STDC网络
为了做到实时推理,很多实时语义分割模型选用轻量骨干网络,但是由于task-specific design的不足,这些从分类任务中借鉴来的轻量级骨干网络可能并不适合解决分割问题。
除了选用轻量backbone,限制输入图像的大小是另一种提高推理速度的常用方法,但这很容易忽略边缘附近的细节和小物体。为了解决这个问题,BiSeNet采用了多路径结构将低层细节信息和高层语义信息相结合,但添加一个额外的路径来获取低层特征非常耗时,而且辅助路径总是缺乏低层信息的指导。
1 创新点
- Short-Term Dense Concatenate module(STDC module):本文设计了一种新的结构,通过少量参数就可获得不同大小的感受野以及多尺度信息。将STDC模块无缝集成到U-net架构中就得到了STDC network,大大提高了语义分割任务中的网络性能。
- Detail Guidance:在decoding阶段,采用Detail Guidance来引导低层空间细节信息的学习。利用Detail Aggregation module来生成细节的ground truth,然后利用bce loss和dice loss来优化细节信息的学习,这可以看作是一种side-information的学习,并且在推理时不需要这个side-information。
2 STDC模块的结构

若STDC模块的最终输出通道数为 C_{out}^{'},除最后一个 block 外,该模块内第 i 个 block 的输出通道数为 C_{out}^{(i)};最后一个 block 的输出特征通道数与倒数第二个 block 保持一致。
与传统的 backbone 不同的是,STDC 模块中深层的特征通道数较少,浅层的特征通道数较多。作者认为,浅层需要更多通道的特征来编码细节信息;而深层更关注高层次语义信息,过多的特征通道数量会导致信息冗余。
对于采用stride=2的STDC模块,我们会在模块内进行下采样操作,以减少计算量。然而,为了确保在不同尺寸的feature map融合时尺寸一致,我们会对较大尺寸的feature map进行下采样,采用stride=2的average pooling操作。
class STDCModule(BaseModule):
"""STDCModule.
Args:
in_channels (int): The number of input channels.
out_channels (int): The number of output channels before scaling.
stride (int): The number of stride for the first conv layer.
norm_cfg (dict): Config dict for normalization layer. Default: None.
act_cfg (dict): The activation config for conv layers.
num_convs (int): Numbers of conv layers.
fusion_type (str): Type of fusion operation. Default: 'add'.
init_cfg (dict or list[dict], optional): Initialization config dict.
Default: None.
"""
def __init__(self,
in_channels,
out_channels,
stride,
norm_cfg=None,
act_cfg=None,
num_convs=4,
fusion_type='add',
init_cfg=None):
super().__init__(init_cfg=init_cfg)
assert num_convs > 1
assert fusion_type in ['add', 'cat']
self.stride = stride
self.with_downsample = True if self.stride == 2 else False
self.fusion_type = fusion_type
self.layers = ModuleList()
#重点关注layers的创建
#4、创建1*1卷积核,输出通道减半
conv_0 = ConvModule(
in_channels, out_channels // 2, kernel_size=1, norm_cfg=norm_cfg)
#5、在B图中,第一步要进行下采样,为此需要再连接卷积或者下采样
if self.with_downsample:
#6、下采样时,创建的卷积,此时输入输出通道保持不变,stride为2,实现下采样
self.downsample = ConvModule(
