
QEMU-KVM内存虚拟化
基础背景知识
物理上来说,不管是GuestOS还是HostOS,其进程最终都是跑在物理内存上的。这是毫无疑问的。
逻辑上来说,GuestOS认为的物理地址,其实是QEMU进程的虚拟地址,那以下的内容说明的是QEMU如何为GuestOS准备GPA,以及如何管理起来的。
QEMU版本:4.0.x
QEMU侧
这里重点说明的是render_memory_region()函数,调用流程其实很简单,但是这个函数比较复杂和抽象。
描述下render_memory_region()函数做的工作,以IO Memory region为例addr=0,size=65536;IO mr有一个子region,叫做kvmvacpi,addr=126,size=2.现在要将以上两个region转换为平坦的flatview。流程如下。
进入函数render_memory_region(),int128_addto(&base, int128_make64(mr->addr)); 这里mr->addr=0,那么这个函数结束后base=0,
接着: tmp = addrrange_make(base, mr->size);//这里mr->size=65536,base=0,函数结果tmp={start = 0, size = 65536}相当于一个地址范围。
clip = addrrange_intersection(tmp, clip);//这里clip代表整个64位地址空间,那么这个函数找到一个公共地址交集,显然函数返回值clip=tmp={start = 0, size = 65536}
由于此mr是最上层的mr,因此mr->alias为空。
QTAILQ_FOREACH(subregion, &mr->subregions, subregions_link) {
render_memory_region(view, subregion, base, clip,
readonly, nonvolatile);
}
这里是一个递归,将mr的子region,即就是kvmvacpi,对kvmvacpi做一次render memory region。
那么这里就重新进入render memory region,此时的输入mr就是kvmvacpi,base还是0,clip变成了{start = 0, size = 65536}(不再是原来的64bit地址空间)
那么接着还是之前的流程,int128_addto(&base, int128_make64(mr->addr));由于kvmvacpi这个mr的addr=126,因此这个函数结束后base=126.
tmp = addrrange_make(base, mr->size);这里mr->size=2, base=126,那么这个函数结束后,tmp={start = 126, size = 2}。
clip = addrrange_intersection(tmp, clip);//再和clip取交集,得到的函数结果clip={start = 126, size = 2}
后面就没有什么可说的了,因此该mr是一个单独的,不涉及alias以及subregion,而且view->nr=0,因此这里直接进入到:
offset_in_region = int128_get64(int128_sub(clip.start, base));
base = clip.start;
remain = clip.size;
以上:
offset_in_region=0
base=126
size=2
此时来到: if (int128_nz(remain))
这里直接生成第一个fr:
fr.offset_in_region = offset_in_region=0
fr.addr = addrrange_make(base, remain)= {start = 126, size = 2}
然后将fr插入到view的ranges数组中。
可以看看此时的view是什么样子。
p *view
183 $38 = {rcu = {next = 0x0, func = 0x0}, ref = 1, ranges = 0x555556a2d060, nr = 1, nr_allocated = 10, dispatch = 0x0, root = 0x5555569cdab0}
p view->ranges[0]
187 $39 = {mr = 0x555556a2c350, offset_in_region = 0, addr = {start = 126, size = 2}, dirty_log_mask = 0 '\000', r omd_mode = true, readonly = false, nonvolatile = false,
至此,对于子region的处理结束,退出子region处理流程,回到上一层。
也就是接着QTAILQ_FOREACH(subregion, &mr->subregions, subregions_link)这里往下继续走。
由于clip.start和base均为零,那么此时的offset_in_region=0.
以及:
base = clip.start;//base=0
remain = clip.size;//remain=65536
注意:此时的mr是io memory region,其subregion:kvmvacpi已经在刚才的QTAILQ_FOREACH中处理了。
接着到了for循环,此时的view->nr=1,可以进入循环处理。
now = int128_min(remain,int128_sub(view->ranges[i].addr.start, base));//这里处理之后now=126.
