

深度学习:损失函数
神经网络以某个指标为线索寻找最优权重参数。神经网络学习中所用的指标称为损失函数(loss function)。这个损失函数可以使用任意函数,但一般用均方误差和交叉熵误差等。
1、均方误差
可有作为损失函数的函数有很多,但其中最有名的是均方误差(mean squared)。
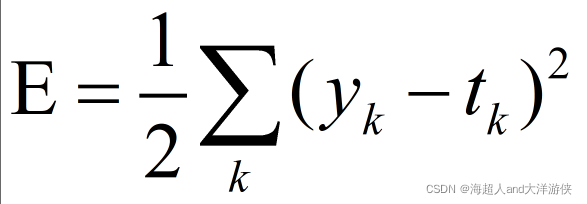
这里yk表示神经网络的输出,tk表示监督数据(训练数据),k表示数据的维数。
实现代码
def mean_squared_error(y,t): return 0.5 * np.sum((y - t)**2)
2、交叉熵误差
![]()
log表示以e为底数的自然对数。yk是神经网络的输出,tk是正确解标签。并且,tk中只有正确解标签的索引为1,其他均为0。当对应解标签的输出较小,则交叉熵误差越大。
def cross_entropy_error(y,t): delta = 1e-7 return -np.sum(t * np.log(y+delta))
这里加上一个微小值delta防治出现当np.log(0)的情况出现无穷大的值的情况。
3、mini-batch学习
前面两个都是针对单个数据的损失函数。如果要求所有训练数据的损失函数的总和,以交叉熵误差为例,可以写成下面的式子。
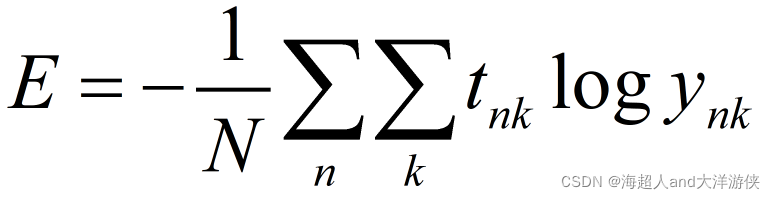
假设数据有N个,tnk表示第n个数据的第k个元素的值。
神经网络的学习是从训练数据中选出一批数据(称为mini-batch),然后对每个mini_batch进行学习。这种学习方式称为mini-batch学习。
mini-batch用随机选择的小批量数据作为全体训练数据的近似值。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?