自监督学习入门
自监督学习入门
声明
本片文章主要介绍了自监督学习在预训练中的主要应用。许多内容非笔者原创,感谢以下作者对本篇文章的启发和指导。欢迎读者进行留言和讨论
1、背景
为什么自监督火了?
-
大模型火了,数据需求量大
-
数据需求量大,导致标注成本提升
-
人工标准有一定误差
另一个层面来讲:
Yann Lecun在AAAI 2020的演讲中,指出目前深度学习遇到的挑战:
- 监督学习:深度模型有海量参数,需要大量的label数据,标注成本高、扩展性差,难以应用到无标记或标记数据少的场景。
- 强化学习:agent需要和环境大量的交互尝试,很多实际场景(例如互联网搜索推荐、无人驾驶)中交互成本大、代价高,很难应用。
而人类和动物学习快速的原因:最重要的是观察世界,而不是靠大量的监督、强化学习。自监督学习的思想就是通过构造任务来提升预训练模型预测能力,即Predicting everything from everything else。具体方法是假装输入中的一部分不存在,然后基于其余的部分用模型预测这个部分,从而学习得到一个能很好地建模输入语义信息的表示学习模型
基于以上的问题,我们可以通过自监督的方法一定程度上进行解决。当然,自监督的方法也不是完全正确的,但是可以提高标注和训练的速度,减少人为因素的干扰
2、自监督学习理论
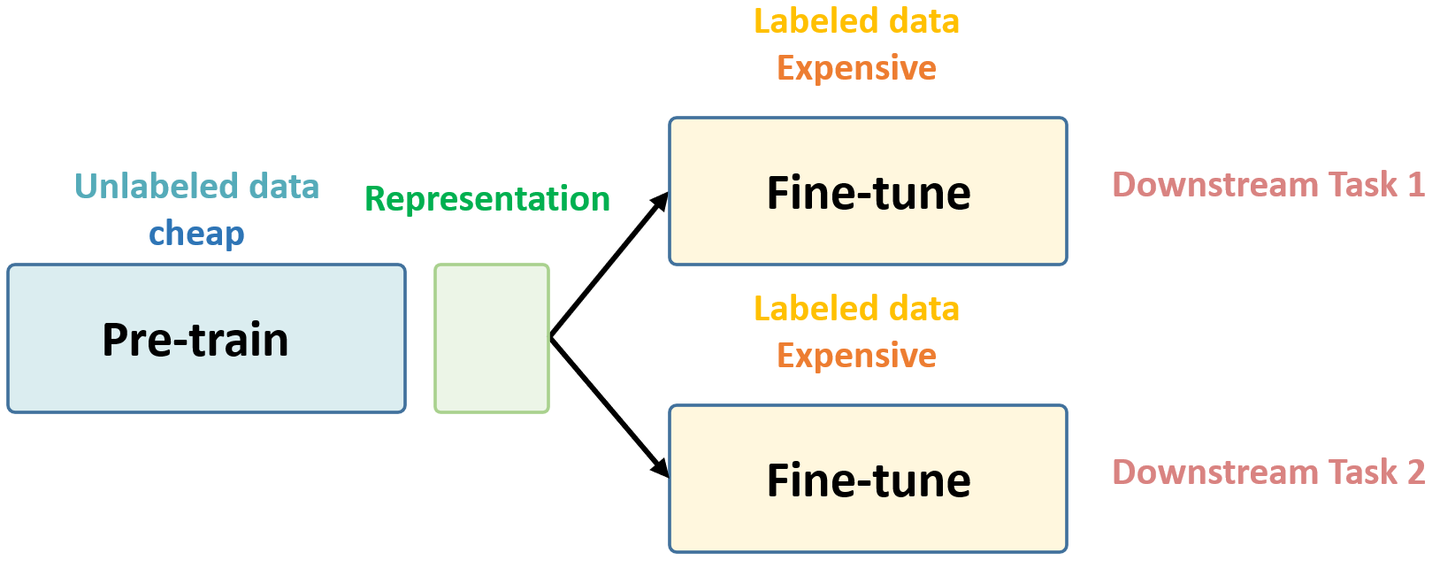
Self-Supervised Learning 的目的一般是使用大量的无 label 的资料去Pre-train一个模型,这么做的原因是无 label 的资料获取比较容易,且数量一般相当庞大,我们希望先用这些廉价的资料获得一个预训练的模型,接着根据下游任务的不同在不同的有 label 数据集上进行 Fine-tune 即可
2.1 什么是自监督学习
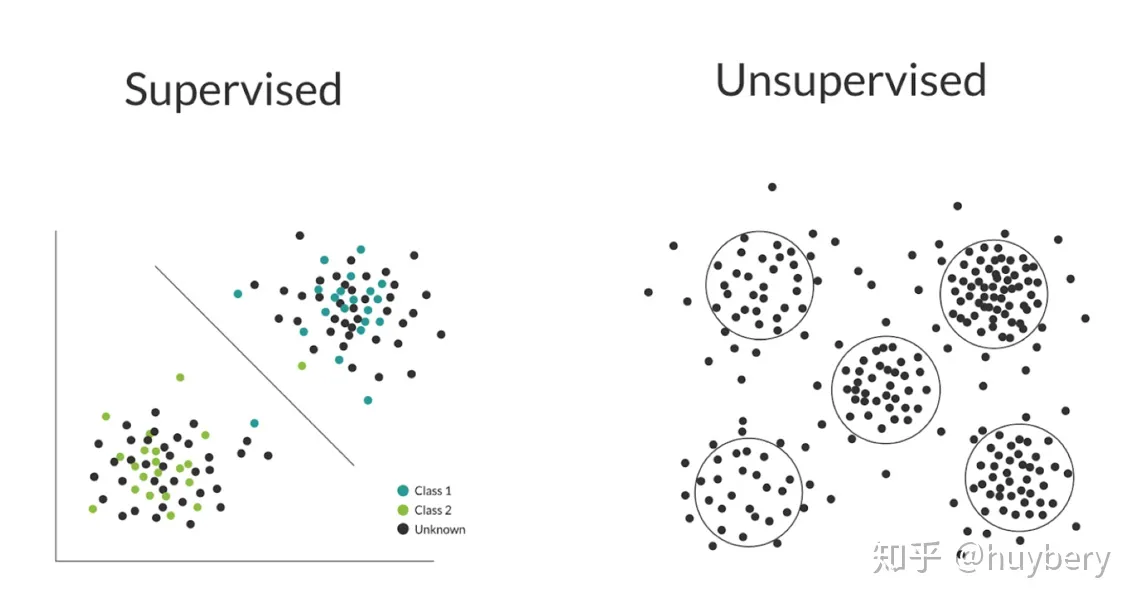
监督学习利用大量的标注数据来训练模型,无监督学习不依赖任何标签值,通过对数据内在特征的挖掘,找到样本间的关系,比如聚类相关的任务。有监督和无监督最主要的区别在于模型在训练时是否需要人工标注的标签信息。
