无需学习Python,一个公式搞定领导想看的大屏
摘要:本文由葡萄城技术团队于博客园原创并首发。转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。
不要让“做不了”成为数字化转型的障碍
随着数字化的脚步加快,越来越多的企业开始注重数据的展示和报告。原有数据的整合,清洗,二次加工变得越来越普遍。为了实现以上功能,企业不得不花大量的人力、物力去做原始数据的加工,但是由于业务场景的快速变化,导致原有代码里面写死的数据处理逻辑和现实的需要产生严重的偏离。针对这些,迫切希望有一个能自己实现数据处理,然后将处理结果进行多维度展示的工具。那么今天,就给大家推荐一款软件工具——Wyn商业智能软件。
作为一款BI软件,Wyn商业智能软件本身支持各种炫酷的可视化展示能力以及自助式BI分析能力,基本可以满足企业绝非大部分数据展示的需求。灵活的嵌入式能力,让使用者可以真正做到无感代入。而且随着产品的发展,更多强大且灵活的表达式也被依次引入,使得他可以面对越来越多的用户场景,今天,给大家带来几个常见的用户场景,来看看如何用公式一键实现领导想看的所有数据,轻松做出一张领导满意的大屏。
强大的数据分析能力-表达式分析(附带Demo)
介绍表达式之前,先大概介绍一下软件的应用界面和一些基本的使用方法。(本次重点介绍的是Wyn商业智能软件仪表板设计器层面的直接分析方法。所有方法都可以直接在仪表板上添加)
分析表达式支持两种:计算列和度量值。
计算列:是指在原表的基础上新增一列,新增的列相当于新的字段被使用,通常被用作过程计算的分析和创建新维度分析,也可以用作直接计算使用。
度量值:度量值需要做一定的聚合运算,它会在你绑定分类的基础上,去计算你设置的表达式,所以更多是在维度分析的基础上做计算分析,产生的结果也只能被用在数值字段上,因为其中的数据本身就是被计算出来的结果。
