[数据库系列之MySQL] Mysql整体架构浅析一
一、引言
平时我们在做Java系统时,一般情况下都会连接到一个MySQL数据库上去,执行各种增删改查的语句。大部分的Java工程师对MySQL的了解和掌握程度,大致就停留在这么一个阶段:对MySQL可以建库建表建索 引,然后就是执行增删改查去更新和查询里面的数据!如下图所示:
但是实际在使用MySQL的过程中,大家总会遇到这样那样的一些问题,比如死锁异常、SQL性能太差、异常报错,等等。大部分Java工程师在遇到MySQL数据库的一些问题时,一般都会上网百度、谷歌,然后自己尝试捣鼓着解决一下,最后解决了问题,自己 可能也没搞明白里面的原理。但是具体MySQL底层原理是什么呢?如果作为一名架构师我想是有必要去深入了解一下的,接下来我们就一起学习吧。
二、MYSQL Server应用层架构
我们知道MYSQL 架构上分为应用层架构和存储引擎层架构,我们先来学习应用层架构,首先我们看一张应用层架构的整体设计图,让我们先有一个整体的认知,然后我们在来逐一拆解。
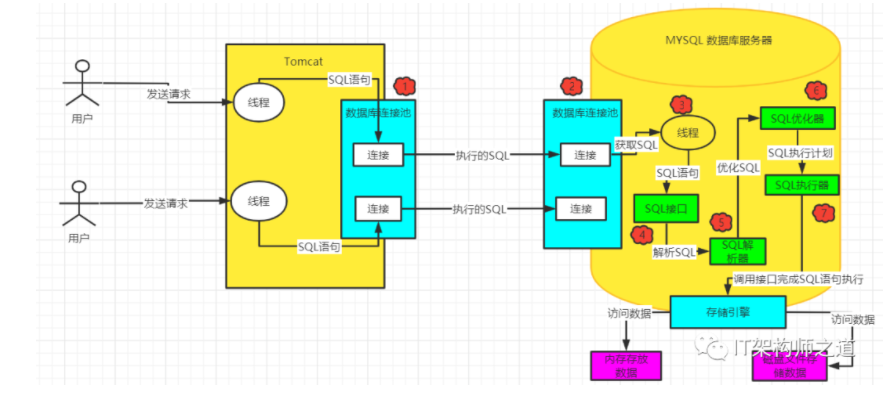
上图告诉我们,我们的系统应用访问我们的MYSQL进行增删改查的操作并不是简单的直接访问了SQL,是经历了很多步骤,比如SQL的解析,SQL的优化、SQL的执行等等才完成SQL的逻辑操作,下面我们来逐个讲解内容。
三、应用端数据库连接池
为什么在应用端会增加数据库连接池,而不是我们上面说的直接发送请求连接到数据库端?首先,我们知道如果要在Java系统中去访问一个MySQL数据库,必须得在系统的依赖中加入一个MySQL驱动,有了这个MySQL驱动才能跟MySQL数据库建立连接,然后执行各种各样的SQL语句,因为这个MySQL驱动,他会在底层跟数据库建立网络连接,有网络连接,接着才能去发送请求给数据库服务器。然后当我们跟数据库之间有了网络连接之后,我们的Java代码才能基于这个连接去执行各种各样的增删改查SQL语句。问题来了,我们上图可以看到用户的访问是多个的,Tomcat也是多个线程来对接的,如果说每一个线程过来了之后,我们都使用MYSQL驱动的一个连接来应对肯定是不行的,因为会竞争这一个MYSQL连接那性能可想而知,那我们就要多个连接了,但是多个连接,如果来一个我们就创建一个连接,然后使用完成之后销毁它,好像没有什么问题,可以解决了我们应对过来的多个连接问题。
如果Tomcat中的每个线程在每次访问数据库的时候,都基于MySQL驱动去创建一个数据库连接,然后执行SQL语句,然后执行完 之后再销毁这个数据库连接,这样行不行呢?可能Tomcat中上百个线程会并发的频繁创建数据库连接,执行SQL语句,然后频繁的销毁数据库连接。上述这个过程反复循环执行,大家觉得可行吗?这也是非常不好的,因为每次建立一个数据库连接都很耗时,好不容易建立好了连接,执行完了SQL语句,你还把数据库连接给销毁了,下一次再重新建立数据库连接,那肯定是效率很低下的!