自监督从无监督的概念中分离出来,成为一个独立的概念,通常为定义一个Pretext task (辅助任务),即从无监督的数据中,通过巧妙地设计自动构造出有监督(伪标签)数据,学习一个预训练模型。具体来说自监督可以定义为:
- 从部分无标签数据自身出发通过设计半自动预训练任务进行处理学习具有监督性质的表征信息。
- 通过这部分学习到特征的数据去预测其他无标签的数据,实现标签的泛化
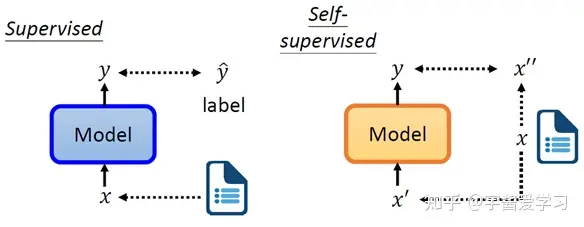
如果学习的预训练模型能准确预测缺失部分的数据,说明它的表示学习能力很强,能够学习到输入中的高级语义信息、泛化能力比较强
Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种通用的特征表达用于下游任务 (Downstream Tasks)。预训练阶段使用无标签的数据集 (unlabeled data),想先把参数从 一张白纸 训练到 初步成型,再从 初步成型 训练到 完全成型。注意这是2个阶段。这个训练到初步成型的东西,我们把它叫做 Visual Representation。预训练模型的时候,就是模型参数从 一张白纸 到 初步成型 的这个过程,还是用无标签数据集。等我把模型参数训练个八九不离十,这时候再根据你 下游任务 (Downstream Tasks) 的不同去用带标签的数据集把参数训练到 完全成型,那这时用的数据集量就不用太多了,因为参数经过了第1阶段就已经训练得差不多了
2.2 如何实现
在自监督学习中,最重要的问题是:如何定义Pretext任务、如何从Pretext任务学习预训练模型
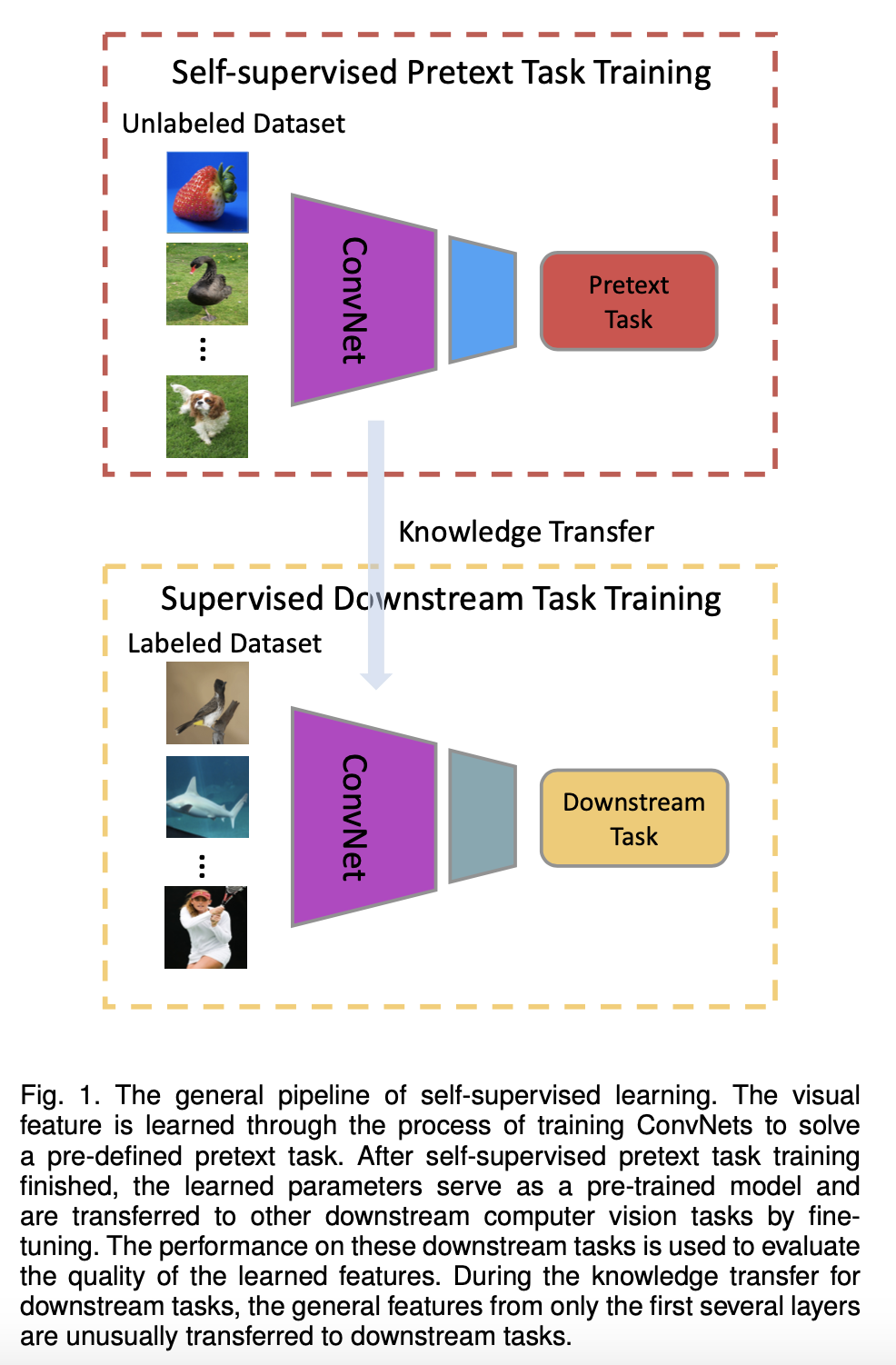
对于自监督学习来说,存在三个挑战:
- 对于大量的无标签数据,如何进行表征学习?
- 从数据的本身出发,如何设计有效的辅助任务 pretext?
- 对于自监督学习到的表征,如何来评测它的有效性?
