Java提高十七:TreeSet 深入分析
前一篇我们分析了TreeMap,接下来我们分析TreeSet,比较有意思的地方是,似乎有Map和Set的地方,Set几乎都成了Map的一个马甲。此话怎讲呢?在前面一篇讨论HashMap和HashSet的详细实现讨论里,我们发现HashSet的详细实现都是通过封装了一个HashMap的成员变量来实现的。这里,TreeSet也不例外。我们先看部分代码,里面声明了成员变量:
private transient NavigableMap<E,Object> m;
这里NavigableMap本身是TreeMap所实现的一个接口。我们再看下面和构造函数相关的实现:
TreeSet(NavigableMap<E,Object> m) { this.m = m; } public TreeSet() { // 无参数构造函数 this(new TreeMap<E,Object>()); } public TreeSet(Comparator<? super E> comparator) { // 包含比较器的构造函数 this(new TreeMap<>(comparator)); } public TreeSet(Collection<? extends E> c) { this(); addAll(c); } public TreeSet(SortedSet<E> s) { this(s.comparator()); addAll(s); } public boolean addAll(Collection<? extends E> c) { // Use linear-time version if applicable if (m.size()==0 && c.size() > 0 && c instanceof SortedSet && m instanceof TreeMap) { SortedSet<? extends E> set = (SortedSet<? extends E>) c; TreeMap<E,Object> map = (TreeMap<E, Object>) m; Comparator<? super E> cc = (Comparator<? super E>) set.comparator(); Comparator<? super E> mc = map.comparator(); if (cc==mc || (cc != null && cc.equals(mc))) { map.addAllForTreeSet(set, PRESENT); return true; } } return super.addAll(c); }
这里构造函数相关部分的代码看起来比较多,实际上主要的构造函数就两个,一个是默认的无参数构造函数和一个比较器构造函数,他们内部的实现都是使用的TreeMap,而其他相关的构造函数都是通过调用这两个来实现的,故其底层使用的就是TreeMap。既然TreeSet只是TreeMap的一个马甲,因此只要掌握了前面一篇的TreeMap原理,那么TreeSet还是比较容易懂的,因此本文不会详细去介绍TreeMap中已介绍的内容。好了,言归正传,下面开始TreeSet的学习。
一、TreeSet简单介绍
TreeSet是JAVA中集合的一种,TreeSet 是一个有序的集合,它的作用是提供有序的Set集合。它继承于AbstractSet抽象类,实现了NavigableSet<E>,Cloneable,java.io.Serializable接口。一种基于TreeMap的NavigableSet实现。
因为TreeSet继承了AbstractSet抽象类,所以它是一个set集合,可以被实例化,且具有set的属性和方法。
TreeSet是基于TreeMap实现的。TreeSet中的元素支持2种排序方式:自然排序 或者 根据创建TreeSet 时提供的 Comparator 进行排序。这取决于使用的构造方法。
TreeSet的性能比HashSet差但是我们在需要排序的时候可以用TreeSet因为他是自然排序也就是升序下面是TreeSet实现代码这个类也似只能通过迭代器迭代元素
ps:TreeSet是有序的Set集合,因此支持add、remove、get等方法。
java.lang.Object ↳ java.util.AbstractCollection<E> ↳ java.util.AbstractSet<E> ↳ java.util.TreeSet<E> public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, java.io.Serializable{}
