
Python 并行计算那点事(第2部分) -- 译文 [原创]
Python 并行计算的那点事(第2部分)(The Python Concurrency Story - Part 2)
英文原文:https://powerfulpython.com/blog/python-concurrency-story-pt2/
本文:https://www.cnblogs.com/popapa/p/python_concurrency2.html
采集日期:2021-05-03
第1部分已经讨论了Python并行计算编程的主要难点。简而言之,对于处理器受限(CPU-bound)的任务而言,Python的线程将会于事无补。那有什么其他办法吗?
概括起来,现实世界中需要面对的并行计算问题有两种:
- 多个CPU可以加速任务
- 再多的CPU也于事无补
本文将介绍第1种情况:可以由多CPU进行加速的任务。通过编写跨越多个进程的Python代码,即可达到目的。最理想的情况下,N个CPU将会让程序运行速度提高N倍。
(第2种情况将在第3部分中介绍,涉及非处理器受限的多任务所需应对的问题。那种情况下,多CPU或多核没什么大的用处。为了取得胜利,必须榨取单个线程的最大收益,最新版的Python中就提供了一些出色的工具。)
并发编程的两种途径(Two Approaches to Concurrent Programming)
就Python而言,好程序员与杰出程序员有一点差别,那就是对现代操作系统提供的并发原语(Concurrency Primitive)的理解程度,包括进程和线程,以及他们的各种使用模式。其实这与编程语言无关。正规的学校教育,或者用其他语言实现并发程序时的经验,都可能让您有所了解。
概括起来,并行计算的实现主要有两种途径:共享内存(Shared Memory)和消息传递(Message Passing)。这两者的主要区别在于:共享内存意味着程序的设计目标是要让两个以上的线程读写同一块内存——就像跳舞时不会相互踩脚。而采用消息传递方式时,任何内存块都只能由单个线程访问。如果两个以上线程需要同步、交互或通信,要把数据从一个线程发送给另一个,也即传递一条消息。
两个线程可以位于同一个进程中,也可以在两个不同的进程中——每个进程都有自己的主线程。因此,共享内存或消息传递都可以用[注1]。但通常共享内存只会在单进程、多线程的系统中使用。多进程程序可以通过类似mmap的结构(Construct)或IPC来访问共享内存,但性能不佳且实现起来比较复杂。[注2]
如果可以避开的话,建议多进程程序不要采用共享内存。干成功的人都知道原因:要想做好很难,而微妙的竞态条件(Race Condition)、死锁和其他错误却很容易生成。有时或许无法避免共享内存的使用。但如果可以,请换成消息传递方式吧。
无论如何,消息传递方式都更适合多进程程序。原因有两个:首先,与单进程、多线程的程序相比,共享内存在多进程中的性能和优雅程度均不高。更重要的是,大部分想用多进程实现的程序都更适合采用消息传递的架构,尤其是在Python中。
编写Python多核应用(Writing Multicore Python)
Python基本上是强制要求用多进程来充分利用多个CPU。[注3]跨进程共享内存的方案有很多,而用较新版本的Python,实现起来相对容易一些。但这里重点还是介绍消息传递方法。
现在真的容易多了。从前如果想让Python善加利用多个CPU,必须使用os.fork进行一些惊悚且不可移植的操作。而现在,标准库中就有了很好的multiprocessing模块。这是一个不错的Python风格(Pythonic)接口,用它处理多进程能让许多困难的事情变得简单[注4]。有关的文章相当多了,也带了很多漂亮、整洁的演示代码。但让我们看下更现实的实例如何?