评测自监督学习的能力,主要是通过 Pretrain-Fintune 的模式。
监督学习中的 Pretrain - Finetune 流程:我们首先从大量的有标签数据上进行训练,得到预训练的模型,然后对于新的下游任务(Downstream task),我们将学习到的参数进行迁移,在新的有标签任务上进行「微调」,从而得到一个能适应新任务的网络。
自监督的 Pretrain - Finetune 流程:首先从大量的无标签数据中通过 pretext 来训练网络,得到预训练的模型,然后对于新的下游任务,和监督学习一样,迁移学习到的参数后微调即可。所以自监督学习的能力主要由下游任务的性能来体现。
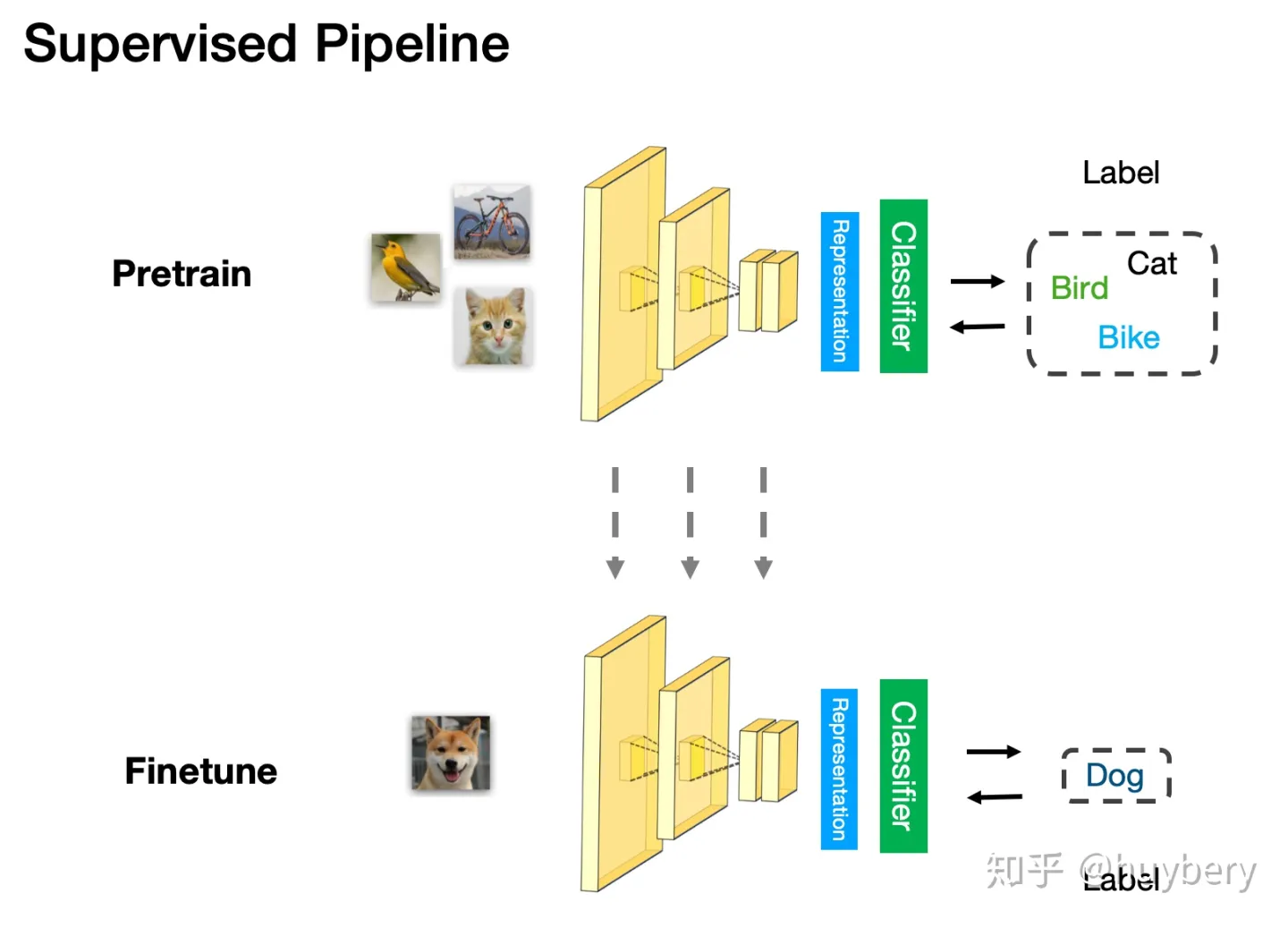
监督学习的 Pretrain-Finetune
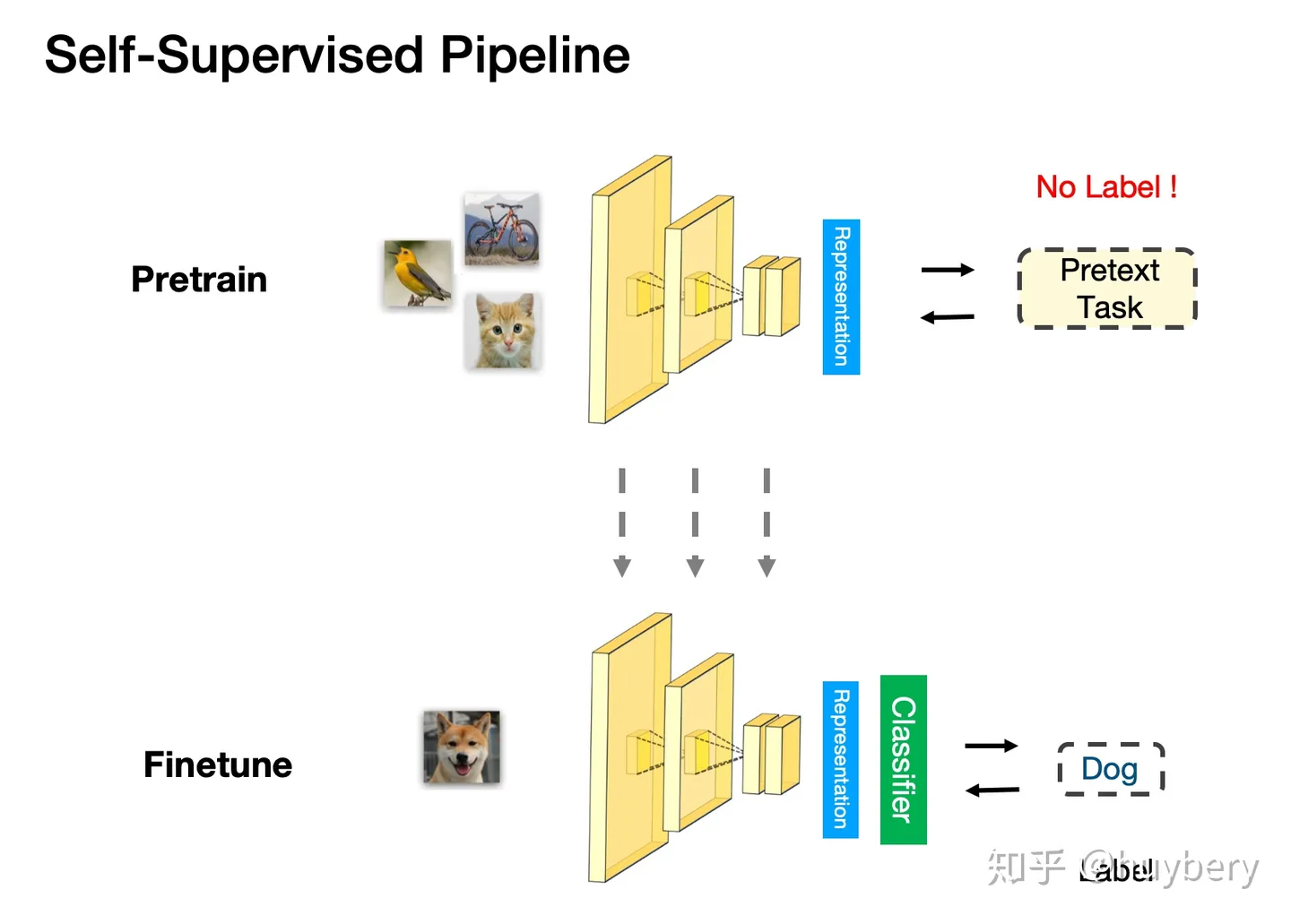
3 、自监督的学习方法
自监督学习的方法主要可以分为 3 类:1. 基于上下文(Context based) 2. 基于时序(Temporal Based)3. 基于对比(Contrastive Based)
3.1 基于上下文
基于数据本身的上下文信息,我们其实可以构造很多任务,比如在 NLP 领域中最重要的算法 Word2vec 。 Word2vec 主要是利用语句的顺序,例如 CBOW 通过前后的词来预测中间的词,而 Skip-Gram 通过中间的词来预测前后的词。
本身是自然语言的处理方式,通过此思想引入到图像领域。