表达式界面基础介绍:
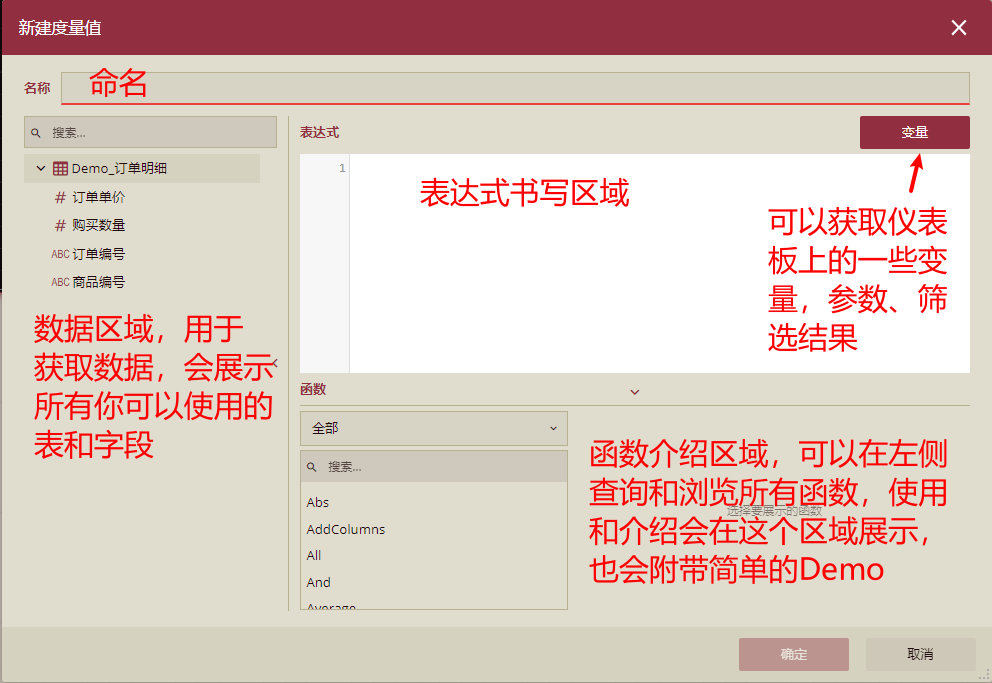
有几点可以特别留意一下:
1)在书写表达式的时候,通常可以将比较困难的表达式拆分为多个表达式。例如(a+b)*c,我们可以先将a+b计算的结果作为一个新的计算列,然后这个计算列会作为一个新的字段被再次复用去乘c,这样就可以抽取共享字段,提高复用性。
2)合理利用Filter、calculate等过滤函数,可以一定程度加快表达式的计算,当不再需要某些值时,减少过多的if使用,而是直接将这些数据过滤掉,提高表达式速度。
可以使用“//”写注释,同时,在一些表达式里面加上自己的备注,方便以后阅读和其他人的接手。
3)在使用的过程中 ’ ’ 单引号中间是写“表名”、 []中括号中间写“字段名”、 “”双引号代表“字符串”。例如: ’销售明细’[订单金额] 代表的是销售明细表的订单金额字段,在多个表没有字段名重复的时候,可以直接使用[]引用字段,不带表名。(注意:所有都是英文字符)
具体详细了解可以参考帮助文档的介绍(https://www.grapecity.com.cn/solutions/wyn/help/docs/wax),这里就不多做赘述了。直接开始表达式介绍:
- 同比-环比
相信在很多分析场景中,同比和环比永远都不会缺席,无论是在月度分析,季度分析还是年度分析的。大家都会关注相对于上个时间维度,或者同期维度的变化情况。这也是基础的、领导想看到的数据对比方式。
同比分析:
年度同比其实就是计算当前年的总合计和上一年的总合计,然后计算同期增长率即可。
所以第一步,计算去年合计:
var basetable = SelectColumns(