out_channels // 2,
out_channels // 2,
kernel_size=3,
stride=2,
padding=1,
groups=out_channels // 2,
norm_cfg=norm_cfg,
act_cfg=None)
#7、将conv1和降采样加入到layer中
self.layers.append(nn.Sequential(conv_0, self.downsample))
if self.fusion_type == 'add':
self.skip = Sequential(
ConvModule(
in_channels,
in_channels,
kernel_size=3,
stride=2,
padding=1,
groups=in_channels,
norm_cfg=norm_cfg,
act_cfg=None),
ConvModule(
in_channels,
out_channels,
1,
norm_cfg=norm_cfg,
act_cfg=None))
else:
#self.layers.append(conv_0)
self.skip = nn.AvgPool2d(kernel_size=3, stride=2, padding=1)
else:
self.layers.append(conv_0)
for i in range(1, num_convs):
#8、最后一个为2**1,其他为2**(i+1),如此保证除了最后一层,其他通道减半
out_factor = 2**(i + 1) if i != num_convs - 1 else 2**i
self.layers.append(
ConvModule(
out_channels // 2**i,
out_channels // out_factor,
kernel_size=3,
stride=1,
padding=1,
norm_cfg=norm_cfg,
act_cfg=act_cfg))
def forward(self, inputs):
#1、网络forwrd,两种方式,一种加,一种连接
if self.fusion_type == 'add':
out = self.forward_add(inputs)
else:
out = self.forward_cat(inputs)
return out
def forward_add(self, inputs):
layer_outputs = []
x = inputs.clone()
#2、将特征图放入到卷积网络中,一边继续卷积,一边放入到list中
for layer in self.layers:
x = layer(x)
layer_outputs.append(x)
# 当stride为2时,进行下采样,即B图
if self.with_downsample:
inputs = self.skip(inputs)
#3、将网络cat,然后在与输入相加,当然输出的大小和inputs的shape相同
return torch.cat(layer_outputs, dim=1) + inputs
def forward_cat(self, inputs):
x0 = self.layers[0](inputs)
layer_outputs = [x0]
for i, layer in enumerate(self.layers[1:]):
if i == 0:
if self.with_downsample:
x = layer(self.downsample(x0))
else:
x = layer(x0)
else:
x = layer(x)
layer_outputs.append(x)
if self.with_downsample:
layer_outputs[0] = self.skip(x0)
return torch.cat(layer_outputs, dim=1)
STDC模块内部执行时,通道每经过一次卷积操作是越来越少,但最终输出通道保持不变(毕竟cat)
1/2+1/4+1/8+1/8= 1。
3.Network Architecture
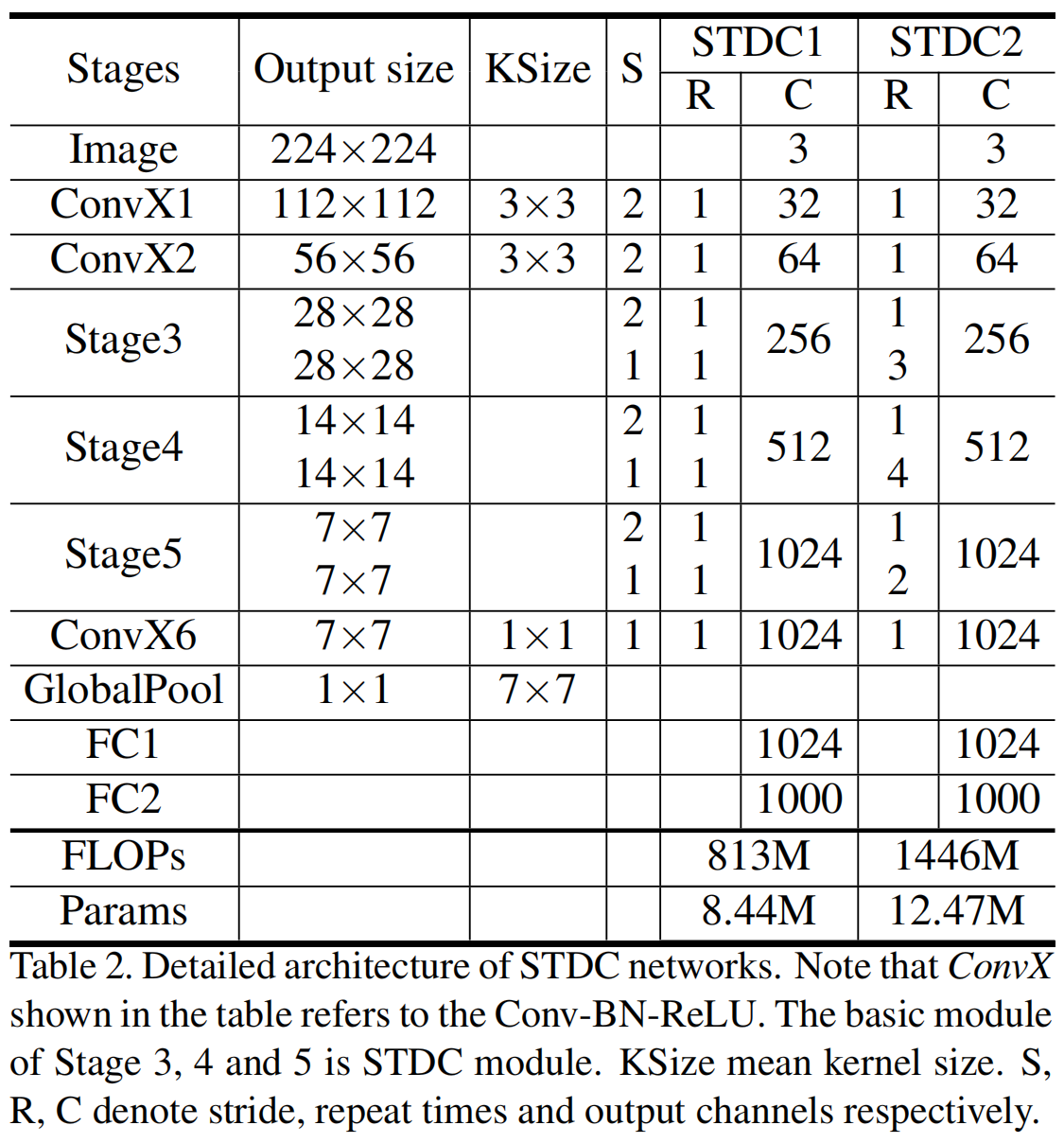
网络的完整结构如图3(a)所示,一共包含6个stage,其中stage1-5中分别进行一次stride=2的下采样,stage6通过一个ConvX一个全局平均池化和两个全连接层得到最终prediction logits。
stage1&2通常作为low-level层提取外观特征,为了追求效率,每个stage中只有一个卷积block。stage3,4,5中STDC module的个数经过仔细调整确定的,其中每个stage的第一个STDC module进行下采样。STDC network的详细结构如表2所示
