centos7部署elasticsearch-7.16.2分布式集群(此版本修复了log4j2漏洞)
简介
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
Elasticsearch 7.x 包里自包含了 OpenJDK 的包。如果你想要使用你自己配置好的 Java 版本,需要设置 JAVA_HOME 环境变量 —— 参考
官方文档 Set up Elasticsearch 有各个 OS 的安装指导,页面 Installing Elasticsearch 中提供了多种安装包对应的指导链接!
本文选择绿色安装包的的方式(tar.gz)安装。
也可以使用yum安装jdk1.8.0版本
yum -y install epel-release #安装第三方yum源仓库
yum -y install java-1.8.0-openjdk #安装java1.8
开始安装ES
不能使用 root 用户启动 es,否则会报错:
Caused by: java.lang.RuntimeException: can not run elasticsearch as root
如果需要新建用户的话可以运行 sudo adduser es,修改 es 用户的密码:sudo passwd es
在本文中我使用的创建的es账号来做验证
环境
| 192.168.113.129 | node-1 | master |
| 192.168.113.130 | node-2 | data |
| 192.168.113.131 | node-3 | data |
下载ES官方二进制包
官方网站https://www.elastic.co/cn/downloads/elasticsearch
下载ES官方包
su es #进入es账号
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.16.2-linux-x86_64.tar.gz
tar -xf elasticsearch-7.16.2-linux-x86_64.tar.gz
mv elasticsearch-7.16.2 elasticsearch
cd elasticsearch注意openfile文件数需要修改为65535
ulimit -n #查看目前文件打开数最大限制
ulimit -n 65535 #临时修改最大限制
vi /etc/security/limits.conf #修改永久生效配置,添加下面内容重启生效
* soft nofile 65535
* hard nofile 65535
vim /etc/sysctl.conf #修改系统最大句柄数,添加如下内容,不然启动会失败
vm.max_map_count = 262144
/sbin/sysctl -p #加载生效ES相关配置
三个配置文件
配置文件主要位于
$ES_HOME/config目录下,也可以通过ES_PATH_CONF环境变量来修改
JAVA配置
$ES_HOME/config/jvm.options当通过tarorzip包安装/etc/elasticsearch/jvm.options当通过 Debian or RPM packages
官网也介绍了如何设置堆大小。
默认情况,ES 告诉 JVM 使用一个最小和最大都为 1GB 的堆。但是到了生产环境,这个配置就比较重要了,确保 ES 有足够堆空间可用。
ES 使用 Xms(minimum heap size) 和 Xmx(maxmimum heap size) 设置堆大小。你应该将这两个值设为同样的大小。
Xms 和 Xmx 不能大于你物理机内存的 50%。
设置的示例:
-Xms2g
-Xmx2gelasticsearch.yml 配置#
ES 默认会加载位于 $ES_HOME/config/elasticsearch.yml 的配置文件。
备注:任何能够通过配置文件设置的内容,都可以通过命令行使用 -E 的语法进行指定,例如:
./bin/elasticsearch -d -Ecluster.name=my_cluster -Enode.name=node_1cluster.name#
cluster.name 设置集群名称。一个节点只能加入一个集群中,默认的集群名称是 elasticsearch。
同一集群中的节点名称不能相同
network.host#
network.host:设置访问的地址。默认仅绑定在回环地址 127.0.0.1 和 [::1]。如果需要从其他服务器上访问以及多态机器搭建集群,我们需要设定 ES 运行绑定的 Host,节点需要绑定非回环的地址。建议设置为主机的公网 IP 或 0.0.0.0:
network.host: 0.0.0.0更多的网络设置可以阅读 Network Settings
http.port#
http.port 默认端口是 9200 :
http.port: 9200{% note warning %}
注意:这是指 http 端口,如果采用 REST API 对接 ES,那么就是采用的 http 协议
{% endnote%}
transport.port#
REST 客户端通过 HTTP 将请求发送到您的 Elasticsearch 集群,但是接收到客户端请求的节点不能总是单独处理它,通常必须将其传递给其他节点以进行进一步处理。它使用传输网络层(transport networking layer)执行此操作。传输层用于集群中节点之间的所有内部通信,与远程集群节点的所有通信,以及 Elasticsearch Java API 中的 TransportClient。
transport.port 绑定端口范围。默认为 9300-9400
transport.port: 9300因为要在一台机器上创建是三个 ES 实例,这里明确指定每个实例的端口。
discovery.seed_hosts#
