Bisenet系列
一、BiSeNet
1.1 背景
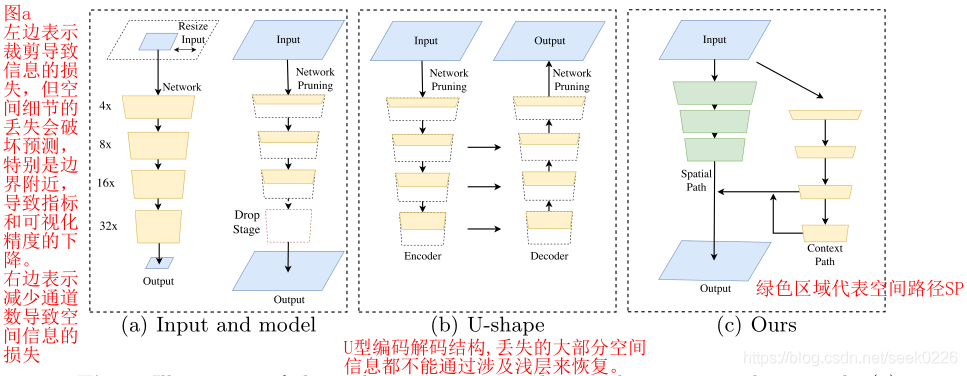
作者对比了当前用于三种用于加速模型的实时语义分割算法:
图(a)左侧所示,通过裁剪图片降低尺寸和计算量,但是会丢失大量边界信息和可视化精度。
图(a)右侧所示,通过修建/减少卷积过程中的通道数目,提高推理速度。其中的红色方框部分,是作者提及的ENet建议放弃模型的最后阶段(downsample操作),模型的接受域不足以覆盖较大的对象导致的识别能力较差。
图形(b)所示为U型的编码,解码结构,通过融合骨干网的细节,u型结构提高了空间分辨率,填补了一些缺失的细节,但是作者认为在u型结构中,一些丢失的空间信息无法轻易回复,不是根本的解决方案。
1.2 网络结构
BiSeNet中设计了一个双边结构,分别为空间路径(Spatial Path)和上下文路径(Context Path)。通过一个特征融合模块(FFM)将两个路径的特征进行融合,得到分割结果。
在模型的一些细节上,作者主要引入了这么些个模块:
- 两个路径Spatial Path + Context Path
- U型的网络结构
- Attention机制(ARM模块)
- 特征融合模块 FFM
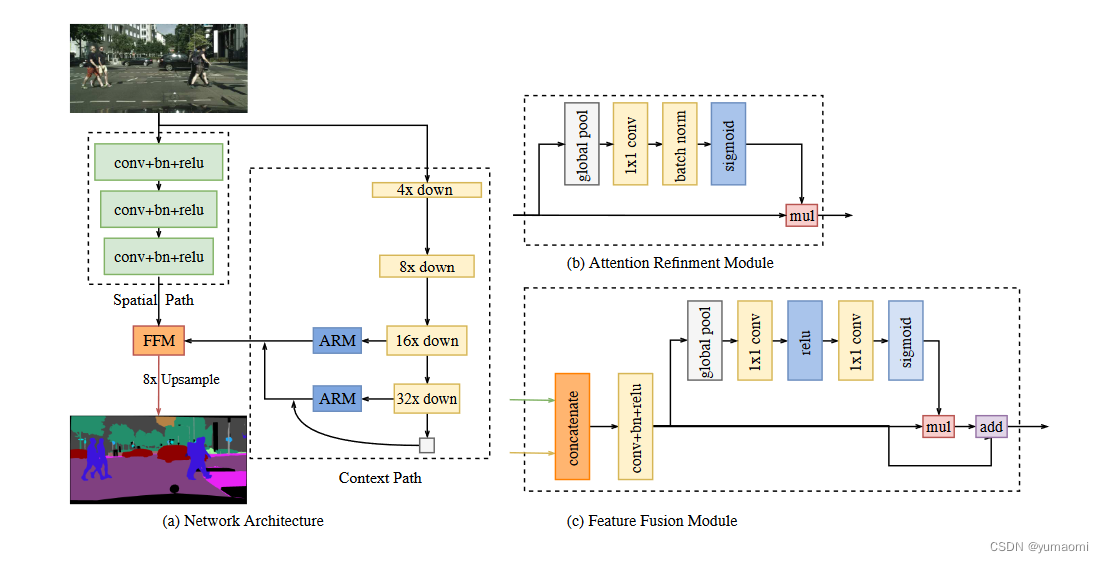
空间路径:计了一个简单但有效的快速下采样的空间路径,通过3个Conv+BN+ReLU的组合层将原图快速下采样8倍(通过卷积层的步幅来调整),保留空间信息的同时,速度却不慢。
上下文路径:在这个路径中,可以通过Xception或者ResNet来快速下采样到16倍和32倍,并且,作者设计了一个半U的结构,也就是只使用16x和32x下采样倍率的特征图,在保留信息的同时,不增加过多的计算量。每一个特征图都通过一个Attention Refinement Module(ARM)来计算Attention vector,突出特征。
在32x特征图的下方,作者还设计了一个全局池化的小模块,计算一个池化后的向量,加到32x特征图的ARM输出中。
特征融合模块FFM:FFM模块用于编码两个分支的特征,设计了一个类似注意力机制的融合模块,编码空间路径(低级别信息)和上下文路径(低级别信息)的输出。最后将结果上采样8倍得到原图。
1.3 代码讲解
网络配置详情:

在网络配置中主干网络为bisenetV1,在head层有解码和辅助解码头
主干网络的代码为:
def forward(self, x):
# stole refactoring code from Coin Cheung, thanks
#此处变量命名错误,从源码看出,为16,32
x_context8, x_context16 = self.context_path(x)
x_spatial = self.spatial_path(x)
x_fuse = self.ffm(x_spatial, x_context8)
outs = [x_fuse, x_context8, x_context16]
