
部署及配置Mycat数据库中间件
Mycat关键特性
关键特性
支持SQL92标准支持MySQL、Oracle、DB2、SQL Server、PostgreSQL等DB的常见SQL语法遵守Mysql原生协议,跨语言,跨平台,跨数据库的通用中间件代理。基于心跳的自动故障切换,支持读写分离,支持MySQL主从,以及galera cluster集群。支持Galera for MySQL集群,Percona Cluster或者MariaDB cluster基于Nio实现,有效管理线程,解决高并发问题。支持数据的多片自动路由与聚合,支持sum,count,max等常用的聚合函数,支持跨库分页。支持单库内部任意join,支持跨库2表join,甚至基于caltlet的多表join。支持通过全局表,ER关系的分片策略,实现了高效的多表join查询。支持多租户方案。支持分布式事务(弱xa)。支持XA分布式事务(1.6.5)。支持全局序列号,解决分布式下的主键生成问题。分片规则丰富,插件化开发,易于扩展。强大的web,命令行监控。支持前端作为MySQL通用代理,后端JDBC方式支持Oracle、DB2、SQL Server 、 mongodb 、巨杉。支持密码加密支持服务降级支持IP白名单支持SQL黑名单、sql注入攻击拦截支持prepare预编译指令(1.6)支持非堆内存(Direct Memory)聚合计算(1.6)支持PostgreSQL的native协议(1.6)支持mysql和oracle存储过程,out参数、多结果集返回(1.6)支持zookeeper协调主从切换、zk序列、配置zk化(1.6)支持库内分表(1.6)集群基于ZooKeeper管理,在线升级,扩容,智能优化,大数据处理(2.0开发版)。
什么是MYCAT
一个彻底开源的,面向企业应用开发的大数据库集群支持事务、ACID、可以替代MySQL的加强版数据库一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品一个新颖的数据库中间件产品
MYCAT监控
支持对Mycat、Mysql性能监控支持对Mycat的JVM内存提供监控服务支持对线程的监控支持对操作系统的CPU、内存、磁盘、网络的监控
1. mycat是怎样实现分库分表的?
mycat里面通过定义路由规则来实现分片表(路由规则里面会定义分片字段,以及分片算法)。分片算法有多种,你所说的hash是其中一种,还有取模、按范围分片等等。在mycat里面,会对所有传递的sql语句做路由处理(路由处理的依据就是表是否分片,如果分片,那么需要依据分片字段和对应的分片算法来判断sql应该传递到哪一个、或者哪几个、又或者全部节点去执行)
2. mycat适用于哪些场景?相对于海量存储的Nosql的适用场景又如何?
数据量大到单机hold不住,而又不希望调整架构切换为NoSQL数据库,这个场景下可以考虑适用mycat。当然,使用前也应该做规划,哪些表需要分片等等。另外mycat对跨库join的支持不是很好,在使用mycat的时候要注意规避这种场景。
1,安装jdk
yum -y install java-1.8.0-openjdk*
2,安装数据库
mysql的主从复制部署方法参考mysql5.7主从复制部署 方法
3,部署Mycat
mycat下载官方网站http://www.mycat.org.cn/
cd /opt
curl -O http://dl.mycat.org.cn/1.6.7.6/20211118155357/Mycat-server-1.6.7.6-release-20211118155357-linux.tar.gz
tar xf Mycat-server-1.6.7.6-release-20211118155357-linux.tar.gz4,配置mycat设置后端数据库连接配置,并实现读写分离
vim /opt/mycat/conf/schema.xml
#现目前修改配置段
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="confluence" checkSQLschema="false" sqlMaxLimit="100" dataNode="confluence"> </schema>
<schema name="test_dy" checkSQLschema="false" sqlMaxLimit="100" dataNode="test_dy"> </schema>
<dataNode name="confluence" dataHost="dh_43" database="confluence" />
<dataNode name="test_dy" dataHost="dh_43" database="test_dy" />
<dataHost name="dh_43" maxCon="10000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<readHost host="45_S1" url="192.168.113.130:3306" user="root" password="123456" />
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>schema name="confluence" 逻辑库库名
dataNode="confluence" 命名后端库名
dataHost="dh_43" 逻辑数据库主机用于下面配置连接等,需要不通配置添加对于应的dataHost配置
database="confluence" 真实库名
writeHost host="43_M" 后端写数据库服务器,43_M是逻辑命名
readHost host="45_S1" 后端读数据库服务器,45_S1是逻辑命名
5,修改配置文件server.xml用户认证配置文件
这里我使用的是主从复制之间创建好两个库confluence和test_dy库做测试验证
vim /opt/mycat/conf/server.xml
#目前只需要修改这两个位置
<user name="root" defaultAccount="true"> #逻辑账号连接mycat时候使用
<property name="password">123456</property>
<property name="schemas">confluence,test_dy</property> #逻辑库名多库逗号隔开,对应schema.xml里面的配置逻辑库名
<property name="defaultSchema">confluence,test_dy</property>
</user>
<user name="user"> #配置逻辑账号只读用户
<property name="password">user</property>
<property name="schemas">confluence,test_dy</property>
<property name="readOnly">true</property> #只读
<property name="defaultSchema">confluence,test_dy</property>
