SimCLR
声明
本片文章主要介绍了自监督学习在预训练中的主要应用。许多内容非笔者原创,感谢以下作者对本篇文章的启发和指导。欢迎读者进行留言和讨论
Self-Supervised Learning 超详细解读 (二):SimCLR系列
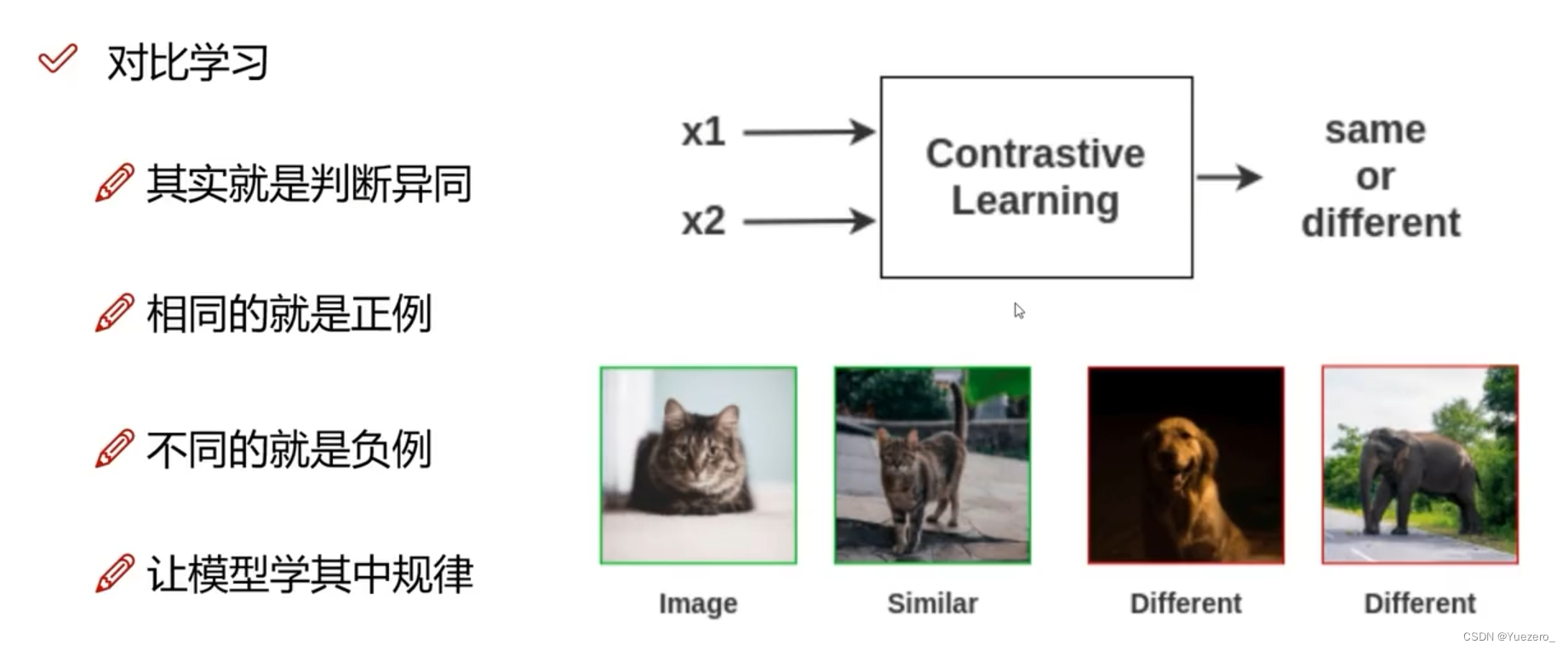
对比学习:通过比较不同实例之间的相似性和差异性来进行学习
将输入数据分为不同的类别或组(正负样本对),并通过比较样本之间的差异来提取特征或进行分类。
样本相似度
对比学习有几种不同的方法,其中最常见的是基于距离度量的方法。这些方法使用距离函数来度量两个实例之间的相似性,例如欧氏距离或余弦相似度,正样本对相似度越近越好,负样本对相似度越远越好
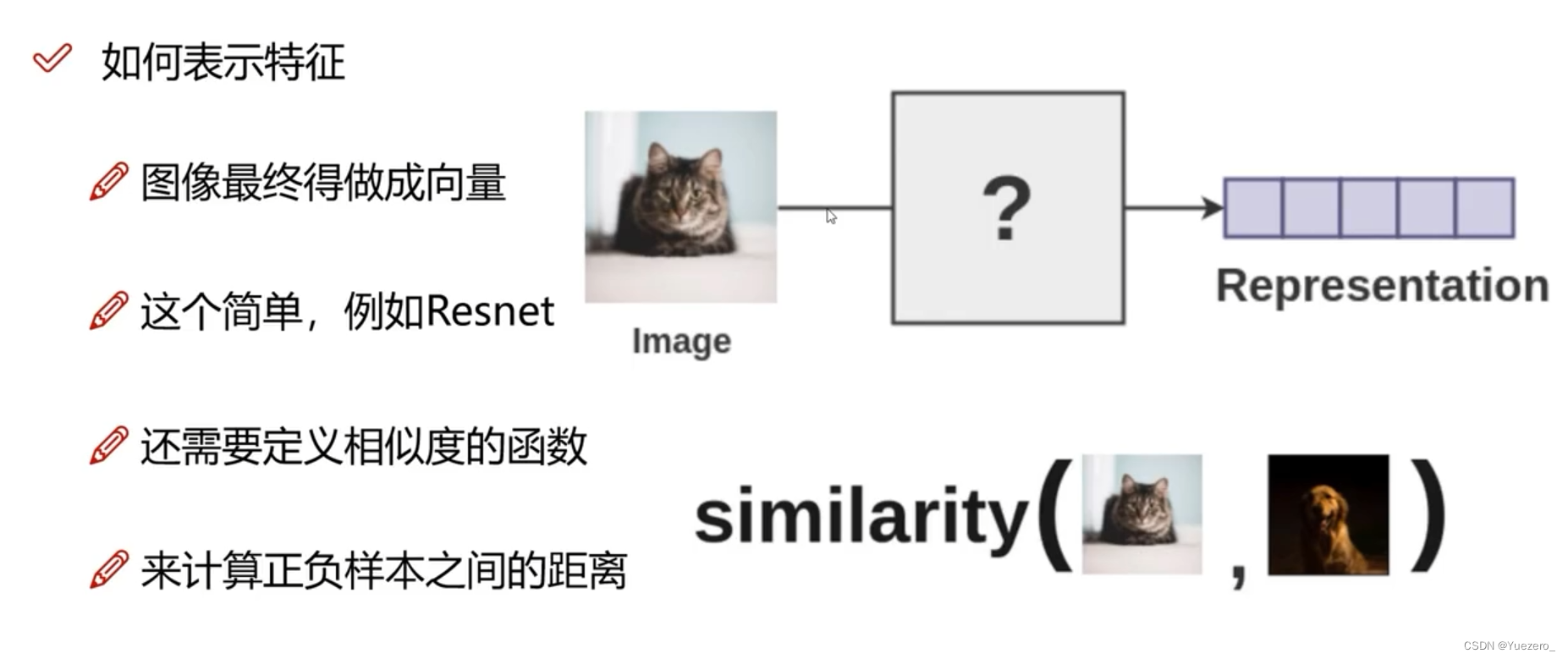
SimCLR 是Hinton团队在 Self-Supervised Learning 领域的一个系列的经典工作。
1、基本理论
下图所示。前两张都是dog 这个类别,后两张是其他类别
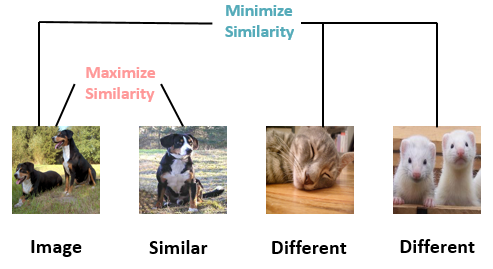
现状:
- 只有大堆images,没有任何标签,不知道哪些是 dog 这个类的,哪些是其他类的。
- 没办法找出哪些图片应该去 Maximize Similarity,哪些应该去 Minimize Similarity。
目标是:它(第一张)与第2张图的相似性越高越好,而与第3,第4张图的相似性越低越好。
思想如图所示:
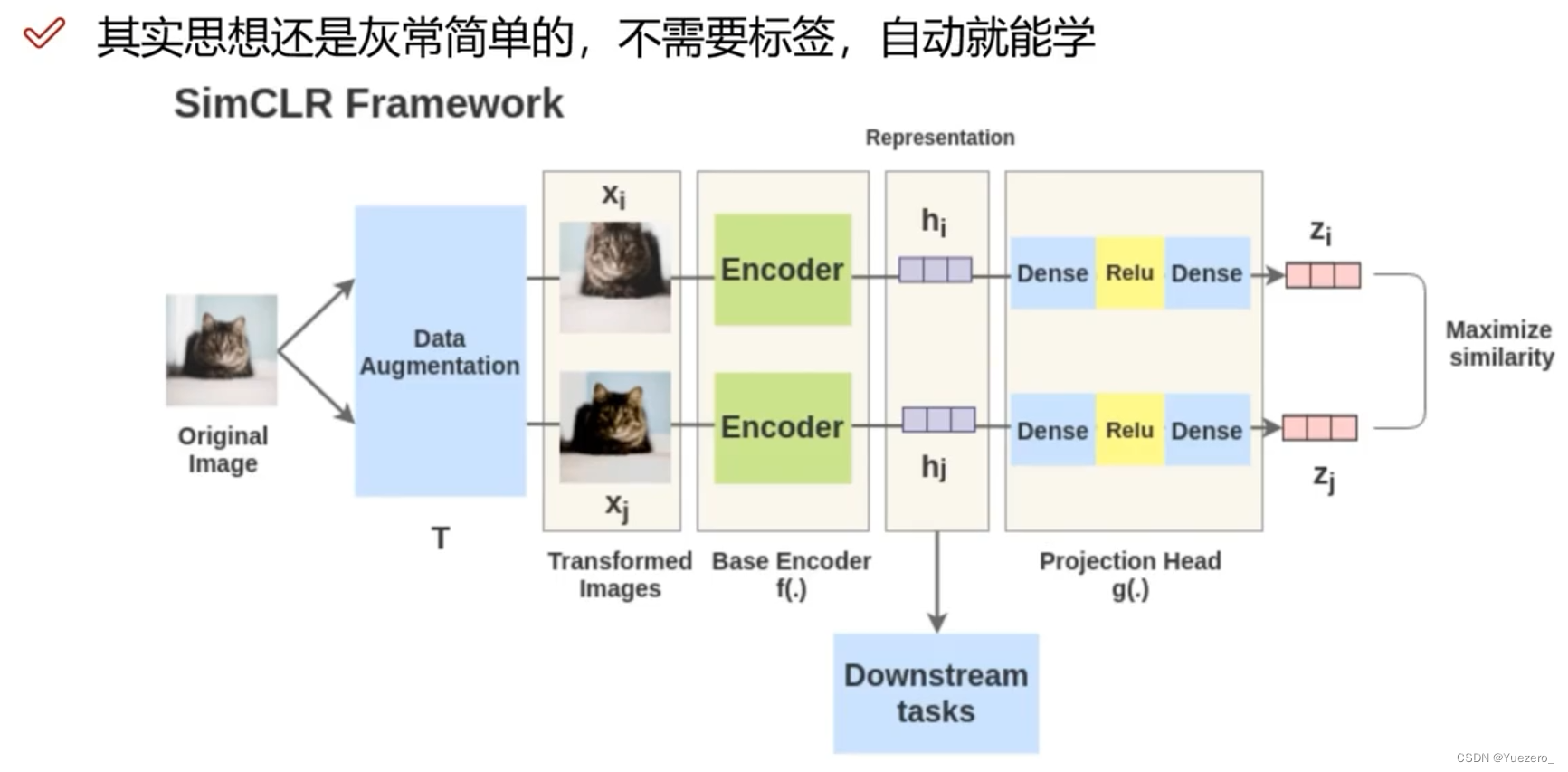
操作步骤:
- 取一个输入图像:同1张图像进行2种数据增强,形成一个正样本对儿;不同图像之间是负样本对儿。
- 准备2个随机的图像增强:旋转,颜色/饱和度/亮度变化,缩放,裁剪等。文中详细讨论了增强的范围,并分析了哪些增广效果最好。(构造正样本:图像SimCLR-数据增强、文本SimCSE-Dropout、图文CLIP-图像文本对)
- 特征提取:运行一个深度神经网络(最好是卷积神经网络,如ViT、Bert、ResNet50)来获得那些增强图像的图像特征表示(嵌入)。
- 特征投影:运行一个小的全连接线性神经网络,将嵌入投影到另一个向量空间。
- 计算loss:计算对比损失并通过两个网络进行反向传播。当来自同一图像的投影相似时,对比损失减少。投影之间的相似度可以是任意的,这里使用余弦相似度,和论文中一样。
- 下游任务:对比学习得到Encoder做为特征提取器,根据下游任务的数据集进行微调Finetune
示例:
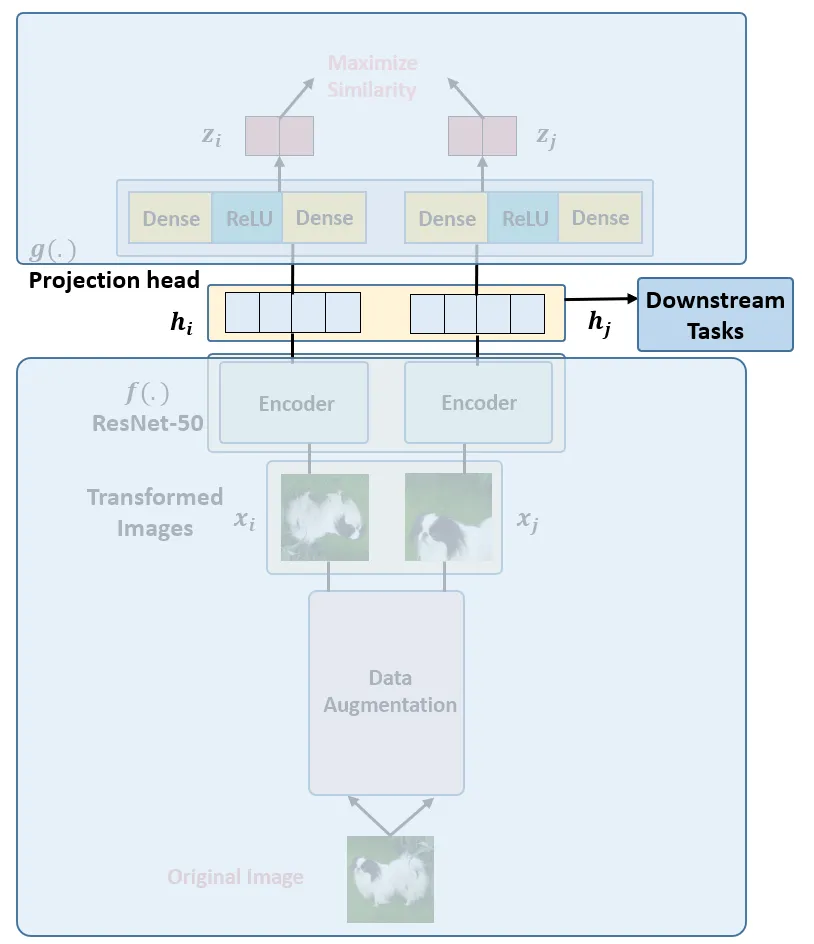
假设现在有1张任意的图片 x ,叫做Original Image,先对它做数据增强,得到2张增强以后的图片 xi,xj 。注意数据增强的方式有以下3种:
接下来把增强后的图片 xi,xj输入到Encoder里面,注意这2个Encoder是共享参数的,得到representation hi,hj ,再把 hi,hj 继续通过 Projection head 得到 representation zi,zj ,这里的2个 Projection head 依旧是共享参数的,且其具体的结构表达式是:
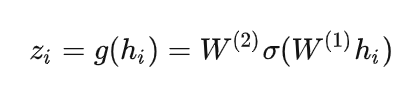
接下来的目标就是最大化同一张图片得到的 zi,zj 。
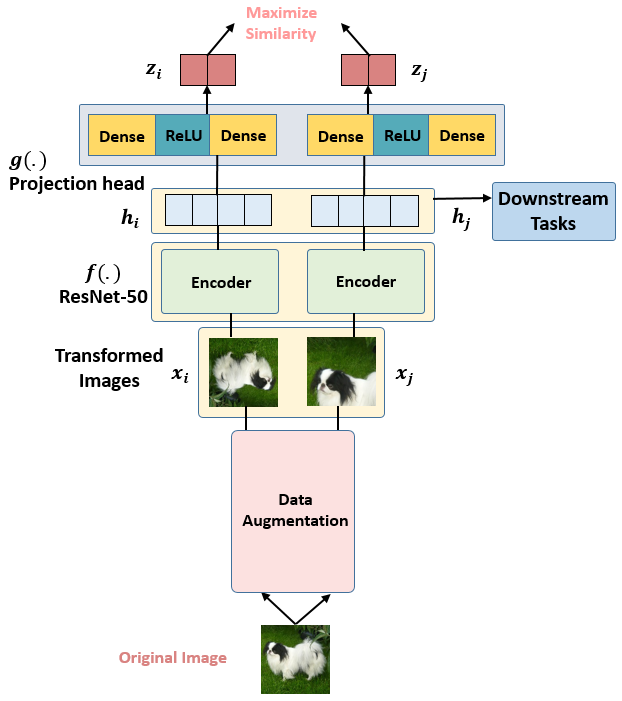
整体流程思想,类似GNN网络的生成阶段,目的就是使网络生成的两张图像相似度高
2、技术点
图像增强
数据增强的方式有以下3种:
- 随机裁剪之后再resize成原来的大小 (Random cropping followed by resize back to the original size)。
- 随机色彩失真 (Random color distortions)。
- 随机高斯模糊 (Random Gaussian Deblur)。
Encoder表征特征
编码器是获取图片的表征,得到的hi,hj两张高纬度特征图片,2个编码器共享权重。本文使用了 ResNet-50 作为 Encoder,输出是 2048 维的向量 ℎ 。

预测头
在 SimCLR 中,Encoder 得到的2个 visual representation再通过Prediction head 进一步提特征,预测头是一个 2 层的MLP,将 visual representation 这个 2048 维的向量hi,hj进一步映射到 128 维隐空间中,得到新的representation zi,zj。利用 zi,zj去求loss 完成训练,训练完毕后扔掉预测头,保留 Encoder 用于获取 visual representation。
