性能测试必备知识(4)- 使用 stress 和 sysstat 分析平均负载过高的场景
做性能测试的必备知识系列,可以看下面链接的文章哦
https://www.cnblogs.com/poloyy/category/1806772.html
stress 介绍
Linux 系统压力测试工具,这里通过异常进程模拟平均负载升高的场景
来看看 stress 命令行参数的讲解
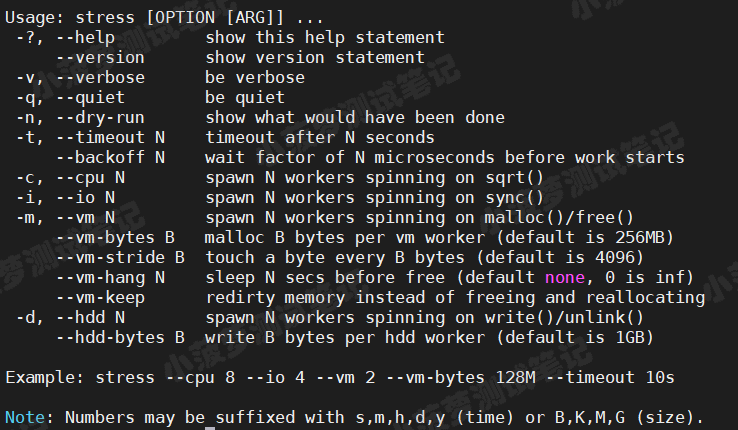
| 字段 | 含义 |
|---|---|
| -?、--help | 帮助文档 |
| --version、-v | 版本号 |
| -q | 退出 |
| -n | 显示已完成指令的情况 |
| -t N、--timeout N | 运行 N 秒后停止 |
| --backoff N | 等待 N 微秒后开始运行 |
| -c N、--cpu N |
|
| -i N、--io N |
|
| -m N、--vm N |
|
|
--vm-bytes B |
指定 malloc() 时内存的字节数,默认256MB |
| --vm-hang N | 指定执行 free() 前等待的秒数 |
| -d N、 --hdd N |
|
| --hdd-bytes B |
每个 hdd worker 写入 B 字节(默认为1GB) |
Numbers may be suffixed with s,m,h,d,y (time) or B,K,M,G (size)
时间单位可以为秒 s,分m,小时h,天d,年y,文件大小单位可以为 K,M,G
sysstat 介绍
- 包含了常用的 Linux 性能工具,用来监控和分析系统的性能
- 接下来会用到 mpstat 和 pidstat 两个命令
- 后面用单独一篇详细讲解里面包含的所有命令
mpstat
- 常用的多核 CPU 性能分析工具
- 实时查看每个 CPU 的性能指标以及所有 CPU 的平均指标
pidstat
- 常用的进程性能分析工具
- 实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标
安装两个工具
提供百度云盘链接
链接:https://pan.baidu.com/s/1YENSYaGw7Ar1Z8hf8CXGqA
提取码:2tpc