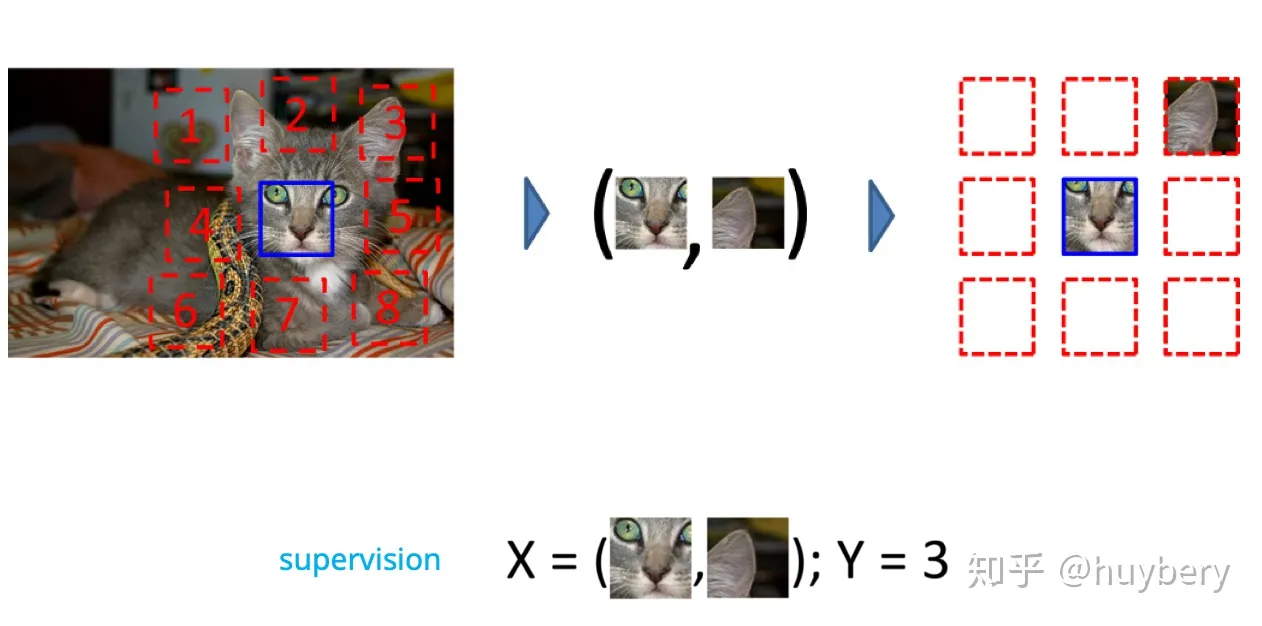
1. 拼图
将一张图分成 9 个部分,然后通过预测这几个部分的相对位置来产生损失,比如我们输入这张图中的小猫的眼睛和右耳朵,期待让模型学习到猫的右耳朵是在脸部的右上方的,如果模型能很好的完成这个任务,那么我们就可以认为模型学习到的表征是具有语义信息的。
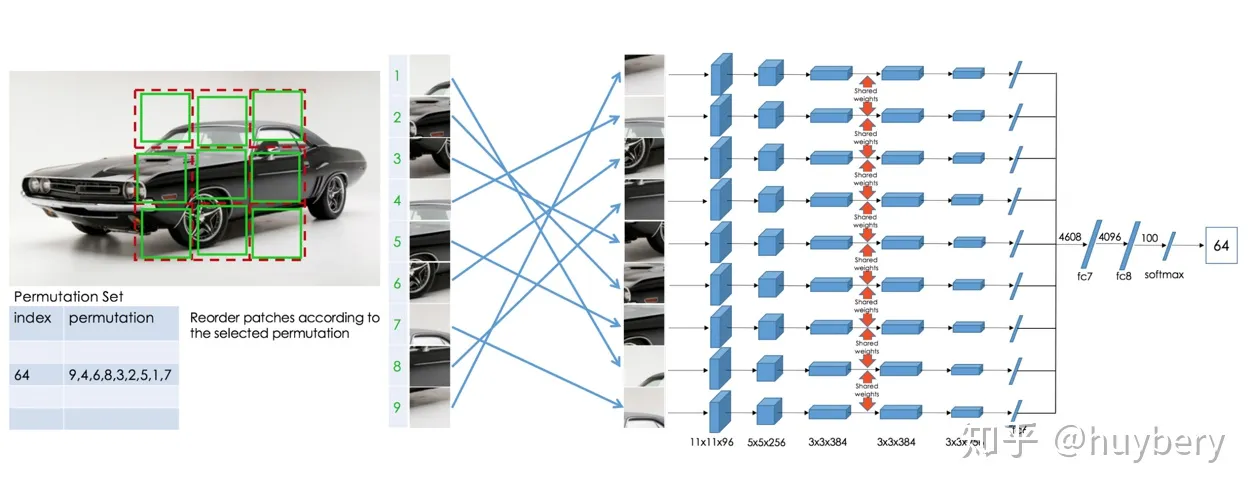
后续的工作[8]人们又拓展了这种拼图的方式,设计了更加复杂的,或者说更难的任务。
- 首先我们依然将图片分为 9 块,我们预先定义好 64 种排序方式。
- 模型输入任意一种被打乱的序列,期待能够学习到这种序列的顺序属于哪个类。
上个工作相比,这个模型需要学习到更多的相对位置信息。这个工作带来的启发就是使用更强的监督信息,或者说辅助任务越难,最后的性能越好。
2.抠图
随机的将图片中的一部分删掉,然后利用剩余的部分来预测扣掉的部分,只有模型真正读懂了这张图所代表的含义,才能有效的进行补全
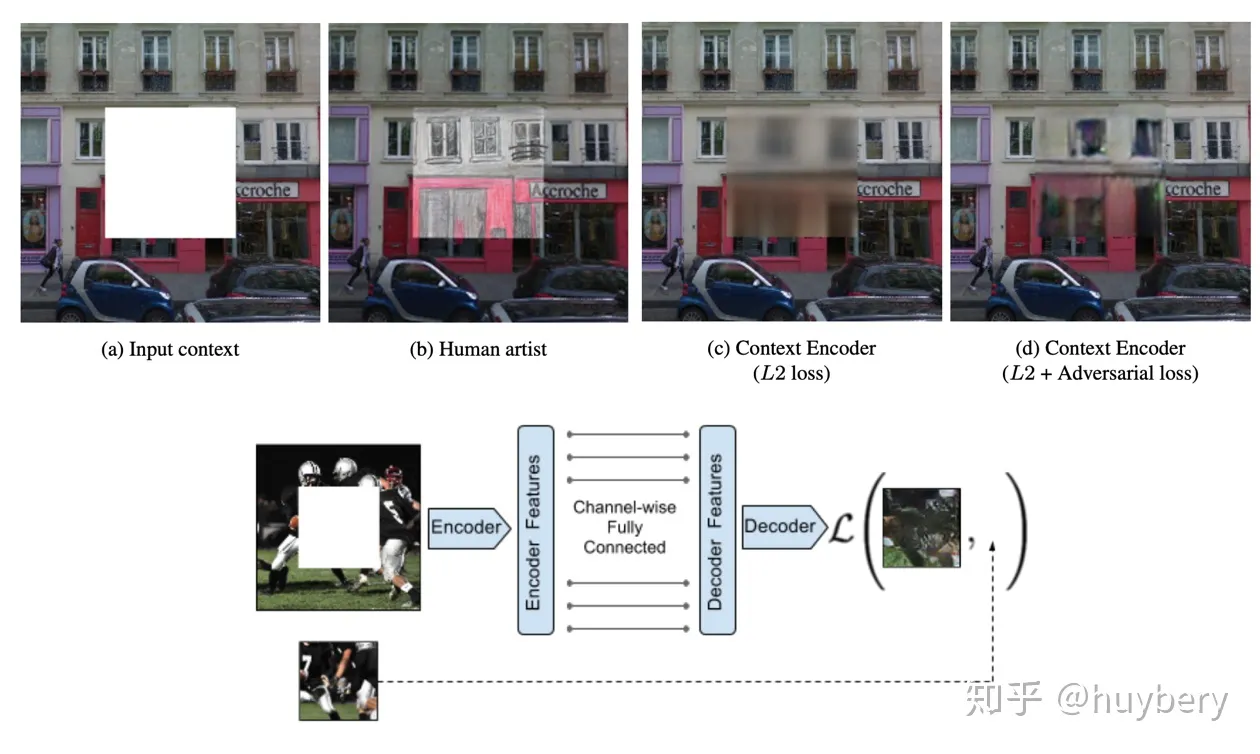
3.颜色信息
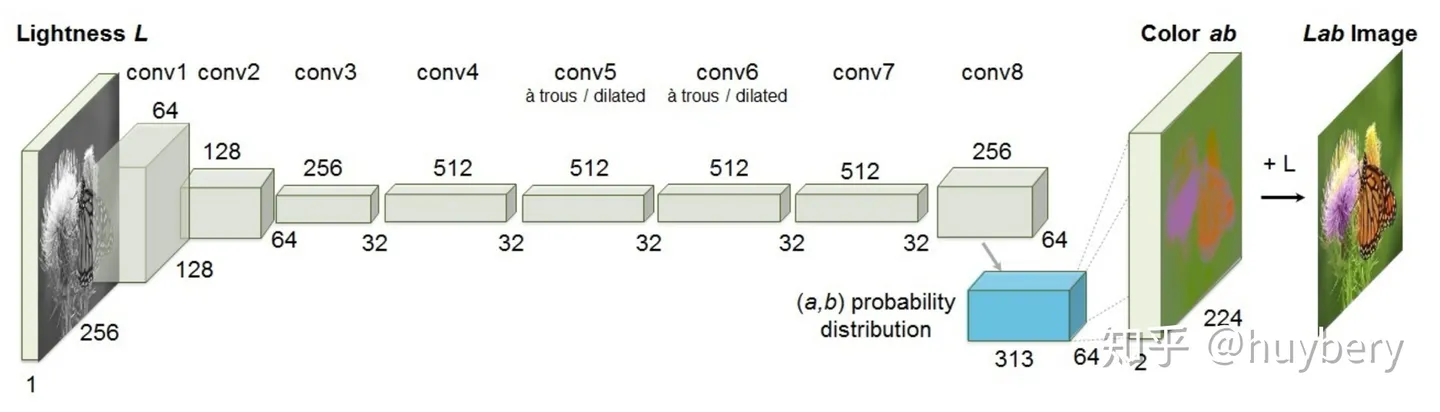
模型输入图像的灰度图,来预测图片的色彩。只有模型可以理解图片中的语义信息才能得知哪些部分应该上怎样的颜色,比如天空是蓝色的,草地是绿色的,只有模型从海量的数据中学习到了这些语义概念,才能得知物体的具体颜色信息。同时这个模型在训练结束后就可以做这种图片上色的任务。
