全网最易懂的正则表达式教程(8 )- 贪婪模式和非贪婪模式
正则详细教程系列可以看此链接的文章哦
https://www.cnblogs.com/poloyy/category/1796055.html
前言
- 学过正则表达式的童鞋肯定都知道贪婪模式和非贪婪模式,这是个重难点!
- 今天我们就来仔细讲讲它们的区别和具体实例
为什么会有贪婪与非贪婪模式?
首先,贪婪模式和非贪婪模式跟前面讲到的量词密切相关,我们先再来看看有哪些量词
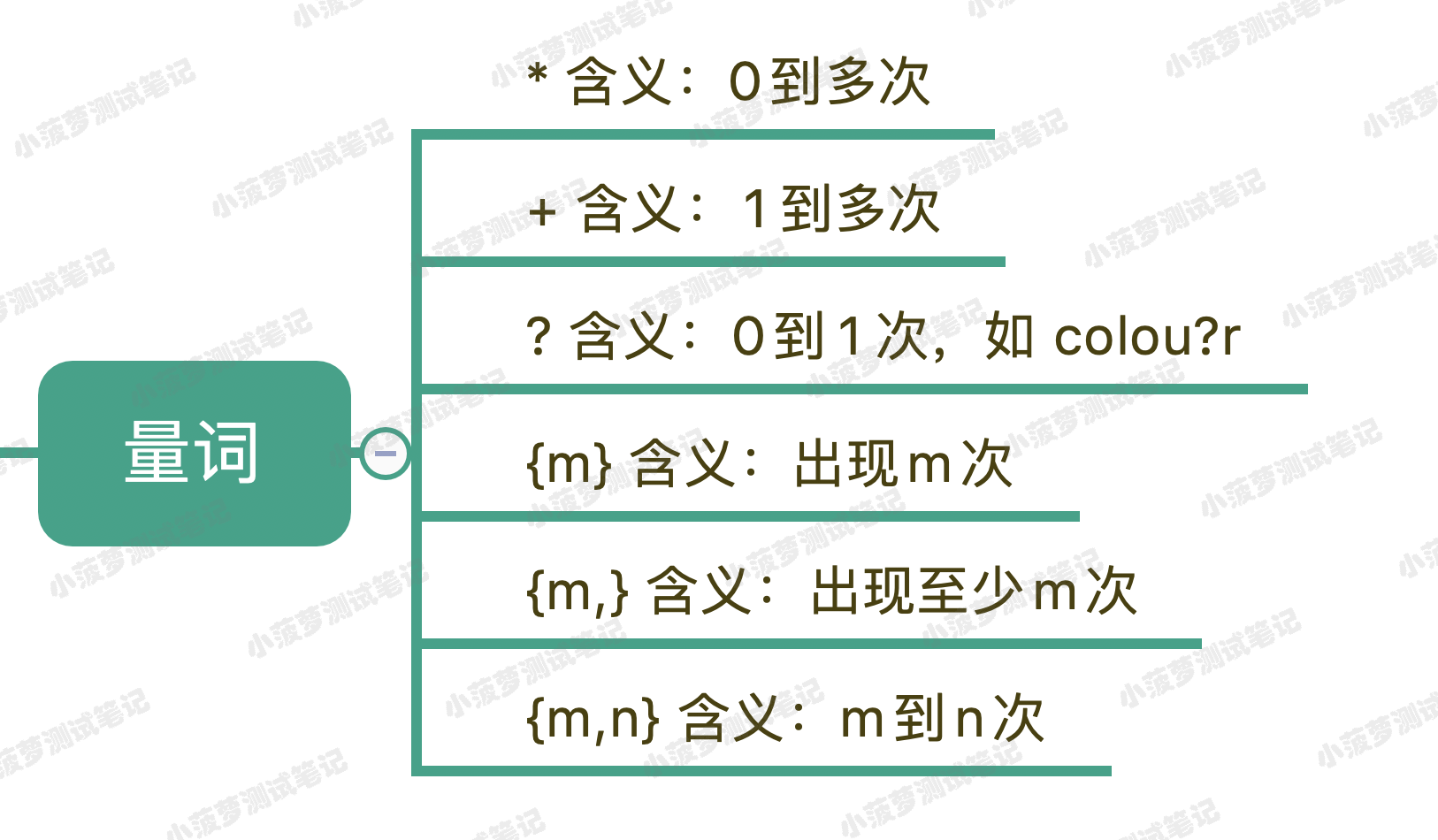
* + ? 通过 {m,n} 的等价写法