TreeSet与Collection关系如下图:
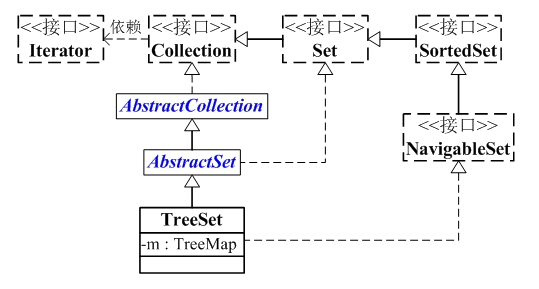
从图中可以看出:
(01) TreeSet继承于AbstractSet,并且实现了NavigableSet接口。
(02) TreeSet的本质是一个"有序的,并且没有重复元素"的集合,它是通过TreeMap实现的。TreeSet中含有一个"NavigableMap类型的成员变量"m,而m实际上是"TreeMap的实例"。
二、TreeSet的构造方法和API
| 序号 | 构造函数的说明 |
|---|---|
| 1 | TreeSet ()
此构造函数构造空树集,将在根据其元素的自然顺序按升序排序。 |
| 2 | TreeSet (集合 c)
此构造函数生成树的集合,它包含的元素的集合 c。 |
| 3 | TreeSet (比较器 comp)
此构造函数构造一个空树集,将根据给定的比较器进行排序。 |
| 4 | TreeSet (SortedSet ss)
此构造函数生成包含给定 SortedSet 的元素 TreeSet |
TreeSet的方法:
| 修饰符和类型 | 方法和描述 |
|---|---|
boolean |
add(E e)
将指定的元素添加到这套,如果它已不存在。
|
boolean |
addAll(Collection<? extends E> c)
在加入这一组指定的集合中添加的所有元素。
|
E |
ceiling(E e)
返回最小的元素在这一组大于或等于给定的元素,则
null如果没有这样的元素。 |
void |
clear()
从这一组中移除所有元素。
|
Object |
clone()
返回此
TreeSet实例浅表副本。 |
Comparator<? super E> |
comparator()
返回用于排序在这集,或空元素,如果这套使用自然排序其元素的比较。
|
boolean |
contains(Object o)
如果此集合包含指定的元素,则返回
true 。 |
Iterator<E> |
descendingIterator()
返回迭代器中这套降序排序的元素。
|
NavigableSet<E> |
descendingSet()
返回逆序视图中包含的元素这一套。
|
E |
first()
返回第一个 (最低) 元素当前在这一套。
|
E |
floor(E e)
返回的最大元素在这一组小于或等于
null如果没有这样的元素。 |
SortedSet<E> |
headSet(E toElement)
返回其元素是严格小于toElement这套的部分视图.
|
NavigableSet<E> |
headSet(E toElement, boolean inclusive)
返回一个视图的这部分设置的元素都小于 (或等于,如果
inclusive是真的) toElement. |
E |
higher(E e)
返回最小的元素在这套严格大于给定的元素,则
null如果没有这样的元素。 |
boolean |
isEmpty()
如果此集不包含任何元素,则返回
true 。 |
Iterator<E> |
iterator()
返回迭代器中这套以升序排序的元素。
|
E |
last()
在这套目前返回的最后一个 (最高) 的元素。
|
E |
lower(E e)
在这一套严格的小于给定的元素,则
null返回的最大元素,如果没有这样的元素。 |
E |
pollFirst()
检索和删除第一个 (最低) 元素,或如果此集合为空,则返回
null 。 |
E |
pollLast()
检索和删除的最后一个 (最高) 的元素,或如果此集合为空,则返回
null 。 |
boolean |
remove(Object o)
从这一组中移除指定的元素,如果它存在。
|
int |
size()
在这套 (其基数) 中返回的元素的数目。
|
NavigableSet<E> |
subSet(E fromElement, boolean fromInclusive, E toElement, boolean toInclusive)
返回此集的部分视图的元素范围从
fromElement到toElement. |
SortedSet<E> |
subSet(E fromElement, E toElement)
返回视图的部分的这一套的元素范围从fromElement,具有包容性,到toElement,独家。
|
SortedSet<E> |
tailSet(E fromElement)
返回其元素是大于或等于fromElement这套的部分视图.