discovery.seed_hosts:发现设置。有两种重要的发现和集群形成配置,以便集群中的节点能够彼此发现并且选择一个主节点。官网/Important discovery and cluster formation settings
discovery.seed_hosts 是组件集群时比较重要的配置,用于启动当前节点时,发现其他节点的初始列表。
开箱即用,无需任何网络配置, ES 将绑定到可用的环回地址,并将扫描本地端口 9300 - 9305,以尝试连接到同一服务器上运行的其他节点。 这无需任何配置即可提供自动群集的体验。
如果要与其他主机上的节点组成集群,则必须设置 discovery.seed_hosts,用来提供集群中的其他主机列表(它们是符合主机资格要求的master-eligible并且可能处于活动状态的且可达的,以便寻址发现过程)。此设置应该是群集中所有符合主机资格的节点的地址的列表。 每个地址可以是 IP 地址,也可以是通过 DNS 解析为一个或多个 IP 地址的主机名(hostname)。
当一个已经加入过集群的节点重启时,如果他无法与之前集群中的节点通信,很可能就会报这个错误
master not discovered or elected yet, an election requires at least 2 nodes with ids from。因此,我在一台服务器上模拟三个 ES 实例时,这个配置我明确指定了端口号。
配置集群的主机地址,配置之后集群的主机之间可以自动发现(可以带上端口,例如 127.0.0.1:9300):
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301"]the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
必须至少配置 [discovery.seed_hosts,discovery.seed_providers,cluster.initial_master_nodes] 中的一个。
cluster.initial_master_nodes#
cluster.initial_master_nodes: 初始的候选 master 节点列表。初始主节点应通过其 node.name 标识,默认为其主机名。确保 cluster.initial_master_nodes 中的值与 node.name 完全匹配。
首次启动全新的 ES 集群时,会出现一个集群引导/集群选举/cluster bootstrapping步骤,该步骤确定了在第一次选举中的符合主节点资格的节点集合。在开发模式下,如果没有进行发现设置,此步骤由节点本身自动执行。由于这种自动引导从本质上讲是不安全的,因此当您在生产模式下第一次启动全新的群集时,你必须显式列出符合资格的主节点。也就是说,需要使用 cluster.initial_master_nodes 设置来设置该主节点列表。重新启动集群或将新节点添加到现有集群时,你不应使用此设置
在新版 7.x 的 ES 中,对 ES 的集群发现系统做了调整,不再有
discovery.zen.minimum_master_nodes这个控制集群脑裂的配置,转而由集群自主控制,并且新版在启动一个新的集群的时候需要有cluster.initial_master_nodes初始化集群主节点列表。如果一个集群一旦形成,你不该再设置该配置项,应该移除它。该配置项仅仅是集群第一次创建时设置的!集群形成之后,这个配置也会被忽略的!
{% note warning %}cluster.initial_master_nodes 该配置项并不是需要每个节点设置保持一致,设置需谨慎,如果其中的主节点关闭了,可能会导致其他主节点也会关闭。因为一旦节点初始启动时设置了这个参数,它下次启动时还是会尝试和当初指定的主节点链接,当链接失败时,自己也会关闭!
因此,为了保证可用性,预备做主节点的节点不用每个上面都配置该配置项!保证有的主节点上就不设置该配置项,这样当有主节点故障时,还有可用的主节点不会一定要去寻找初始节点中的主节点!
{% endnote%}
关于 cluster.initial_master_nodes 可以查看如下资料:
其他#
集群的主要配置项上面已经介绍的差不多了,同时也给出了一些文档拓展阅读。实际的生产环境中,配置稍微会复杂点,下面补充一些配置项的介绍。需要说明的是,下面的一些配置即使不配置,ES 的集群也可以成功启动的。
- Elasticsearch 集群中节点角色的介绍 对上文中的
node.master等配置做了介绍。如果本地仅是简单测试使用,上文中的node.master/node.data/node.ingest不用配置也没影响。
创建集群#
实验机器有限,我们在同一台机器上创建三个 ES 实例来创建集群,分别明确指定了这些实例的 http.port 和 transport.port。discovery.seed_hosts明确指定实例的端口对测试集群的高可用性很关键。
如果后期有新节点加入,新节点的
discovery.seed_hosts没必要包含所有的节点,只要它里面包含集群中已有的节点信息,新节点就能发现整个集群了。
创建集群
分别在三台集群服务器上面修改配置文件 elasticsearch.yml
vim elasticsearch.yml
master节点配置
# es-7.16.2-node-1
cluster.name: hcwx
node.name: node-1
node.master: true
node.data: false
node.ingest: false #注意如果kibana需要添加检测堆锥需要将这个配置改为
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
discovery.seed_hosts: ["192.168.113.129:9300","192.168.113.130:9300","192.168.113.131:9300"]
cluster.initial_master_nodes: ["node-1"]slave1节点配置