outs = [outs[i] for i in self.out_indices]
return tuple(outs)
代码比较清晰,分为空间和上下文以及FFM将这三层分别送入到head层。
FeatureFusionModule的代码为:
def forward(self, x_sp, x_cp):
#上下文和空间信息连接
x_concat = torch.cat([x_sp, x_cp], dim=1)
x_fuse = self.conv1(x_concat)
#池化
x_atten = self.gap(x_fuse)
# Note: No BN and more 1x1 conv in paper.
#注意力模块
x_atten = self.conv_atten(x_atten)
#相乘
x_atten = x_fuse * x_atten
#相加输出
x_out = x_atten + x_fuse
return x_out
ContextPath 上下文代码
def forward(self, x):
#正如配置文件所示,从resnet18中输出各个阶段的特征图
x_4, x_8, x_16, x_32 = self.backbone(x)
#32出来的特征图进行全局池化和卷积
x_gap = self.gap_conv(x_32)
#32进行arm的操作
x_32_arm = self.arm32(x_32)
x_32_sum = x_32_arm + x_gap
#上采样操作变成了16
x_32_up = resize(input=x_32_sum, size=x_16.shape[2:], mode='nearest')
x_32_up = self.conv_head32(x_32_up)
#相同的操作
x_16_arm = self.arm16(x_16)
x_16_sum = x_16_arm + x_32_up
x_16_up = resize(input=x_16_sum, size=x_8.shape[2:], mode='nearest')
x_16_up = self.conv_head16(x_16_up)
#最终输出两个尺度的特征图
return x_16_up, x_32_up
AttentionRefinement的代码为:
class AttentionRefinementModule(BaseModule):
"""Attention Refinement Module (ARM) to refine the features of each stage.
Args:
in_channels (int): The number of input channels.
out_channels (int): The number of output channels.
Returns:
x_out (torch.Tensor): Feature map of Attention Refinement Module.