对于原始数据,首先分成两部分,然后通过一部分的信息来预测另一部分,最后再合成完成的数据。和传统编码器不同的是,这种预测的方式可以促使模型真正读懂数据的语义信息才能够实现,所以相当于间接地约束编码器不单单靠 pixel-wise 层面来训练,而要同时考虑更多的语义信息
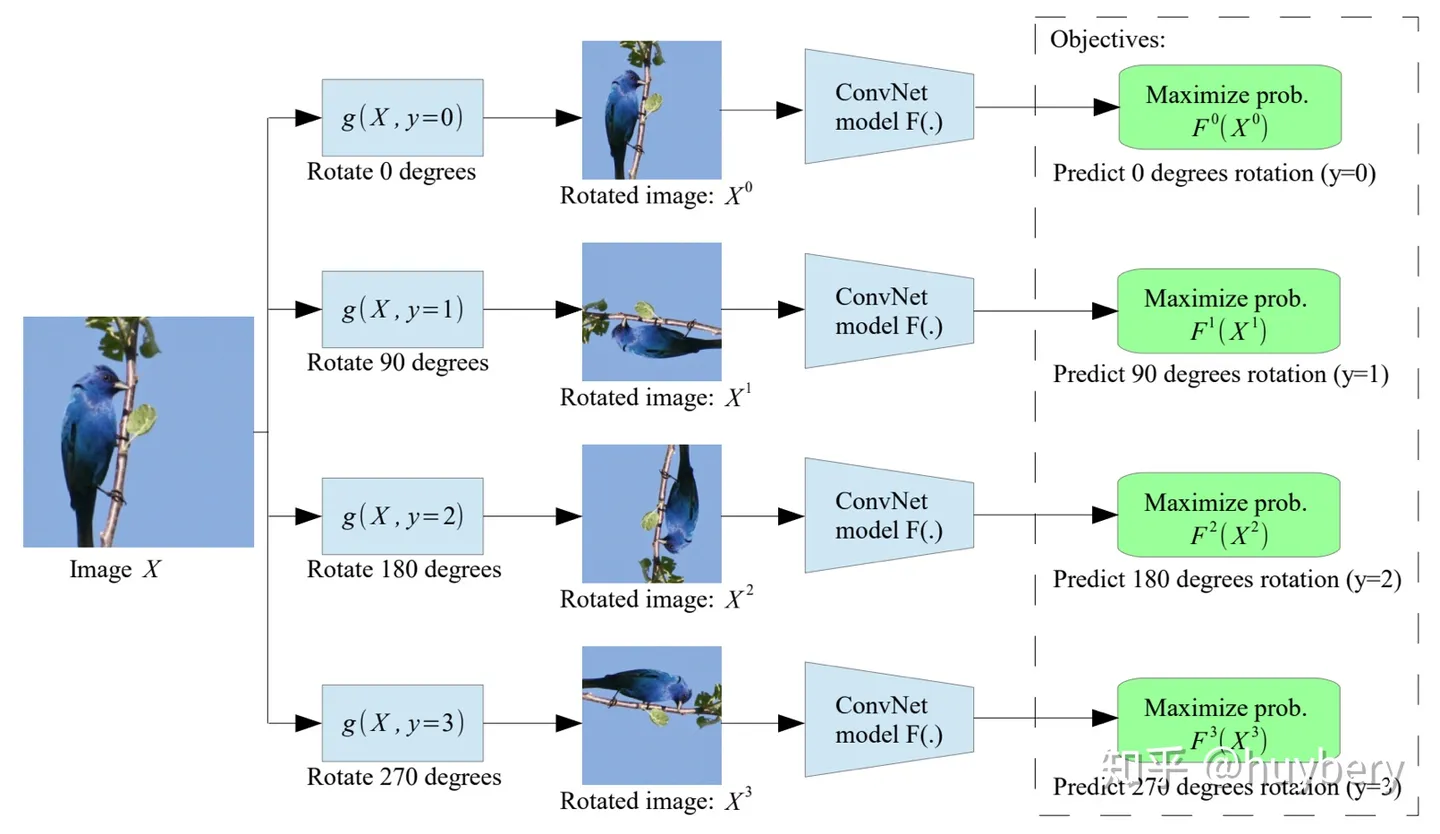
4.数据增广
给定一张输入的图片,我们对其进行不同角度的旋转,模型的目的是预测该图片的旋转角度。
文章中还出现了自监督和有监督学习first layer filters的比较:

可以看到,自监督的结果主要是各种频率的定向边缘过滤器。并且,相比有有监督学习,自监督增加了旋转角度的预测,因此有更多的种类。
2.基于时序
之前介绍的方法大多是基于样本自身的信息,比如旋转、色彩、裁剪等。而样本间其实也是具有很多约束关系的,这里我们来介绍利用时序约束来进行自监督学习的方法。最能体现时序的数据类型就是视频了(video)。
1.相邻特征相似性
视频中的相邻帧特征是相似的,而相隔较远的视频帧是不相似的,通过构建这种相似(position)和不相似(negative)的样本来进行自监督约束
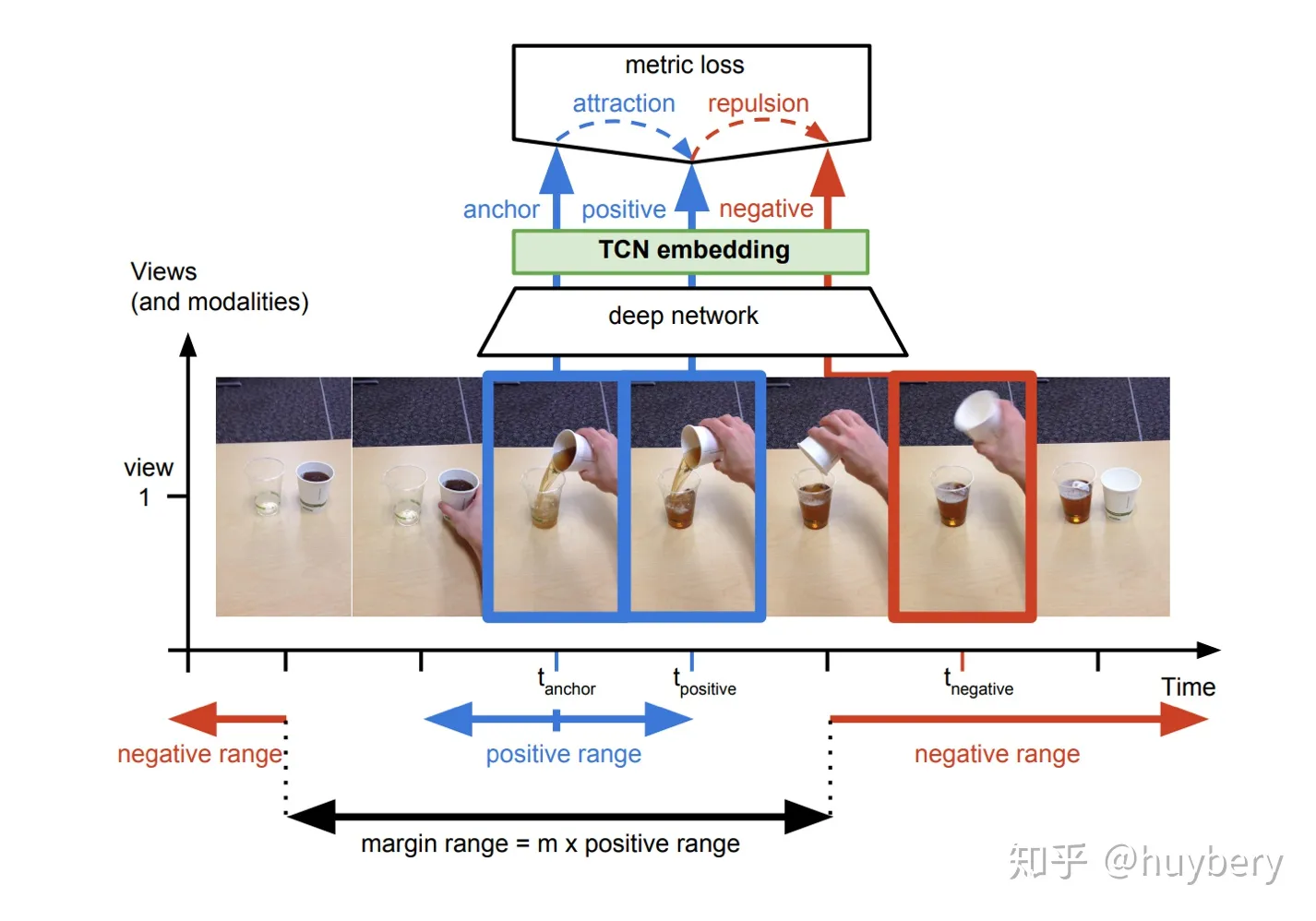
2.多视角相似性
对于同一个物体的拍摄是可能存在多个视角(multi-view),对于多个视角中的同一帧,可以认为特征是相似的,对于不同帧可以认为是不相似的。