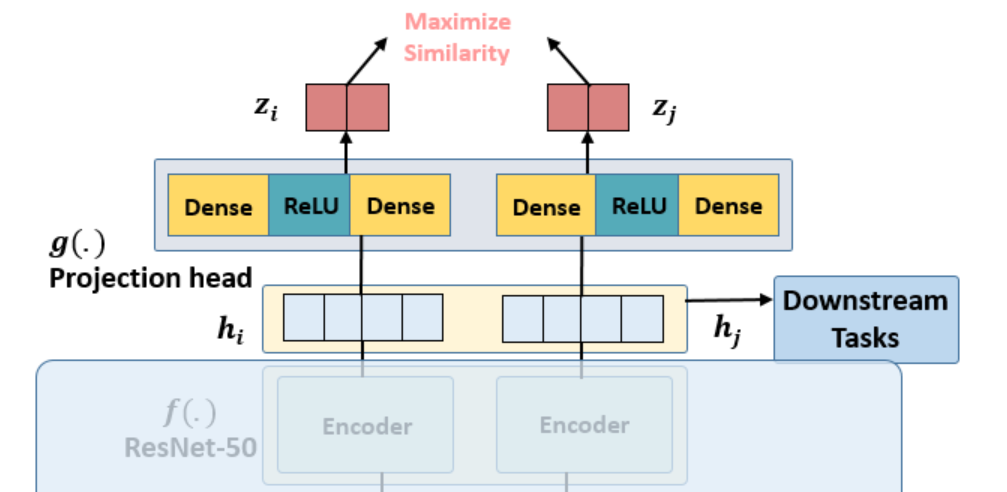
Loss计算
每个Batch,我们得到了如下图12所示的Representation z1,...,z4 。

使用余弦相似度Cosine Similarity:
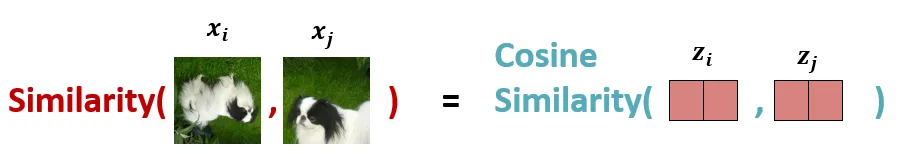
Cosine Similarity把计算两张 Augmented Images xi,xj 的相似度转化成了计算两个Projected Representation zi,zj的相似度.理想情况下,狗的增强图像之间的相似度会很高,而狗和鲸鱼图像之间的相似度会较低。
衡量相似度的办法,但是这还不够,要最终转化成一个能够优化的 Loss Function 才可以。SimCLR用了一种叫做 NT-Xent loss (Normalized Temperature-Scaled Cross-Entropy Loss)的对比学习损失函数
- 使用 softmax 函数来获得这两个相同类别图像相似的概率:
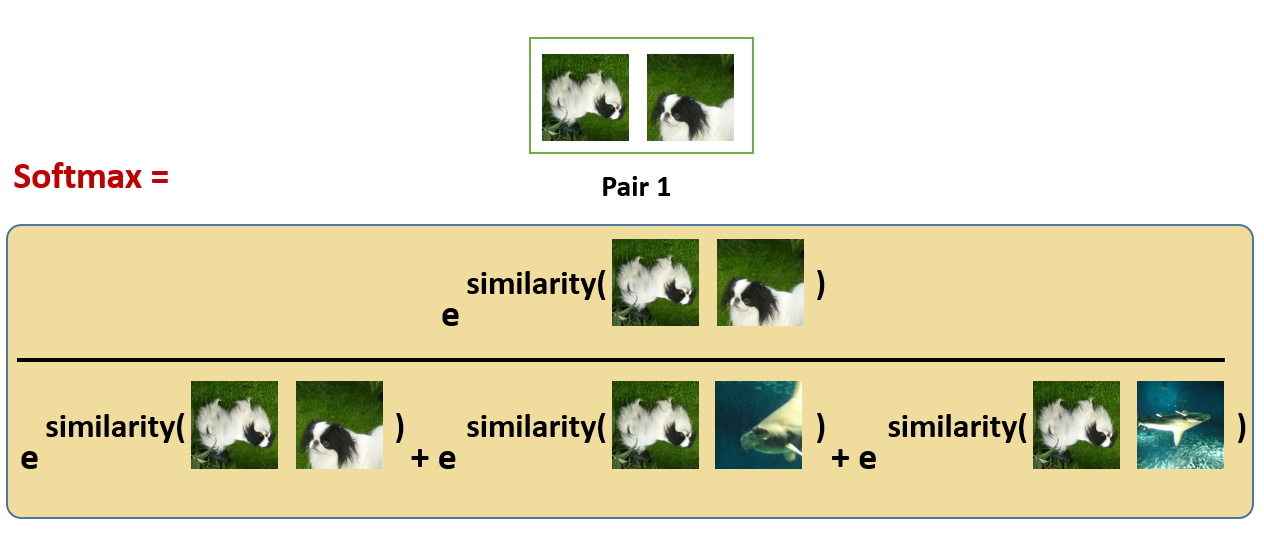
这种 softmax 计算等价于获得第2张增强的狗的图像与该对中的第1张狗的图像最相似的概率。 在这里,分母中的其余的项都是其他图片的增强之后的图片,也是negative samples。所以我们希望上面的softmax的结果尽量大,所以损失函数取了softmax的负对数:
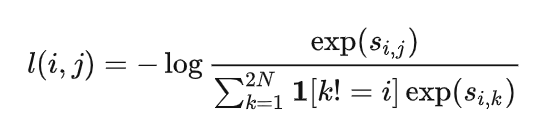
