
二、Kafka基础实战:消费者和生产者实例
一、Kafka消费者编程模型
1.分区消费模型
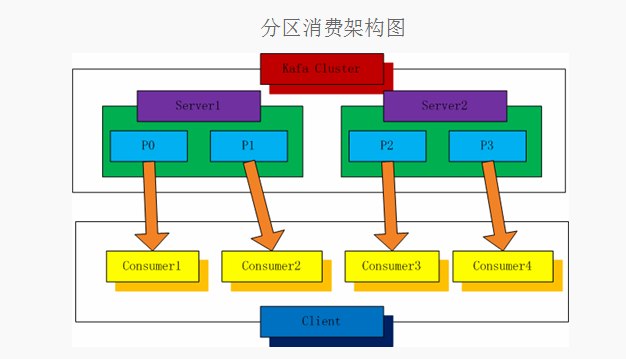
分区消费伪代码描述

main()
获取分区的size
for index =0 to size
create thread(or process) consumer(Index)
第index个线程(进程)
consumer(index)
创建到kafka broker的连接: KafkaClient(host,port)
指定消费参数构建consumer: SimpleConsumer(topic, partitions)
设置消费offset : consumer.seek(offset,0)
while True
消费指定topic第index个分区的数据
处理
记录当前消息offset
提交当前offset(可选)
2.组(Group)消费模型
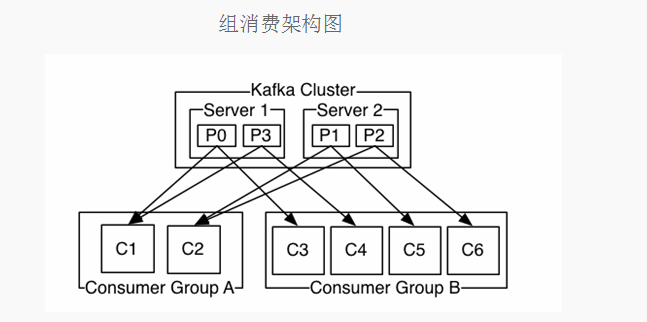
按组(Group)消费伪代码描述
main() 设置需要创建的流数N for index =0 to N create thread consumer(Index) 第index个线程 consumer(index) 创建到kafka broker的连接: KafkaClient(host,port) 指定消费参数构建consumer: SimpleConsumer(topic, partitions) 设置从头消费还是从最新的消费(smallest或largest) while True 从指定topic的第index个流取数据 处理 (offset会自动提交到zookeeper,无需我们操作)
Consumer分配算法

3.两种消费模型对比
分区消费模型更加灵活但是:
(1)需要自己处理各种异常情况;
(2)需要自己管理offset(以实现消息传递的其他语义);
分组消费模型更加简单,但是不灵活:
(1)不需要自己处理异常情况,不需要自己管理offset;
(2)只能实现kafka默认的最少一次消息传递语义;
消息传递三种语义:
(1)至多一次;
(2)最少一次;
(3)恰好一次;
二、Kafka消费者的Python和Java客户端实现
1.Python客户端实例讲解
•需要的软件环境:
已搭建好的kafka集群、Linux服务器一台、Python2.7.6 、 kafka-Python软件包
•分区消费模型的Python实现;
main.py
# -*- coding: utf-8 -*- """ This module provide kafka partition and group consumer demo example. """ import logging, time import partition_consumer def main(): threads = [] partition = 3 for index in range(partition): threads.append(partition_consumer.Consumer(index)) for t in threads: t.start() time.sleep(50000) if __name__ == '__main__': #logging.basicConfig( # format='%(asctime)s.%(msecs)s:%(name)s:%(thread)d:%(levelname)s:%(process)d:%(message)s', # level=logging.INFO # ) main()
partition_consumer.py
# -*- coding: utf-8 -*- """ This module provide kafka partition partition consumer demo example. """ import threading from kafka.client import KafkaClient from kafka.consumer import SimpleConsumer class Consumer(threading.Thread): daemon = True def __init__(self,partition_index): threading.Thread.__init__(self) self.part = [partition_index] self.__offset = 0 def run(self): client = KafkaClient("10.206.216.13:19092,10.206.212.14:19092,10.206.209.25:19092") consumer = SimpleConsumer(client, "test-group", "jiketest",auto_commit=False,partitions=self.part) consumer.seek(0,0) while True: message = consumer.get_message(True,60) self.__offset = message.offset print message.message.value
•组(Group)消费模型的Python实现;
main.py
# -*- coding: utf-8 -*- """ This module provide kafka partition and group consumer demo example. """ import logging, time import group_consumer def main(): conusmer_thread = group_consumer.Consumer() conusmer_thread.start() time.sleep(500000) if __name__ == '__main__': #logging.basicConfig( # format='%(asctime)s.%(msecs)s:%(name)s:%(thread)d:%(levelname)s:%(process)d:%(message)s', # level=logging.INFO # ) main()
group_consumer.py
# -*- coding: utf-8 -*- """ This module provide kafka partition group consumer demo example. """ import threading from kafka.client import KafkaClient from kafka.consumer import SimpleConsumer class Consumer(threading.Thread): daemon = True def run(self): client = KafkaClient("10.206.216.13:19092,10.206.212.14:19092,10.206.209.25:19092") consumer = SimpleConsumer(client, "test-group", "jiketest") for message in consumer: print(message.message.value)
2.Python客户端参数调优