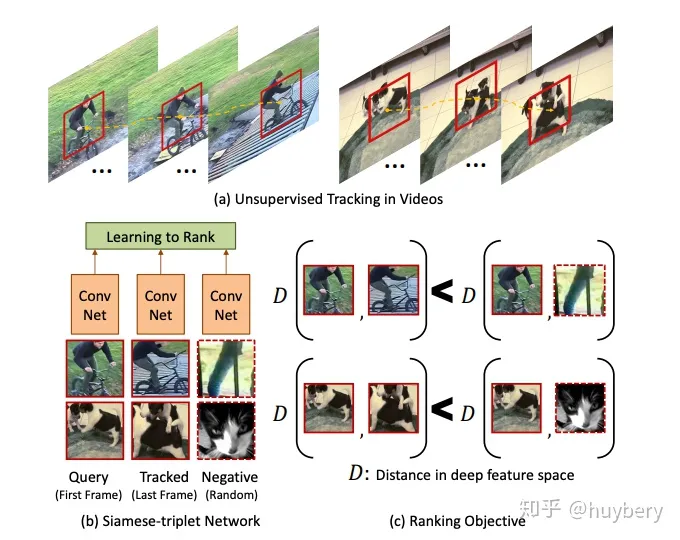
基于顺序的约束还被应用了到了对话系统中,ACL 2019 [20] 提出的自监督对话学习就是基于这种思想。这篇文章主要是想解决对话系统中生成的话术连贯性的问题,期待机器生成的回复和人类交谈一样是符合之前说话的风格、习惯等等。从大量的历史预料中挖掘出顺序的序列(positive)和乱序的序列(negative),通过模型来预测是否符合正确的顺序来进行训练。训练完成后就拥有了一个可以判断连贯性的模型,从而可以嵌入到对话系统中,最后利用对抗训练的方式生成更加连贯的话术。
3.基于对比
介绍的基于时序的方法已经涉及到了这种基于对比的约束,通过构建正样本(positive)和负样本(negative),然后度量正负样本的距离来实现自监督学习。核心思想样本和正样本之间的相似度远远大于样本和负样本之间的相似度。
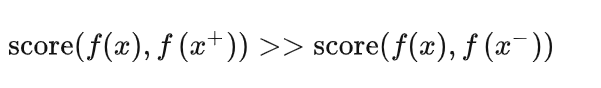
这里的 x 通常也称为 「anchor」数据,为了优化 anchor 数据和其正负样本的关系,我们可以使用点积的方式构造距离函数,然后构造一个 softmax 分类器,以正确分类正样本和负样本。
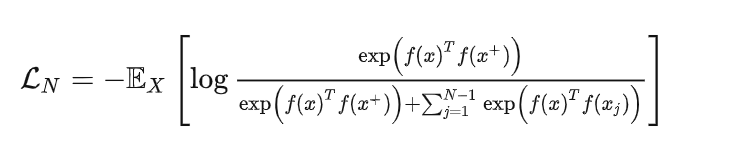
这个损失也被称为 InfoNCE,后面的所有工作也基本是围绕这个损失进行的。
对比学习和之前提到的生成学习有什么区别呢?