class STDCNet(BaseModule):
"""This backbone is the implementation of `Rethinking BiSeNet For Real-time
Semantic Segmentation <https://arxiv.org/abs/2104.13188>`_.
Args:
stdc_type (int): The type of backbone structure,
`STDCNet1` and`STDCNet2` denotes two main backbones in paper,
whose FLOPs is 813M and 1446M, respectively.
in_channels (int): The num of input_channels.
channels (tuple[int]): The output channels for each stage.
bottleneck_type (str): The type of STDC Module type, the value must
be 'add' or 'cat'.
norm_cfg (dict): Config dict for normalization layer.
act_cfg (dict): The activation config for conv layers.
num_convs (int): Numbers of conv layer at each STDC Module.
Default: 4.
with_final_conv (bool): Whether add a conv layer at the Module output.
Default: True.
pretrained (str, optional): Model pretrained path. Default: None.
init_cfg (dict or list[dict], optional): Initialization config dict.
Default: None.
Example:
>>> import torch
>>> stdc_type = 'STDCNet1'
>>> in_channels = 3
>>> channels = (32, 64, 256, 512, 1024)
>>> bottleneck_type = 'cat'
>>> inputs = torch.rand(1, 3, 1024, 2048)
>>> self = STDCNet(stdc_type, in_channels,
... channels, bottleneck_type).eval()
>>> outputs = self.forward(inputs)
>>> for i in range(len(outputs)):
... print(f'outputs[{i}].shape = {outputs[i].shape}')
outputs[0].shape = torch.Size([1, 256, 128, 256])
outputs[1].shape = torch.Size([1, 512, 64, 128])
outputs[2].shape = torch.Size([1, 1024, 32, 64])
"""
arch_settings = {
'STDCNet1': [(2, 1), (2, 1), (2, 1)],
'STDCNet2': [(2, 1, 1, 1), (2, 1, 1, 1, 1), (2, 1, 1)]
}
def __init__(self,
stdc_type,
in_channels,
channels,
bottleneck_type,
norm_cfg,
act_cfg,
num_convs=4,
with_final_conv=False,
pretrained=None,
init_cfg=None):
super().__init__(init_cfg=init_cfg)
assert stdc_type in self.arch_settings, \
f'invalid structure {stdc_type} for STDCNet.'
assert bottleneck_type in ['add', 'cat'],\
f'bottleneck_type must be `add` or `cat`, got {bottleneck_type}'
assert len(channels) == 5,\
f'invalid channels length {len(channels)} for STDCNet.'
