
httpclient 学习
Http协议的重要性相信不用我多说了,HttpClient相比传统JDK自带的URLConnection,增加了易用性和灵活性,它不仅是客户端发送Http请求变得容易,而且也方便了开发人员测试接口(基于Http协议的),即提高了开发的效率,也方便提高代码的健壮性。因此熟练掌握HttpClient是很重要的必修内容,掌握HttpClient后,相信对于Http协议的了解会更加深入。
一、简介
HttpClient是Apache Jakarta Common下的子项目,用来提供高效的、最新的、功能丰富的支持HTTP协议的客户端编程工具包,并且它支持HTTP协议最新的版本和建议。HttpClient已经应用在很多的项目中,比如Apache Jakarta上很著名的另外两个开源项目Cactus和HTMLUnit都使用了HttpClient。
二、特性
1. 基于标准、纯净的Java语言。实现了Http1.0和Http1.1
2. 以可扩展的面向对象的结构实现了Http全部的方法(GET, POST, PUT, DELETE, HEAD, OPTIONS, and TRACE)。
3. 支持HTTPS协议。
4. 通过Http代理建立透明的连接。
5. 利用CONNECT方法通过Http代理建立隧道的https连接。
6. Basic, Digest, NTLMv1, NTLMv2, NTLM2 Session, SNPNEGO/Kerberos认证方案。
7. 插件式的自定义认证方案。
8. 便携可靠的套接字工厂使它更容易的使用第三方解决方案。
9. 连接管理器支持多线程应用。支持设置最大连接数,同时支持设置每个主机的最大连接数,发现并关闭过期的连接。
10. 自动处理Set-Cookie中的Cookie。
11. 插件式的自定义Cookie策略。
12. Request的输出流可以避免流中内容直接缓冲到socket服务器。
13. Response的输入流可以有效的从socket服务器直接读取相应内容。
14. 在http1.0和http1.1中利用KeepAlive保持持久连接。
15. 直接获取服务器发送的response code和 headers。
16. 设置连接超时的能力。
17. 实验性的支持http1.1 response caching。
18. 源代码基于Apache License 可免费获取。
三、使用方法
使用HttpClient发送请求、接收响应很简单,一般需要如下几步即可。
1. 创建HttpClient对象。
2. 创建请求方法的实例,并指定请求URL。如果需要发送GET请求,创建HttpGet对象;如果需要发送POST请求,创建HttpPost对象。
3. 如果需要发送请求参数,可调用HttpGet、HttpPost共同的setParams(HetpParams params)方法来添加请求参数;对于HttpPost对象而言,也可调用setEntity(HttpEntity entity)方法来设置请求参数。
4. 调用HttpClient对象的execute(HttpUriRequest request)发送请求,该方法返回一个HttpResponse。
5. 调用HttpResponse的getAllHeaders()、getHeaders(String name)等方法可获取服务器的响应头;调用HttpResponse的getEntity()方法可获取HttpEntity对象,该对象包装了服务器的响应内容。程序可通过该对象获取服务器的响应内容。
6. 释放连接。无论执行方法是否成功,都必须释放连接
四、实例
实例一:模拟get请求发送,获取返回的内容。

package httpclient; import java.io.IOException; import org.apache.http.HttpEntity; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; /** * Hello world! * */ public class App { public static void main( String[] args ) throws Exception, IOException { CloseableHttpClient httpclient = HttpClients.createDefault(); //创建httpclient HttpGet httpGet = new HttpGet("https://www.cnblogs.com"); //创建get 请求 CloseableHttpResponse response = httpclient.execute(httpGet); //通过httpcleint 发送get 请求 if(response != null) { HttpEntity httpentity = response.getEntity(); //获取响应 System.out.println(EntityUtils.toString(httpentity,"UTF-8")); //采用工具来将实体进行转换输出 } response.close(); httpclient.close(); } }