'同比测试',
"年度", '同比测试'[下年度],
"订单金额",'同比测试'[订单金额])
return Calculate(
SumX(basetable,[订单金额]), Values([年度]))
上述表达式中,首先创建了一个临时表,在临时表中新增两个字段,年和金额。其中,年取的是当前年的下一年,也就是年度+1。而这个年就是下一个表达式中我们用作过滤的条件。
第二个表达式先用新建的表做一个金额的求和,然后再去过滤“年”字段(values[年度])。因为实际取值的时候,会根据关联过滤,取到对应同比的值,再去计算同比即可。具体可以参考下面图解。
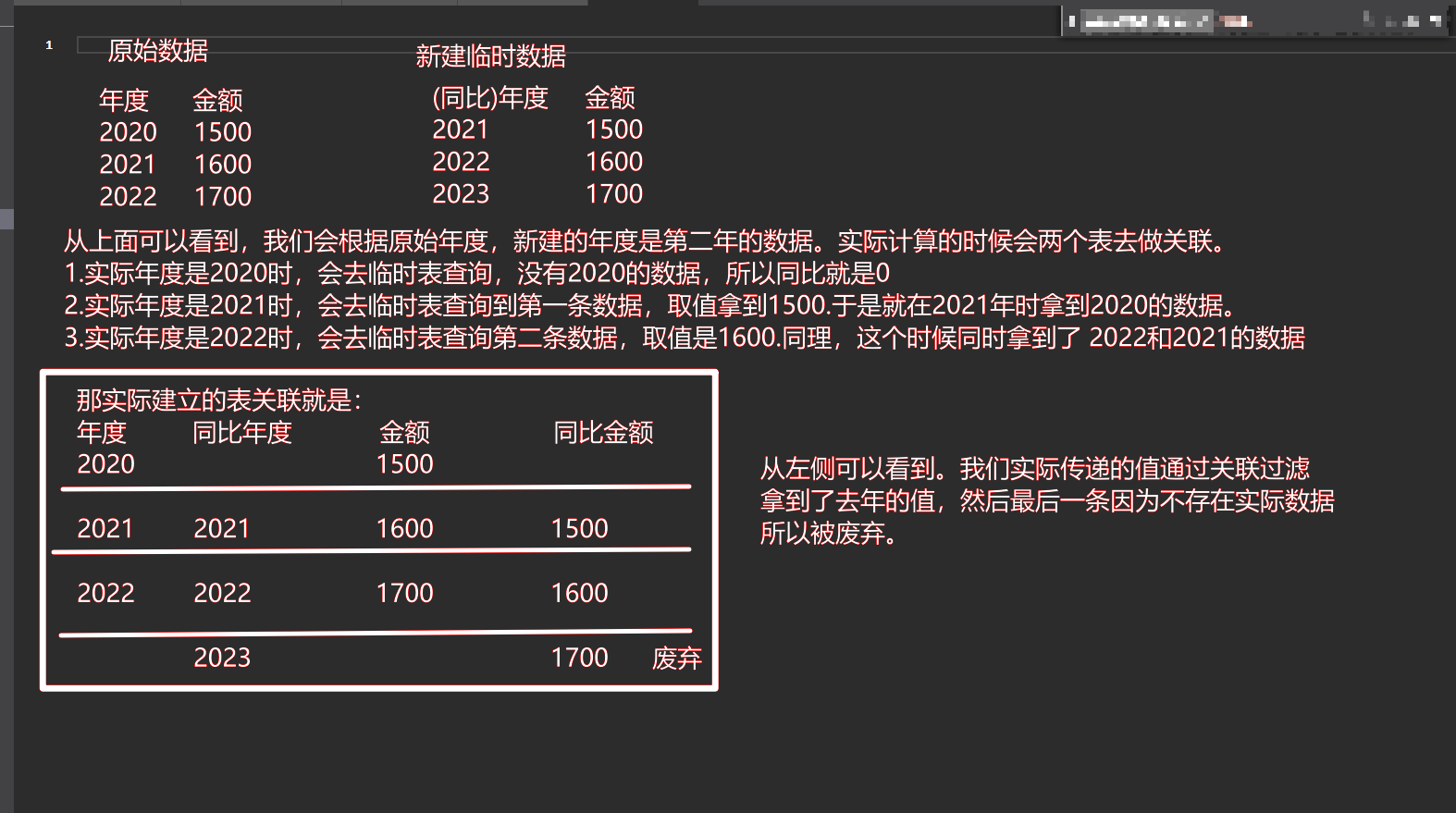
Divide('同比测试'[当前年合计] - '同比测试'[去年合计], '同比测试'[去年合计])
最后一步就是求同比,这个表达式就很简单,使用今年合计减去去年合计,然后除去年,就是增长率了。
环比分析:
有了同比的基础,环比其实也是同样的道理。同比是取去年的,而环比是取上个季度或者上个月度的。以同季度为例,表达式如下:
var basetable = SelectColumns(
'同比测试',
"年度", '同比测试'[环比年度],
"季度", '同比测试'[环比季度],
"订单金额",'同比测试'[订单金额])
return Calculate(
SumX(basetable,[订单金额]), Values([年度]))
其原理还是一样的,首先新建一个临时表,使用临时表的环比年度和环比季度做计算。这里可以参考上一个同比年的理解,当计算对象为前三个季度时,自然无需做任何处理,自然加一即可,但是当你是第四季度时,这时候不存在第五季度,所以就需要配合年度,年度先加一,然后季度返回第一季度,也就是返回第二年的第一季度。做好之后,按照上面的方式做计算和过滤,传年做过滤即可。
