100 0000 1101 0011 1101是61的二进制表示方法
a = 60 b = 13 #a = 0011 1100 60的二进制表示方法 #b = 0000 1101 13的二进制表示方法 c = a ^ b print("a ^ b =", c) #执行结果: #a ^ b = 49 0011 1100 0000 1101 0011 0001是49的二进制表示方法
a = 60 b = 13 #a = 0011 1100 60的二进制表示方法 #b = 0000 1101 13的二进制表示方法 c = a ~ b print("a ~ b =", c) #执行结果: #a ~ b = -61 #0011 1100 #0000 1101 #1100 0011是-61的二进制表示方法
a = 60 b = 13 #a = 0011 1100 60的二进制表示方法 #b = 0000 1101 13的二进制表示方法 c = a << 2 print("a << 2 =", c) #执行结果: #a << b = 240 #0011 1100 #0000 1101 #1111 0000是240的二进制表示方法
a = 60 b = 13 #a = 0011 1100 60的二进制表示方法 #b = 0000 1101 13的二进制表示方法 c = a >> 2 print("a >> 2 =", c) #执行结果: #a >> b = 15 #0011 1100 #0000 1101 #0000 1111是15的二进制表示方法
E:逻辑运算符
a = 68 b = 128 if (a and b): print("变量a和b都为true") else: print("变量a和b有一个不为true") #执行结果: 变量a和b都为true
a = 68 b = 128 if (a or b): print("变量a和b都为true,或其中一个变量为true") else: print("变量a和b有一个不为true") #执行结果: 变量a和b都为true,或其中一个变量为true
a = 68 b = 128 if not(a and b): print("变量a和b都为false,或其中一个变量为false") else: print("变量a和b都为true") #执行结果: 变量a和b都为true
F:成员运算符
a = 6 b = 128 list1 = [1, 2, 4, 6, 8, 10, 1121, 60, 33] if (a in list1): print("变量a的值%d在list1中" % (a)) else: print("变量a的值%d不在list1" % (a)) if (b in list1): print("变量b的值%d在list1中" % (b)) else: print("变量b的值%d不在list1中" % (b)) #执行结果: 变量a的值6在list1中 变量b的值128不在list1中
a = 6 b = 128 list1 = [1, 2, 4, 6, 8, 10, 1121, 60, 33] if (a not in list1): print("变量a的值%d在list1中" % (a)) else: print("变量a的值%d不在list1" % (a)) if (b in list1): print("变量b的值%d在list1中" % (b)) else: print("变量b的值%d不在list1中" % (b)) #执行结果: 变量a的值6不在list1 变量b的值128不在list1中
G:身份运算符
list1 = 10 list2 = 10 if (list1 is list2): print("list1和list2有相同的标识符") else: print("list1和list2没有相同的标识符") 执行结果: list1和list2有相同的标识符
list1 = 10 list2 = 10 if (list1 is not list2): print("list1和list2有相同的标识符") else: print("list1和list2没有相同的标识符") 执行结果: list1和list2没有相同的标识符
♣五;数据类型
计算机被研究出来大范围使用的本质还是计算机能快速的进行大规模的计算,因此,计算机需要去区分出不同的数据类型,是数字,还是汉字,是图片,还是视频,这个就需要提前定义你的内容是属于什么类型,在python中能够直接处理的数据类型有以下几种:
A:数字
int(整型)
python可以处理任意大小的数字,其中就包括整数和负数,例如1,100,-888999,34567等等。
可以通过type来查看数据类型
>>> a = 1
>>> type(a)
<class 'int'> #可以看到a的值就是属于整型
long(长整型)
在python2.2的版本之后当数字长度超过int类型的限制,会自动转成long类型,在2.2版本之前当32位机器超过-2**31~2**31 -1和64位机器超过-2**63 -1~2**63 -1的长度都是属于long(长整型),长整型本身不限制数值的大小,受限于机器内存的大小,长整型也是不能无限大的。
float(浮点型)
浮点型其实就是指小数,在科学计数法中,一个小数的小数点的位置是变化的。例如1.23,3.45等,但是对于很大或者很小的浮点数就需要通过科学计数法e表示了。
>>> 1.456**1000
1.4500232872337884e+163
>>> -2.345**-101
-4.1264106704974406e-38
>>> c = 2.345
>>> type(c) #可以通过type来查看数据类型
<class 'float'> #可以看到c的类型就是浮点型
浮点型在很多场景下,是需要控制输出整数位和小数位的个数的,例如小学题:10 / 3,这个是永远除不尽的数字,我们就需要控制输出的小数位的个数,不能让其无限制的增加输出,往往越到小数位后面的数字越没有必要。
>>> round(3.33333,2) #可以通过python内置方法found来控制输出内容的精度,浮点数小数位是5位,我只想取小数点后面2位,直接在结果后面指定要输出的位数即可
3.33 #我指定输出2位,得到结果也是2位
>>> round(2.645) #还能四舍五入?