放到 Linux 下的某个目录
解压
tar -zxvf sysstat-12.1.5.tar.gz tar -zxvf stress-1.0.4.tar.gz
分别进入解压后的两个文件夹执行以下命令
./configure make&&make install
平均负载和 CPU 使用率的实际栗子
前言
- 前面一篇文章也讲到了平均负载和 CPU 使用率的三个场景,接下来我们分别对这三个场景举例子
- 需要打开三个终端访问同一个 Linux 机器哦
- 我的 Linux 是虚拟机,2个cpu,2核
CPU 密集型进程
第一个终端
在第一个终端运行 stress 命令,模拟一个 CPU 使用率 100% 的场景
stress -c 1 -t 600
![]()
第二个终端
运行 uptime 查看系统平均负载情况,-d 参数表示高亮显示变化的区域
watch -d uptime

可以看到,1 分钟的平均负载会慢慢增加到 1.00
第三个终端
运行 mpstat 查看 CPU 使用率的变化情况
mpstat -P ALL 5
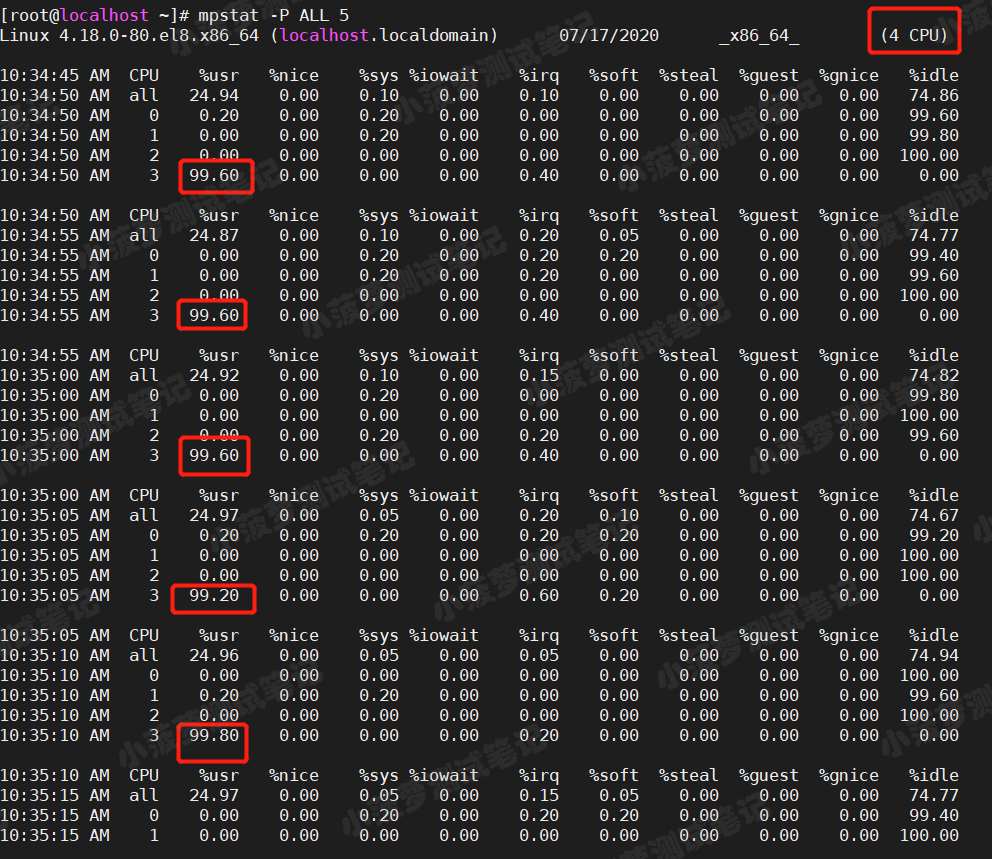
可以看出
- 仅有一个 CPU 的使用率接近 100%,但它的 iowait 只有 0
- 这说明,平均负载的升高正是由于 CPU 使用率为 100%
接下来,就要排查是哪个进程导致 CPU 的使用率这么高的
使用 pidstat 命令
间隔 5 秒后输出一组数据
pidstat -u 5 1
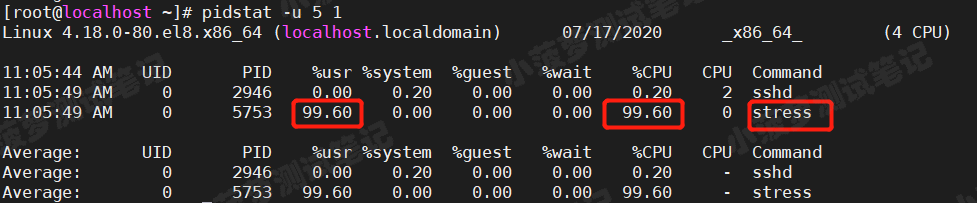
从这里可以明显看到,stress 进程的 CPU 使用接近 100%
I/O 密集型进程
第一个终端
运行 stress 命令,但这次模拟 I/O 压力,即不停地执行 sync()
![]()
第二个终端
运行 uptime 查看系统平均负载情况,-d 参数表示高亮显示变化的区域
watch -d uptime

可以看到,1 分钟的平均负载也会慢慢增加到 1.00
第三个终端
运行 mpstat 查看 CPU 使用率的变化情况
mpstat -P ALL 5 1
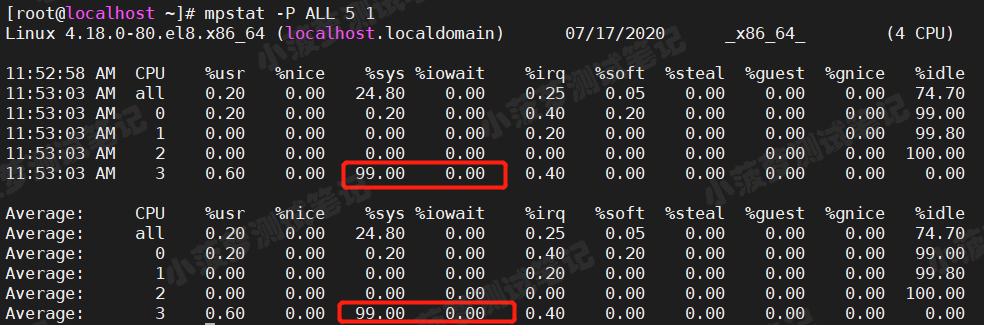
灵魂拷问
其实 iowait 并没有上去,反而还是系统态(%sys)升高了,这是怎么回事?难道是工具的问题?
