Python 高级特性(4)- 生成器 generator
列表生成式
通过上一篇介绍 列表生成式文章可以知道,它可以快速创建我们需要的列表
局限性
- 受内存限制,列表生成式创建的列表的容量肯定有限的
- 不仅占用很大的存储空间,如果我们仅仅需要访问前几个元素,那后面绝大多数元素占用的空间都白白浪费了
什么是生成器
- 若列表元素可以按照某种算法算出来,就可以在循环的过程中不断推算出后续需要用的元素,而不必创建完整的 list,从而节省大量的空间
- 边循环边计算的机制,叫生成器(generator)
最简单的生成器

L = [x * x for x in range(10)] print(L) print(type(L)) L = (x * x for x in range(10)) print(L) print(type(L)) # 输出结果 [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] <class 'list'> <generator object <genexpr> at 0x000001D607541EB8> <class 'generator'>
只要把一个列表生成式的 [] 改成 () ,就创建了一个 generator
如何打印生成器每个元素
直接简单 for 循环
L2 = (x * x for x in range(10)) for i in L2: print(i)
next() 方法
可以获取 generator 的下一个元素
基本不会使用这个
L2 = (x for x in range(10)) print(next(L2)) print(next(L2)) print(next(L2)) print(next(L2)) print(next(L2)) print(next(L2)) # 输出结果 0 1 2 3 4 5
还有另一个方法 .__next()__
L2 = (x for x in range(10)) print(L2.__next__()) print(L2.__next__()) print(L2.__next__()) print(L2.__next__()) print(L2.__next__()) print(L2.__next__()) # 输出结果 0 1 2 3 4 5
生成器的迭代原理
generator 能够迭代的关键就是 next() 方法,通过重复调用 next() 方法,直到捕获一个异常
yield 函数
- 带有 yield 的函数不再是一个普通函数,而是一个生成器 generator
- yield 相当于 return 返回一个值,并且记住这个返回值的位置,下次迭代时,代码会从 yield 的下一条语句开始执行,直到函数结束或遇到下一个 yield
普通的斐波拉契数列
1, 1, 2, 3, 5, 8, 13, 21, 34, ...,除第一个和第二个数外,任意一个数都可由前两个数相加得到
# 斐波拉契数列 def fib(max): n, a, b = 0, 0, 1 while n < max: print(b) a, b = b, a + b n = n + 1 fib(8) # 输出结果 1 1 2 3 5 8 13 21
它和生成器很像,知道第一个元素值,就可以推算后面的任意个元素了
是用 yield 的斐波拉契数列
def fib(max): n, a, b = 0, 0, 1 while n < max: yield b a, b = b, a + b n = n + 1 fib(8) print(fib(8)) # 输出结果 1 1 2 3 5 8 13 21 <generator object fib at 0x00000246A5001EB8>
生成器的执行流程
函数是顺序执行,遇到 return 或者最后一行执行完就返回
而生成器的执行流程是
- 每次调用 next() 或 for 循环的时候执行,遇到 yield 就返回
- 一个生成器里面可以有多个 yield
- 再次执行时从上次返回的 yield 语句处继续执行
# 执行流程 def odd(): print('step 1') yield 1 print('step 2') yield 3 print('step 3') yield 5 L = odd() for i in L: print(i) # 输出结果 step 1 1 step 2 3 step 3 5
生成器的工作原理
- 它是在 for 循环过程中不断计算下一个元素,并在适当的条件结束 for 循环
- 对于函数改成的 generator 来说,,遇到 return 语句或者执行到函数最后一行时,就是结束 generator 的指令,for 循环随之结束
生成器的优点
在不牺牲过多速度情况下,释放了内存,支持大数据量的操作
不使用生成器下的代码
from tqdm import tqdm a = [] for i in tqdm(range(10000000)): temp = ['你好'] * 2000 a.append(temp) for ele in a: continue
运行结果

可以看到开始运行大数据量循环代码后,内存暴增,并且占满了电脑所有内存,很明显这是不合理且不可接受的!
使用生成器的代码
def test(): for i in tqdm(range(10000000)): temp = ['你好'] * 2000 yield temp a = test() for ele in a: continue
运行结果
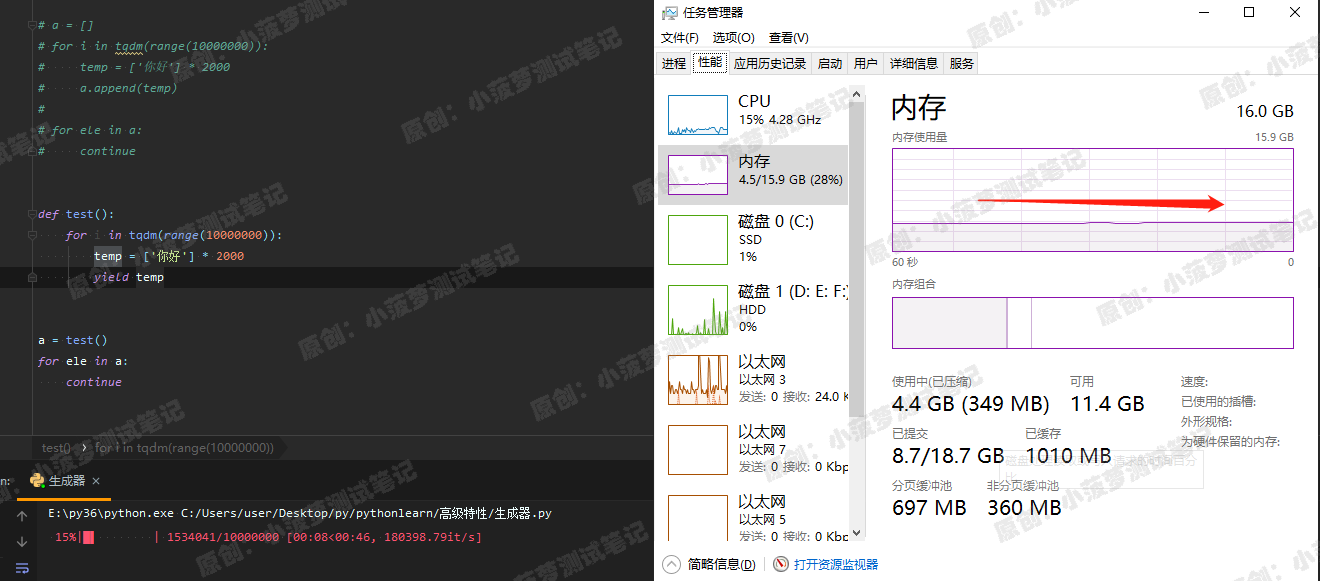
内存丝滑的很,奈斯!
生成器的应用场景
当然就是需要处理大数据量的场景了,比如一个文件有几百万行数据,或者有几百万个文件需要分别读取处理
标签:
Python


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具
2020-04-16 Pytest系列(19)- 我们需要掌握的allure特性
2020-04-16 Pytest系列(18)- 超美测试报告插件之allure-pytest的基础使用
2020-04-16 Pytest系列(17)- pytest-xdist分布式测试的原理和流程