- 对同一对图片交换位置以后计算损失。

- 计算每个Batch里面的所有Pair的损失之和取平均:
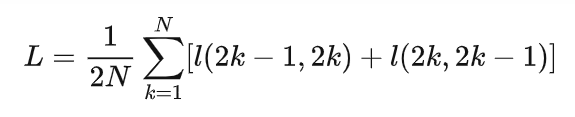
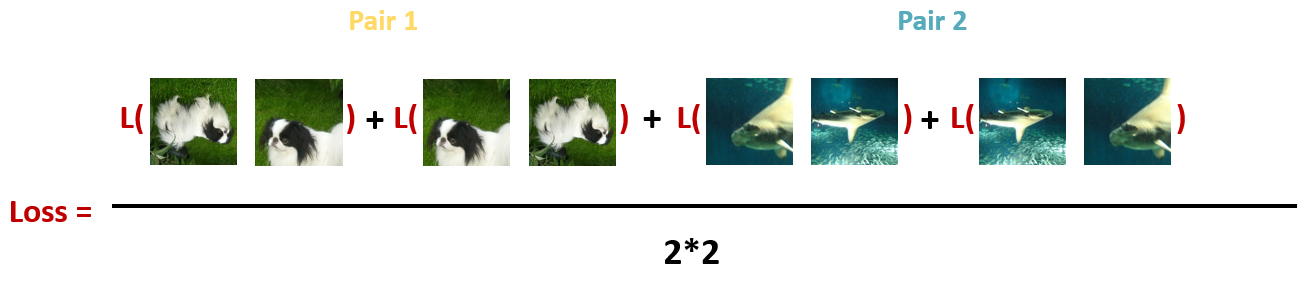
下游fine-tune
对比学习,巧妙地在没有任何标签的情况下训练好了 SimCLR 模型,使得其Encoder的输出可以像正常有监督训练的模型一样表示图片的Representation信息,一旦 SimCLR 模型在对比学习任务上得到训练,它就可以用于迁移学习,如 ImageNet 分类
本质是将loss计算换成分类的loss头,用少量数据进行训练即可。
性能
SimCLR (4×) 这个模型可以在 ImageNet 上面达到 76.5% 的 Top 1 Accuracy,比当时的 SOTA 模型高了7个点。如果把这个预训练模型用 1%的ImageNet的标签给 Fine-tune 一下,借助这一点点的有监督信息,SimCLR 就可以再达到 85.5% 的 Top 5 Accuracy,也就是再涨10个点
FAQ1:这个 76.5% 和 85.5% 是怎么得到的呢?
答1:76.5% 是通过Linear Evaluation得到的。
按照上面的方式进行完Pre-train之后,Encoder部分和Projection head部分的权重也就确定了。那么这个时候我们去掉Projection head的部分,在Encoder输出的 ℎi,ℎj 之后再添加一个线性分类器 (Linear Classifier),它其实就是一个FC层。