L02_机器学习任务攻略
目录
Framework of ML
训练模型的过程分为三个步骤:
- 写出一个具有未知数的,,表示模型中的所有的未知参数。
- 定义损失函数,函数的输入就是一组参数,用来判断这一组参数的好坏。
- 进行最优化,寻找让损失函数最小的参数
怎样将模型训练的更好
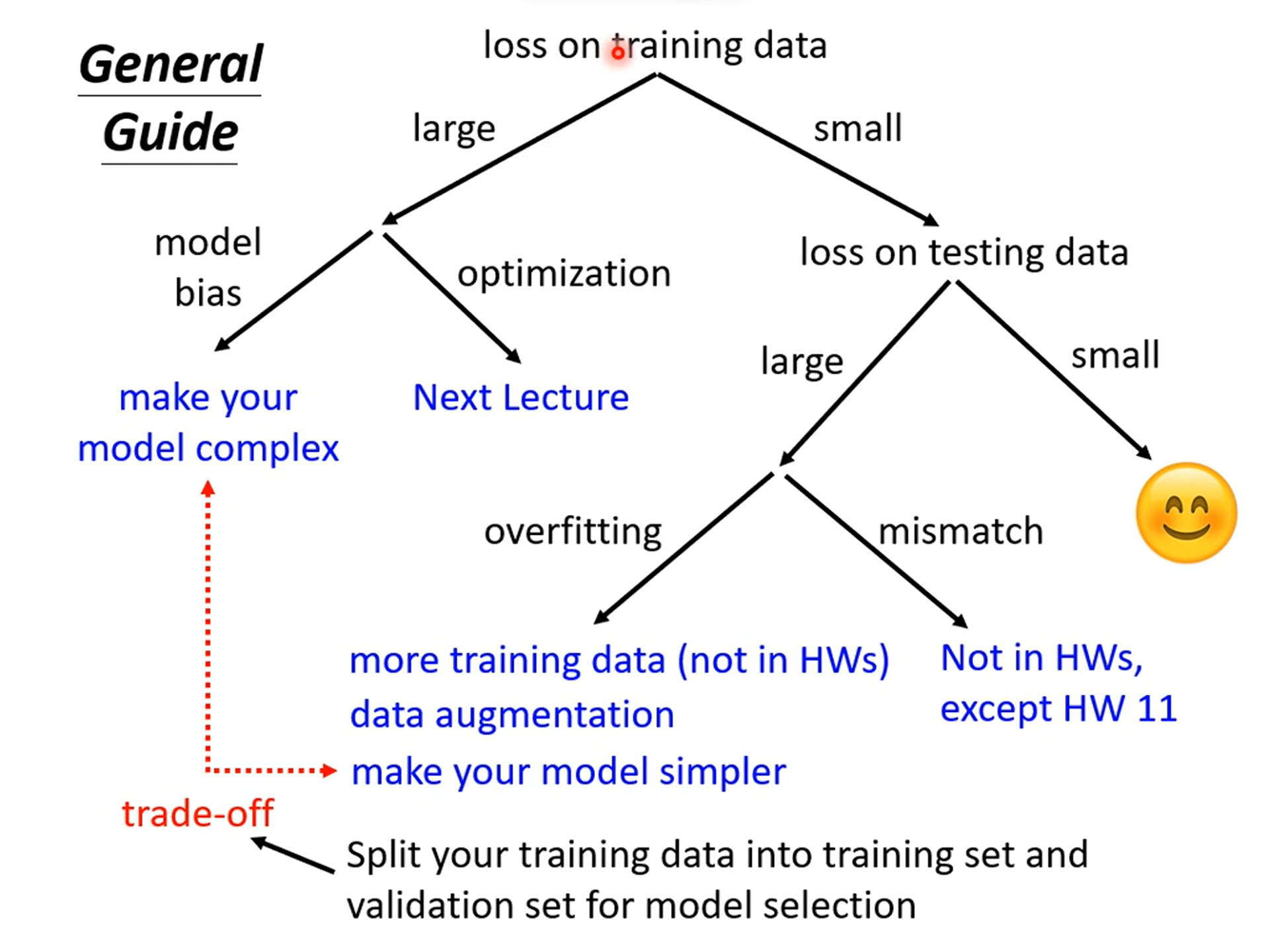
情况一:在训练数据集的Loss比较大
1. 模型过于简单,相当于在大海捞针,但是针不在大海中。
解决方法:增加模型的弹性。
-
增加输入的;
-
使用深度学习,使用更多的neurons和layers。
-
Optimization Issue,最优化做的不够好,虽然存在最优的,但是设计的最优化方法并不能找到,相当于针在海里,但是无法找到。
解决方法:使用更加强大的优化技术。
2. 怎么判断是哪一个问题呢?
通过比较不同的模型,来得知自己的model够不够大。
- 从一个弹性比较小的神经网络(或者其他模型)出发,因为这些模型比较容易进行最优化,一般不会出现失败的情况。
- 然后设计一个更深的神经网络,如果更深的弹性更大的神经网络还没有弹性较小的神经网络得到的Loss小,那就说明是Optimization Issue。
情况二:在训练集的Loss较小,但是在测试集的比较大
Overfitting
举例说明原因
举一个比较极端的例子:
这个函数在训练集上的Loss为0,但是在测试集上的Loss比较大。
另一个比较可能的原因是训练资料太少,出现了类似于插值函数中的龙格现象的问题。
解决方法:
-
对训练数据集进行修改。
-
增加训练数据的量;
-
进行
Data augmentation,对原有的数据进行合理的修改;
-
-
对模型进行修改,选择弹性较小的模型,给自己的模型进行限制(不能给出太大的限制)。
- 使用更少的参数,共享相同的参数
- 使用更少的features
- Early stopping
- Reguarization
- Dropout
分类:
李宏毅机器学习_学习笔记


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程