</user>6,启动Mycat并测试验证
sh /opt/mycat/bin/mycat restart
netstat -lntp #查看默认配置的端口8066是否正常启用
mysql -h 192.168.113.131 -uroot -p -P8066 #登录验证,注意防火墙
#连接登录后修改数据查看看数据是否正常7,Mycat调优
Conf/log4j.xml
Conf/log4j.xml中,日志级别调整为至少info级别,默认是debug级别,用于排查错误,不能用于性能测试和正式生产中。
conf/server.xml
conf/server.xml中 有如下参数可以调整:
<system>
<!-- CPU核心数越多,可以越大,当发现系统CPU压力很小的情况下,可以适当调大此参数,如4核心的4CPU,可以设置为16,24核心的可以最大设置为128 -->
<property name="processors">1</property>
<!-- 下面这个参数为每个processor的线程池大小,建议可以是16-64,根据系统能力来测试和确定。-->
<property name="processorExecutor">16</property>
</system>
System中以下重要参数也根据情况进行调整
processorBufferPool :每个processor分配的Socket Direct Buffer,用于网络通信,每个processor上管理的所有连接共享,processorBufferChunk为Pool的最小分配单元,每个POOL的容量即为processorBufferPool/processorBufferChunk,默认前者为1024 * 1024 * 16=16M,后者为4096字节。processorBufferPool参数的调整,需要观察show @@processor的结果来确定:
BU_PERCENT为已使用的百分比、BU_WARNS为Socket Buffer Pool不够时,临时创新的新的BUFFER的次数,若百分比经常超过90%并且BU_WARNS>0,则表明BUFFER不够,需要增大processorBufferPool。基本上,连接数越多,并发越高,需要的POOL越大,建议BU_PERCENT最大在40-80%之间。
conf/schema.xml
conf/schema.xml中有如下参数可以调整:
<schema name="TESTDB" checkSQLschema="true">,checkSQLschema属性建议设置为false,要求开发中,不能在sql中添加数据库的名称,如select * from TESTDB.company,这样可以优化SQL解析。
<dataHost name="localhost1" maxCon="500" minCon="10" balance="0"
dbType="mysql" dbDriver="native" banlance="0">
最大连接池maxCon,可以改为1000至2000,同一个Mysql实例上的所有datanode节点的共享本dataHost 上的所有物理连接
性能测试的时候,建议minCon=maxCon= mysql max_connections设为2000左右。
另外,读写分离是否开启,根据环境的配置来决定。
缓存优化调整:
Show @@cache命令展示了缓存的使用情况,经常观察其结果,需要时候进行调整:
一般来说:若CUR接近MAX,而PUT大于MAX很多,则表明MAX需要增大,HIT/ACCESS为缓存命中率,这个值越高越好。重新调整缓存的最大值以后,观测指标都会跟随变化,调整是否有效,主要观察缓存命中率是否在提升,PUT则下降。
目前缓存服务的配置文件为:cacheservice.properties,主要使用的缓存为enhache,enhache.xml里面设定了enhance缓存的全局属性,下面定义了几个缓存:
#used for mycat cache service conf
factory.encache=org.opencloudb.cache.impl.EnchachePooFactory
#key is pool name ,value is type,max size, expire seconds
pool.SQLRouteCache=encache,10000,1800
pool.ER_SQL2PARENTID=encache,1000,1800
layedpool.TableID2DataNodeCache=encache,10000,18000
layedpool.TableID2DataNodeCache.TESTDB_ORDERS=50000,18000
SQLRouteCache为SQL 解析和路由选择的缓存,这个大小基本相对固定,就是所有SELECT语句的数量。
ER_SQL2PARENTID为ER分片时候,根据关联SQL查询父表的节点时候用到,没有用到ER分片的,这个缓存用不到
TableID2DataNodeCache,当某个表的分片字段不是主键时,缓存主键到分片ID的关系,这个是二层的缓存,每个表定义一个子缓存,如”TEST_ORDERS”,这里命名为schema_tableName(tablename要大写),当有很多的根据主键查询SQL时,这个缓存往往需要设置比较大,才能更好的提升性能。
Mycat大数据量查询调优
1.返回结果比较多
建议调整 frontWriteQueueSize 在系统许可的情况下加大,默认值*3
这个原因是因为返回数据太多
这里做了一个改进,就是超过POOL以后,仍然创建临时的BUFFER供使用,但这些不回收。。
这样的情况下,需要增加BUFFER参数
调整 processorBufferPool = 默认值*2
不够的情况下,继续加大。
8,mycat 分库配置案例,配置两个不同的数据库写
修改schema.xml文件
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="test_dy" checkSQLschema="false" sqlMaxLimit="100" dataNode = 'test_dy'> </schema>
<schema name="confluence" checkSQLschema="false" sqlMaxLimit="100" dataNode = 'confluence'> </schema>
<dataNode name="test_dy" dataHost="dh_43" database="test_dy" />
<dataNode name="confluence" dataHost="dh_44" database="confluence" />
<dataHost name="dh_43" maxCon="10000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="43_M" url="192.168.113.129:3306" user="root"