那么我们使用全部的 ImageNet 去训练这个 Linear Classifier,具体方法是把预训练部分,即 ℎi,ℎj 之前的权重frozen住,只训练线性分类器的参数,那么 Test Accuracy 就作为 a proxy for representation quality,就是76.5%。
85.5% 是通过Fine-tuning得到的。
按照上面的方式进行完Pre-train之后,Encoder部分和Projection head部分的权重也就确定了。那么这个时候我们去掉Projection head的部分,在Encoder输出的 ℎi,ℎj之后再添加一个线性分类器 (Linear Classifier),它其实就是一个FC层。那么我们使用 1%的ImageNet 的标签 去训练整个网络,不固定 Encoder 的权重了。那么最后的 Test Accuracy 就是85.5%。
FAQ2:Projection head 一定要使用非线性层吗?
答2:不一定。作者尝试了3种不同的 Projection head 的办法,分别是:Non-Linear, Linear 层和 Identity mapping,结果如下图21所示。发现还是把Projection head 设置成非线性层 Non-Linear 比较好。 Non-Linear 比 Linear 层要涨3%的Top 1 Accuracy,比 Identity mapping 层要涨10%的Top 1 Accuracy。
而且,作者的另一个发现是 Projection head 前面的 hidden layer 相比于 Projection head后面的 hidden layer 更好。那这个更好是什么意思呢?
就是假设我们把 Projection head 前面的 hidden layer ℎ 作为图片的representation的话,那么经过线性分类层得到的模型性能是好的。如果把Projection head 后面的 hidden layer 作为图片的representation的话,那么经过线性分类层得到的模型性能不好,如下图22所示,是对 ℎ 或者 分别训练一个额外的MLP, ℎ 或者 的hidden dimension 都是2048。
AQ4:SimCLR 的性能与 Batch size 的大小和训练的长度有关吗?
答4:有关系。如下图23所示,作者发现当使用较小的 training epochs 时,大的 Batch size 的性能显著优于小的 Batch size 的性能。作者发现当使用较大的 training epochs 时,大的 Batch size 的性能和小的 Batch size 的性能越来越接近。这一点其实很好理解:在对比学习中,较大的 Batch size 提供更多的 negative examples,能促进收敛。更长的 training epochs 也提供了更多的 negative examples,改善结果


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律