# es-7.16.2-node-2
cluster.name: hcwx
node.name: node-2
node.master: true
node.data: true
node.ingest: false
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
discovery.seed_hosts: ["192.168.113.129:9300","192.168.113.130:9300","192.168.113.131:9300"]slave2节点配置
# es-7.16.2-node-3
cluster.name: hcwx
node.name: node-3
node.master: true
node.data: true
node.ingest: false
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
discovery.seed_hosts: ["192.168.113.129:9300","192.168.113.130:9300","192.168.113.131:9300"]分别启动ES服务
./bin/elasticsearch如果要将 ES 作为守护程序运行,请在命令行中指定 -d,指定 -p 参数,将进程 ID 记录到 pid 文件
./bin/elasticsearch -d -p pid如果要停止 ES,运行如下的命令
pkill -F pid 或者查找pid编号kill -p pid检查运行状态
curl -X GET "192.168.113.129:9200/?pretty"
{
"name" : "node-1",
"cluster_name" : "hcwx",
"cluster_uuid" : "8UU0zIp_Q2GocsYIc5HK0Q",
"version" : {
"number" : "7.16.2",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "83c34f456ae29d60e94d886e455e6a3409bba9ed",
"build_date" : "2021-10-07T21:56:19.031608185Z",
"build_snapshot" : false,
"lucene_version" : "8.9.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}查看集群状态
curl http://192.168.113.129:9200/_cat/nodes
192.168.113.129 57 40 0 0.18 0.21 0.15 lmr * node-1
192.168.113.130 64 60 2 0.17 0.13 0.08 cdfhlmrstw - node-2
192.168.113.131 10 62 1 0.34 1.23 0.86 cdfhlmrstw - node-3http://192.168.113.129:9200/_nodes 将会显示节点更多的详情信息
web页面head插件安装也可以安装elasticsearch-kopf插件
修改master节点配置
修改elasticsearch.yml文件,增加如下内容:然后重启es服务
http.cors.enabled: true
http.cors.allow-origin: "*"(1)github下载:https://github.com/mobz/elasticsearch-head,解压
(2)按照github文档,需要先安装npm
在有外网或者本地仓库源的可以使用第三方源yum安装npm,没外网的使用二进制包
yum -y install npm*注:(JavaScript中的npm:相当于python中的pip、java中的maven)
①下载并解压node-v14.6.0-linux-x64(wget https://nodejs.org/download/release/v14.6.0/node-v14.6.0-linux-x64.tar.gz)
②cd进bin目录,测试./node –v
③创建软连接 ln –s ‘源文件node位置’/usr/local/bin/node
ln –s ‘源文件npm位置’/usr/local/bin/npm
在有外网或者npm仓库使用这个方法
因为/usr/local/bin是环境变量PATH的内容,所以建立软连接后可以直接使用node命令
(3)使用npm安装elasticsearch-head
①cd到elasticsearch-head目录下
配置依赖
cd /opt
wget https://npm.taobao.org/mirrors/phantomjs/phantomjs-2.1.1-linux-x86_64.tar.bz2
vim /etc/profile
export PATH=$PATH:/opt/phantomjs-2.1.1-linux-x86_64/bin
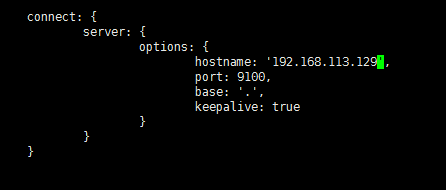
sour /etc/profile修改启动配置文件在端口上一行添加hostname
②#npm install
③#npm run start
④默认在localhost:9100端口启动
⑤打开原安装的elasticsearch.yml配置文件,再修改一下elasticsearch的服务安全策略,使得elasticsearch-head插件与elasticsearch服务连接,如下

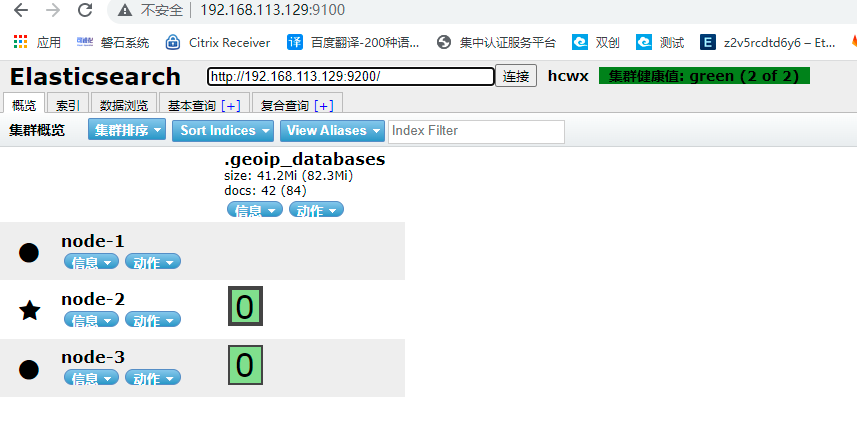
5.访问http://ip:9100 ,进入显示如下:
安装elasticsearch-analysis-ik 7.16.2分词器插件
1.ik分词器是基于Elasticsearch的,所以Elasticsearch必须是已经安装好,并且能使用的状态,另外最好也安装好了Elasticsearch Head插件。