3 #继续往下看
>>> round(2.645,2) #取两位,两位的位置正好是偶数,得到的结果是四舍五入的结果
2.65
>>> round(2.655,2) #同样取两位,应该是四舍五入的结果2.66,结果还是2.65,只是把后面的第三位5去掉了
2.65
>>> round(2.675,2)
2.67
>>> round(2.665,2) #通过上面可以得到规律,round不是简单的四舍五入
2.67
round函数的四舍五入方式是:当遇到截取位数的数字正好是奇数,那么就直接截取,如果是偶数,那么才会四舍五入,那么这么也会带来一定的问题,所有需要通过其他的办法来处理,后续会讲到。
上述是我们知道结果的前提下做的位数指定输出方法,往往很多情况下,我们是不知道结果会有几位小数,这个方法就不适用,需要通过其他办法来指定。
>>> a = 10 /3
>>> a
3.3333333333333335 #在默认情况下,python会计算到17位的进度,这17位是包含了小数点前面的整数部分
>>> a = "%.30f" %(10/3) #如果是要精确到小数点后面30位,50位,需要通过“%.多少位” %(计算数据内容)这样来
>>> a
'3.333333333333333481363069950021' #但是你会发现到一定精度之后就不准了,应该是3.3333连续到30位全部输出完,这个需求用到其他办法来解决,后面会讲到
>>> a = "%.5f" %(10/3)
>>> a
'3.33333'
>>> a = "%.10f" %(10/3)
>>> a
'3.3333333333' #指定比默认17位要少的情况下是能显示是符合我们预期值
格式化的操作也会有问题,那就是得到的值超过17就不精准了,如果是需要得到精准的小数位,此方法不推荐,也需要通过其他方法来得到精准的小数值,后续也会讲到。
还有一个complex(复数)类型也不常用,这里就不做过多解释了。
B:字符串
字符串前面我们赋值很多都是字符串形式的,字符串创建很简单,只需要通过定义即可,例如:a = “hello python” ,字符串可以做截取,格式化,字符串转意等操作。
字符串的截取:
例如:a = "hello python" ,我们只需要字符串里面的py两个字符,可以通过字符串的截取来完成。
 可以看到字符和下面的数字一一对应,数字代表字符的下标,通过指定下标来截取相应的内容,【注:空格也算一位字符】
可以看到字符和下面的数字一一对应,数字代表字符的下标,通过指定下标来截取相应的内容,【注:空格也算一位字符】
>>> a = "hello python"
>>> a[6:8] #从下标第6位置开始到第8位结束,就可以截取py两个字符,
'py' #【注:截取起始点是在截取字符前面的一个下标,不是截取字符的当前下标,整个字符的最开始和结束点除外】
>>> a[0:5]
'hello'
>>> a[6:12]
'python'
>>> a[:-2] #还可以从字符串后面开始截取,不设起点,结束点在字符串最后2位结束
'hello pyth'
>>> a[-5:-2] #还可以从字符串尾部开始截取,从倒数第2位开始到倒数第5位结束
'yth'
字符串格式化:
有这种情况,要用户填写信息,姓名和年龄,用户需要通过交互界面填写之后,将用户填写的信息加上固定的内容展示到用户的交互界面,这种情况就需要字符串格式化来完成。
>>> print("尊敬的用户%s,您好!您的年龄:%d不符合注册年龄,注册失败!" % ("小明", 12)) #通过%s来讲后面的名字带入到字符串内部,并打印出来
尊敬的用户小明,您好!您的年龄:12不符合注册年龄,注册失败!