password="123456">
<!-- can have multi read hosts -->
<readHost host="45_S1" url="192.168.113.130:3306" user="root" password="123456" />
</writeHost>
</dataHost>
<dataHost name="dh_44" maxCon="10000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="44_N" url="192.168.113.131:3306" user="root"
password="123456">
</writeHost>
</dataHost>
</mycat:schema>9.mycat分片案例
这里案例使用的是取表的id字段算法案例
[root@localhost conf]# vim rule.xml #修改分片规则
<tableRule name="jch">
<rule>
<columns>id</columns> #以字段id取模
<algorithm>mod-long</algorithm> #对应下面的算法规则名
</rule>
</tableRule>
#对应的算法
<function name="mod-long" class="io.mycat.route.function.PartitionByMod"> #分片规则
<!-- how many data nodes -->
<property name="count">2</property> #设置两个分片
</function>
修改分片规则配置
[root@localhost conf]# vim schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="test_dy" checkSQLschema="false" sqlMaxLimit="100">
<table name="employee" primaryKey="id" dataNode="test_dy1,test_dy2" rule="jch"/> #实际分片的表
<table name="t_user" primaryKey="id" dataNode="test_dy1,test_dy2" rule="jch"/>
</schema>
<dataNode name="test_dy1" dataHost="dh_43" database="test_dy" /> #两台分片主机对应同一个真实的库
<dataNode name="test_dy2" dataHost="dh_44" database="test_dy" />
<dataHost name="dh_43" maxCon="10000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="43_M" url="192.168.113.129:3306" user="root"
password="123456">
<!-- can have multi read hosts -->
<readHost host="45_S1" url="192.168.113.130:3306" user="root" password="123456" />
</writeHost>
</dataHost>
<dataHost name="dh_44" maxCon="10000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="44_N" url="192.168.113.131:3306" user="root"
password="123456">
</writeHost>
</dataHost>
</mycat:schema>
修改server.xml 的mycat访问配置
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">test_dy</property>
<property name="defaultSchema">test_dy</property>
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">test_dy</property>
<property name="readOnly">true</property>
<property name="defaultSchema">test_dy</property>
</user>
创建库并插入数据测试验证
mysql> CREATE TABLE IF NOT EXISTS `t_user` (`id` bigint(20) NOT NULL COMMENT 'id',`name` varchar(50) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL COMMENT '名字',`age` int(11) DEFAULT NULL COMMENT '年龄',`address` varchar(255) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL COMMENT '地址',PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=latin1 COMMENT='用户表';INSERT INTO `test_dy`.`t_user` (`id`, `name`, `age`, `address`) VALUES (1, 'wang', 16, '6')
INSERT INTO `test_dy`.`t_user` (`id`, `name`, `age`, `address`) VALUES (2, 'zhang', 17, '5')
INSERT INTO `test_dy`.`t_user` (`id`, `name`, `age`, `address`) VALUES (3, 'liu', 18, '4')
INSERT INTO `test_dy`.`t_user` (`id`, `name`, `age`, `address`) VALUES (4, 'li', 19, '3')
INSERT INTO `test_dy`.`t_user` (`id`, `name`, `age`, `address`) VALUES (5, 'hai', 15, '2')
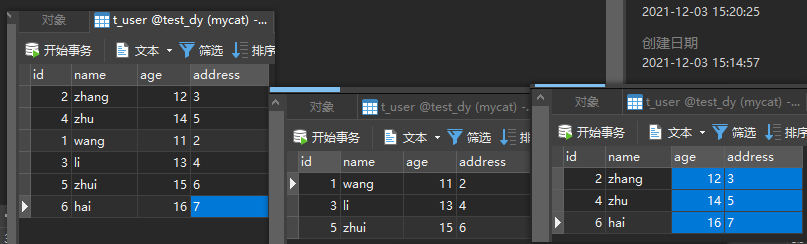
INSERT INTO `test_dy`.`t_user` (`id`, `name`, `age`, `address`) VALUES (6, 'jie', 14, '1')分别查看mycat跟两台分片数据库的分片表数据
定义的两个分片的规则所以分片库的id以奇数偶数进行划分
mycat分片的十四种算法mycat算法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号