fr.offset_in_region = offset_in_region;//fr.offset_in_region=0
fr.addr = addrrange_make(base, now);// {start = 0, size = 126}
那么此时可以看出,0~126这个地址范围也组成了一个fr,即将被放入到view中。并且编号是0。(这里有个疑问那之前range[0]保存的kvmvacpi到哪里去了呢?原来在flatview_insert函数中有一个拷贝的操作,将range[0]拷贝到range[1]位置上。并且++view->nr)
后面的fr依次是{start=126, size=2}和{start=128,size=65408}
如下:
(gdb) p view->ranges[0]
373 $75 = {mr = 0x5555569cdab0, offset_in_region = 0, addr = {start = 0, size = 126}, dirty_log_mask = 0 '\000', r omd_mode = true, readonly = false, nonvolatile = false,
374 has_coalesced_range = 0}
375 (gdb) p view->ranges[1]
376 $76 = {mr = 0x555556a2c350, offset_in_region = 0, addr = {start = 126, size = 2}, dirty_log_mask = 0 '\000', r omd_mode = true, readonly = false, nonvolatile = false,
377 has_coalesced_range = 0}
378 (gdb) p view->ranges[2]
379 $77 = {mr = 0x5555569cdab0, offset_in_region = 128, addr = {start = 128, size = 65408}, dirty_log_mask = 0 '\0 00', romd_mode = true, readonly = false, nonvolatile = false,
需要说明的是: view->ranges[i]中有一个offset_in_region这个字段,表示的是在fr所属的region中偏移量。例如ranges[0]所属的mr是IO Memory region,并且其实地址start=0,故offset_in_region=0;ranges[1]所属的mr是kvmvacpi,这个kvmvacpi的base地址就是126,起始地址start=126,这个fr在kvmvacpi这个mr中的offset也是0;ranges[2]所属的mr是IO Memory region,base=0,fr的start=128,故offset是128.
KVM侧
当通过
memory_region_transaction_commit()
->flatviews_reset()
->render_memory_region()
之后,
就开始调用address_space_set_flatview()以及address_space_update_topology_pass()来将相关内存的改动提交到kvm中。所以下面主要就是更新到kvm的前后做的工作。
注意:往后续代码中可以看出,如果此内存不是RAM,那么该Address Space中的MemoryRegion不会注册到KVM中,这其实是符合理论的。因为在x86中IO地址空间是一个独立的地址空间。如x86 CPU的I/O空间就只有64KB(0-0xffff),大小为65536(关于IO地址空间的理论可以看这里:https://www.cnblogs.com/wuchanming/p/4732595.html)
总结
总体来说,流程如下:
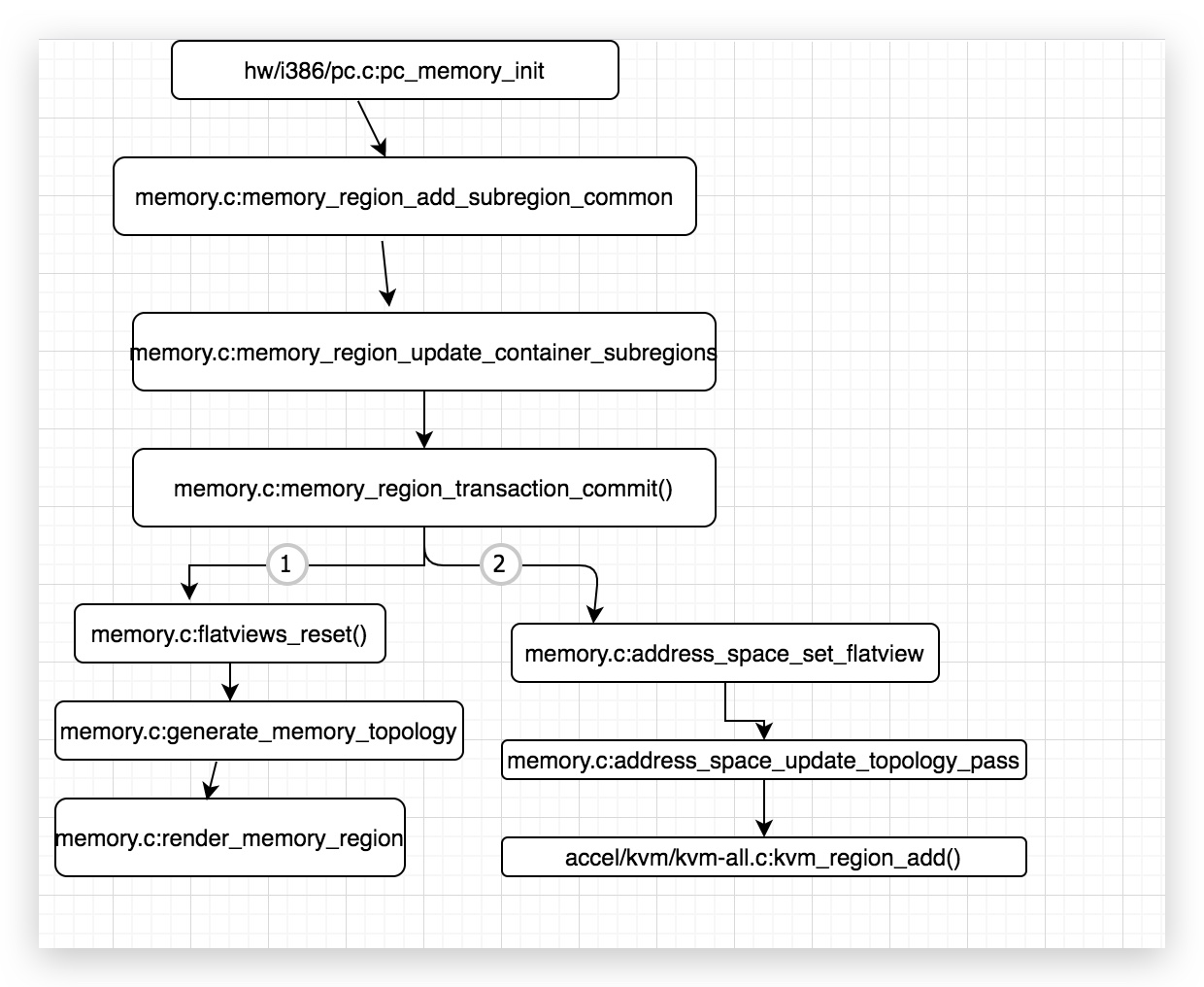
这里再说说render_memory_region()这个函数。render这个函数是从memory_region_add_subregion()这个函数开始调用的。
通过分析调用可以发现,render_memory_region()函数参数列表中的MemoryRegion *mr实际上就是memory_region_add_subregion()的第一个参数:system_memory
FlatView 的dispatch初始化。
这里还算是比较关键的步骤,因为这里会涉及到以后的在QEMU中GPA到HVA 转换(在IO过程中,会通过GPA找到对应的memoryregion,而在MemoryRegion上注册了Op用于处理IO。)
static FlatView *generate_memory_topology(MemoryRegion *mr)
{
int i;
FlatView *view;
view = flatview_new(mr);
if (mr) {