2.进入Elasticsearch的根目录下的plugins
3.新建目录ik
4.执行下载ik软件
5.解压缩ik软件
执行命令--->mkdir -p /home/es/plugins/ik
执行命令--->wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.16.2/elasticsearch-analysis-ik-7.16.2.zip
执行命令--->unzip elasticsearch-analysis-ik-7.16.2.zip
6.重启Elasticsearch
7.测试分词器是否好用
7-1.打开postman工具。
7-2.使用POST请求http://192.168.113.129:9200/_analyze (0.47:9200是我的es服务器,_analyze是函数名)
7-3.请求体内raw写json格式的内容,如下:{"analyzer": "ik_max_word","text": "我的偶像是刘德华"}
6、ES添加用户密码安全认证
简介:有需要配置授权安全认证的可以继续往下配置,
背景: ES集群原先没设置密码,存在数据泄露,被篡改风险。
1、集群设置证书
启用了x-pack模块,那么集群中的各节点之间通讯就必须安全认证。为了解决节点间通讯的认证问,我们需要制作证书。
不然直接生成密码的话, 会报Cause: Cluster state has not been recovered yet, cannot write to the [null]index
执行下面的操作用于生成elastic-certificates.p12 文件,文件将自动生成在cd /opt/elasticsearch下面
cd /opt/elasticsearch/bin
./elasticsearch-certutil cert
2、elasticsearch.yml配置文件添加下面认证 配置(每个节点都需要添加)
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: certs/elastic-certificates.p12分别在每台es节点的conf目录下面创建目录certs目录
cd /opt/elasticsearch/config
mkdir certs拷贝这个ca文件到每个节点的certs目录下面
scp elastic-certificates.p12 到每个节点的certs目录
mv elastic-certificates.p12 config/certs/上面的配置好后重启ES
Elasticsearch 有两个级别的通信,传输通信和 http 通信。 传输协议用于 Elasticsearch 节点之间的内部通信,http 协议用于客户端到 Elasticsearch 集群的通信。
个人认为上面只设置了内部传输协议直接的证书,所以只用cert生成 ,没有ca生成。
elasticsearch.yml设置里面也只设置了 xpack.security.transport.ssl, 没有设置xpack.security.http.ssl...
开始设置密码:
在ES集群的任意一个节点的bin目录下面执行来自动生成密码,把生成的密码跟账号记录下来
./elasticsearch-setup-passwords interactive #自定义账号密码方式
./elasticsearch-setup-passwords auto #自动生成账号密码 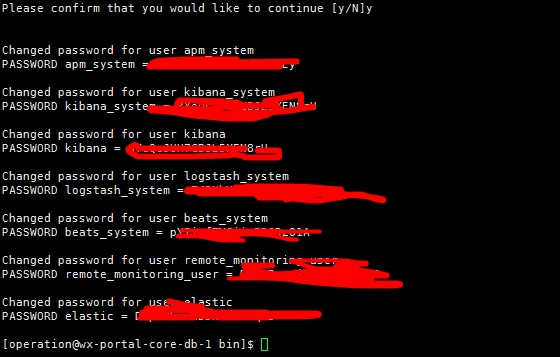
存储密码可能需要elasticsearch.keystore
用./elasticsearch-keystore create来生成
生成好后配置到kibana等需要集成ES的组件里面。
kibana上可以自定义设置角色和用户。设置只读用户read,写入用户write
后续可以用这些用户来操作ES了,
如
curl -XGET "http://localhost:9200/_search" -H 'Content-Type: application/json' -d'{"query": {"match_all": {}}}' -u read:read1234
curl -XPOST 'http://localhost:9200/teacher/_doc' -u apm_system:apm1234 -d '{"name":"lihua1","age":13}' -H 'Content-Type:application/json; charset=UTF-8'修改账号密码的操作方法,这里用elastic管理账号做示范
curl -XPOST -u elastic "127.0.0.1:9200/_security/user/elastic/_password" -H 'Content-Type: application/json' -d'{"password" : "elastic123456"}'
#elastic123456是新密码
#在执行上面的curl后输入原始密码将账号加入到超级管理员角色
curl -XPOST -H 'Content-type: application/json' -u elastic:当前超级管理员账号密码 'http://127.0.0.1:9200/_xpack/security/user/dbtest(需要加权限的账号)?pretty' -d '{"password":"dbtest账号密码","full_name":"dbscan","roles":["superuser"]}'配置了密码认证后访问head插件需要这样访问
es-head连接地址:http://192.168.113.129:9100/?auth_user=elastic&auth_password=密码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号