通过 * 和 + 引入贪婪、非贪婪模式
+ 的栗子
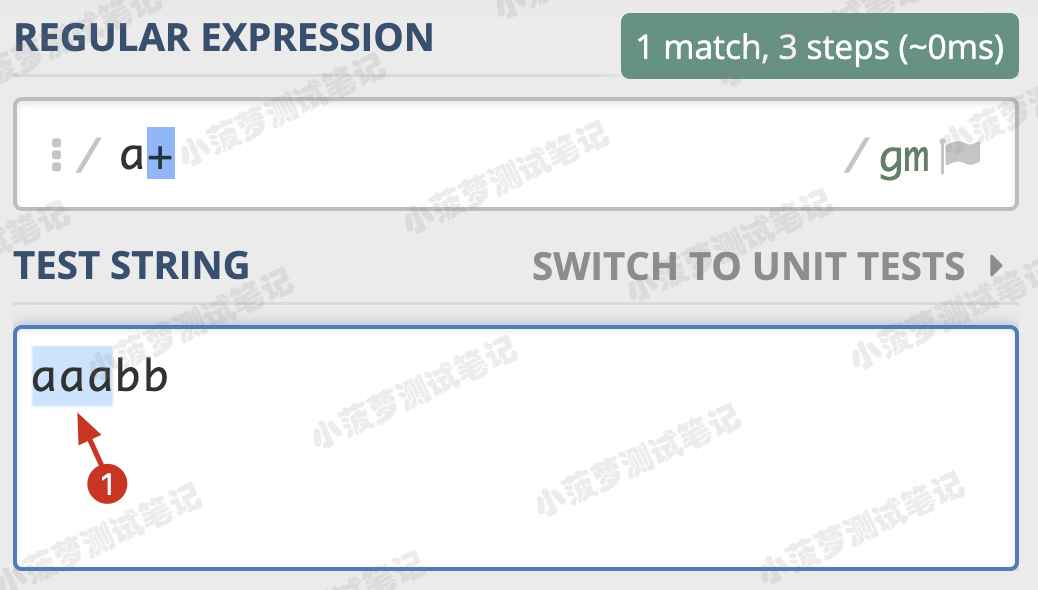
只匹配一个结果
* 的栗子
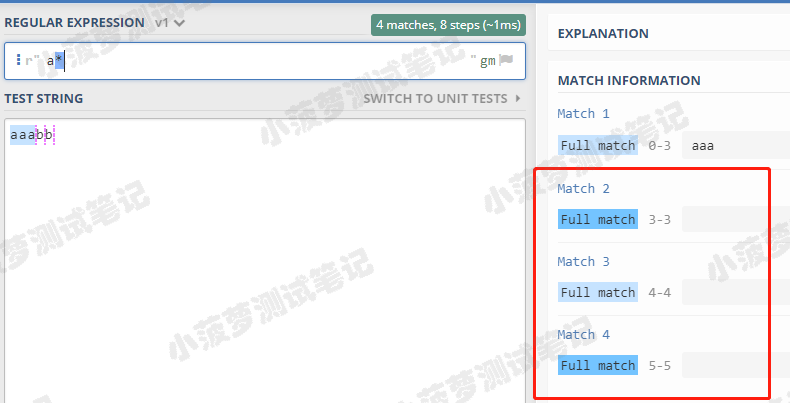
可以看到会匹配了三个空字符串,我们再通过 Python 代码看看输出结果
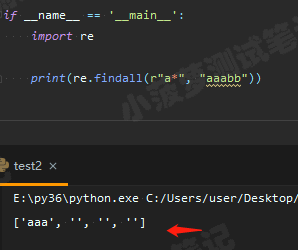
的确是会有三个空字符串
为什么会匹配到三个空字符串
因为 * 代表 0 到多次,匹配 0 次就是空字符串
小伙伴们你是否有很多个 ?
aaa 之间的空字符串咋没匹配上呢?