|
NavigableSet<E> |
tailSet(E fromElement, boolean inclusive)
返回其元素是大于 (或等于,如果
inclusive是真的) 这套的部分视图fromElement. |
三、TreeSet主要方法分析
1、add:将指定的元素添加到此 set(如果该元素尚未存在于 set 中)。
public boolean add(E e) { return m.put(e, PRESENT)==null; }
2、addAll:将指定 collection 中的所有元素添加到此 set 中。
public boolean addAll(Collection<? extends E> c) { // Use linear-time version if applicable if (m.size()==0 && c.size() > 0 && c instanceof SortedSet && m instanceof TreeMap) { SortedSet<? extends E> set = (SortedSet<? extends E>) c; TreeMap<E,Object> map = (TreeMap<E, Object>) m; Comparator<? super E> cc = (Comparator<? super E>) set.comparator(); Comparator<? super E> mc = map.comparator(); if (cc==mc || (cc != null && cc.equals(mc))) { map.addAllForTreeSet(set, PRESENT); return true; } } return super.addAll(c); }
3、ceiling:返回此 set 中大于等于给定元素的最小元素;如果不存在这样的元素,则返回 null。
public E ceiling(E e) { return m.ceilingKey(e); }
4、clear:移除此 set 中的所有元素。
public void clear() { m.clear(); }
5、clone:返回 TreeSet 实例的浅表副本。属于浅拷贝。
public Object clone() { TreeSet<E> clone = null; try { clone = (TreeSet<E>) super.clone(); } catch (CloneNotSupportedException e) { throw new InternalError(); } clone.m = new TreeMap<>(m); return clone; }
6、comparator:返回对此 set 中的元素进行排序的比较器;如果此 set 使用其元素的自然顺序,则返回 null。
public Comparator<? super E> comparator() { return m.comparator(); }
7、contains:如果此 set 包含指定的元素,则返回 true。
public boolean contains(Object o) { return m.containsKey(o); }
8、descendingIterator:返回在此 set 元素上按降序进行迭代的迭代器。
public Iterator<E> descendingIterator() { return m.descendingKeySet().iterator(); }
9、descendingSet:返回此 set 中所包含元素的逆序视图。
public NavigableSet<E> descendingSet() { return new TreeSet<>(m.descendingMap()); }
10、first:返回此 set 中当前第一个(最低)元素。
public E first() { return m.firstKey(); }
剩下的不一一分析,都比较简单。
四、TreeSet遍历方式
Iterator顺序遍历
for(Iterator iter = set.iterator(); iter.hasNext(); ) { iter.next(); }
// 假设set是TreeSet对象 for(Iterator iter = set.descendingIterator(); iter.hasNext(); ) { iter.next(); }
for-each遍历HashSet
// 假设set是TreeSet对象,并且set中元素是String类型 String[] arr = (String[])set.toArray(new String[0]); for (String str:arr) System.out.printf("for each : %s\n", str);
TreeSet不支持快速随机遍历,只能通过迭代器进行遍历!
测试:
1 import java.util.*; 2 3 public class TreeSetIteratorTest { 4 5 public static void main(String[] args) { 6 TreeSet set = new TreeSet(); 7 set.add("aaa"); 8 set.add("aaa"); 9 set.add("bbb"); 10 set.add("eee"); 11 set.add("ddd"); 12 set.add("ccc"); 13 14 // 顺序遍历TreeSet 15 ascIteratorThroughIterator(set) ; 16 // 逆序遍历TreeSet 17 descIteratorThroughIterator(set); 18 // 通过for-each遍历TreeSet。不推荐!此方法需要先将Set转换为数组 19 foreachTreeSet(set); 20 } 21 22 // 顺序遍历TreeSet 23 public static void ascIteratorThroughIterator(TreeSet set) { 24 System.out.print("\n ---- Ascend Iterator ----\n"); 25 for(Iterator iter = set.iterator(); iter.hasNext(); ) { 26 System.out.printf("asc : %s\n", iter.next()); 27 } 28 } 29 30 // 逆序遍历TreeSet 31 public static void descIteratorThroughIterator(TreeSet set) { 32 System.out.printf("\n ---- Descend Iterator ----\n"); 33 for(Iterator iter = set.descendingIterator(); iter.hasNext(); ) 34 System.out.printf("desc : %s\n", (String)iter.next()); 35 } 36 37 // 通过for-each遍历TreeSet。不推荐!此方法需要先将Set转换为数组 38 private static void foreachTreeSet(TreeSet set) { 39 System.out.printf("\n ---- For-each ----\n"); 40 String[] arr = (String[])set.toArray(new String[0]); 41 for (String str:arr) 42 System.out.printf("for each : %s\n", str); 43 } 44 }