>>> name = "张三疯"
>>> print("我是%s" % name) #也可以通过事先定义变量,后面在打印的时候将变量的值带入到字符串内部
我是张三疯 #【注:此类方法也叫字符串拼接】
字符串更新:
>>> string = "hello python"
>>> print(string[:6] + "java") #通过指定字符串下标,从第6位开始改,不限制结束点将python改成java
hello java
字符串还有其他常用的功能,移除空白,分割,长度等。
C:布尔
布尔就两个参数“真”和“假”。
>>> True
True
>>> False
False
D:列表
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
列表的创建方法
>>> list1 = [1, 2, 3, 4, 5, 6] #列表是以方括号内逗号分隔值来创建的
>>> list2 = ["python", "html", "java", "php", "go"] #字符类型是需要加上引号
>>> list1
[1, 2, 3, 4, 5, 6]
>>> list2
['python', 'html', 'java', 'php', 'go']
列表基本操作:
>>> len(list1) #可以通过len()函数来获取列表元素的个数
6
>>> len(list2)
5
>>> list2[3] #通过下标来查看元素的内容
'php'
>>> print(list2[2:4]) #可以通过指定下标的起始结束点来查看多个元素
['java', 'php']
>>> print(list1[:2]) #和字符串的操作方式相同
[1, 2]
>>> list2.append("c++") #通过append就可以将需要追加的元素追加到列表末尾
>>> list2
['python', 'html', 'java', 'php', 'go', 'c++']
>>> list1.append(7, 8, 9)
Traceback (most recent call last):
File "<pyshell#23>", line 1, in <module>
list1.append(7, 8, 9)
TypeError: append() takes exactly one argument (3 given)
#因为append()总是把新的元素添加到list的尾部,只能接受一个元素,不能一次给多个元素
>>> list1.insert(1, 9)
>>> list1
[1, 9, 2, 3, 4, 5, 6, 7]
>>> list2.insert(3, "C")
>>> list2
['python', 'html', 'java', 'C', 'php', 'go', 'c++']
#通过insert来指定位置来插入元素
>>> list1.pop(1)
9
>>> list1
[1, 2, 3, 4, 5, 6, 7]
>>> list2.pop(3)
'C'
>>> list2
['python', 'html', 'java', 'php', 'go', 'c++']
通过pop()来指定下标删除元素
>>> list1
[1, 1, 3, 4, 5, 6, 7]
>>> list2[1]= "javascrip"
>>> list2
['python', 'javascrip', 'java', 'php', 'go', 'c++']
在列表后面指定下标,替换新元素到下标所在的旧元素
>>> list3 = ["a", "b", list1, "c", list2]
>>> list3
['a', 'b', [1, 1, 3, 4, 5, 6, 7], 'c', ['python', 'javascrip', 'java', 'php', 'go', 'c++']]
#通过创建列表的时候将list1和list2带入到list3里面,list3就包含了list1和2里面的元素
>>> list1
[1, 1, 3, 4, 5, 6, 7, 1, 1, 2, 2, 2]
>>> list1.count(1)
4
>>> list1.count(2)
3
#通过count()指定需要统计的元素,就可以统计出改元素在列表中有几个相同的元素
>>> list4 = ["ABC", "DEF"]
>>> list3
['a', 'b', [1, 1, 3, 4, 5, 6, 7, 1, 1, 2, 2, 2], 'c', ['python', 'javascrip', 'java', 'php', 'go', 'c++']]
>>> list4.extend(list3)
>>> list4
['ABC', 'DEF', 'a', 'b', [1, 1, 3, 4, 5, 6, 7, 1, 1, 2, 2, 2], 'c', ['python', 'javascrip', 'java', 'php', 'go', 'c++']]
#通过extend()将添加的元素全部移动到新列表中
>>> list1
[1, 1, 3, 4, 5, 6, 7, 1, 1, 2, 2, 2]
>>> list2
['python', 'javascrip', 'java', 'php', 'go', 'c++']
>>> list1.index(1)
0
>>> list1.index(2)
9
>>> list2.index("php")
3
#通过index()指定元素,就可以得到改元素的下标是在哪位,不过是按照最开始哪位元素的下标的来显示
>>> list2
['python', 'javascrip', 'java', 'php', 'go', 'c++']
