
Kafka 温故(一):Kafka背景及架构介绍
一.Kafka简介
Kafka是分布式发布-订阅消息系统。它最初由LinkedIn公司开发,使用Scala语言编写,之后成为Apache项目的一部分。Kafka是一个分布式的,可划分的,多订阅者,冗余备份的持久性的日志服务。它主要用于处理活跃的流式数据(实时性的计算)。
在大数据系统中,常常会碰到一个问题,整个大数据是由各个子系统组成,数据需要在各个子系统中高性能,低延迟的不停流转。传统的企业消息系统并不是非常适合大规模的数据处理。为了已在同时搞定在线应用(消息)和离线应用(数据文件,日志)Kafka就出现了。Kafka可以起到两个作用:
1.降低系统组网复杂度。
2.降低编程复杂度,各个子系统不在是相互协商接口,各个子系统类似插口插在插座上,Kafka承担高速数据总线的作用。
二.Kafka的主要特点
1.同时为发布和订阅提供高吞吐量。据了解,Kafka每秒可以生产约25万消息(50 MB),每秒处理55万消息(110 MB)。
2.可进行持久化操作。将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。通过将数据持久化到硬盘以及replication防止数据丢失。
3.分布式系统,易于向外扩展,可以和ZooKeeper结合。所有的producer、broker和consumer都会有多个,均为分布式的。无需停机即可扩展机器。
4.消息被处理的状态是在consumer端维护,而不是由server端维护。当失败时能自动平衡。
5.支持online和offline的场景。
三.为何使用消息系统
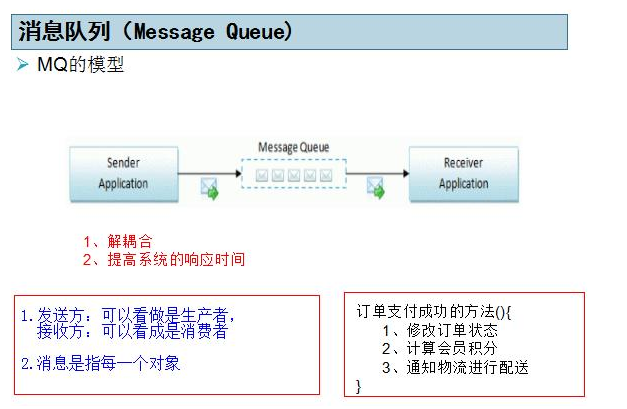
可以通过消息队列做系统之间的通信,即系统之间的相互协调和调用
注意:使用消息队列和SOA架构的区别?
1.SOA是直接调用的(可以通过RPC和HTTPClient来直接调用)
2.使用消息队列是通过消息的传递,来完成两个系统之间的整合和调用
带来的好处:
1.解耦合
使用了消息队列后,两个系统之间没有直接的调用关系,只是通过消息的传递来交互,两个系统之间没有侵入性。
2.提高系统的响应速度
例子:订单处理
订单支付成功的方法(){
1、修改订单状态
2、计算会员积分
3、通知物流进行配送
}
注:
1.原来系统中这个三个步骤要同时处理后再返回,这样比较耗时;
2.现在可以先处理用户最关心的,最急需看到的修改订单状态成功信息,这样可以先处理"修改订单状态",然后立刻返回给用户,
后面的“计算会员积分”,“通知物流进行配送”,放入消息队列中交给后面的系统继续处理。
冗余
有些情况下,处理数据的过程会失败。除非数据被持久化,否则将造成丢失。消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
扩展性
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。不需要改变代码、不需要调节参数。扩展就像调大电力按钮一样简单。
灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见;如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
顺序保证
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。Kafka保证一个Partition内的消息的有序性。
缓冲
在任何重要的系统中,都会有需要不同的处理时间的元素。例如,加载一张图片比应用过滤器花费更少的时间。消息队列通过一个缓冲层来帮助任务最高效率的执行———写入队列的处理会尽可能的快速。该缓冲有助于控制和优化数据流经过系统的速度。
异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
四.消息队列的分类
消息队列的分类:点对点,发布/订阅
1.点对点
消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并且消费消息
注意(缺点):
1.消息被消费以后,queue中不再有存储,所以消费者不可肯消费到已经被消费的消息。
2.queue中支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
(当一个系统消费了该个消息后,其他的系统不能再消费了)
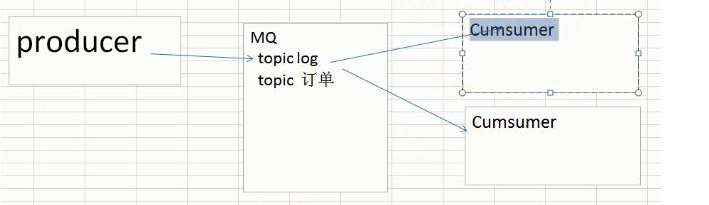
2.发布/订阅(最常用的)
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅的消费者消费。
五.常见的消息队列对比
1.RabbitMQ:支持的协议多,非常重量级消息队列,对路由(Routing),负载均衡(Load balance)或者数据持久化都有很好的支持。
2.ZeroMQ:号称最快的消息队列系统,尤其针对大吞吐量的需求场景,擅长的高级/复杂的队列,但是技术也复杂,并且只提供非持久性的队列。
3.ActiveMQ(JMS的实现):Apache下的一个子项,类似ZeroMQ,能够以代理人和点对点的技术实现队列 。
4.Redis:是一个key-Value的NOSql数据库,但也支持MQ功能,数据量较小,性能优于RabbitMQ,数据超过10K就慢的无法忍受。
注:消息队列不可能是单点的,也需要集群。这样就涉及到了,负载均衡和消息的持久化
六.Kafka的测试效果

参考资料:
《百知教育》apache kafka



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端
2017-10-17 JAVA提高五:注解Annotation