这就要说到我们的贪婪、非贪婪模式了
引入贪婪、非贪婪模式
- 这两种模式都必须满足匹配次数的要求才能匹配上
- 贪婪模式,简单说就是尽可能进行最长匹配
- 非贪婪模式,则会尽可能进行最短匹配
- 正是这两种模式产生了不同的匹配结果
贪婪模式(Greedy)
在正则中,表示次数的量词默认是贪婪的,在贪婪模式下,会尝试尽可能最大长度去匹配
字符串 aaabb 中使用正则 a* 的匹配过程

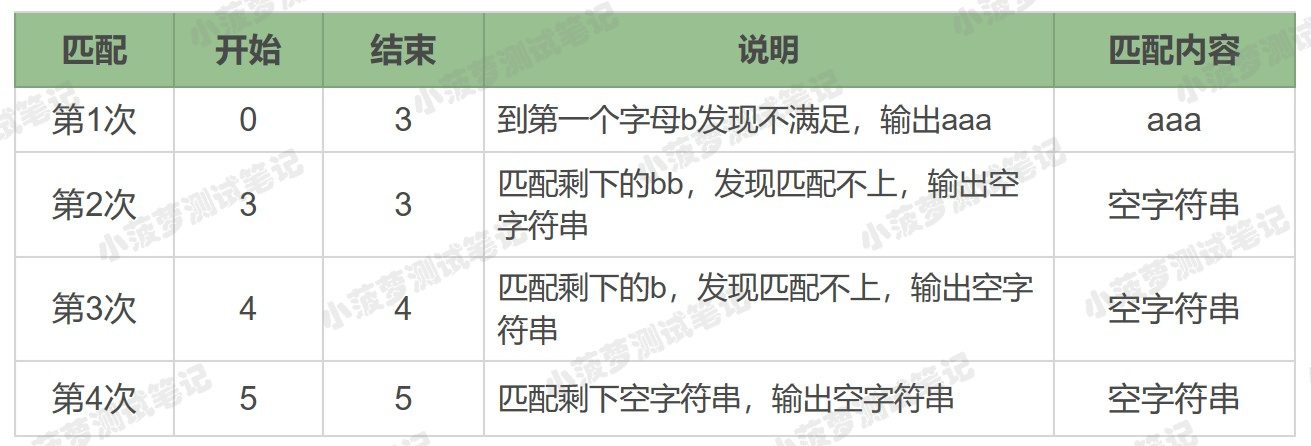
分析
a* 在匹配开头的 a 时,会尽量匹配更多的 a,直到第一个 b 不满足要求为止,匹配上三个 a,后面每次匹配时都得到空字符串
非贪婪匹配(Lazy)
如何从贪婪模式变成非贪婪模式呢
在量词后面加上 ? ,正则就变成了 a*?
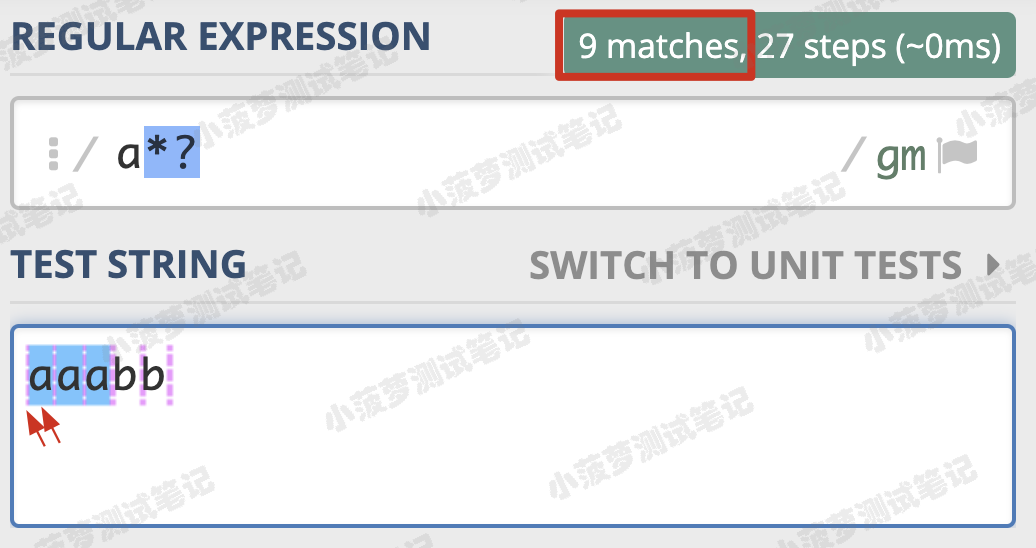
再来看一个栗子
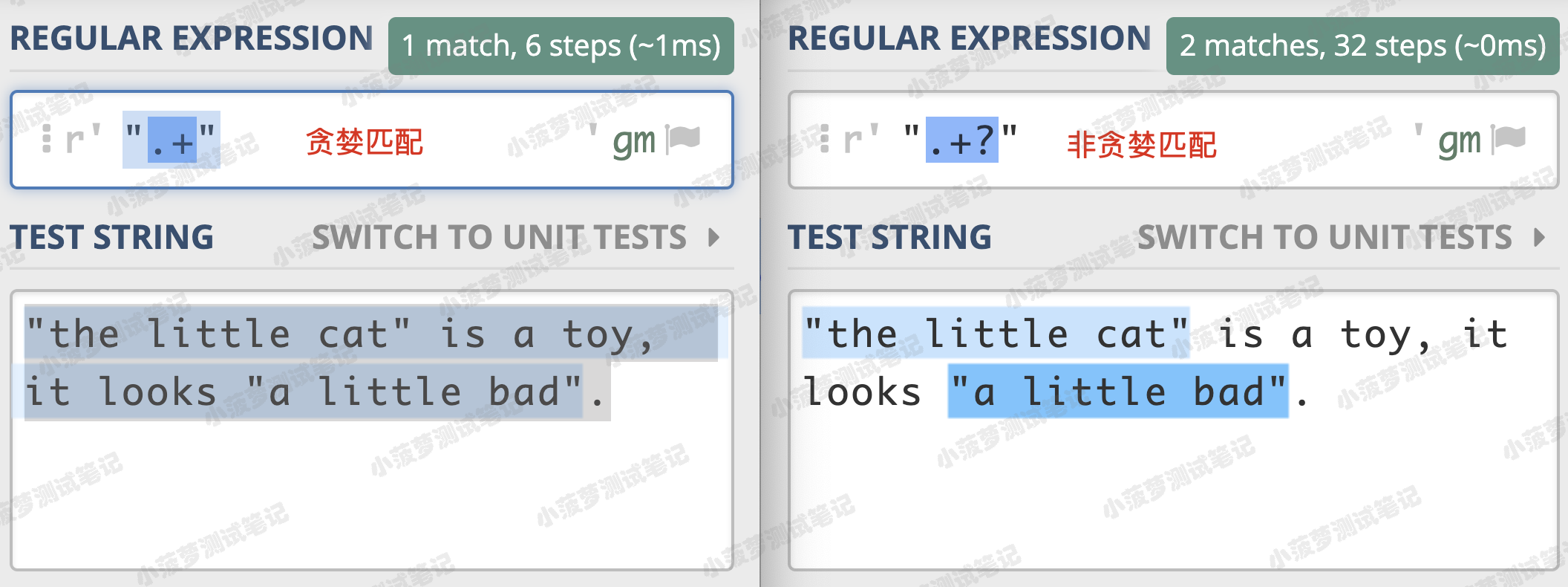
贪婪匹配:匹配上从第一个 " 到最后一个 " 之间的所有内容
非贪婪匹配:找到符合要求的结果
贪婪匹配和非贪婪匹配的区别

独占模式(Possessive)
前提
这一小节基本都搬了《正则表达式入门课》的内容
什么是独占模式
- 贪婪模式和非贪婪模式,都需要发生回溯才能完成相应的功能