>>> list2.reverse()
>>> list2
['c++', 'go', 'php', 'java', 'javascrip', 'python']
通过reverse()来翻转元素的位置
>>> list5
[1, 1, 4, 8, -10, -88]
>>> list5.sort()
>>> list5
[-88, -10, 1, 1, 4, 8]
通过sort()来对列表里面的元素进行排序,如果是有字符,是按照ASCII码来进行来排序
>>> list5
[-88, -10, 1, 1, 4, 8]
>>> list5.clear()
>>> list5
[]
#通过clear()可以将列表清空
>>> list2
['c++', 'go', 'php', 'java', 'javascrip', 'python']
>>> list5
[]
>>> list5 = list2.copy()
>>> list5
['c++', 'go', 'php', 'java', 'javascrip', 'python']
#通过copy()可以将其他元素拷贝到指定列表里面去
列表还有一个统计最大和最小的操作
>>> max(list1)
7
>>> min(list1)
1
#通过max和min来统计列表里面元素最大值和最小值
练习:让用户随便输入6个数字,将这6个数字按照从小到大依次排序到列表中
程序分析:1;先要限定用户输入的次数
2:假设用户第一次输入的数字是X,将X和后面输入的Y,Z......做比较
3:将用户输入的数字追加到列表中
4:进行数字的排序
5:输出排序之后的内容
num = []
for i in range(6): #限制次数
x = (input('请输入数字:\n')) #提示用户输入
num.append(x) #追加到列表
num.sort() #用soft()函数进行排序
print(num) #打印排序之后的列表
执行结果:
请输入数字:
12
请输入数字:
14
请输入数字:
56
请输入数字:
78
请输入数字:
22
['12', '14', '22', '56', '78']
E:元祖
元祖和列表的功能很相似,唯独就是一旦创建成功就不允许元祖的元素的修改
元祖的创建方法:
>>> tup1 = (1, 2, 3, 4, 5, 6) #元祖通过小括号和逗号分隔值
>>> tup1
(1, 2, 3, 4, 5, 6)
>>> tup2 = ("python", "java", "php", "c++", "go") #字符串还是需要加上引号
>>> tup2
('python', 'java', 'php', 'c++', 'go')
元祖的操作:
元祖很多功能都和列表一样,除了不能修改之外元素之外,其他的如索引等都可以。
>>> tup3 = tup1 + tup2 #这种方式是将两个列表和元祖合并成新的元祖和列表,元素还试单一的
>>> tup3
(1, 2, 3, 4, 5, 6, 'python', 'java', 'php', 'c++', 'go')
>>> tup4 = ("a", tup1, "b", tup2) #这种方式是将之前的列表和元祖作为新元祖和列表的一部分,元素是之前的列表和元祖的所有内容
>>> tup4
('a', (1, 2, 3, 4, 5, 6), 'b', ('python', 'java', 'php', 'c++', 'go')) #上诉的两种方式要注意区分下
元祖的元素是不允许删除的,我们可以删除整个元祖
>>> tup1
(1, 2, 3, 4, 5, 6)
>>> del tup1 #通过del来删除元祖
>>> tup1
Traceback (most recent call last):
File "<pyshell#22>", line 1, in <module>
tup1
NameError: name 'tup1' is not defined
F:字典
字典也是和列表元祖类似,可变化,可存储任意对象
元祖的创建方法:
>>> dic1 = {1 : "python", 2 : "java", 3 : "php"} #字典是通过花括号外加键值对和逗号分隔值
>>> dic1
{1: 'python', 2: 'java', 3: 'php'}
字典的就已经和一些数据库类似了,通过键值对来存储更加复杂的数据。
字典的操作:
>>> dic1
{1: 'python', 2: 'java', 3: 'php'}
>>> dic1[1] = "c" #通过key来改value
>>> dic1
{1: 'c', 2: 'java', 3: 'php'}
>>> dic2
{'a': 'app', 'b': 'bmw', 'c': 'cdn', 'd': 'dns'}
>>> dic2["b"] #指定key来查看value
'bmw'
>>> len(dic1) #通过len统计键值对的数目
3
>>> str(dic2) #将字典以字符串的形式显示字典全部内容
"{'a': 'app', 'b': 'bmw', 'c': 'cdn', 'd': 'dns'}"
字典基本操作:
>>> dic1.clear()
>>> dic1
{}
>>> dic2
{'a': 'app', 'b': 'bmw', 'c': 'cdn', 'd': 'dns'}
>>> dic3 = dic2.copy()
>>> dic3
{'a': 'app', 'b': 'bmw', 'c': 'cdn', 'd': 'dns'}
#在拷贝操作还有一个深浅拷贝,这个后续讲到
tup = ("python", "java", "php")