self.in_channels = in_channels
self.channels = channels
self.stage_strides = self.arch_settings[stdc_type]
self.prtrained = pretrained
self.num_convs = num_convs
self.with_final_conv = with_final_conv
self.stages = ModuleList([
ConvModule(
self.in_channels,
self.channels[0],
kernel_size=3,
stride=2,
padding=1,
norm_cfg=norm_cfg,
act_cfg=act_cfg),
ConvModule(
self.channels[0],
self.channels[1],
kernel_size=3,
stride=2,
padding=1,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
])
# `self.num_shallow_features` is the number of shallow modules in
# `STDCNet`, which is noted as `Stage1` and `Stage2` in original paper.
# They are both not used for following modules like Attention
# Refinement Module and Feature Fusion Module.
# Thus they would be cut from `outs`. Please refer to Figure 4
# of original paper for more details.
self.num_shallow_features = len(self.stages)
for strides in self.stage_strides:
idx = len(self.stages) - 1
self.stages.append(
self._make_stage(self.channels[idx], self.channels[idx + 1],
strides, norm_cfg, act_cfg, bottleneck_type))
# After appending, `self.stages` is a ModuleList including several
# shallow modules and STDCModules.
# (len(self.stages) ==
# self.num_shallow_features + len(self.stage_strides))
if self.with_final_conv:
self.final_conv = ConvModule(
self.channels[-1],
max(1024, self.channels[-1]),
1,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
def _make_stage(self, in_channels, out_channels, strides, norm_cfg,
act_cfg, bottleneck_type):
layers = []
for i, stride in enumerate(strides):
layers.append(
STDCModule(
in_channels if i == 0 else out_channels,
out_channels,
stride,
norm_cfg,
act_cfg,
num_convs=self.num_convs,
fusion_type=bottleneck_type))
return Sequential(*layers)
def forward(self, x):
outs = []
for stage in self.stages:
x = stage(x)
outs.append(x)
if self.with_final_conv:
outs[-1] = self.final_conv(outs[-1])
outs = outs[self.num_shallow_features:]
return tuple(outs)
4.Segmentation Architecture