结果如下:
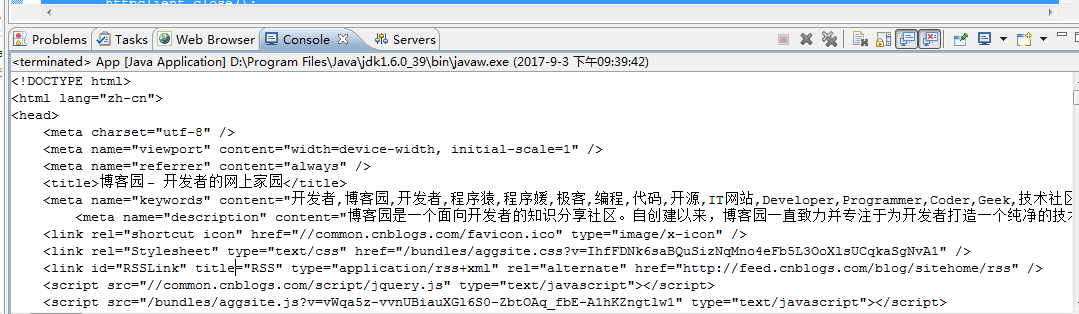
说明上面代码采用的maven 项目需要导入httpclient相关的包,pom文件如下:
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.2</version>
</dependency>
总结,上面我看看到httpclient 很容易的模拟了,客户端发送了http请求,post方式方式一样,但是接下来我们看下面的一个实例:
package httpclient; import java.io.IOException; import org.apache.http.HttpEntity; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; /** * Hello world! * */ public class App { public static void main( String[] args ) throws Exception, IOException { CloseableHttpClient httpclient = HttpClients.createDefault(); //创建httpclient HttpGet httpGet = new HttpGet("http://www.tuicool.com/"); //创建get 请求 CloseableHttpResponse response = httpclient.execute(httpGet); //通过httpcleint 发送get 请求 if(response != null) { HttpEntity httpentity = response.getEntity(); //获取响应 System.out.println(EntityUtils.toString(httpentity,"UTF-8")); //采用工具来将实体进行转换输出 } response.close(); httpclient.close(); } }
结果如下:

这是为什么呢? 原因就在于我们上面模拟的是客户端发送了http请求,但不是模拟的浏览器发出的请求,因此有些网站做了防护,怎么来模拟浏览器发出的请求呢? 浏览器在请的过程中,我们知道会有请求头信息,以便目标服务器识别,如下:
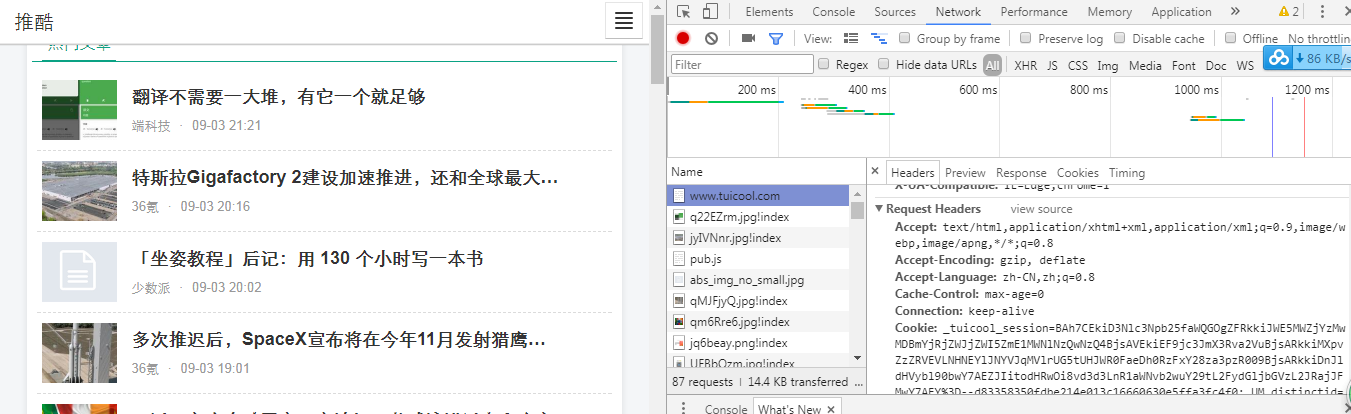
会有一个:
其中最重要的是就是User-Agent,那么我们要模拟浏览器,则需要设置头消息,代码如下:
package httpclient; import java.io.IOException; import org.apache.http.HttpEntity; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; /** * Hello world! * */ public class App { public static void main( String[] args ) throws Exception, IOException { CloseableHttpClient httpclient = HttpClients.createDefault(); //创建httpclient HttpGet httpGet = new HttpGet("http://www.tuicool.com/"); //创建get 请求 httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36"); CloseableHttpResponse response = httpclient.execute(httpGet); //通过httpcleint 发送get 请求 if(response != null) { HttpEntity httpentity = response.getEntity(); //获取响应 System.out.println(EntityUtils.toString(httpentity,"UTF-8")); //采用工具来将实体进行转换输出 } response.close(); httpclient.close(); } }
这个时候,我们测试一下可以看到结果如下:
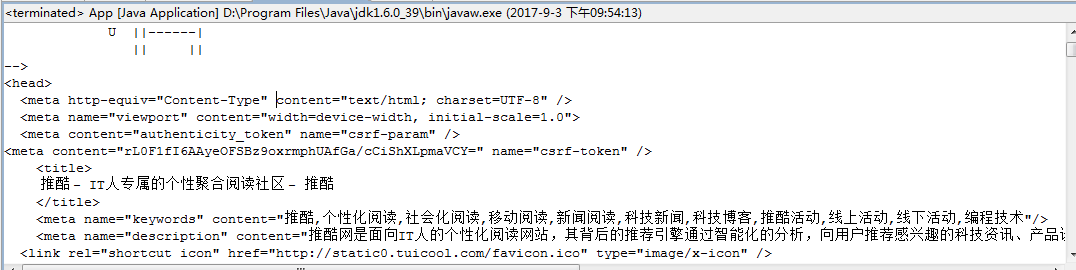
结果已经正常显示出来了,但这个时候,我们是否想到,既然一个浏览器发送了http请求,我们会看到有状态,那么如何通过httpclient返回的response来获取对应的状态呢,以及如何获取响应的类型呢?类型即我们说的content-type
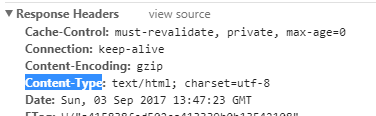
这个时候我们需要通过HttpEntity 来获取,为什么获取content-type 是因为获取的类型非常多,有些是不需要我们采集的,这个时候我们可以通过这个内容类型进行采集过滤。
代码如下:
package httpclient; import java.io.IOException; import org.apache.http.HttpEntity; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; /** * Hello world! * */ public class App { public static void main( String[] args ) throws Exception, IOException { CloseableHttpClient httpclient = HttpClients.createDefault(); //创建httpclient HttpGet httpGet = new HttpGet("http://www.tuicool.com/"); //创建get 请求 httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36"); CloseableHttpResponse response = httpclient.execute(httpGet); //通过httpcleint 发送get 请求 if(response != null) { System.out.println(response.getStatusLine().getStatusCode()); HttpEntity httpentity = response.getEntity(); //获取响应 System.out.println(httpentity.getContentType().getValue()); //System.out.println(EntityUtils.toString(httpentity,"UTF-8")); //采用工具来将实体进行转换输出 } response.close(); httpclient.close(); } }
结果如下:

总结,上面我们采取的都静态的文本等,但是我们采集的时候,如果要采集图片怎么办,图片的获取处理方式如下:
比如:http://aimg2.tuicool.com/qm6Rre6.jpg!index 采集这个图片。
package httpclient; import java.io.File; import java.io.IOException; import java.io.InputStream; import org.apache.commons.io.FileUtils; import org.apache.http.HttpEntity; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; /** * Hello world! * */ public class App { public static void main( String[] args ) throws Exception, IOException { CloseableHttpClient httpclient = HttpClients.createDefault(); //创建httpclient HttpGet httpGet = new HttpGet("http://aimg2.tuicool.com/qm6Rre6.jpg!index"); //创建get 请求 httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36"); CloseableHttpResponse response = httpclient.execute(httpGet); //通过httpcleint 发送get 请求 if(response != null) { //System.out.println(response.getStatusLine().getStatusCode()); HttpEntity httpentity = response.getEntity(); //获取响应 if(httpentity != null) { System.out.println(httpentity.getContentType().getValue()); //判断内容的类型,因为我们要采集图片,所以要过滤掉其它内容. //接着,图片肯定要通过流的方式去读取. InputStream inputStream = httpentity.getContent(); //然后通过输入流,然后读取流,输出流,则可以转换读取我们的图片,流的复制. //在这里我们可以 通过Apache 提供的IO 工具流来直接进行流的复制. FileUtils.copyToFile(inputStream, new File("D://a.jpg")); //实际中是要拷贝真是的目录下面,并且图片的名称也是唯一的。 } //System.out.println(httpentity.getContentType().getValue()); //System.out.println(EntityUtils.toString(httpentity,"UTF-8")); //采用工具来将实体进行转换输出 } response.close(); httpclient.close(); } }
注意上面,需要导入io 包。
https://mvnrepository.com/artifact/commons-io/commons-io/2.5
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.5</version>
</dependency>
实例二 :上面我们演示了,图片的采集,和静态信息的采集,但是对于一些有防范的网站,一般大公司会有屏蔽信,即不让你长时间采集,一旦你长时间采集,则会进行封掉IP,那这个时候我们该怎么办,这个时候我们需要代码IP,先看下面的介绍:
在爬取网页的时候,有的目标站点有反爬虫机制,对于频繁访问站点以及规则性访问站点的行为,会采集屏蔽IP措施。
这时候,代理IP就派上用场了。
关于代理IP的话 也分几种 透明代理、匿名代理、混淆代理、高匿代理
1、透明代理(Transparent Proxy)
REMOTE_ADDR = Proxy IP
HTTP_VIA = Proxy IP
HTTP_X_FORWARDED_FOR = Your IP
透明代理虽然可以直接“隐藏”你的IP地址,但是还是可以从HTTP_X_FORWARDED_FOR来查到你是谁。
2、匿名代理(Anonymous Proxy)
REMOTE_ADDR = proxy IP
HTTP_VIA = proxy IP
HTTP_X_FORWARDED_FOR = proxy IP
匿名代理比透明代理进步了一点:别人只能知道你用了代理,无法知道你是谁。
还有一种比纯匿名代理更先进一点的:混淆代理,见下节。
3、混淆代理(Distorting Proxies)
REMOTE_ADDR = Proxy IP
HTTP_VIA = Proxy IP
HTTP_X_FORWARDED_FOR = Random IP address
如上,与匿名代理相同,如果使用了混淆代理,别人还是能知道你在用代理,但是会得到一个假的IP地址,伪装的更逼真:-)
4、高匿代理(Elite proxy或High Anonymity Proxy)
REMOTE_ADDR = Proxy IP
HTTP_VIA = not determined
HTTP_X_FORWARDED_FOR = not determined
可以看出来,高匿代理让别人根本无法发现你是在用代理,所以是最好的选择。
一般我们搞爬虫 用的都是 高匿的代理IP;
那代理IP 从哪里搞呢 很简单 百度一下,你就知道 一大堆代理IP站点。 一般都会给出一些免费的,但是花点钱搞收费接口更加方便;
httpClient使用代理IP代码:
package httpclient; import java.io.IOException; import org.apache.http.HttpEntity; import org.apache.http.HttpHost; import org.apache.http.client.config.RequestConfig; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; /** * Hello world! * */ public class App { public static void main( String[] args ) throws Exception, IOException { CloseableHttpClient httpclient = HttpClients.createDefault(); //创建httpclient HttpGet httpGet = new