dic = dict.fromkeys(tup)
print(dic)
dic = dict.fromkeys(tup, 2017)
print(dic)
list1 = ["A", "B", "C"]
dic = dict.fromkeys(list1)
print(dic)
dic = dict.fromkeys(list1,1)
print(dic)
#执行结果:
{'python': None, 'java': None, 'php': None}
{'python': 2017, 'java': 2017, 'php': 2017}
{'A': None, 'B': None, 'C': None}
{'A': 1, 'B': 1, 'C': 1}
#可以看到fromkeys()方法可以快速将元祖和列表转换成字典之外,还能进行赋值, fromkeys() 函数用于创建一个新字典,以序列list1或者tup中元素做字典的键,2017和1为字典所有键对应的初始值。
tup = ("python", "java", "php")
dic = dict.fromkeys(tup)
print(dic)
dic = dict.fromkeys(tup, 2017)
print(dic.get("java"))
print(dic.get(1))
print(dic.get("heelo", "c++"))
#执行结果:
{'python': None, 'java': None, 'php': None}
2017
None
python
#如果key存在则返回key对应的value,如果不存在就返回None,也可以指定来返回value
tup = ("python", "java", "php")
dic = dict.fromkeys(tup)
print(dic)
dic = dict.fromkeys(tup, 2017)
if "python" in dic:
print("key:python存在","值是:",dic.get("python"))
else:
print("key:python不存在,请重新赋值")
if "go" in dic:
print("key:go存在","值是:",dic.get("go"))
else:
print("key:go不存在,请重新赋值")
#执行结果:
{'python': None, 'java': None, 'php': None}
key:python存在 值是: 2017
key:go不存在,请重新赋值
#通过循环遍历查找dic,如果存才就得到对应的值,如果不存在就提醒重新赋值
tup = ("python", "java", "php")
dic = dict.fromkeys(tup)
print(dic)
dic = dict.fromkeys(tup, 2017)
print(dic.items())
for i, j in dic.items():
print(i,":", j)
#执行结果:
{'python': None, 'java': None, 'php': None}
dict_items([('python', 2017), ('java', 2017), ('php', 2017)])
python : 2017
java : 2017
php : 2017
#items()方法可以遍历字典里面的key和value,并打印出来
tup = ("python", "java", "php")
dic = dict.fromkeys(tup)
print(dic)
dic = dict.fromkeys(tup, 2017)
print(dic.keys())
for i in dic.keys():
print(i)
#执行结果:
{'python': None, 'java': None, 'php': None}
dict_keys(['python', 'java', 'php'])
python
java
php
#keys()方法值统计字典的所有key内容
#(注:setdefault()和get()的方法类似,都是通过键去查询值,单两者也有不一样的地方。)
dic = {'A': "python", 'B': "java"}
print(dic.setdefault('A'))
print(dic.setdefault('c', None))
print(dic)
print(dic.get('B',))
print(dic.get('d', None))
print(dic)
#执行结果:
python #如果此键有值就返回存在的值
None #如果此键没有值就返回默认值
{'A': 'python', 'B': 'java', 'c': None}#并将新键值对更新到字典中
java #如果此键有值就返回存在的值
None #如果此键没有值就返回默认值
{'A': 'python', 'B': 'java', 'c': None}#并不会更新字典原始内容
#(注:字典 update() 方法可以将字典1的内容更新(合并)到字典2中)
dic1 = {'A': "python", 'B': "java"}
dic2 = {1: "X", 2: "Y"}
dic1.update(dic2)
print(dic1)
dic2.update(dic1)
print(dic2)
#执行结果:
{'A': 'python', 'B': 'java', 1: 'X', 2: 'Y'}#将字典2中的键值对合并到了字典1中,并在原始的字典最后面添加
{1: 'X', 2: 'Y', 'A': 'python', 'B': 'java'}#将字典1中的键值对合并到了字典2中.