数据准备好之后,就是展示环节了。简单的将系统所做的数据拖拽到页面上,就可以看到效果了:
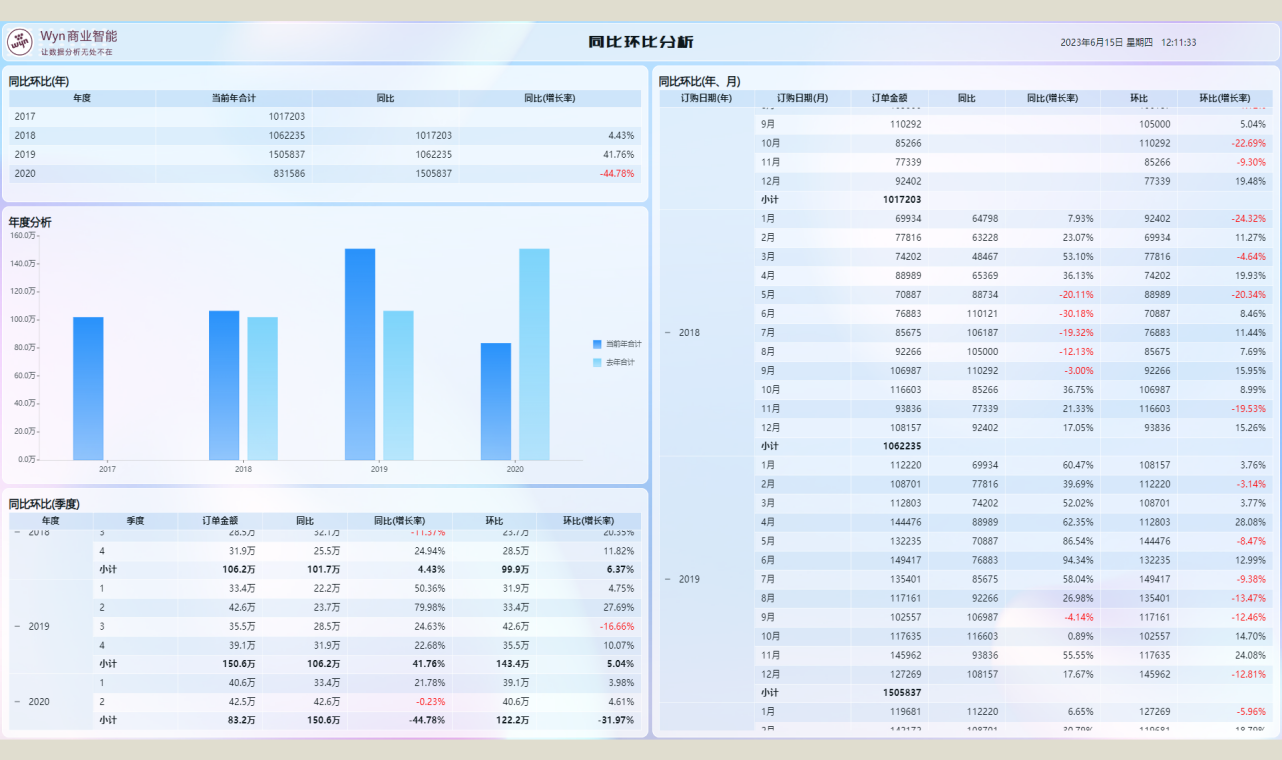
至此,一个同比-环比的分析就做好啦。
- 区间分析
在经营分析场景中,往往会看到满屏的销售数据,不同地区的销售额度杂乱无章的摆放着,没有做任何区分。这个时候就需要对最终的数据做区间分析了。比如想知道销售额度在100w-200w的有哪些地区,200w-300w的哪些地区。
针对这种场景,应该怎么实现呢?先一起来梳理一下思路:
首先明确是否要按不同地区求金额的总和,然后要把这些地区划分出来,按不同销售额度来进行划分。这样就可以将数据划分为多个区间进行分析。具体的实现方法如下:
var sales = SUMX('订单明细','订单明细'[购买数量]\*'订单明细'[订单单价])
var sales1 =
calculate(sales,Values('销售大区'[大区]))
var categories=
SWITCH(
TRUE,
sales1 \< 8000000, "小于800万",
sales1 \>= 8000000 && sales1 \< 12000000, "大于800万小于1200万",
sales1 \>= 12000000 , "大于1200万"
)
return categories
上述的第一步就是求金额的总和,求出来后就要按照大区做一个过滤。这个过滤会在数据绑定时自己做过滤,然后把求出来的金额按照想要的区间进行划分,从而就可以得到新的字段(计算列),同时可以对数据做了划分。接下来就是数据展示的环节了:
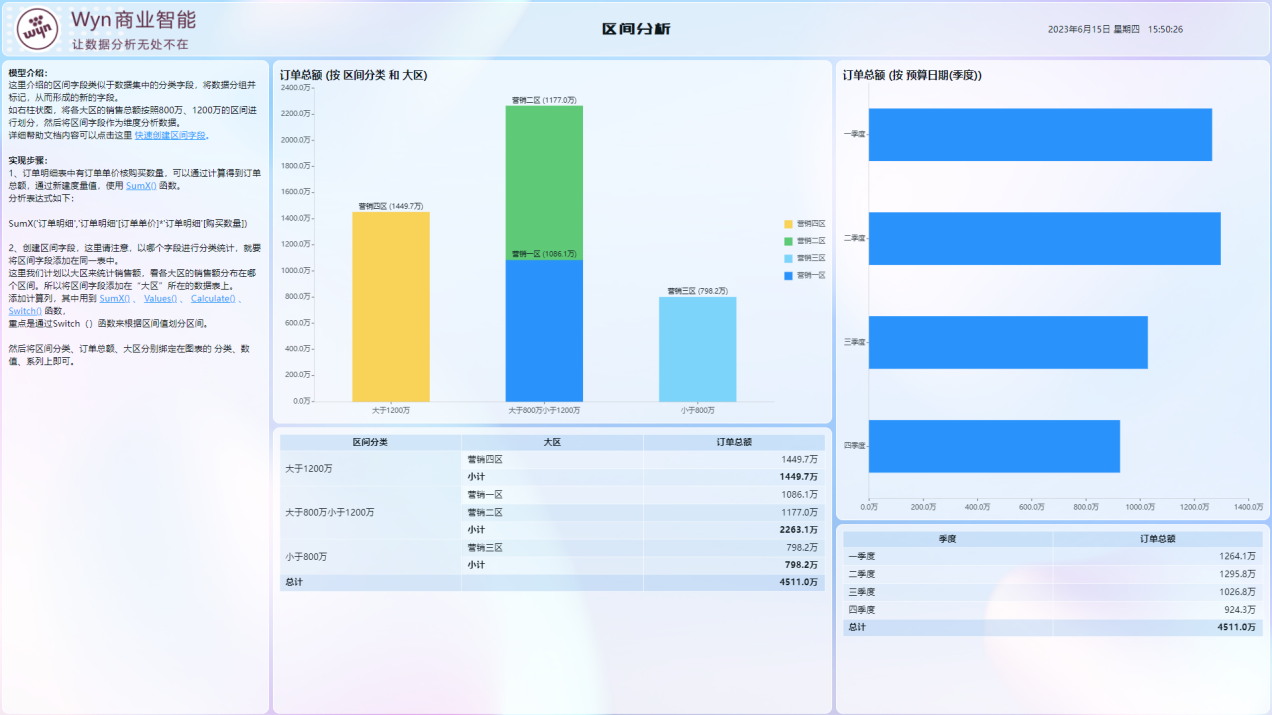
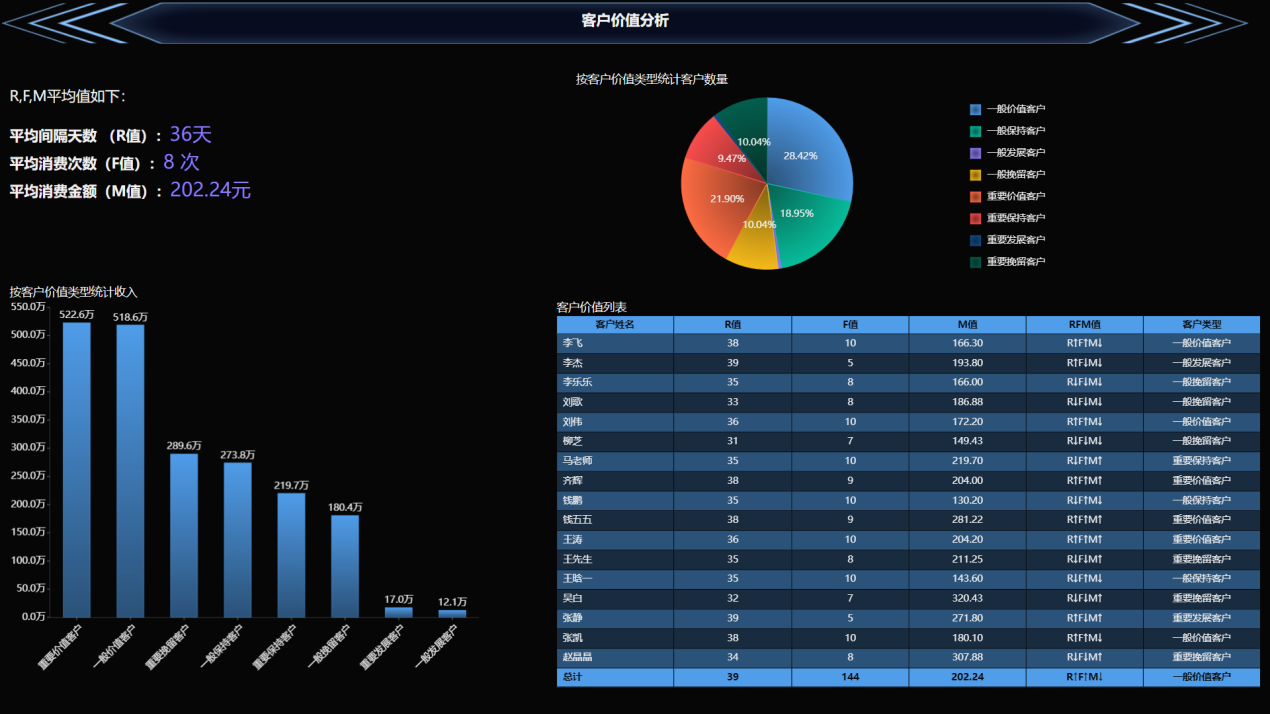
- RFM模型分析
除了上面介绍的常见应用,在销售指标方面RFM模型也是非常重要的一个衡量指标。它可以用来分析客户价值,让分析者能更清楚的知道哪些客户更重要。
- R (Recency),最近一次消费时间间隔
- F (Frequency),消费频率
- M (Monetary),消费金额
一般来说,最近一次消费的间隔越短、消费频率和消费金额越高,客户价值越大。而基于这个原理,就需要去计算对应的平均R,F,M分别是多少,然后再去对比这个客户相对于平均值是大于还是小于。大于平均值的自然就是价值更高的。
有了思路就开始,先计算平均R,F,M
R_Avg
CALCULATE(
AVERAGEX(
SUMMARIZECOLUMNS(
'Customer'[Name],
"rdayValues",
datediff(
'Sales'[Rday],
'Sales'[Rmax],
day
)
),
[rdayValues]
),
REMOVEFILTERS('Customer'[Name])
)
上述datadiff求的就是客户最后消费日期距离业务最新成交日期的天数,然后全部求平均值。因为是平均值,所以也要去除过滤器,否则绑定分类的时候会自动做分类。
F_Avg
CALCULATE(
AVERAGEX(
SUMMARIZECOLUMNS(
'Customer'[Name],
"fCount",
calculate(
DISTINCTCOUNTX('Sales','Sales'[Order Number])
)
),
[fCount]
),
REMOVEFILTERS('Customer'[Name])