•fetch_size_bytes: 从服务器获取单包大小;
•buffer_size: kafka客户端缓冲区大小;
•Group:分组消费时分组名
•auto_commit: offset是否自动提交;
3.Java客户端实例讲解
•需要的软件环境:
已搭建好的kafka集群、Linux服务器一台、Apache Maven 3.2.3、 kafka 0.8.1
•分区消费模型的Java实现;
package kafka.consumer.partition; import kafka.api.FetchRequest; import kafka.api.FetchRequestBuilder; import kafka.api.PartitionOffsetRequestInfo; import kafka.common.ErrorMapping; import kafka.common.TopicAndPartition; import kafka.javaapi.*; import kafka.javaapi.consumer.SimpleConsumer; import kafka.message.MessageAndOffset; import java.nio.ByteBuffer; import java.util.ArrayList; import java.util.Collections; import java.util.HashMap; import java.util.List; import java.util.Map; public class PartitionConsumerTest { public static void main(String args[]) { PartitionConsumerTest example = new PartitionConsumerTest(); long maxReads = Long.MAX_VALUE; String topic = "jiketest"; if(args.length < 1){ System.out.println("Please assign partition number."); } List<String> seeds = new ArrayList<String>(); String hosts="10.206.216.13,10.206.212.14,10.206.209.25"; String[] hostArr = hosts.split(","); for(int index = 0;index < hostArr.length;index++){ seeds.add(hostArr[index].trim()); } int port = 19092; int partLen = Integer.parseInt(args[0]); for(int index=0;index < partLen;index++){ try { example.run(maxReads, topic, index/*partition*/, seeds, port); } catch (Exception e) { System.out.println("Oops:" + e); e.printStackTrace(); } } } private List<String> m_replicaBrokers = new ArrayList<String>(); public PartitionConsumerTest() { m_replicaBrokers = new ArrayList<String>(); } public void run(long a_maxReads, String a_topic, int a_partition, List<String> a_seedBrokers, int a_port) throws Exception { // find the meta data about the topic and partition we are interested in // PartitionMetadata metadata = findLeader(a_seedBrokers, a_port, a_topic, a_partition); if (metadata == null) { System.out.println("Can't find metadata for Topic and Partition. Exiting"); return; } if (metadata.leader() == null) { System.out.println("Can't find Leader for Topic and Partition. Exiting"); return; } String leadBroker = metadata.leader().host(); String clientName = "Client_" + a_topic + "_" + a_partition; SimpleConsumer consumer = new SimpleConsumer(leadBroker, a_port, 100000, 64 * 1024, clientName); long readOffset = getLastOffset(consumer,a_topic, a_partition, kafka.api.OffsetRequest.EarliestTime(), clientName); int numErrors = 0; while (a_maxReads > 0) { if (consumer == null) { consumer = new SimpleConsumer(leadBroker, a_port, 100000, 64 * 1024, clientName); } FetchRequest req = new FetchRequestBuilder() .clientId(clientName) .addFetch(a_topic, a_partition, readOffset, 100000) // Note: this fetchSize of 100000 might need to be increased if large batches are written to Kafka .build(); FetchResponse fetchResponse = consumer.fetch(req); if (fetchResponse.hasError()) { numErrors++; // Something went wrong! short code = fetchResponse.errorCode(a_topic, a_partition); System.out.println("Error fetching data from the Broker:" + leadBroker + " Reason: " + code); if (numErrors > 5) break; if (code == ErrorMapping.OffsetOutOfRangeCode()) { // We asked for an invalid offset. For simple case ask for the last element to reset readOffset = getLastOffset(consumer,a_topic, a_partition, kafka.api.OffsetRequest.LatestTime(), clientName); continue; } consumer.close(); consumer = null; leadBroker = findNewLeader(leadBroker, a_topic, a_partition, a_port); continue; } numErrors = 0; long numRead = 0; for (MessageAndOffset messageAndOffset : fetchResponse.messageSet(a_topic, a_partition)) { long currentOffset = messageAndOffset.offset(); if (currentOffset < readOffset) { System.out.println("Found an old offset: " + currentOffset + " Expecting: " + readOffset); continue; } readOffset = messageAndOffset.nextOffset(); ByteBuffer payload = messageAndOffset.message().payload(); byte[] bytes = new byte[payload.limit()]; payload.get(bytes); System.out.println(String.valueOf(messageAndOffset.offset()) + ": " + new String(bytes, "UTF-8")); numRead++; a_maxReads--; } if (numRead == 0) { try { Thread.sleep(1000); } catch (InterruptedException ie) { } } } if (consumer != null) consumer.close(); } public static long getLastOffset(SimpleConsumer consumer, String topic, int partition, long whichTime, String clientName) { TopicAndPartition topicAndPartition = new TopicAndPartition(topic, partition); Map<TopicAndPartition, PartitionOffsetRequestInfo> requestInfo = new HashMap<TopicAndPartition, PartitionOffsetRequestInfo>(); requestInfo.put(topicAndPartition, new PartitionOffsetRequestInfo(whichTime, 1)); kafka.javaapi.OffsetRequest request = new kafka.javaapi.OffsetRequest( requestInfo, kafka.api.OffsetRequest.CurrentVersion(), clientName); OffsetResponse response = consumer.getOffsetsBefore(request); if (response.hasError()) { System.out.println("Error fetching data Offset Data the Broker. Reason: " + response.errorCode(topic, partition) ); return 0; } long[] offsets = response.offsets(topic, partition); return offsets[0]; } private String findNewLeader(String a_oldLeader, String a_topic, int a_partition, int a_port) throws Exception { for (int i = 0; i < 3; i++) { boolean goToSleep = false; PartitionMetadata metadata = findLeader(m_replicaBrokers, a_port, a_topic, a_partition); if (metadata == null) { goToSleep = true; } else if (metadata.leader() == null) { goToSleep = true; } else if (a_oldLeader.equalsIgnoreCase(metadata.leader().host()) && i == 0) { // first time through if the leader hasn't changed give ZooKeeper a second to recover // second time, assume the broker did recover before failover, or it was a non-Broker issue // goToSleep = true; } else { return metadata.leader().host(); } if (goToSleep) { try { Thread.sleep(1000); } catch (InterruptedException ie) { } } } System.out.println("Unable to find new leader after Broker failure. Exiting"); throw new Exception("Unable to find new leader after Broker failure. Exiting"); } private PartitionMetadata findLeader(List<String> a_seedBrokers, int a_port, String a_topic, int a_partition) { PartitionMetadata returnMetaData = null; loop: for (String seed : a_seedBrokers) { SimpleConsumer consumer = null; try { consumer = new SimpleConsumer(seed, a_port, 100000, 64 * 1024, "leaderLookup"); List<String> topics = Collections.singletonList(a_topic); TopicMetadataRequest req = new TopicMetadataRequest(topics); kafka.javaapi.TopicMetadataResponse resp = consumer.send(req); List<TopicMetadata> metaData = resp.topicsMetadata(); for (TopicMetadata item : metaData) { for (PartitionMetadata part : item.partitionsMetadata()) { if (part.partitionId() == a_partition) { returnMetaData = part; break loop; } } } } catch (Exception e) { System.out.println("Error communicating with Broker [" + seed + "] to find Leader for [" + a_topic + ", " + a_partition + "] Reason: " + e); } finally { if (consumer != null) consumer.close(); } } if (returnMetaData != null) { m_replicaBrokers.clear(); for (kafka.cluster.Broker replica : returnMetaData.replicas()) { m_replicaBrokers.add(replica.host()); } } return returnMetaData; } }
•组(Group)消费模型的Java实现;
package kafka.consumer.group; import kafka.consumer.ConsumerIterator; import kafka.consumer.KafkaStream; public class ConsumerTest implements Runnable { private KafkaStream m_stream; private int m_threadNumber; public ConsumerTest(KafkaStream a_stream, int a_threadNumber) { m_threadNumber = a_threadNumber; m_stream = a_stream; } public void run() { ConsumerIterator<byte[], byte[]> it = m_stream.iterator(); while (it.hasNext()){ System.out.println("Thread " + m_threadNumber + ": " + new String(it.next().message())); } System.out.println("Shutting down Thread: " + m_threadNumber); } }
package kafka.consumer.group; import kafka.consumer.ConsumerConfig; import kafka.consumer.KafkaStream; import kafka.javaapi.consumer.ConsumerConnector; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Properties; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.TimeUnit; public class GroupConsumerTest extends Thread { private final ConsumerConnector consumer; private final String topic; private ExecutorService executor; public GroupConsumerTest(String a_zookeeper, String a_groupId, String a_topic){ consumer = kafka.consumer.Consumer.createJavaConsumerConnector( createConsumerConfig(a_zookeeper, a_groupId)); this.topic = a_topic; } public void shutdown() { if (consumer != null) consumer.shutdown(); if (executor != null) executor.shutdown(); try { if (!executor.awaitTermination(Long.MAX_VALUE, TimeUnit.MILLISECONDS)) { System.out.println("Timed out waiting for consumer threads to shut down, exiting uncleanly"); } } catch (InterruptedException e) { System.out.println("Interrupted during shutdown, exiting uncleanly"); } } public void run(int a_numThreads) { Map<String, Integer> topicCountMap = new HashMap<String, Integer>(); topicCountMap.put(topic, new Integer(a_numThreads)); Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap); List<KafkaStream<byte[], byte[]>> streams = consumerMap.get(topic); // now launch all the threads // executor = Executors.newFixedThreadPool(a_numThreads); // now create an object to consume the messages // int threadNumber = 0; for (final KafkaStream stream : streams) { executor.submit(new ConsumerTest(stream, threadNumber)); threadNumber++; } } private static ConsumerConfig createConsumerConfig(String a_zookeeper, String a_groupId) { Properties props = new Properties(); props.put("zookeeper.connect", a_zookeeper); props.put("group.id", a_groupId); props.put("zookeeper.session.timeout.ms", "40000"); props.put("zookeeper.sync.time.ms", "2000"); props.put("auto.commit.interval.ms", "1000"); return new ConsumerConfig(props); } public static void main(String[] args) { if(args.length < 1){ System.out.println("Please assign partition number."); } String zooKeeper = "10.206.216.13:12181,10.206.212.14:12181,10.206.209.25:12181"; String groupId = "jikegrouptest"; String topic = "jiketest"; int threads = Integer.parseInt(args[0]); GroupConsumerTest example = new GroupConsumerTest(zooKeeper, groupId, topic); example.run(threads); try { Thread.sleep(Long.MAX_VALUE); } catch (InterruptedException ie) { } example.shutdown(); } }