#(注:字典 values() 方法可以返回字典中所有值)
dic1 = {'A': "python", 'B': "java"}
dic2 = {1: "X", 2: "Y"}
dic1.update(dic2)
print(dic1)
print(dic1.values())
dic2.update(dic1)
print(dic2)
print(list(dic2.values()))
#执行结果:
{'A': 'python', 'B': 'java', 1: 'X', 2: 'Y'}
dict_values(['python', 'java', 'X', 'Y'])#这种表现方式不太友好
{1: 'X', 2: 'Y', 'A': 'python', 'B': 'java'}
['X', 'Y', 'python', 'java']#调整下,让其输出到列表中,可以看到所有值都在列表中
#(注:字典 pop() 方法可以删除指定key的值,必须要指定key,否则返回default值。)
dic1 = {'A': "python", 'B': "java"}
dic2 = {1: "X", 2: "Y"}
dic1.update(dic2)
print(dic1)
dic1.pop('A')
print(dic1)
print(dic2)
#执行结果:
{'A': 'python', 'B': 'java', 1: 'X', 2: 'Y'}
{'B': 'java', 1: 'X', 2: 'Y'}#可以看到A所在的键值对就删除掉了
{1: 'X', 2: 'Y'}
#(注:字典 popitem()方法也是删除,不过是随机删除字典中的一对键值对(一般从末尾开始删除),不需要指定key,直接删除。
dic1 = {'A': "python", 'B': "java", 'C': "c++"}
print(dic1)
dic1.popitem()
print(dic1)
dic1.popitem()
print(dic1)
dic1.popitem()
print(dic1)
dic1.popitem()
#执行结果:
{'A': 'python', 'B': 'java', 'C': 'c++'}
{'A': 'python', 'B': 'java'} #popitem()默认每次都会从末尾开始删除
{'A': 'python'}#每次删掉一对键值对
{}
Traceback (most recent call last):
File "F:/pythonpath/data1/1.py", line 10, in <module>
dic1.popitem()
KeyError: 'popitem(): dictionary is empty'
#当字典中已经没有键值对可以删除就会报KeyError(popitem():字典是空的”)的错误
♣六;文本的基本操作
文件的操作是我们在python中以后会经常用到的,所有需要对文件操作需要很熟悉。
文件操作大致也就分三步:
1:打开文件
2:操作文件
操作文件也是我们学习文件操作的主要目的,只要对文件有操作的情况下都是有模式的,常规的四种分类
常规模式:
- r 只读模式 (默认)
- w 只写模式 (不可读,不纯在就创建,纯在则删除原始内容)
- a 追加模式 (可读,不存在就创建,存在就追加内容)
- x 写模式 (不可读,不存在就创建,存在就报错)
+模式:
- r+ 可读写文件(可读,可写,可追加)
- w+ 写读模式
- a+ 追加模式(没有意义)
- x+ 写读模式
u模式(这个是当你文件里面有\n,\r自动帮你转换成\n,这个和上面的+模式配合起来使用)
- ru
- r+u (这个用的比较多,当文件有\n,\r的时候,r+n可以将\n转化成本来的意义,还有就是你写文件的时候,r+n模式也会把\n,\r保留为本来的意思)
b模式(表示处理二进制文件,这个模式在linux系统下就没有意义,因为linux系统下一切皆文件,而在windows系统下这个就很有意义了,所以在win系统下要用到这个模式传文件到linux下就很有必 要)
- rb
- wb
- ab
- xb
3:关闭文件
在常规操作中,文件都是放在目录下的文件夹里面,所有还需要会创建文件夹和寻找目录,这个需要用到我们后面需要用到的os模块,这边简单介绍下基础操作。
os.makedirs和os.mkdir用法:
import os import os.path os.makedirs(r"F:\python1\test") #创建多层目录 os.mkdir(r"F:\test1") #创建单层目录
执行结果:
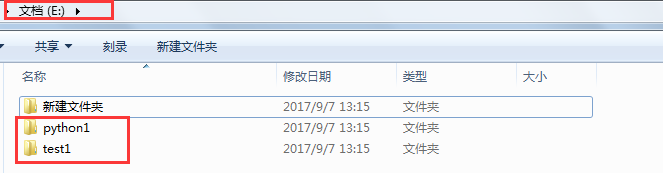 可以看到我本地的E盘下创建了python1的多层目录和test1的单层目录