区别主要在两个方面:
- 损失计算的空间不同。生成或者预测类方法损失是在输出空间计算的;而对比方法的损失是在表征空间计算的。
- 对比方法有对相关性或复杂结构进行建模的能力,而不仅仅像生成方法一样基于像素进行特征学习。
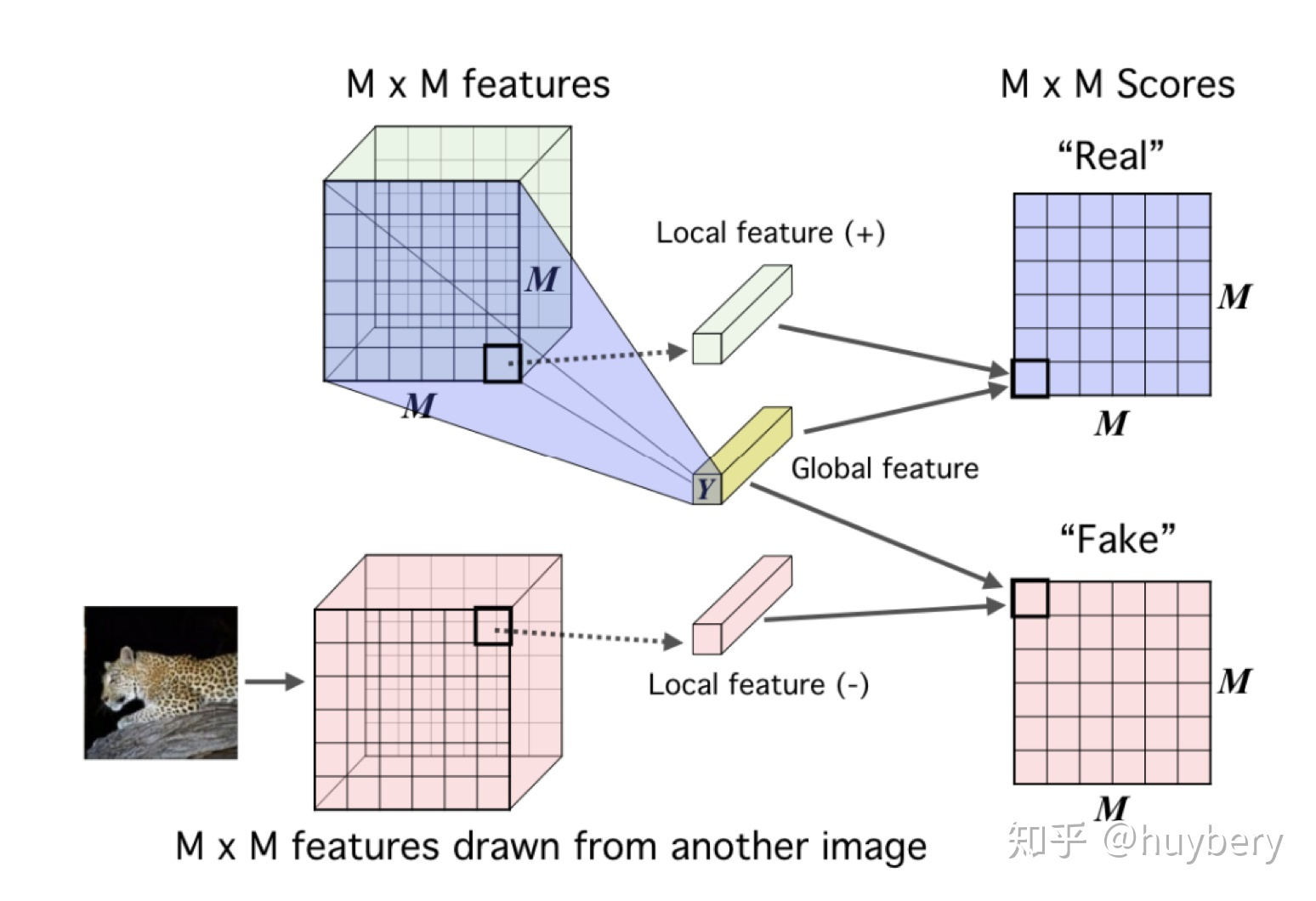
DIM
DIM 的具体思想是对于隐层的表达,对不同的图片用卷积encoder进行表征的提取,encoder最终的输出为全局的特征(global features);而中间层的输出为本地特征(local features),模型需要分类全局特征和局部特征是否来自同一图像。所以这里 x 是来自一幅图像的全局特征,正样本是该图像的局部特征,而负样本是其他图像的局部特征。
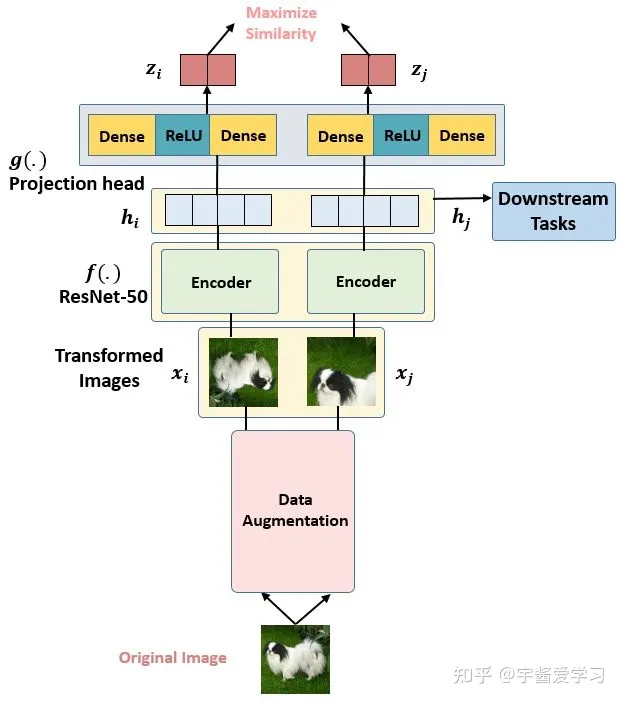
SimCLR
SimCLR V1是Hitom团队在2020年时提出的一种针对视觉的对比自监督模型。后续文章会详细讲解
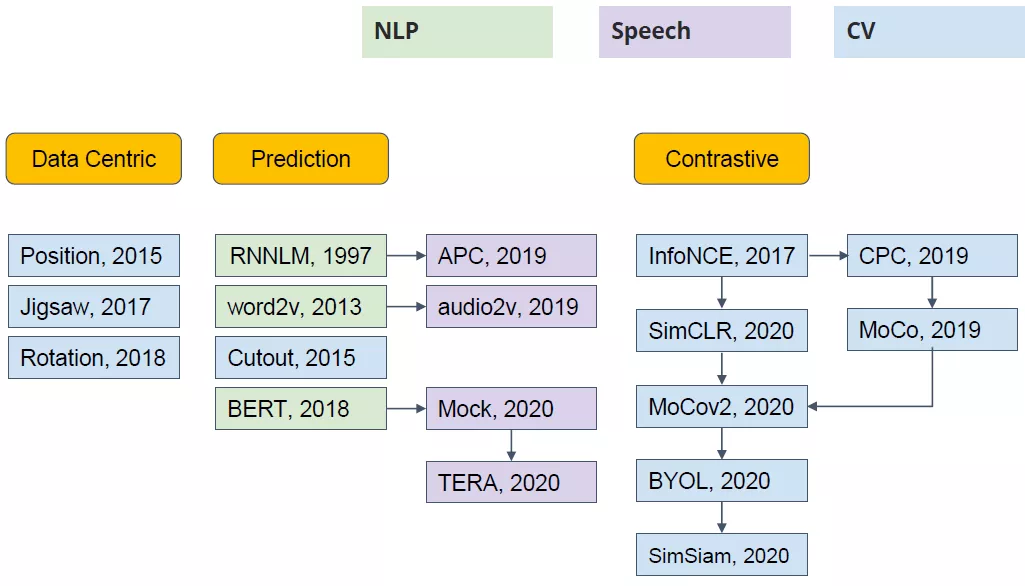
4、展望
自监督学习分类示意图
自监督学习在预训练模型中的成功让研究人员觉得非常兴奋,同时也激发了更多的灵感。越来越多的工作开始思考自监督学习和具体任务紧密结合的方法(Task Related Self-Supervised Learning)
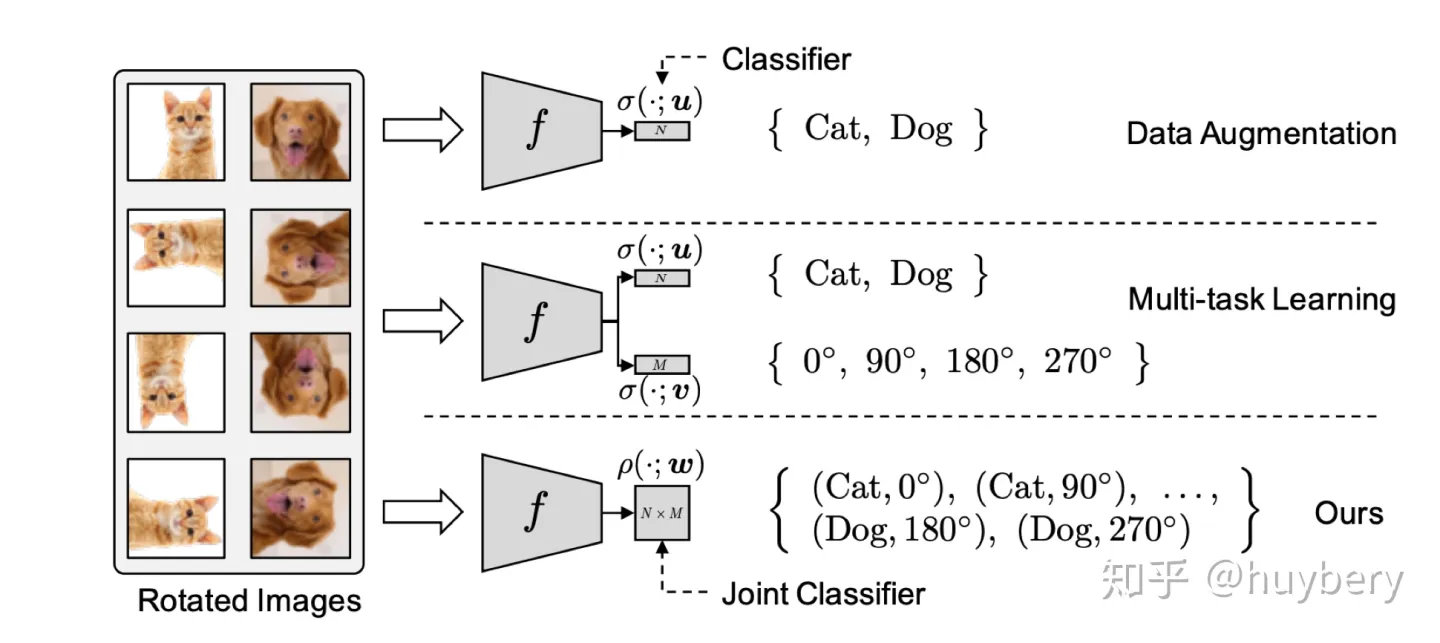