- 但是在一些场景下,我们不需要回溯,匹配不上返回失败就好了
- 因此正则中还有另外一种模式,独占模式,它类似贪婪匹配,但匹配过程不会发生回溯,因此在一些场合下性能会更好
什么是回溯
正则是贪婪
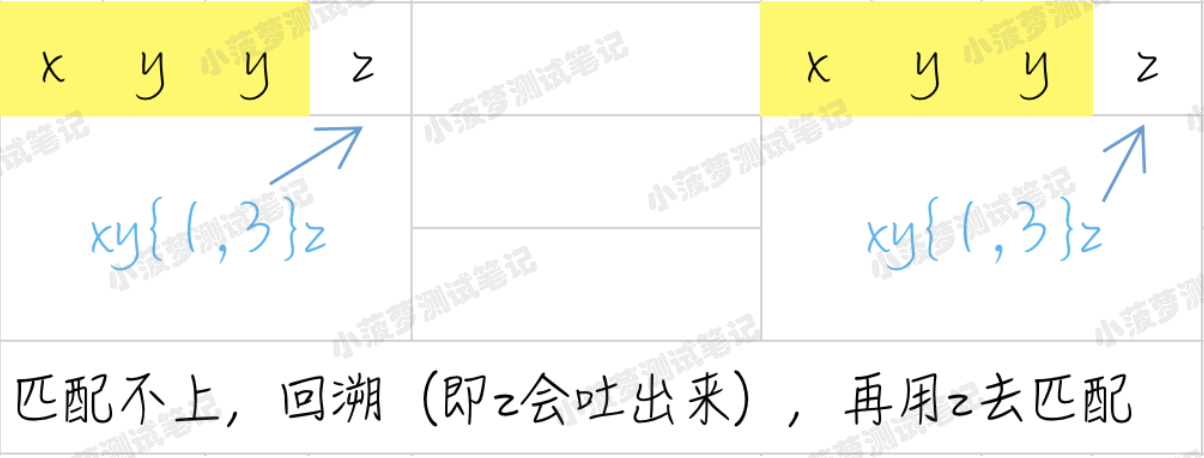
正则:xy{1,3}z
文本:xyyz
匹配结果:xyyz
匹配过程
- {1,3} 会尽可能长地去匹配匹配过程
- 当匹配完 xyy 后,由于 y 要尽可能匹配最长,即三
- 但字符串中后面是个 z 就会导致匹配不上,这时候正则就会向前回溯,吐出当前字符 z,接着用正则中的 z 去匹配
正则是非贪婪模式
正则:xy{1,3}z
文本:xyyz
匹配结果:xyyz
匹配过程
- 由于 y{1,3}? 代表匹配 1 到 3 个 y,尽可能少地匹配
- 匹配上一个 y 之后,也就是在匹配上 text 中的 xy 后
- 正则会使用 z 和 text 中的 xy 后面的 y 比较,发现正则 z 和 y 不匹配
- 这时正则就会向前回溯,重新查看 y 匹配两个的情况,匹配上正则中的 xyy
- 然后再用 z 去匹配 text 中的 z,匹配成功

看看独占模式
独占模式和贪婪模式很像,独占模式会尽可能多地去匹配,如果匹配失败就结束,不会进行回溯,这样的话就比较节省时间
具体写法
在量词后加上 +
栗子