)
这里其实就是求客户消费的不重复计数,也就是DISTINCTCOUNTX,然后再求所有的平均值和去除过滤,和之前一样
M_Avg
CALCULATE(
AVERAGEX(
SUMMARIZECOLUMNS(
'Customer'[Name],
"mValues",
calculate(
'Sales'[M]
)
),
[mValues]
),
REMOVEFILTERS('Customer'[Name])
)
最后就是消费金额的平均值,表达式中的【M】已经做了聚合,然后依旧是平均和去除过滤。
上述都是计算的平均值,也就是计算的对比字段,用来衡量客户的消费情况,之后就是计算每个客户自己的值。上述表达式中我们可以看到,每个最后都用到一个removeFilters。这个作用就是去除过滤。而作用就是Wyn实际计算会根据你绑定的分类做统计,也就是值会因为绑定的分类而不一样,所以每个客户的实际值计算也就很简单,把上面的所有表达式去除AVEGAGEX,去除removeFilters。也就是去除求平均,去除过滤器。就是每个客户自己的数据:
R:DATEDIFF( 'Sales'[Rday], 'Sales'[Rmax], Day )
F:DISTINCTCOUNTX('Sales','Sales'[Order Number])
M:SUMX( 'Sales', 'Sales'[Quantity]\*'Sales'[Net Price] )
然后用每个客户自己的值去和平均值做判断,就可以求出这个客户是不是更有价值。通过这样的方式,可以把所有的数据做一下区分:
R↑F↑M↑:重要价值客户
R↑F↑M↓:一般价值客户
R↑F↓M↑:重要发展客户
R↑F↓M↓:一般发展客户
R↓F↑M↑:重要保持客户
R↓F↑M↓:一般保持客户
