全网最易懂的正则表达式教程(7)- 环视
正则详细教程系列可以看此链接的文章哦
https://www.cnblogs.com/poloyy/category/1796055.html
前言
- 环视:可以理解成看看左边,再看看右边
- 在正则中我们有时候也需要瞻前顾后,找准定位
- 环视就是要求匹配部分的前面或后面要满足(或不满足)某种规则
- 有些地方也称环视为零宽断言
- 环视其实也是断言的一种方式
什么时候用环视?
通过一个栗子来讲解
需求
邮政编码的规则是第一位是 1-9,一共有 6 位数字组成。现在要求你写出一个正则,提取文本中的邮政编码
最朴实的正则
[1-9]\d{5}
测试
| 测试文本 | 结果 |
| 012300 | 不满足第一位是 1-9 |
| 130400 | 满足要求 |
| 465441 | 满足要求 |
| 4654000 | 长度过长 |
| 138001380002 | 长度过长 |
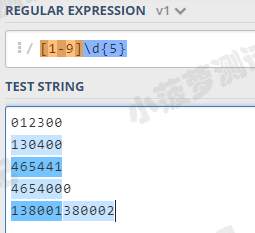
可以发现:
7 位数的前 6 位也能匹配上,12 位数匹配上了两次,这显然是不符合要求的,它们并不是正常的邮政编码
所以,除了 6 位数的规则外,这 6 位数左边或右边都不能是数字
环视解决问题
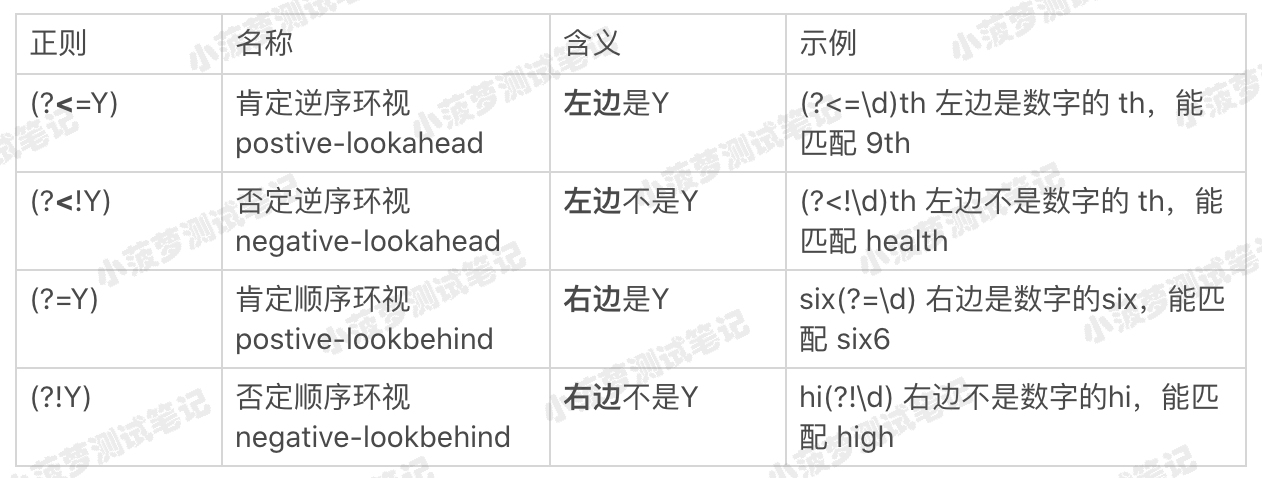
记忆口诀
<看左边,没有<看右边,感叹号是非的意思
通过环视来写邮编的正则
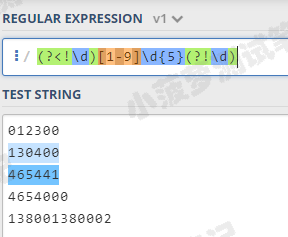
(?<!\d)[1-9]\d{5}(?!\d)
这样就满足正常邮编的规则了
表示单词边界 \b 用环视的方式如何写?
- (?<!\w) 表示左边不能是单词组成字符,
- (?!\w) 右边不能是单词组成字符
- 即 \b\w+\b 也可以写成 (?<!\w)\w+(?!\w)
但并不推荐这样写,直接用 \b 写不香吗
环视与分组
- 环视和分组都有 ( )
- 但环视只匹配位置,不匹配文本内容
- 而分组是为了将匹配到的文本内容用于后续的操作