预训练的STDC network作为encoder的backbone,并且用BiSeNet中的context path来编码上下文信息。
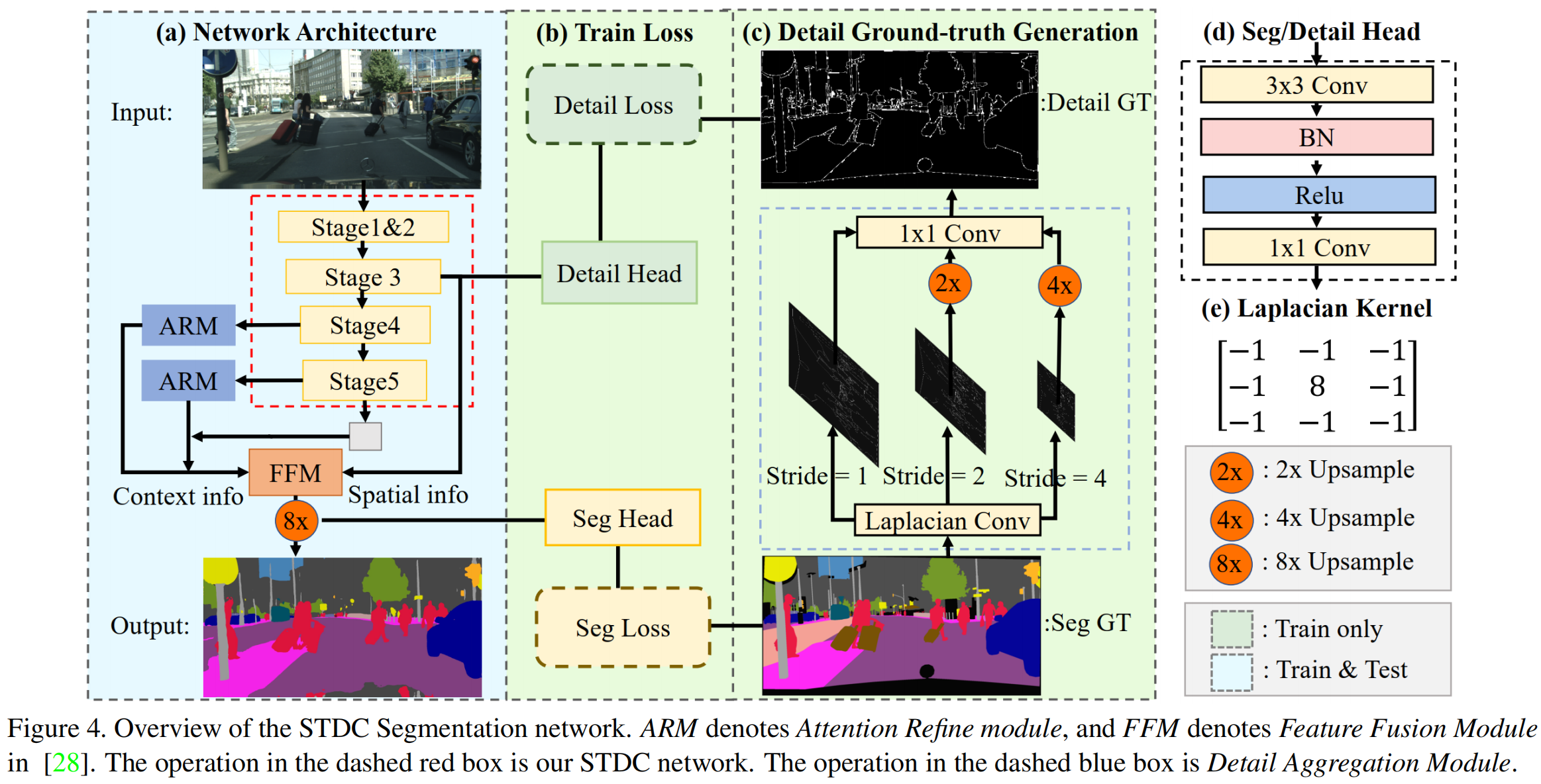
- stage3, 4, 5来生成降采样率分别为1/8, 1/16, 1/32的特征图。
- 使用全局平均池化来提供具有较大感受野的全局上下文信息。
- 接着使用U-shape结构进行上采样,并与encoding阶段对应部分(stage4, 5)进行融合。
融合结果作为Feature Fusion Module (FFM)的输入,提供高层次语义信息,而FFM的另一个输入则为Stage3输出的特征,提供低层次细节信息。FFM的输出特征通过上采样进入Seg Head,Seg Head包括卷积、BN和ReLU操作,以及卷积,最终输出维度特征,即分割类别数。
class STDCContextPathNet(BaseModule):
"""STDCNet with Context Path. The `outs` below is a list of three feature
maps from deep to shallow, whose height and width is from small to big,
respectively. The biggest feature map of `outs` is outputted for
`STDCHead`, where Detail Loss would be calculated by Detail Ground-truth.
The other two feature maps are used for Attention Refinement Module,
respectively. Besides, the biggest feature map of `outs` and the last
output of Attention Refinement Module are concatenated for Feature Fusion
Module. Then, this fusion feature map `feat_fuse` would be outputted for
`decode_head`. More details please refer to Figure 4 of original paper.
Args:
backbone_cfg (dict): Config dict for stdc backbone.
last_in_channels (tuple(int)), The number of channels of last
two feature maps from stdc backbone. Default: (1024, 512).
out_channels (int): The channels of output feature maps.
Default: 128.
ffm_cfg (dict): Config dict for Feature Fusion Module. Default:
`dict(in_channels=512, out_channels=256, scale_factor=4)`.
upsample_mode (str): Algorithm used for upsampling:
``'nearest'`` | ``'linear'`` | ``'bilinear'`` | ``'bicubic'`` |
``'trilinear'``. Default: ``'nearest'``.
align_corners (str): align_corners argument of F.interpolate. It
must be `None` if upsample_mode is ``'nearest'``. Default: None.
norm_cfg (dict): Config dict for normalization layer.
Default: dict(type='BN').
init_cfg (dict or list[dict], optional): Initialization config dict.
Default: None.
Return:
outputs (tuple): The tuple of list of output feature map for
auxiliary heads and decoder head.
