Mysql常用sql语句(21)- regexp 正则表达式查询
测试必备的Mysql常用sql语句系列
https://www.cnblogs.com/poloyy/category/1683347.html
前言
正则的强大不言而喻,Mysql中也提供了 regexp 关键字来进行正则查询
正则查询的语法格式
<列名> regexp '正则表达式'
常用的正则表达式
| 选项 | 说明 | 例子 | 匹配值示例 |
|---|---|---|---|
| ^ | 匹配文本的开始字符 | '^b' 匹配以字母 b 开头的字符串 | book、big、banana、bike |
| $ | 匹配文本的结束字符 | 'st$' 匹配以 st 结尾的字符串 | test、resist、persist |
| . | 匹配任何单个字符 | 'b.t' 匹配任何 b 和 t 之间有一个字符 | bit、bat、but、bite |
| * | 匹配零个或多个在它前面的字符 | 'f*n' 匹配字符 n 前面有任意个字符 f | fn、fan、faan、abcn |
| + | 匹配前面的字符 1 次或多次 | 'ba+' 匹配以 b 开头,后面至少紧跟一个 a | ba、bay、bare、battle |
| <字符串> | 匹配包含指定字符的文本 | 'fa' 匹配包含‘fa’的文本 | fan、afa、faad |
| [字符集合] | 匹配字符集合中的任何一个字符 | '[xz]' 匹配 x 或者 z | dizzy、zebra、x-ray、extra |
| [^] | 匹配不在括号中的任何字符 | '[^abc]' 匹配任何不包含 a、b 或 c 的字符串 | desk、fox、f8ke |
| 字符串{n,} | 匹配前面的字符串至少 n 次 | 'b{2}' 匹配 2 个或更多的 b | bbb、bbbb、bbbbbbb |
| 字符串 {n,m} |
匹配前面的字符串至少 n 次, 至多 m 次 | 'b{2,4}' 匹配最少 2 个,最多 4 个 b | bbb、bbbb |
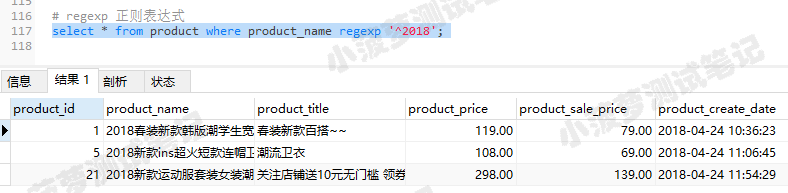
先看看product表有什么数据
product表
这里没有截全哈,因为数据比较多

栗子一:^
select * from product where product_name regexp '^2018';
栗子二:$
select * from product where product_name regexp '潮$';
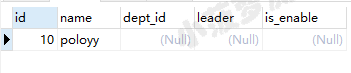
先看看emp表有什么数据
emp表

后面再解释下为啥又换表了
栗子三: *、+
po*:查询 name 字段包含字母 p ,且 p 后面出现字母 o 的记录,而 * 可以表示0个字符,代表不出现
select * from emp where name regexp 'po*';

po+:查询 name 字段包含字母 p ,且 p 后面出现字母 o 的记录,但 + 表示至少出现1个字符
select * from emp where name regexp 'po+';
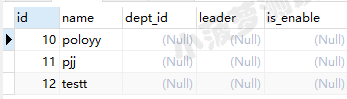
栗子四:[]
下面两种写法是一样的,用 , 隔开每个字符,可能可读性更高
select * from emp where name regexp '[p,s]'; select * from emp where name regexp '[ps]';
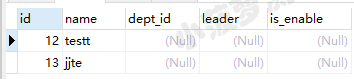
栗子五:[^]
注意:这里的^是取反,不是开头的意思哦!不要混淆
查询 id >=10 且 开头非字母 p 的记录
select * from emp where id >=10 and name regexp '^[^p]';
为啥中途换表
因为,我发现正则表达式并不是对所有中文都生效,举个下面的栗子
select * from emp where name regexp '[小]';

可以看到,name 字段需要匹配到一个【小】才应该被返回,但是除了红框以外的数据都被返回了,有问题有问题....
那为什么会这样呢?
- 原来,是因为 regexp 不支持多字节匹配,说白了,就是不支持中文编码
- 要想查询中文,最好通过 like 关键字进行模糊匹配啦
当然啦,也不是没有解决办法
只需要用小括号()把中文括起来就行了
select * from emp where name regexp '^(小)';

但,这种写法在 [ ] 里面还是不起作用
select * from emp where name regexp '[(小)]';
所以啊,还是推荐用 like 模糊匹配中文字符吧!而且日常工作中也完全够用啦!