所以一般我们必须要使用一个数据库连接池,也就是说在一个池子里维持多个数据库连接,让多个线程使用里面的不同的数据库连接去执行SQL语句,然后执行完SQL语句之后,不要销毁这个数据库连接,而是把连接放回池子里,后续还可以继续使用。基于这样的一个数据库连接池的机制,就可以解决多个线程并发的使用多个数据库连接去执行SQL语句的问题,而且还避免了数据库连接使用完之后就销毁的问题。
常见的数据库连接池有DBCP,C3P0,Druid,等等,大家如果有兴趣的话,可以去搜索一下数据库连接池的使用例子和代码,甚至探索一下数据库连接池的底层原理。
四、MYSQL端数据库连接池
现在我们已经知道,我们任何一个系统都会有一个数据库连接池去访问数据库,也就是说这个系统会有多个数据库连接,供多线程并发的使用。同时我们可能会有多个系统同时去访问一个数据库,这都是有可能的。
肯定会有很多系统要与MySQL数据库建立很多个连接,那么MySQL也必然要维护与系统之间的多个连接,所以MySQL架构体系中的第一个环节,就是连接池。实际上MySQL中的连接池就是维护了与系统之间的多个数据库连接。除此之外,你的系统每次跟MySQL建立连接的 时候,还会根据你传递过来的账号和密码,进行账号密码的验证,库表权限的验证。
五、SQL接口:负责处理接收到的SQL语句
当我们的系统只要能从数据库连接池获取到一个数据库连接之后,我们就可以执行增删改查的SQL语句了,但是现在假设我们的数据库服务器的连接池中的某个连接接收到了网络请求,假设就是一条SQL语句,那么大家先思考一个问题,谁负责从这个连接中去监听网络请求?谁负责从网络连接里把请求数据读取出来?
那就是网络连接必须得分配给一个线程去进行处理,由一个线程来监听请求以及读取请求数据,比如从网络连接中读取和解析出来一条我们的系统发送过去的SQL语句。当MySQL内部的工作线程从一个网络连接中读取出来一个SQL语句之后,此时会如何来执行这个SQL语句呢?如果你要去执行这个SQL语句,去完成底层数据的增删改查,那这就是一项极度复杂的任务了!
所以MySQL内部首先提供了一个组件,就是SQL接口(SQL Interface),他是一套执行SQL语句的接口,专门用于执行我们发送给MySQL的那些增删改查的SQL语句因此MySQL的工作线程接收到SQL语句之后,就会转交给SQL接口去执行。
六、查询解析器:让MySQL能看懂SQL语句
问题:SQL接口怎么执行SQL语句呢?你直接把SQL语句交给MySQL,他能看懂和理解这些SQL语句吗?
SQL语句,我们用人脑是直接就可以处理一下,只要懂SQL语法的人,立马大家就知道他是什么意思,但是MySQL自己本身也是一个系统,是一个数据库管理系统,他没法直接理解这些SQL语句!所以此时有一个关键的组件要出场了,那就是查询解析器。所谓的SQL解析,就是按照既定的SQL语法,对我们按照SQL语法规则编写的SQL语句进行解析,然后理解这个SQL语句要干什么事情。
七、查询优化器:选择最优的查询路径
当我们通过解析器理解了SQL语句要干什么之后,接着会找查询优化器(Optimizer)来选择一个最优的查询路径。查询优化器他会针对你编写的几十行、几百行甚至上千行的复杂SQL语句生成查询路径树,然后从里面选择一条最优的查询路径出来。相当于他会告诉你,你应该按照一个什么样的步骤和顺序,去执行哪些操作,然后一步一步的把SQL语句就给完成了。
八、执行器:根据执行计划调用存储引擎的接口
接下来的问题是优化的查询路径出来之后谁来负责调度的问题即和存储引擎打交道的问题,那么就是执行器了,执行器产生执行计划调度存储引擎。
执行器会根据优化器选择的执行方案,去调用存储引擎的接口按照一定的顺序和 步骤,就把SQL语句的逻辑给执行了。
九、调用存储引擎接口,真正执行SQL语句
查询优化器选择的最优查询路径,也就是你到底应该按照一个什么样的顺序和步骤去执行这个SQL语句的路径,由执行器生成执行计划交给底层的存储引擎去真正的执行。这个存储引擎是MySQL的架构设计中很有特色的一个环节。
真正在执行SQL语句的时候,要不然是更新数据,要不然是查询数据,那么数据你觉得存放在哪里?
数据库自己就是一个编程语言写出来的系统而已,然后启动之后也是一个进程,执行他里面的各种代码,也就是我们上面所说 的那些东西。所以对数据库而言,我们的数据要不然是放在内存里,要不然是放在磁盘文件里,没什么特殊的地方!
我们已经知道一个SQL语句要如何执行了,但是我们现在怎么知道哪些数据在内存里?哪些数据在磁盘 里?我们执行的时候是更新内存的数据?还是更新磁盘的数据?我们如果更新磁盘的数据,是先查询哪个磁盘文件,再更新哪 个磁盘文件?
所以这个时候就需要存储引擎了,存储引擎其实就是执行SQL语句的,他会按照一定的步骤去查询内存缓存数据,更新磁盘数 据,查询磁盘数据,等等,执行诸如此类的一系列的操作。
MySQL的架构设计中,SQL接口、SQL解析器、查询优化器其实都是通用的,他就是一套组件而已。
但是存储引擎的话,他是支持各种各样的存储引擎的,比如我们常见的InnoDB、MyISAM、Memory等等,我们是可以选择 使用哪种存储引擎来负责具体的SQL语句执行的。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号