render_memory_region(view, mr, int128_zero(),
addrrange_make(int128_zero(), int128_2_64()),
false, false);
}
flatview_simplify(view);
view->dispatch = address_space_dispatch_new(view);
for (i = 0; i < view->nr; i++) {
MemoryRegionSection mrs =
section_from_flat_range(&view->ranges[i], view);
flatview_add_to_dispatch(view, &mrs);
}
address_space_dispatch_compact(view->dispatch);
g_hash_table_replace(flat_views, mr, view);
return view;
}
然后从这里view->dispatch = address_space_dispatch_new(view); 这里初始化Phy Page。
这个页表会用于在QEMU的GPA到HVA转换。
以下函数address_space_dispatch_new()用于分配一个dispatch。
AddressSpaceDispatch *address_space_dispatch_new(FlatView *fv)
{
AddressSpaceDispatch *d = g_new0(AddressSpaceDispatch, 1);
uint16_t n;
n = dummy_section(&d->map, fv, &io_mem_unassigned);
assert(n == PHYS_SECTION_UNASSIGNED);
n = dummy_section(&d->map, fv, &io_mem_notdirty);
assert(n == PHYS_SECTION_NOTDIRTY);
n = dummy_section(&d->map, fv, &io_mem_rom);
assert(n == PHYS_SECTION_ROM);
n = dummy_section(&d->map, fv, &io_mem_watch);
assert(n == PHYS_SECTION_WATCH);
d->phys_map = (PhysPageEntry) { .ptr = PHYS_MAP_NODE_NIL, .skip = 1 };
return d;
页表的建立过程是在flatview_add_to_dispatch()函数中完成的,具体过程可以参考以下:
注册页表的过程:
static void register_multipage(FlatView *fv,
MemoryRegionSection *section)
{
AddressSpaceDispatch *d = flatview_to_dispatch(fv);
hwaddr start_addr = section->offset_within_address_space;
uint16_t section_index = phys_section_add(&d->map, section); //将section加入到数组中,返回section在数组中的index,页表中其实保存的就是这个索引。
uint64_t num_pages = int128_get64(int128_rshift(section->size,
TARGET_PAGE_BITS));
assert(num_pages);
phys_page_set(d, start_addr >> TARGET_PAGE_BITS, num_pages, section_index);
}
static void phys_page_set(AddressSpaceDispatch *d,
hwaddr index, hwaddr nb,
uint16_t leaf)
{
/* Wildly overreserve - it doesn't matter much. */
phys_map_node_reserve(&d->map, 3 * P_L2_LEVELS);
phys_page_set_level(&d->map, &d->phys_map, &index, &nb, leaf, P_L2_LEVELS - 1);
}
static void phys_page_set_level(PhysPageMap *map, PhysPageEntry *lp,
hwaddr *index, hwaddr *nb, uint16_t leaf,
int level)
{
PhysPageEntry *p;
hwaddr step = (hwaddr)1 << (level * P_L2_BITS);
//如果skip = 0,则表示该ptr指向的是页表项,页表项指向MemoryRegionSection.看下默认情况下,skip为多少?