"""
def __init__(self,
backbone_cfg,
last_in_channels=(1024, 512),
out_channels=128,
ffm_cfg=dict(
in_channels=512, out_channels=256, scale_factor=4),
upsample_mode='nearest',
align_corners=None,
norm_cfg=dict(type='BN'),
init_cfg=None):
super().__init__(init_cfg=init_cfg)
self.backbone = MODELS.build(backbone_cfg)
self.arms = ModuleList()
self.convs = ModuleList()
#将注意力模块添加到数组中,注意通道数和输入
for channels in last_in_channels:
#此处通道数先1024,再512
self.arms.append(AttentionRefinementModule(channels, out_channels))
self.convs.append(
ConvModule(
out_channels,
out_channels,
3,
padding=1,
norm_cfg=norm_cfg))
self.conv_avg = ConvModule(
last_in_channels[0], out_channels, 1, norm_cfg=norm_cfg)
#特征融合模块,在执行完arm后,将各个特征图进行融合
self.ffm = FeatureFusionModule(**ffm_cfg)
self.upsample_mode = upsample_mode
self.align_corners = align_corners
def forward(self, x):
#1、stdc主干网络的特曲提出,此处会有多尺度的网络获取
outs = list(self.backbone(x))
#2、最后一层的输出进行全局池化,获取上下文信息
avg = F.adaptive_avg_pool2d(outs[-1], 1)
avg_feat = self.conv_avg(avg)
#3、上采样操作
feature_up = resize(
avg_feat,
size=outs[-1].shape[2:],
mode=self.upsample_mode,
align_corners=self.align_corners)
arms_out = []
for i in range(len(self.arms)):
#4、从后开始提取特征图,分别为1/32,1/16的特征图
x_arm = self.arms[i](outs[len(outs) - 1 - i]) + feature_up
#5、上采样操作,并进行卷积
feature_up = resize(
x_arm,
size=outs[len(outs) - 1 - i - 1].shape[2:],
mode=self.upsample_mode,
align_corners=self.align_corners)
feature_up = self.convs[i](feature_up)
arms_out.append(feature_up)
#6、两个的arm输出进行特征融合
feat_fuse = self.ffm(outs[0], arms_out[1])
# The `outputs` has four feature maps.
# `outs[0]` is outputted for `STDCHead` auxiliary head.
# Two feature maps of `arms_out` are outputted for auxiliary head.
# `feat_fuse` is outputted for decoder head.
#此处outs[0]看主干网络的forward,则是为1/8的输出