运行结果:
---- Ascend Iterator ---- asc : aaa asc : bbb asc : ccc asc : ddd asc : eee ---- Descend Iterator ---- desc : eee desc : ddd desc : ccc desc : bbb desc : aaa ---- For-each ---- for each : aaa for each : bbb for each : ccc for each : ddd for each : eee
五、综合对比
TreeSet和TreeMap
相同点:
TreeMap和TreeSet都是有序的集合。
TreeMap和TreeSet都是非同步集合,因此他们不能在多线程之间共享,不过可以使用方法Collections.synchroinzedMap()来实现同步。
运行速度都要比Hash集合慢,他们内部对元素的操作时间复杂度为O(logN),而HashMap/HashSet则为O(1)。
不同点:
最主要的区别就是TreeSet和TreeMap非别实现Set和Map接口
TreeSet只存储一个对象,而TreeMap存储两个对象Key和Value(仅仅key对象有序)
TreeSet中不能有重复对象,而TreeMap中可以存在。
TreeSet和HashSet
相同点:
都是唯一不重复的Set集合。
不同点:
底层来说,HashSet是用Hash表来存储数据,而TreeSet是用二叉平衡树来存储数据。 功能上来说,由于TreeSet是有序的Set,可以使用SortedSet。接口的first()、last()等方法。但由于要排序,势必要影响速度。所以,如果不需要顺序的话,还是使用HashSet吧,使用Hash表存储数据的HashSet在速度上更胜一筹。如果需要顺序则TreeSet更为明智。
底层来说,HashSet是用Hash表来存储数据,而TreeSet是用二叉平衡树来存储数据。
总结:
1、不能有重复的元素;
2、具有排序功能;
3、TreeSet中的元素必须实现Comparable接口并重写compareTo()方法,TreeSet判断元素是否重复 、以及确定元素的顺序 靠的都是这个方法;
①对于java类库中定义的类,TreeSet可以直接对其进行存储,如String,Integer等,因为这些类已经实现了Comparable接口);
②对于自定义类,如果不做适当的处理,TreeSet中只能存储一个该类型的对象实例,否则无法判断是否重复。
4、依赖TreeMap。
5、相对HashSet,TreeSet的优势是有序,劣势是相对读取慢。根据不同的场景选择不同的集合。
整体源码(1.6):
package java.util; public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, java.io.Serializable { // NavigableMap对象 private transient NavigableMap<E,Object> m; // TreeSet是通过TreeMap实现的, // PRESENT是键-值对中的值。 private static final Object PRESENT = new Object(); // 不带参数的构造函数。创建一个空的TreeMap public TreeSet() { this(new TreeMap<E,Object>()); } // 将TreeMap赋值给 "NavigableMap对象m" TreeSet(NavigableMap<E,Object> m) { this.m = m; } // 带比较器的构造函数。 public TreeSet(Comparator<? super E> comparator) { this(new TreeMap<E,Object>(comparator)); } // 创建TreeSet,并将集合c中的全部元素都添加到TreeSet中 public TreeSet(Collection<? extends E> c) { this(); // 将集合c中的元素全部添加到TreeSet中 addAll(c); } // 创建TreeSet,并将s中的全部元素都添加到TreeSet中 public TreeSet(SortedSet<E> s) { this(s.comparator()); addAll(s); } // 返回TreeSet的顺序排列的迭代器。 // 因为TreeSet时TreeMap实现的,所以这里实际上时返回TreeMap的“键集”对应的迭代器 public Iterator<E> iterator() { return m.navigableKeySet().iterator(); } // 返回TreeSet的逆序排列的迭代器。 // 因为TreeSet时TreeMap实现的,所以这里实际上时返回TreeMap的“键集”对应的迭代器 public Iterator<E> descendingIterator() { return m.descendingKeySet().iterator(); } // 返回TreeSet的大小 public int size() { return m.size(); } // 返回TreeSet是否为空 public boolean isEmpty() { return m.isEmpty(); } // 返回TreeSet是否包含对象(o) public boolean contains(Object o) { return m.containsKey(o); } // 添加e到TreeSet中 public boolean add(E e) { return m.put(e, PRESENT)==null; } // 删除TreeSet中的对象o public boolean remove(Object o) { return m.remove(o)==PRESENT; } // 清空TreeSet public void clear() { m.clear(); } // 将集合c中的全部元素添加到TreeSet中 public boolean addAll(Collection<? extends E> c) { // Use linear-time version if applicable if (m.size()==0 && c.size() > 0 && c instanceof SortedSet && m instanceof TreeMap) { SortedSet<? extends E> set = (SortedSet<? extends E>) c; TreeMap<E,Object> map = (TreeMap<E, Object>) m; Comparator<? super E> cc = (Comparator<? super E>) set.comparator(); Comparator<? super E> mc = map.comparator(); if (cc==mc || (cc != null && cc.equals(mc))) { map.addAllForTreeSet(set, PRESENT); return true; } } return super.addAll(c); } // 返回子Set,实际上是通过TreeMap的subMap()实现的。 