//address_space_dispatch_new()函数在初始化phys_map的时候讲skip置为1,ptr初始化为PHYS_MAP_NODE_NIL
if (lp->skip && lp->ptr == PHYS_MAP_NODE_NIL) {
lp->ptr = phys_map_node_alloc(map, level == 0);
}
p = map->nodes[lp->ptr];
lp = &p[(*index >> (level * P_L2_BITS)) & (P_L2_SIZE - 1)];
while (*nb && lp < &p[P_L2_SIZE]) {
if ((*index & (step - 1)) == 0 && *nb >= step) {
lp->skip = 0;
/*顺便说下,最后在查找section的时候是通过lp->ptr作为索引找到sections数组中的某个section的*/
lp->ptr = leaf; //这里的leaf就是section保存在map->sections数组中的索引。最后一个页表的页表项就是sections数组中的索引。所以是leaf叶子。
*index += step;
*nb -= step;
} else {
phys_page_set_level(map, lp, index, nb, leaf, level - 1);
}
++lp;
}
}
以上代码如果不好理解,可以看下面的模拟代码,逻辑上模拟了上述流程:
// =====================================================================================
//
// Filename: qemu phyaddr section.c
//
// Description:
//
// Version: 1.0
// Created: 2020/07/29 20时18分30秒
// Revision: none
// Compiler: g++
// =====================================================================================
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <stdbool.h>
#include <string.h>
#define CAI ((uint32_t)~0)
#define MAX(a, b) (((a) > (b)) ? (a) : (b))
void printBits(size_t const size, void const * const ptr)
{
unsigned char *b = (unsigned char*) ptr;
unsigned char byte;
int i, j;
for (i=size-1;i>=0;i--)
{
for (j=7;j>=0;j--)
{
byte = (b[i] >> j) & 1;
printf("%u", byte);
}
}
puts("");
}
typedef void* gpointer;
typedef unsigned long gsize;
#define g_new0(struct_type, n_structs) _G_NEW (struct_type, n_structs, malloc0)
#define _G_NEW(struct_type, n_structs, func) ((struct_type *) g_##func##_n ((n_structs), sizeof (struct_type)))
#define g_renew(struct_type, mem, n_structs) _G_RENEW (struct_type, mem, n_structs, realloc)
#define _G_RENEW(struct_type, mem, n_structs, func) (struct_type *) g_##func##_n (mem, (n_structs), sizeof (struct_type))
/*
* https://fossies.org/linux/glib/glib/gmem.h
* https://fossies.org/linux/glib/glib/gmem.c
* */
gpointer g_realloc (gpointer mem,gsize n_bytes);
gpointer g_realloc_n (gpointer mem, gsize n_blocks, gsize n_block_bytes)
{
return g_realloc (mem, n_blocks * n_block_bytes);
}
gpointer g_realloc (gpointer mem,gsize n_bytes)
{
gpointer newmem;
newmem = realloc (mem, n_bytes);
return newmem;
}
gpointer g_malloc0(gsize n_bytes)
{
gpointer mem;
mem = calloc (1, n_bytes);
return mem;
}
gpointer g_malloc0_n (gsize n_blocks,gsize n_block_bytes)
{
return g_malloc0 (n_blocks * n_block_bytes);
}
/***********************************************/
#define P_L2_BITS 9
#define P_L2_SIZE (1 << P_L2_BITS) //512
#define PHYS_SECTION_UNASSIGNED 0
#define PHYS_MAP_NODE_NIL (((uint32_t)~0) >> 6)
#define ADDR_SPACE_BITS 64
#define TARGET_PAGE_BITS 12
#define P_L2_LEVELS (((ADDR_SPACE_BITS - TARGET_PAGE_BITS - 1) / P_L2_BITS) + 1)
/*
#define g_renew(struct_type, mem, n_structs) _G_RENEW (struct_type, mem, n_structs, realloc)
#define _G_RENEW(struct_type, mem, n_structs, func) \
((struct_type *) g_##func##_n (mem, (n_structs), sizeof (struct_type)))
*/
typedef uint64_t hwaddr;
typedef struct PhysPageEntry PhysPageEntry;