R↓F↓M↑:重要挽留客户
R↓F↓M↓:一般挽留客户
那么就针对这个求它的价值,三个维度其实都是同理的:
R:IF( 'Sales'[R]\<='Sales'[Ravg], "R_UP", "R_DOWN" )
F::IF( 'Sales'[F]\<='Sales'[Favg], "F_UP", "F_DOWN" )
M:IF( 'Sales'[M]\<='Sales'[Mavg], "M_UP", "M_DOWN" )
到此为止,一个客户价值分析的数据模型便已经成型。一起来看看最终的展示结果吧:
介绍了这么多,相信大家也看到了Wyn商业智能软件强大和炫酷的界面。这里只是简单的介绍了几种方法,实际包含几十种不同的表达式,从时间、文本、数字等多层面都对数据可以分析。而且除了文章中提到的表达式,Wyn商业智能软件还提供了图表上可直接设置的排序、过滤、排名和字段格式化能力。让使用者轻松地就可以做出来一款完整的BI看板。
Wyn商业智能软件除了在BI设计层面可以做表达式计算,在数据获取层面也可以做表达式计算、分组计算以及权限控制等完整的功能。作为一款B/S架构的软件,客户只需要能访问服务器即可做出属于自己设计和展示的大屏。
除此之外,Wyn商业智能软件提供了上百个不同的接口,让使用者可以无感的嵌入到已有的系统或产品中。调用者可以单独做查看,单独调用接口获取平台数据等等。并且本身附带完善的权限控制,保证信息不外漏。同时,也可以做单点登录的集成,使用系统已有的公司人员组织管理数据。如此炫酷的软件,还不快入手尝试。
代码链接:https://github.com/GrapeCityXA/Wyn--formula
扩展链接:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号