下面介绍一下Thumper吧。这个Python程序将为数量庞大的图像库生成缩略图。假设某个Web应用程序每天凌晨2点都要抓取一批10万张的图片,且需要在合理的时间内为这些图片生成缩略图,那么用Thumper就正合适。这个案例利用多CPU实现十分理想:生成缩略图是处理器受限的任务,并且两张不同图片的计算过程是完全独立的。
看看漂亮的结果吧:
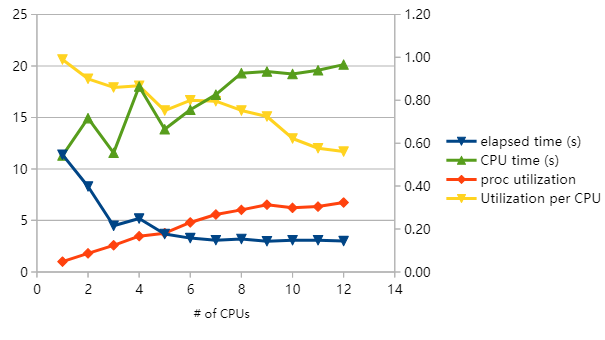
以上是在NASA TIFF图像数据集上多次运行thumper之后的结果,用的是AWS c3.2 xlarge主机实例。横坐标是工作进程的数量。
这张图中出现了一次LOT的情况。我正在研究高级Python精通课程,该课程将深入研究其中的内容,让我的学生获得蝙蝠侠般的并发编程超级能力。下面将重点关注Thumper的实现,以及它是如何绕开GIL用足CPU核心的。
核心代码非常简单,这多亏有了先进的Pillow,它是PIL(Python图像库)的分支代码。
# PIL is actually Pillow. Confusing, I know,
# but nicely backwards compatible.
from PIL import Image
def create_thumbnail(src_path, dest_path, thumbnail_width, thumbnail_height):
image = Image.open(src_path)
image.thumbnail((thumbnail_width, thumbnail_height))
os.makedirs(os.path.dirname(dest_path), exist_ok=True)
image.save(dest_path)
很直白吧。然后要将其推进为多个工作进程。以下是一些注意事项:
- 用多少个进程呢? 正如即将看到的那样,这是个惊人的难题,事实证明这是一个不断变化的值。因此,我们需要灵活性——在运行时指定进程数量的能力。
- 如何避免创建的流程太多或太少?
- 如何高效地等待一个工作进程的完成,然后立即把一张新图片交给它生成缩略图呢?
Python的multiprocessing池(Python's multiprocessing Pools)
multiprocessing模块包含了一个非常有用的抽象概念,并以Pool类的形式给出。如下即可创建它:
import multiprocessing
pool = multiprocessing.Pool(num_processes)
哇,有点难!单词“multiprocessing”的字符太多了,要打这么多字。谢天谢地,总算干完了,就只剩向每个工作进程分发图片了。Pool有好几个方法可供使用。每种方法的参数都是一个可调用的函数(Callable)及调用的参数,在这里将是create_thumbnail。
下面列出Pool的一部分方法:
apply_async
参数为一个函数及一些参数,将其送入*某个*工作进程中运行。结果对象会立即返回,有点像future,完成后可以马上获取返回值。
map和map_async
类似于Python内置的`map()`函数,只是操作是对子进程进行的。`map`将阻塞至所有任务完成为止;`map_async`则会立即返回结果对象。限制:可调用函数只能带有一个参数。
imap和imap_async
类似于`map`和`map_async`,只是返回的是迭代器而不是序列全体。可被视为`lazy_map`。
starmap和starmap_async
类似于`map`和`map_async`,只是其可调用函数可以接受多个参数。
大多数[注5]要用到的方法就是以上这些,如您所见,他们几乎都是概念类似的变体。因为我们的create_thumbnail函数要用到多个参数,所以Thumper选用了starmap_async。