struct PhysPageEntry {
uint32_t skip : 6;
uint32_t ptr : 26;
};
typedef PhysPageEntry Node[P_L2_SIZE];
typedef struct PhysPageMap {
// struct rcu_head rcu;
unsigned sections_nb;
unsigned sections_nb_alloc;
unsigned nodes_nb;
unsigned nodes_nb_alloc;
Node *nodes;
// MemoryRegionSection *sections;
} PhysPageMap;
typedef struct AddressSpaceDispatch {
PhysPageEntry phys_map;
PhysPageMap map;
}AddressSpaceDispatch;
static void phys_map_node_reserve(PhysPageMap *map, unsigned nodes)
{
printf("Numbers of nodes: %u\n", nodes);
printf("(1)Numbers of map->nodes_nb_alloc: %u\n", map->nodes_nb_alloc);
printf("Numbers of map->nodes_nb: %u\n", map->nodes_nb);
static unsigned alloc_hint = 16;
if(map->nodes_nb+nodes > map->nodes_nb_alloc) {
map->nodes_nb_alloc = MAX(map->nodes_nb_alloc, alloc_hint);
map->nodes_nb_alloc = MAX(map->nodes_nb_alloc, map->nodes_nb + nodes);
printf("(2)Numbers of map->nodes_nb_alloc: %u\n", map->nodes_nb_alloc);
// map->nodes = (Node*)realloc(map->nodes, map->nodes_nb_alloc*sizeof(Node));
map->nodes = g_renew(Node, map->nodes, map->nodes_nb_alloc);
}
}
static uint32_t phys_map_node_alloc(PhysPageMap *map, bool leaf)
{
unsigned i;
uint32_t ret;
PhysPageEntry e, *p;
ret = map->nodes_nb++;
p = map->nodes[ret];
e.skip = leaf ? 0 : 1;
e.ptr = leaf ? PHYS_SECTION_UNASSIGNED : PHYS_MAP_NODE_NIL;
int length = P_L2_SIZE;
for (i = 0; i < P_L2_SIZE; ++i)
{
memcpy(&p[i], &e, sizeof(e));
}
return ret;
}
static void phys_page_set_level(PhysPageMap *map, PhysPageEntry *lp,
hwaddr *index, hwaddr *nb, uint16_t leaf, int level)
{
PhysPageEntry *p;
hwaddr step = (hwaddr)1 << (level * P_L2_BITS);
if (lp->skip && lp->ptr == PHYS_MAP_NODE_NIL)
{
lp->ptr = phys_map_node_alloc(map, level == 0);
}
p = map->nodes[lp->ptr];
lp = &p[(*index >> (level * P_L2_BITS)) & (P_L2_SIZE - 1)];
while (*nb && lp < &p[P_L2_SIZE])
{
if ((*index & (step - 1)) == 0 && *nb >= step) {
lp->skip = 0;
lp->ptr = leaf;
*index += step;
*nb -= step;
}else {
phys_page_set_level(map, lp, index, nb, leaf, level - 1);
}
++lp;
}
}
int main()
{
AddressSpaceDispatch *d = g_new0(AddressSpaceDispatch, 1);
d->phys_map = (PhysPageEntry) { .ptr = PHYS_MAP_NODE_NIL, .skip = 1 };
//PhysPageMap *map = NULL;
/*g_new0 is equal calloc()*/
//map = (struct PhysPageMap*)calloc(1 ,sizeof(struct PhysPageMap));
//map = g_new0(PhysPageMap ,1);
phys_map_node_reserve(&d->map, 3 * P_L2_LEVELS);
hwaddr start_addr = 65535;
hwaddr index = start_addr >> TARGET_PAGE_BITS;
printf("page number index: %llu\n", index);
uint64_t num_pages = 512;
uint16_t section_index = 0;
uint16_t leaf = section_index;
phys_page_set_level(&d->map, &d->phys_map,&index, &num_pages, leaf, P_L2_LEVELS - 1 );
return 0;
}
int main_test(int argv, char* argc[])
{
int i = PHYS_MAP_NODE_NIL;
// printBits(sizeof(i), &i);
printf("%d\n", P_L2_SIZE);
int level = 5;
int r = level * P_L2_BITS & (P_L2_SIZE - 1);
printf("%d\n",r );
return 0;
}
https://www.anquanke.com/post/id/86412
https://blog.csdn.net/woai110120130/article/details/102312695
https://richardweiyang-2.gitbook.io/understanding_qemu/00-as/04-flatview