HttpGet("https://www.taobao.com/"); //创建get 请求 HttpHost proxy = new HttpHost("115.202.167.56",808); RequestConfig config = RequestConfig.custom().setProxy(proxy).build(); //设置代理IP httpGet.setConfig(config); httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36"); CloseableHttpResponse response = httpclient.execute(httpGet); //通过httpcleint 发送get 请求 if(response != null) { //System.out.println(response.getStatusLine().getStatusCode()); HttpEntity httpentity = response.getEntity(); //获取响应 if(httpentity != null) { System.out.println(httpentity.getContentType().getValue()); System.out.println(EntityUtils.toString(httpentity,"UTF-8")); //采用工具来将实体进行转换输出 //System.out.println(httpentity.getContentType().getValue()); //判断内容的类型,因为我们要采集图片,所以要过滤掉其它内容. //接着,图片肯定要通过流的方式去读取. //InputStream inputStream = httpentity.getContent(); //然后通过输入流,然后读取流,输出流,则可以转换读取我们的图片,流的复制. //在这里我们可以 通过Apache 提供的IO 工具流来直接进行流的复制. //FileUtils.copyToFile(inputStream, new File("D://a.jpg")); //实际中是要拷贝真是的目录下面,并且图片的名称也是唯一的。 } //System.out.println(httpentity.getContentType().getValue()); //System.out.println(EntityUtils.toString(httpentity,"UTF-8")); //采用工具来将实体进行转换输出 } response.close(); httpclient.close(); } }
通过代理IP,测试结果如下:

其它知识点:
如连接超时时间设置,读取内容超时时间设置等。
实例三:连接超时和内容超时
httpClient在执行具体http请求时候 有一个连接的时间和读取内容的时间;
HttpClient连接时间
所谓连接的时候 是HttpClient发送请求的地方开始到连接上目标url主机地址的时间,理论上是距离越短越快,
线路越通畅越快,但是由于路由复杂交错,往往连接上的时间都不固定,运气不好连不上,HttpClient的默认连接时间,据我测试,
默认是1分钟,假如超过1分钟 过一会继续尝试连接,这样会有一个问题 假如遇到一个url老是连不上,会影响其他线程的线程进去,说难听点,
就是蹲着茅坑不拉屎。所以我们有必要进行特殊设置,比如设置10秒钟 假如10秒钟没有连接上 我们就报错,这样我们就可以进行业务上的处理,
比如我们业务上控制 过会再连接试试看。并且这个特殊url写到log4j日志里去。方便管理员查看。
HttpClient读取时间
所谓读取的时间 是HttpClient已经连接到了目标服务器,然后进行内容数据的获取,一般情况 读取数据都是很快速的,
但是假如读取的数据量大,或者是目标服务器本身的问题(比如读取数据库速度慢,并发量大等等..)也会影响读取时间。
同上,我们还是需要来特殊设置下,比如设置10秒钟 假如10秒钟还没读取完,就报错,同上,我们可以业务上处理。
HttpClient给我们提供了一个RequestConfig类 专门用于配置参数比如连接时间,读取时间以及前面讲解的代理IP等。
主要通过:
RequestConfig config=RequestConfig.custom() .setConnectTimeout(5000) .setSocketTimeout(5000) .build(); httpGet.setConfig(config);
到此,httpclient 相关的一些基本知识就学到这里了,如果深入学习,可以参考httpclient的书籍深入.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端