outputs = [outs[0]] + list(arms_out) + [feat_fuse]
return tuple(outputs)
具体的网络配置为:
model = dict(
type='EncoderDecoder',
data_preprocessor=data_preprocessor,
pretrained=None,
backbone=dict(
type='STDCContextPathNet',
backbone_cfg=dict(
type='STDCNet',
stdc_type='STDCNet1',
in_channels=3,
channels=(32, 64, 256, 512, 1024),
bottleneck_type='cat',
num_convs=4,
norm_cfg=norm_cfg,
act_cfg=dict(type='ReLU'),
with_final_conv=False),
last_in_channels=(1024, 512),
out_channels=128,
ffm_cfg=dict(in_channels=384, out_channels=256, scale_factor=4)),
decode_head=dict(
type='FCNHead',
in_channels=256,
channels=256,
num_convs=1,
num_classes=19,
in_index=3,
concat_input=False,
dropout_ratio=0.1,
norm_cfg=norm_cfg,
align_corners=True,
sampler=dict(type='OHEMPixelSampler', thresh=0.7, min_kept=10000),
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
auxiliary_head=[
dict(
type='FCNHead',
in_channels=128,
channels=64,
num_convs=1,
num_classes=19,
in_index=2,
norm_cfg=norm_cfg,
concat_input=False,
align_corners=False,
sampler=dict(type='OHEMPixelSampler', thresh=0.7, min_kept=10000),
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
dict(
type='FCNHead',
in_channels=128,
channels=64,
num_convs=1,
num_classes=19,
in_index=1,
norm_cfg=norm_cfg,
concat_input=False,
align_corners=False,
sampler=dict(type='OHEMPixelSampler', thresh=0.7, min_kept=10000),
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
dict(
type='STDCHead',
in_channels=256,
channels=64,
num_convs=1,
num_classes=2,
boundary_threshold=0.1,
#此处对应的1/8的输出,然后接入到新提出的stdc-head
in_index=0,
norm_cfg=norm_cfg,