Lee, Hankook et al [14]探索了在多任务学习中增加自监督学习的可能,他们将普通的分类任务中嵌入了旋转预测任务。除了简单的多任务学习,也可以设计联合学习策略,直接预测两种监督信息。同样的想法也被用到了小样本学习[15]中,一个分支进行传统的小样本分类,另一个分支来进行自监督旋转预测,虽然这篇文章的想法和设计不是很亮眼,但提升还是比较明显的。
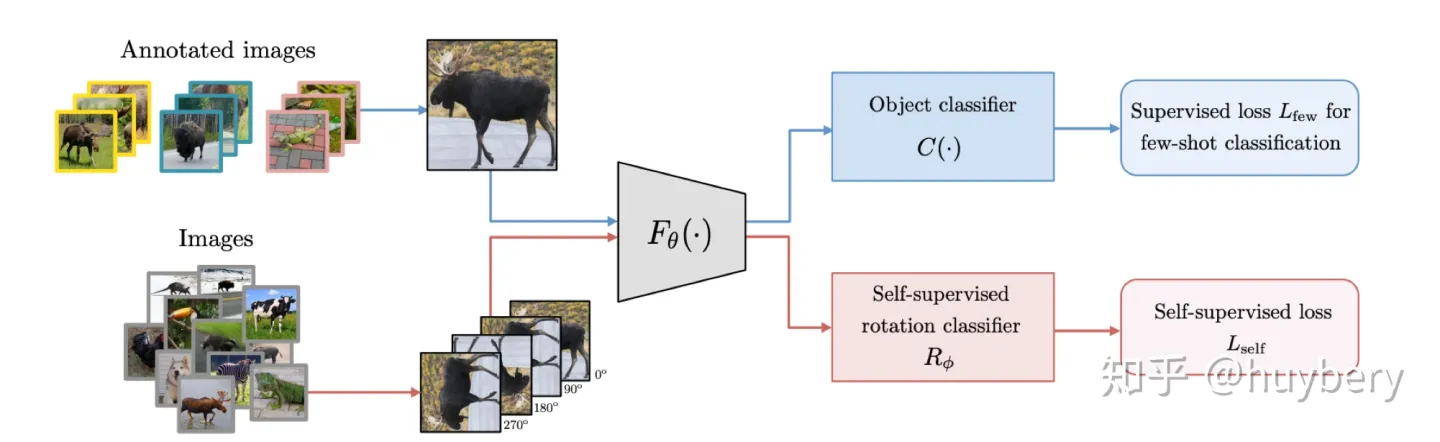
而自监督和半监督学习[16]也可以进行结合,对于无标记的数据进行自监督学习(旋转预测),和对于有标记数据,在进行自监督学习的同时利用联合训练的想法进行有监督学习
Lee, Hankook et al [14]探索了在多任务学习中增加自监督学习的可能,他们将普通的分类任务中嵌入了旋转预测任务。除了简单的多任务学习,也可以设计联合学习策略,直接预测两种监督信息。同样的想法也被用到了小样本学习[15]中,一个分支进行传统的小样本分类,另一个分支来进行自监督旋转预测,虽然这篇文章的想法和设计不是很亮眼,但提升还是比较明显的。

而自监督和半监督学习[16]也可以进行结合,对于无标记的数据进行自监督学习(旋转预测),和对于有标记数据,在进行自监督学习的同时利用联合训练的想法进行有监督学习


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通