回答
- iowait 无法升高是因为案例中 stress -i 使用的是 sync() 系统调用,它的作用是刷新缓冲区内存到磁盘中
- 对于新安装的虚拟机,缓冲区可能比较小,无法产生大的io压力
- 这样大部分都是系统调用的消耗了
- 所以,只看到系统 CPU 使用率升高
解决办法
使用 stress 的另一个参数 -d ,含义上面已经说了哦
stress --hdd 1 -t 600 --hdd-bytes 4G
再通过 mpstat 看看指标
mpstat -P ALL 5
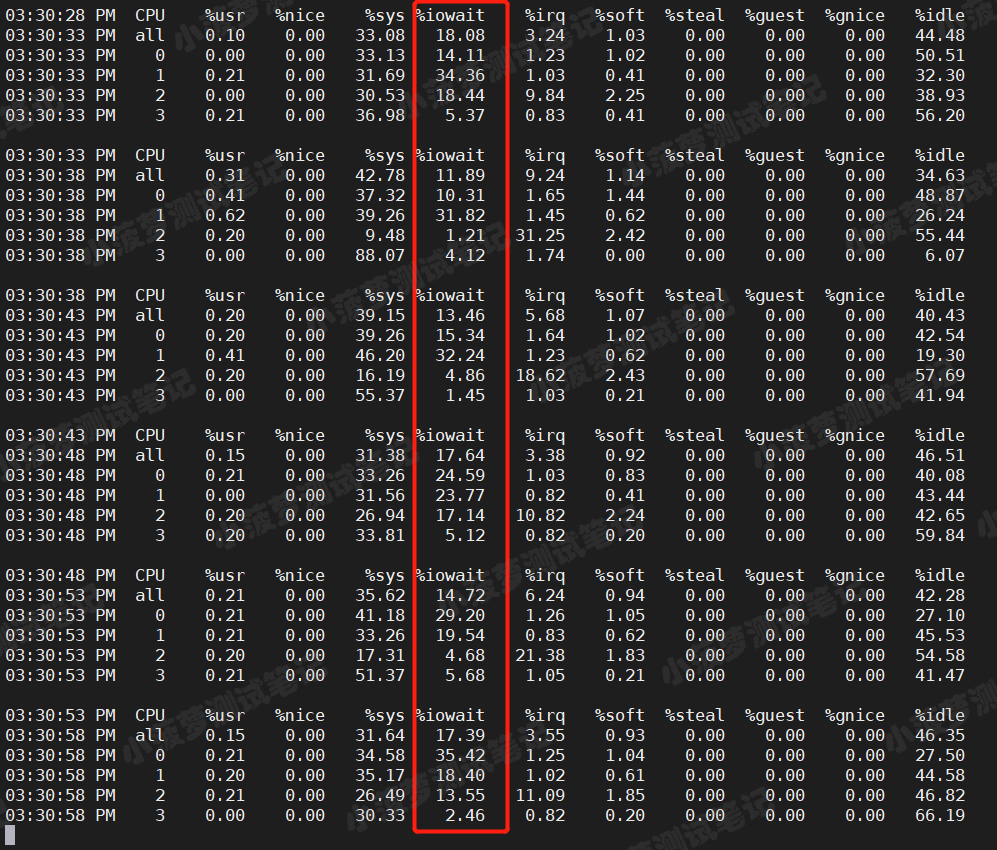
可以看到
- iowait 是明显升高了,虽然我们的 CPU 使用率也较高
- 当做了几次尝试之后,包括启动了 2个、4个进程,发现 CPU 使用率仍然保持在 30%+,而 iowait 则不断升高,最高可达到40%+,而且平均负载也在不断升高
- 所以可以看出平均负载的升高,很大原因是因为 iowait 的不断升高
接下来,就要排查是哪个进程导致 iowait 这么高了
使用 pidstat 命令
间隔 5 秒后输出一组数据,收集 10 次,查看最后的平均值
pidstat -u 5 10
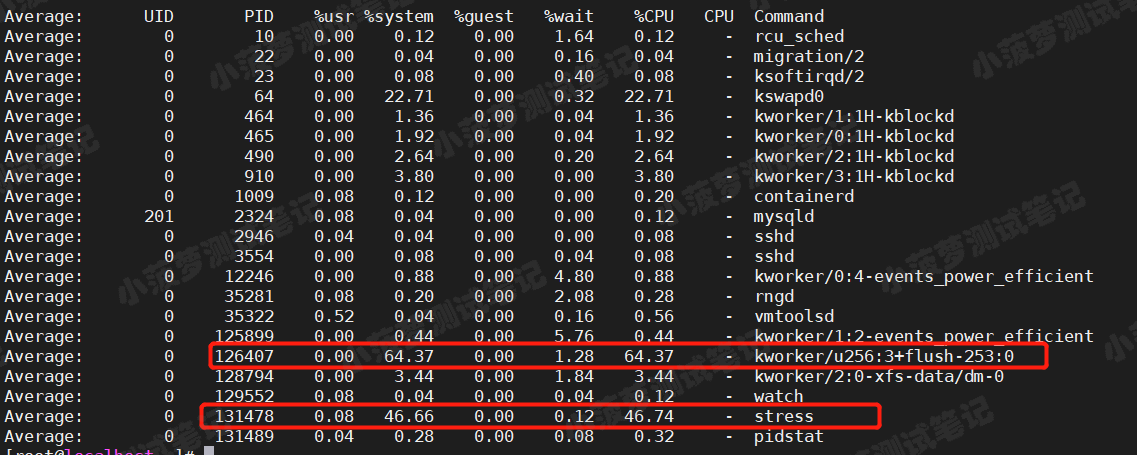
可以看到
kworker 内核进程 和 stress 进程的 CPU 使用率都是偏高的
大量进程的场景
目的
当系统中运行进程超出 CPU 运行能力时,就会出现等待 CPU 的进程