# src_dir是存放全尺寸图片的文件夹
# dest_dir是要写入缩略图的地方
# in是并行处理的文件集
def gen_child_args():
for (dirpath, dirnames, filenames) in os.walk(src_dir):
for filename in filenames:
src_path = os.path.join(dirpath, filename)
dest_path = find_dest_path(src_dir, dest_dir, src_path)
yield (src_path, dest_path, thumbnail_width, thumbnail_height)
pool.starmap_async(create_thumbnail, gen_child_args())
没错,startmap_async的第2个参数是可迭代。因为Thumper实际需要处理数百万个图像,所以这里编写了一个节省内存的生成器对象,该生成器将根据需要创建参数元组,而不是生成一个巨大的列表(为每个图像生成一个元组)。
对性能的理解(Understanding Performance)
程序运行成果如何呢?起初确实需要费点脑子才能理解。想象一下,您用的是一台有8个CPU(或核心)的机器。想要给Thumper用多少个CPU呢?理论上会是8个,也就是核心总数。但也可能是别的什么数字,具体要取决于(a)系统的其他状况,(b)应用程序的状况。通常,进程数量少于CPU数量即可获得完全相同的性能。这意味着已经达到了硬件CPU不再是瓶颈的地步。信不信由你,我还见过用了工作进程太多引起资源竞争、拖慢运行速度的情况。
以我自己的经验,确定进程数量的唯一方法就是测试:重复执行,每次只改变所用的CPU数量。就是以上我做的那样。下面着重看下耗时情况,因为我们的重点是要让耗时最短:
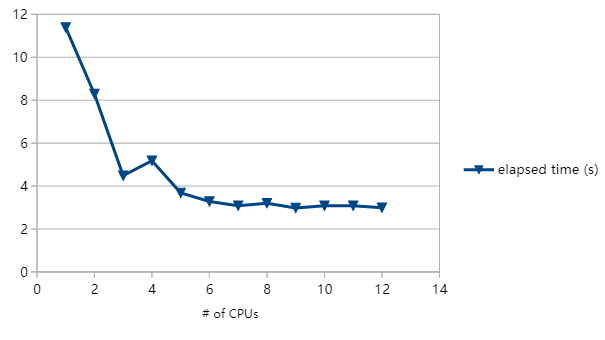
以上是在c3.2 xlarge EC2实例上完成的,这是一台拥有8个CPU的重武器。横坐标是Thumper产生的工作进程数。纵坐标是为所有图片生成缩略图的总耗时,因此越小越好。
如图所示,随着工作进程的加入,耗时逐渐减少,直至CPU数为6为止。为什么不是8或7呢?原因可能有很多,可以是和特定的应用程序密切相关。既然已经尽可能在CPU方面进行了扩展,一般情况下是遇到了别的瓶颈。或许是耗尽了所有可用的内存,已开始了分页。或许CPU缓存饱和了。或许I/O吞吐到了极限,也即每秒加载的图片数据不能增加了。
如您所见,学习multiprocessing提供的类、方法和函数只是第一步。
无论用什么语言,对于一般的编程而言,涉足多CPU只会让您越走越偏。另外,投入的CPU越多,代价就更高。如果真想榨取机器的最大收益,还必须掌握榨取单个线程的最大收益。这就是第3部分将要讨论的内容。关键就是真正击中单个线程要害,秘籍就是……
好吧,发布第3部分时您就会知晓了。请订阅邮件吧。
[注1] 对于单进程、多线程的程序而言,可以通过全局的线程安全队列或其他数据结构来实现消息传递;多进程则可通过IPC完成。
[注2] 除非使用Python的multiprocessing模块。但还是不要太超前了。
[注3] 这太简单了。用C语言扩展就能以与C相似的方式充分利用多CPU,至少在Python应用程序的某个有限部分内可以实现。对于CPython之外的其他Python实现,情形会有所差别。
对于当今大多数使用官方解释器的纯Python应用程序,要用多CPU就意味着要用多进程。
[注4] 或许,至少能降低难度吧。不那么棘手了(And with fewer sharp pointy jagged edges)。
[注5] 还有一些其他方法,比如apply其实就是apply_async,只是在返回之前会阻塞。想不通为什么要在用到multiprocessing的程序里用它吧?我也想不通。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号