可以看到我本地的E盘下创建了python1的多层目录和test1的单层目录
os.chdir(更改工作目录);os.getcwd(返回当前工作目录);os.listdir(返回指定路径下的文件和文件夹名字的列表);os.rename(文件重命名)用法:
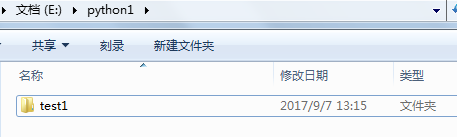 可以看到当前路径下的文件名
可以看到当前路径下的文件名
import os
import os.path
print("当前目录为:%s" % os.getcwd())
os.chdir("E:\python1")
print("更改当前目录为:%s" % os.getcwd())
print("E盘:\pthon1下有:%s" % os.listdir(),"文件")
print("重命名E盘:\pthon1下test1为:%s" % os.listdir(os.rename("test1", "test2")),"文件")
os.mkdir("test3")
print("E盘:\pthon1下有:%s" % os.listdir(),"文件")
#执行结果
当前目录为:F:\pythonpath\data1
更改当前目录为:E:\python1
E盘:\pthon1下有:['test1'] 文件
重命名E盘:\pthon1下test1为:['test2'] 文件
E盘:\pthon1下有:['test2', 'test3'] 文件
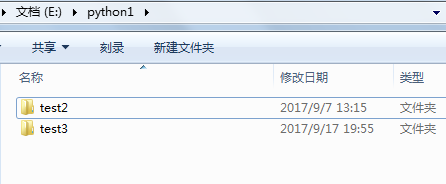 可以看到代码执行结果,已经将源文件夹test1重命名为test2
可以看到代码执行结果,已经将源文件夹test1重命名为test2
文件夹创建好之后就是存储文件和内容,在文件操作和文件夹类似,都是需要相应的模式来处理。
注:要注意最后一定要关闭文件:f.close(),close()可以允许调用多次,当文件关闭就不能在进行读写操作,否则会触发ValueError 错误,或者当file对象被引用来操作另外一个文件的时候,python就会自动关闭之前的
file对象,使用close()方法关闭文件是一个好习惯,可以规避不必要的错误。
python只能将字符串写入到文本文件。要将数值数据存储到文本本件中,必须先使用函数str()将其转换为字符串格式。
文件的创建,写入,读取实例:
#coding=gbk
import os
import os.path
print("当前工作的目录为: %s" % os.getcwd())
os.chdir("D:\python project")
print("更改当前工作目录为: %s" % os.getcwd())
os.mkdir("file")
print("D:\python project下有:%s" % os.listdir(),"文件")
os.chdir("D:\python project/file")
file_test = open("test.txt", 'w')
print("D:\python project/file下有:%s" % os.listdir(),"文件")
file_test.write("hello word!\nhello python")
file_test.close()
print("读取test.txt内容:\n",open("test.txt").read())
file_test.close()
#执行结果:
当前工作的目录为: D:\pycharm\python path\untitled
更改当前工作目录为: D:\python project
D:\python project下有:['file'] 文件
D:\python project/file下有:['test.txt'] 文件
读取文件内容:
hello world!
hello python
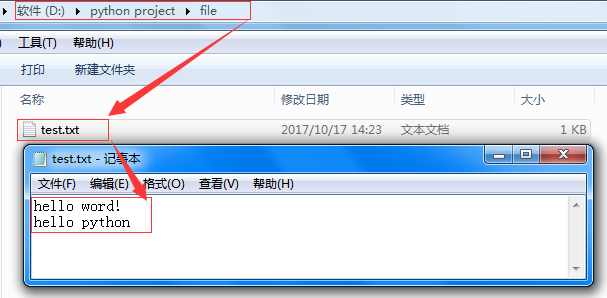 可以看到我本地D盘的文件目录结构和文件内容
可以看到我本地D盘的文件目录结构和文件内容
文件的读取:
使用open函数或者file函数来读取文件,并使用文件名的字符串作为输入参数:
view1 = open("test.txt)
view2 = file("test.txt)
两种方法没有太大的区别,而且默认都是以读的方式打开文件,如果文件不存在就会报错。
用read方法读取文件里面所有内容
#coding=gbk
import os
import os.path
os.chdir("D:\python project/file")
view1 = open('test.txt')
text = view1.read()
print(text)
view1.close()
执行结果:
hello world!
hello python!