concat_input=False,
align_corners=True,
loss_decode=[
dict(
type='CrossEntropyLoss',
loss_name='loss_ce',
use_sigmoid=True,
loss_weight=1.0),
#引入了两个loss,具体见下节讲解
dict(type='DiceLoss', loss_name='loss_dice', loss_weight=1.0)
]),
],
Detail Head
为了弥补去除BiSeNet中的Spatial分支造成的细节损失,作者在Stage3后面插入了Detail Head。该Detail Head仅在训练时使用,目的是让Stage3输出的特征图包含更多的细节特征,以便与Context分支的高层次语义特征融合。
为了训练Detail Head,作者使用Laplacian Conv对标签进行步长为1、2、4的卷积,将步长为2和步长为4的输出结果进行和的上采样,再使用可学习参数的卷积进行融合。最终通过0.1的阈值输出2值Ground Truth,以得到Detail Head的Ground Truth。
在上述操作生成的ground truth中,细节特征所占的像素远少于非细节所占的像素,因此Detail Head部分面临着类别不均衡问题。于是就联合使用binary cross-entropy loss和dice loss,dice loss可以缓解类别不均衡问题。
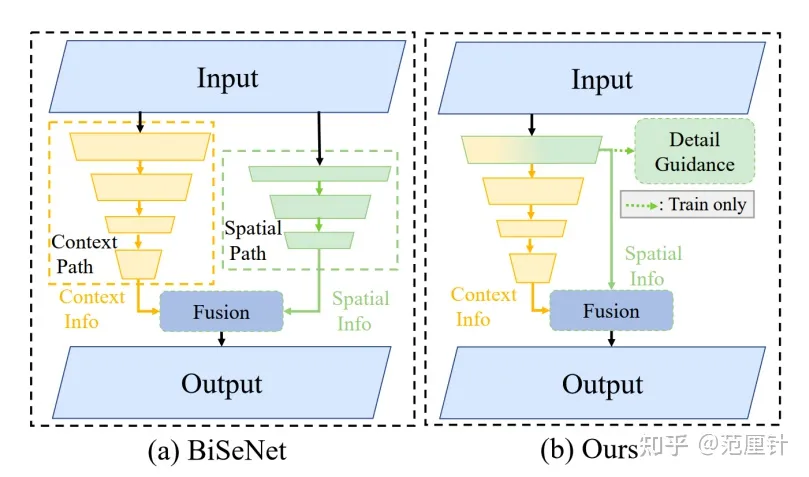
其中Detail Head包括1个的卷积、BN和ReLU操作,以及1个卷积。STDC分割网络和BiSeNet在总体结构上的差异如下图所示:
utputs = [outs[0]] + list(arms_out) + [feat_fuse]
# (16,256,60,60) + [(16,128,30,30),(16,128,60,60)] + (16,256,60,60)
其中outs[0]是stage3的输出,后续需要接Detail Head。arms_out是两个ARM模块的输出,在mmseg的实现中,对这两个输出用FCN当做auxiliary head进行监督(论文中没有提到),推理阶段去除。feat_fuse就是spatial info和context info经过FFM融合后的输出,后接FCN,并用bce loss + dice loss进行优化。
Detail Head的ground truth的生成代码如下,其中提到虽然论文中说经过三个不同步长的拉普拉斯卷积后用一个可训练的1x1卷积对三者进行融合,但在官方实现和其它第三方实现中,并没有使用可训练的1x1卷积,因此这里也是用了一个不可训练参数提前设定不随训练更新的fusion_kernel进行融合。
实验结果
STDC用于分类
在ImageNet数据集上训练STDC,并在验证集上进行测试,测试结果如下:
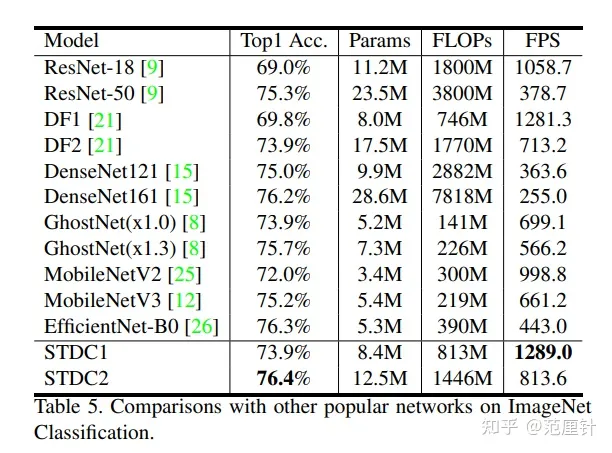
从上图中可以看出,STDC系列网络兼顾性能和计算速度。
STDC用于分割
本文介绍了使用Cityscapes数据集训练STDC分割网络的实验结果。在实验中,我们分别使用不同分辨率的图片作为网络输入,将输出结果上采样至特定分辨率。训练集和验证集被用来模型训练,之后在测试集上进行测试,结果如下表所示。
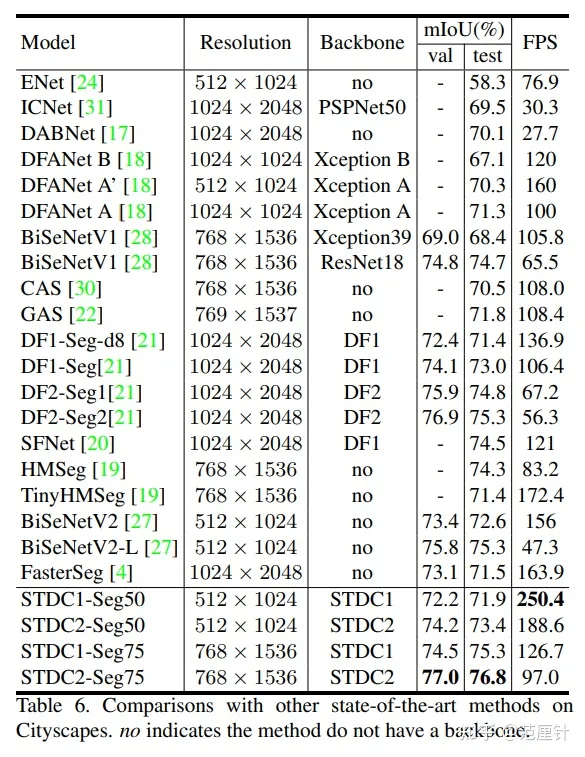
Seg50表示输入图片分辨率为50%,Seg75表示输入图片分辨率为75%。
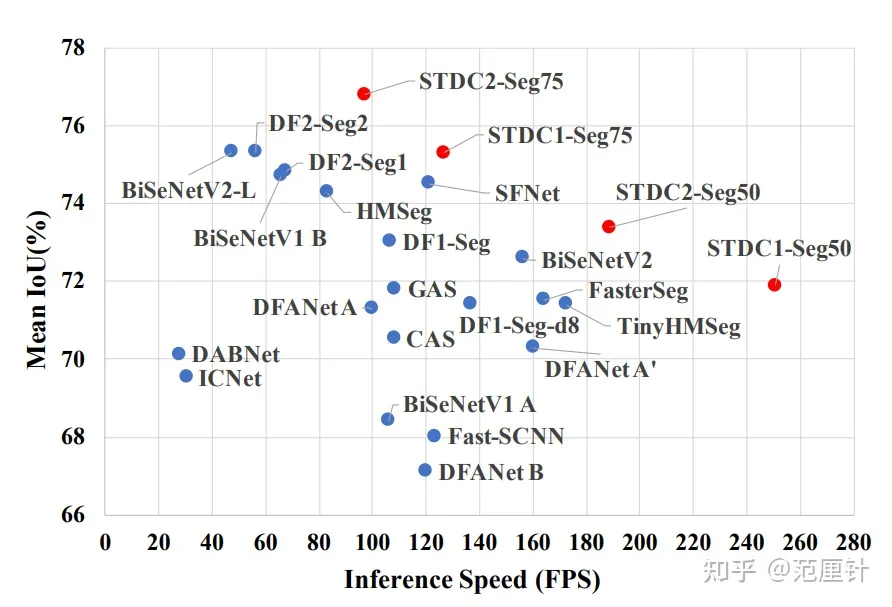
实验结果表明,STDC分割网络在保持高推理速度的同时有着更高的精度。如下图所示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号