4.Java客户端参数调优
•fetchSize: 从服务器获取单包大小;
•bufferSize: kafka客户端缓冲区大小;
•group.id: 分组消费时分组名
三、Kafka生产者编程模型
1.同步生产模型

2.异步生产模型
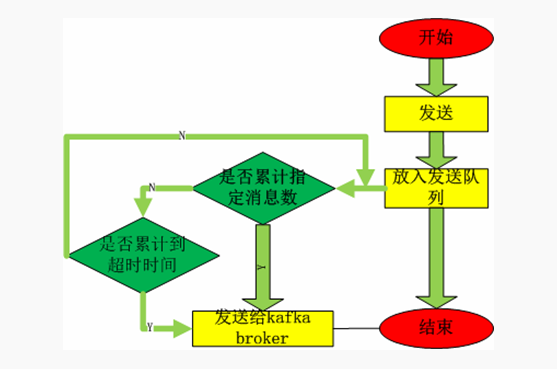
3.两种生产模型伪代码描述
main() 创建到kafka broker的连接:KafkaClient(host,port) 选择或者自定义生产者负载均衡算法 partitioner 设置生产者参数 根据负载均衡算法和设置的生产者参数构造Producer对象 while True getMessage:从上游获得一条消息 按照kafka要求的消息格式构造kafka消息 根据分区算法得到分区 发送消息 处理异常
4.两种生产模型对比
同步生产模型:
(1)低消息丢失率;
(2)高消息重复率(由于网络原因,回复确认未收到);
(3)高延迟
异步生产模型:
(1)低延迟;
(2)高发送性能;
(3)高消息丢失率(无确认机制,发送端队列满)
四、Kafka生产者的Python和Java客户端实现
1.Python客户端实例讲解
•需要的软件环境:
已搭建好的kafka集群、Linux服务器一台、Python2.7.6 、 kafka-Python软件包
main.py
# -*- coding: utf-8 -*- """ This module provide kafka sync and async producer demo example. """ import logging, time from async.ASyncProducer import ASyncProducer from sync.SyncProducer import SyncProducer def main(): threads = [ ASyncProducer(), SyncProducer() ] for t in threads: t.start() time.sleep(5000) if __name__ == "__main__": #logging.basicConfig( # format='%(asctime)s.%(msecs)s:%(name)s:%(thread)d:%(levelname)s:%(process)d:%(message)s', # level=logging.INFO # ) main()
•同步生产模型的Python实现
SyncProducer.py
# -*- coding: utf-8 -*- """ This module provide kafka partition and group consumer demo example. """ import threading, time from kafka.client import KafkaClient from kafka.producer import SimpleProducer from kafka.partitioner import HashedPartitioner class SyncProducer(threading.Thread): daemon = True def run(self): client = KafkaClient("10.206.216.13:19092,10.206.212.14:19092,10.206.209.25:1909") producer = SimpleProducer(client) #producer = KeyedProducer(client,partitioner=HashedPartitioner) while True: producer.send_messages('jiketest', "test") producer.send_messages('jiketest', "test") time.sleep(1)
•异步生产模型的Python实现
ASyncProducer.py
# -*- coding: utf-8 -*- """ This module provide kafka partition and group consumer demo example. """ import threading, time from kafka.client import KafkaClient from kafka.producer import SimpleProducer class ASyncProducer(threading.Thread): daemon = True def run(self): client = KafkaClient("10.206.216.13:19092,10.206.212.14:19092,10.206.209.25:19092") producer = SimpleProducer(client,async=True) while True: producer.send_messages('jiketest', "test") producer.send_messages('jiketest', "test") time.sleep(1)
2.Python客户端参数调优
•req_acks:发送失败重试次数;
•ack_timeout: 未接到确认,认为发送失败的时间;
•async : 是否异步发送;
•batch_send_every_n: 异步发送时,累计最大消息数;
•batch_send_every_t:异步发送时,累计最大时间;
3.Java客户端实例讲解
•需要的软件环境:
已搭建好的kafka集群、Linux服务器一台、Apache Maven 3.2.3、 kafka 0.8.1
SimplePartitioner.java