public NavigableSet<E> subSet(E fromElement, boolean fromInclusive, E toElement, boolean toInclusive) { return new TreeSet<E>(m.subMap(fromElement, fromInclusive, toElement, toInclusive)); } // 返回Set的头部,范围是:从头部到toElement。 // inclusive是是否包含toElement的标志 public NavigableSet<E> headSet(E toElement, boolean inclusive) { return new TreeSet<E>(m.headMap(toElement, inclusive)); } // 返回Set的尾部,范围是:从fromElement到结尾。 // inclusive是是否包含fromElement的标志 public NavigableSet<E> tailSet(E fromElement, boolean inclusive) { return new TreeSet<E>(m.tailMap(fromElement, inclusive)); } // 返回子Set。范围是:从fromElement(包括)到toElement(不包括)。 public SortedSet<E> subSet(E fromElement, E toElement) { return subSet(fromElement, true, toElement, false); } // 返回Set的头部,范围是:从头部到toElement(不包括)。 public SortedSet<E> headSet(E toElement) { return headSet(toElement, false); } // 返回Set的尾部,范围是:从fromElement到结尾(不包括)。 public SortedSet<E> tailSet(E fromElement) { return tailSet(fromElement, true); } // 返回Set的比较器 public Comparator<? super E> comparator() { return m.comparator(); } // 返回Set的第一个元素 public E first() { return m.firstKey(); } // 返回Set的最后一个元素 public E first() { public E last() { return m.lastKey(); } // 返回Set中小于e的最大元素 public E lower(E e) { return m.lowerKey(e); } // 返回Set中小于/等于e的最大元素 public E floor(E e) { return m.floorKey(e); } // 返回Set中大于/等于e的最小元素 public E ceiling(E e) { return m.ceilingKey(e); } // 返回Set中大于e的最小元素 public E higher(E e) { return m.higherKey(e); } // 获取第一个元素,并将该元素从TreeMap中删除。 public E pollFirst() { Map.Entry<E,?> e = m.pollFirstEntry(); return (e == null)? null : e.getKey(); } // 获取最后一个元素,并将该元素从TreeMap中删除。 public E pollLast() { Map.Entry<E,?> e = m.pollLastEntry(); return (e == null)? null : e.getKey(); } // 克隆一个TreeSet,并返回Object对象 public Object clone() { TreeSet<E> clone = null; try { clone = (TreeSet<E>) super.clone(); } catch (CloneNotSupportedException e) { throw new InternalError(); } clone.m = new TreeMap<E,Object>(m); return clone; } // java.io.Serializable的写入函数 // 将TreeSet的“比较器、容量,所有的元素值”都写入到输出流中 private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException { s.defaultWriteObject(); // 写入比较器 s.writeObject(m.comparator()); // 写入容量 s.writeInt(m.size()); // 写入“TreeSet中的每一个元素” for (Iterator i=m.keySet().iterator(); i.hasNext(); ) s.writeObject(i.next()); } // java.io.Serializable的读取函数:根据写入方式读出 // 先将TreeSet的“比较器、容量、所有的元素值”依次读出 private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException { // Read in any hidden stuff s.defaultReadObject(); // 从输入流中读取TreeSet的“比较器” Comparator<? super E> c = (Comparator<? super E>) s.readObject(); TreeMap<E,Object> tm; if (c==null) tm = new TreeMap<E,Object>(); else tm = new TreeMap<E,Object>(c); m = tm; // 从输入流中读取TreeSet的“容量” int size = s.readInt(); // 从输入流中读取TreeSet的“全部元素” tm.readTreeSet(size, s, PRESENT); } // TreeSet的序列版本号 private static final long serialVersionUID = -2479143000061671589L; }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号