还可以使用readlines方法返回一个列表,某个元素代表文件里面的一行内容:
#coding=gbk
import os
import os.path
os.chdir("D:\python project/file")
view1 = open('test.txt')
text = view1.readlines() #后面会将到文件的三种读取方式
print(text)
view1.close()
#执行结果
['hello world!\n', 'hello python!\n', 'python文件的读取实例\n']
指定文件文件字符串下标读取内容:
#coding=gbk
import os
import os.path
os.chdir("D:\python project/file")
view1 = open('test.txt', "w+")
view1.write("hello world!")
view1.seek(6) #从文件的第六行开始,读取后面的全部内容
print(view1.read())
view1.close()
#执行结果
world!
文件内容的追加和覆盖:
#coding=gbk
import os
import os.path
os.chdir("D:\python project/file")
view1 = open('test.txt', "a") #a模式是追加,默认会追加到文件最后一行
view1.write("python is good!")
view1.close()
view2 = open("test.txt")
text = view2.read()
print(text)
view2.close()
#执行结果
hello world!
hello python!
python文件的读取实例python is good!python is good!python is good!
#coding=gbk
import os
import os.path
os.chdir("D:\python project/file")
view1 = open('test.txt', "w") #当文件存在,w模式会之前所写的所有内容
view1.write("file to delent!")
view1.close()
view2 = open("test.txt")
text = view2.read()
print(text)
view2.close()
#执行结果
file to delent!
文件的【+】模式:w+是读写模式,文件存在就覆盖。
#coding=gbk
import os
import os.path
os.chdir("D:\python project/file")
view1 = open('test.txt', "w+")
view1.write("hello world!")
view1.seek(6) #从文件的第六行开始,读取后面的全部内容
print(view1.read())
view1.close()
#执行结果
world!
文件操作后续功能:
# 原文件内容:历史上十大名人语录 # k = open("log.txt",mode="r+",encoding="utf-8") # #k.read(5) #读出来都是字节 # k.seek(k.tell() + 18) #tell的作用是定位光标在哪里,一般都是末尾。 # # #seek的主要作用就是调整光标,我们将他调整9个字节(一个汉字=3个字节码) # print(k.read()) # k.close() # #执行结果 # 人语录
#k = open("log.txt",mode="r+",encoding="utf-8") #count=k.readline()#一行一行的读 #执行结果: #历史上十大名人语录 #其实文件里面是4行内容 #count=k.readlines()每一行当成列表里面的一个元素 #执行结果: #['历史上十大名人语录\n', '历史上十大名人语录\n', '历史上十大名人语录\n', '历史上十大名人语录\n', '历史上十大名人语录\n'] #k.truncate(5)#对原文件进行截取,seek是显示的截取 #print(count) #k.close()
在实际工作中一定要使用一行一行或者光标定位一段去读,因为生产文件实时在更新,是不知道有多大的文件。
with open("log.txt",mode="r+",encoding="utf-8") as file1,open("log1.txt",mode="w+",encoding="utf-8") as file2: print(file1.read(),file2.read()) #with语句可以方便用户不用在每次读取完文件之后进行close,with读完直接关闭 #with语句后面可以接多个文件集中操作
username = input('请输入您要注册的用户名:') password = input('请输入注册的用户名密码:') with open('account_account',mode='w',encoding='utf-8') as f: f.write('{}\n{}'.format(username,password)) #用format进行格式化 print('恭喜注册成功') lis = [] i = 0 while i<3: uname = input('请输入您的用户名:') pwd = input('请输入户名密码:') with open('account_account',mode='r+',encoding='utf-8') as f1: for line in f1: lis.append(line) if uname == lis[0].strip() and pwd == lis[1].strip(): print('登陆成功') break else: print('账号和密码错误') i+=1
(注:在windows上的文件有时候会遇到编码问题导致的困扰,这个时候需要在读取文件的同时进行声明文件的编码,encoding=‘gbk’ and enconfig=‘utf-8-sig’)
后面还会大量的使用到文件的操作,比如execl,word的文件都是需要模块是支持的。
posted on 2017-08-01 14:27 ppc_server 阅读(634) 评论(0) 编辑 收藏 举报