第一个终端
这次模拟 8 个进程
stress -c 8 -t 600

第二个终端
运行 uptime 查看系统平均负载情况,-d 参数表示高亮显示变化的区域
watch -d uptime

我的系统只有 4 个 CPU,比 8 个进程少得多,CPU 处于严重的过载状态,平均负载已经超过 8 了
第三个终端
可以直接通过 pidstat 来查看进程的情况了,每隔 5s 收集一次,收集 5 次,看平均值
pidstat -u 5 5
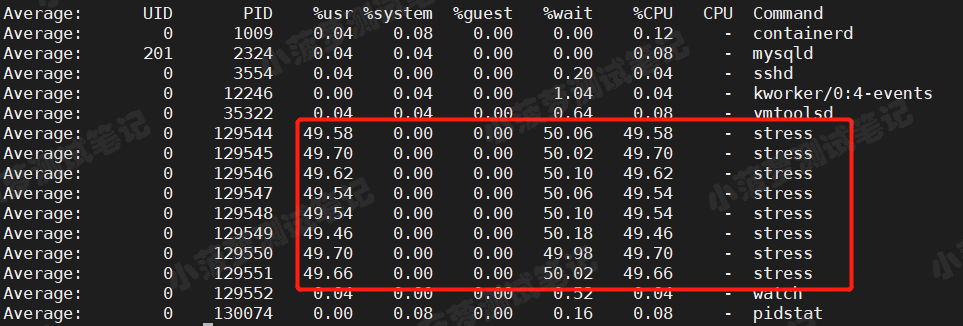
可以看到
- 8 个进程在竞争 4 个 CPU
- 每隔进程等待 CPU 的时间(%wait)高达 50%
- 这些超出 CPU 计算能力的进程,导致 CPU 过载
对于平均负载的一个理解和总结
- 平均负载提供了一个快速查看系统整体性能的手段,反映了整的负载情况
- 但只看平均负载本身,我们并不能直接发现到底是哪里出现了瓶颈
平均负载过高的分析排查思路
- 有可能是 CPU 即密集型进程导致的
- 平均负载过高不代表 CPU 使用率高,也有可能是 I/O 更密集了
- 当发现平均负载过高时,可以通过 mpstat、pidstat 等工具,辅助分析负载的来源
通俗总结
平均负载过高是出现性能瓶颈的表现,分析瓶颈产生的源头和原因,需要通过各类工具

 浙公网安备 33010602011771号
浙公网安备 33010602011771号