正则:xy{1,3}z
文本:xyyz
匹配结果:xyyz

注意事项
Python 和 Go 的标准库目前都不支持独占模式
Python 支持独占模式
需要安装 regex
pip install regex
Python独占模式栗子
>>> import regex 4 >>> regex.findall(r'xy{1,3}z', 'xyyz') # 贪婪模式 ['xyyz'] >>> regex.findall(r'xy{1,3}+z', 'xyyz') # 独占模式 ['xyyz'] >>> regex.findall(r'xy{1,2}+yz', 'xyyz') # 独占模式 []
再来一个栗子
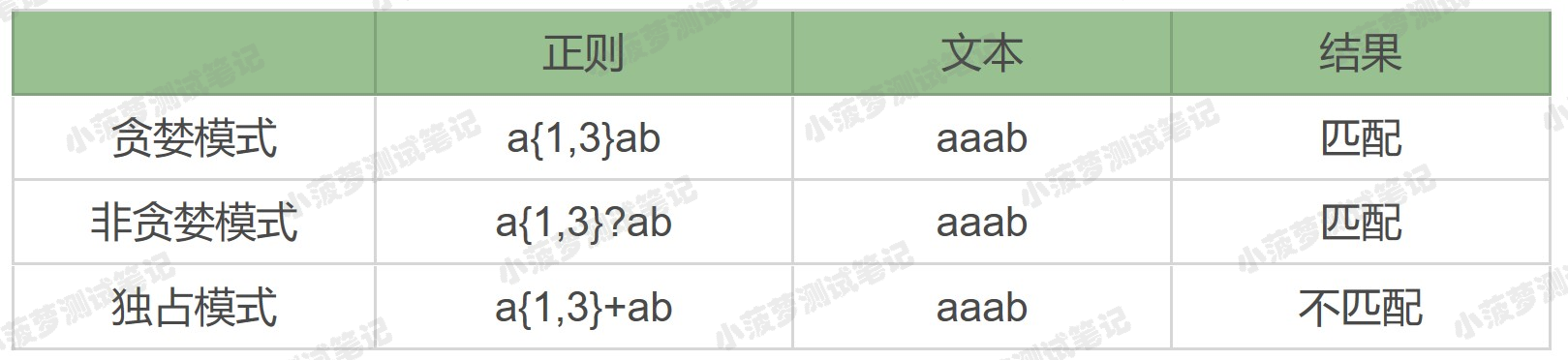
分析
- a{1,3}+ab 去匹配 aaab 字符串,a{1,3}+ 会把前面三个 a 都用掉,并且不会回溯
- 这样字符串中内容只剩下 b 了,导致正则中加号后面的 a 匹配不到符合要求的内容, 匹配失败
- 如果是贪婪模式 a{1,3} 或非贪婪模式 a{1,3}? 都可以匹配上
独占模式总结
- 独占模式性能比较好,可以节约匹配的时间和 CPU 资源
- 但有些情况下并不能满足需求(上面的栗子)
- 要想使用这个模式还要看具体需求,另外还得看你当前使用的语言或库的支持程度