package kafka.producer.partiton; import kafka.producer.Partitioner; import kafka.utils.VerifiableProperties; public class SimplePartitioner implements Partitioner { public SimplePartitioner (VerifiableProperties props) { } public int partition(Object key, int a_numPartitions) { int partition = 0; String stringKey = (String) key; int offset = stringKey.lastIndexOf('.'); if (offset > 0) { partition = Integer.parseInt( stringKey.substring(offset+1)) % a_numPartitions; } return partition; } }
•同步模型的Java实现
package kafka.producer.sync; import java.util.*; import kafka.javaapi.producer.Producer; import kafka.producer.KeyedMessage; import kafka.producer.ProducerConfig; public class SyncProduce { public static void main(String[] args) { long events = Long.MAX_VALUE; Random rnd = new Random(); Properties props = new Properties(); props.put("metadata.broker.list", "10.206.216.13:19092,10.206.212.14:19092,10.206.209.25:19092"); props.put("serializer.class", "kafka.serializer.StringEncoder"); //kafka.serializer.DefaultEncoder props.put("partitioner.class", "kafka.producer.partiton.SimplePartitioner"); //kafka.producer.DefaultPartitioner: based on the hash of the key props.put("request.required.acks", "1"); //0; 绝不等确认 1: leader的一个副本收到这条消息,并发回确认 -1: leader的所有副本都收到这条消息,并发回确认 ProducerConfig config = new ProducerConfig(props); Producer<String, String> producer = new Producer<String, String>(config); for (long nEvents = 0; nEvents < events; nEvents++) { long runtime = new Date().getTime(); String ip = "192.168.2." + rnd.nextInt(255); String msg = runtime + ",www.example.com," + ip; //eventKey必须有(即使自己的分区算法不会用到这个key,也不能设为null或者""),否者自己的分区算法根本得不到调用 KeyedMessage<String, String> data = new KeyedMessage<String, String>("jiketest", ip, msg); // eventTopic, eventKey, eventBody producer.send(data); try { Thread.sleep(1000); } catch (InterruptedException ie) { } } producer.close(); } }
•异步模型的Java实现
ASyncProduce.java
package kafka.producer.async; import java.util.*; import kafka.javaapi.producer.Producer; import kafka.producer.KeyedMessage; import kafka.producer.ProducerConfig; public class ASyncProduce { public static void main(String[] args) { long events = Long.MAX_VALUE; Random rnd = new Random(); Properties props = new Properties(); props.put("metadata.broker.list", "10.206.216.13:19092,10.206.212.14:19092,10.206.209.25:19092"); props.put("serializer.class", "kafka.serializer.StringEncoder"); //kafka.serializer.DefaultEncoder props.put("partitioner.class", "kafka.producer.partiton.SimplePartitioner"); //kafka.producer.DefaultPartitioner: based on the hash of the key //props.put("request.required.acks", "1"); props.put("producer.type", "async"); //props.put("producer.type", "1"); // 1: async 2: sync ProducerConfig config = new ProducerConfig(props); Producer<String, String> producer = new Producer<String, String>(config); for (long nEvents = 0; nEvents < events; nEvents++) { long runtime = new Date().getTime(); String ip = "192.168.2." + rnd.nextInt(255); String msg = runtime + ",www.example.com," + ip; KeyedMessage<String, String> data = new KeyedMessage<String, String>("jiketest", ip, msg); producer.send(data); try { Thread.sleep(1000); } catch (InterruptedException ie) { } } producer.close(); } }
4.Java客户端参数调优
•message.send.max.retries: 发送失败重试次数;
•retry.backoff.ms :未接到确认,认为发送失败的时间;
•producer.type: 同步发送或者异步发送;
•batch.num.messages: 异步发送时,累计最大消息数;
•queue.buffering.max.ms:异步发送时,累计最大时间;



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端