re正则--匹配方法
--re.match()方法
语法:re.match(pattern,string,flags)
其中flags表示的标志位。有以下几种
re.I 忽略大小写
re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M 多行模式
re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
re.X 为了增加可读性,忽略空格和
re.match方法:尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 none。
import re url = 'https://www.baidu.com' result = re.match('http',url).span() print(result)
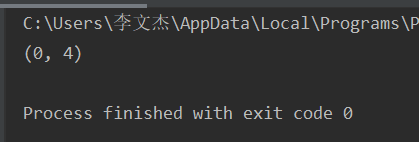
不是从头开始匹配的,直接返回None
import re url = 'https://www.baidu.com' result = re.match('www',url) print(result)
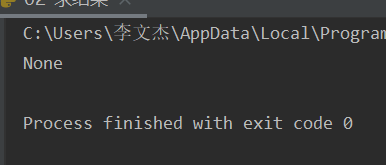
---re.search()方法
re.search(pattern,string,flags) 扫描整个字符串并返回第一个成功的匹配,和re.match区别是全字符串匹配,不限于头部。
import re
url = 'https://WWW.baidu.com'
result = re.search('www',url,flags=re.I)
print(result)
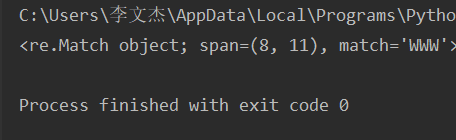
--re.split()
re.spilit()方法按照能够匹配的子串将字符串分割后返回列表
语法:split(pattern, string, maxsplit=0, flags=0)
import re url = 'https://WWW.baidu.com,https://www.taobao.com' result = re.split(',',url,flags=re.I) print(result)
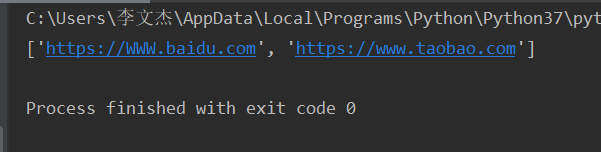
----re.sub()
匹配字符并且进行替换
语法:sub(pattern, repl, string, count=0, flags=0)
import re
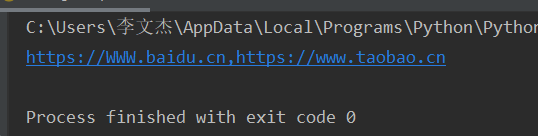
url = 'https://WWW.baidu.com,https://www.taobao.com'
result = re.sub('com','cn',url,flags=re.I)
print(result)
--re.findall()
re.findall()用法与其他一样,与re.match和re.search不同的是,re.findall可以匹配多个,用()括起来,返回一个列表,列表的内容就是()内匹配到的字符
import re
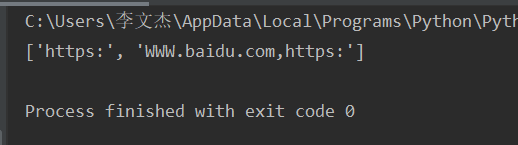
url = 'https://WWW.baidu.com,https://www.taobao.com'
result = re.findall('(.*?)//',url,flags=re.I)
print(result)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号