"""
def __init__(self,
in_channels,
out_channel,
conv_cfg=None,
norm_cfg=dict(type='BN'),
act_cfg=dict(type='ReLU'),
init_cfg=None):
super().__init__(init_cfg=init_cfg)
self.conv_layer = ConvModule(
in_channels=in_channels,
out_channels=out_channel,
kernel_size=3,
stride=1,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
self.atten_conv_layer = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
ConvModule(
in_channels=out_channel,
out_channels=out_channel,
kernel_size=1,
bias=False,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=None), nn.Sigmoid())
def forward(self, x):
x = self.conv_layer(x)
x_atten = self.atten_conv_layer(x)
x_out = x * x_atten
return x_out
SpatialPath的源码为:
class SpatialPath(nn.Module):
def __init__(self):
super(SpatialPath, self).__init__()
self.downpath = nn.Sequential(
nn.Conv2d(3, 64, 7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, 64, 3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, 64, 3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, 128, 1),
nn.BatchNorm2d(128),
nn.ReLU(),
)
def forward(self, x):
return self.downpath(x)
在backbone输出后,各个特征图根据index进入到指定的head进行loss计算,最终进行更新。
二、BisetNetV2
背景介绍
相对于V1版本,改动点为:
- V2简化了原始结构,使网络更加高效
- 设计了Semantic Branch的网络,使用更加轻巧的深度可分离卷积来加速模型。
- 设计了更为有效的Aggregation Layer,以增强Semantic Branch和Detail Branch之间的链接
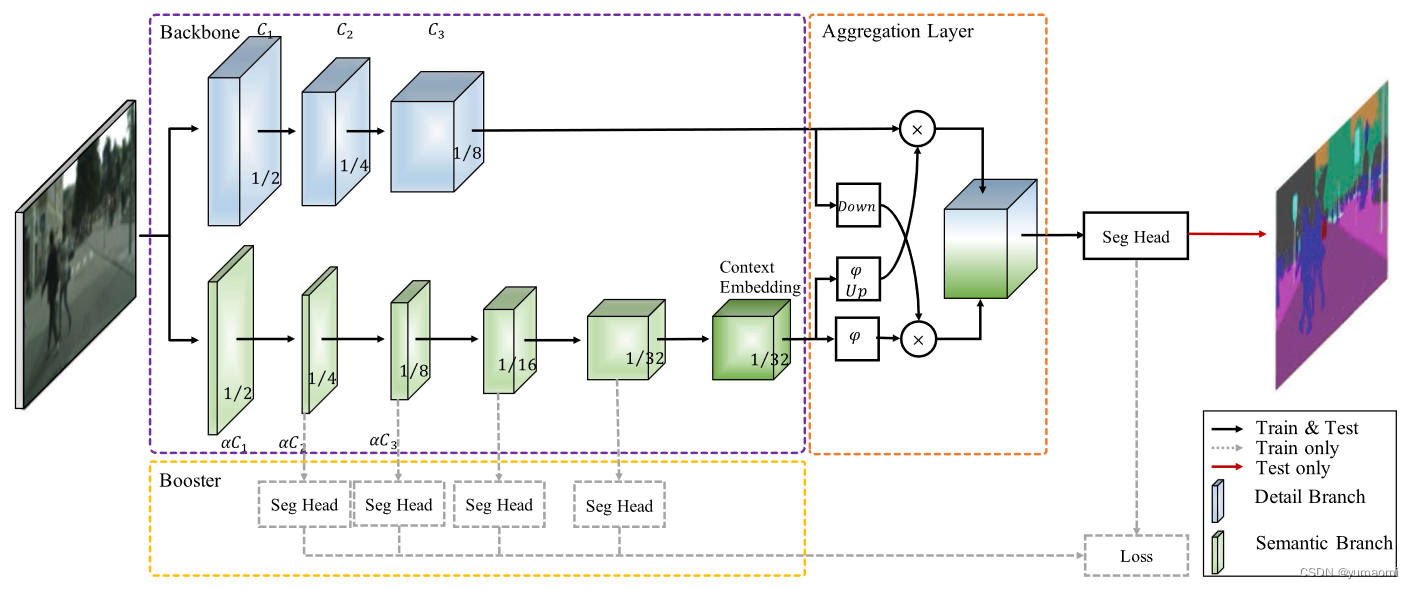
BiSeNetV2主要包含几个结构:
-
紫色框(backbone)内的双路分支,上为Detail Branch分支,该分支的网络层数较少,但是特征图的尺寸比较大,因此适用于提取空间细节信息。下为Semantic Branch分支该分支相对比较深,而且特征图的尺寸相对较小,具有较大的感受野,因此适用于提取高级语义信息。
-
橙色框(Aggregation Layer)内的Aggregation Layer聚合层,这个模块被用来融合Detail分支和Semantic分支的特征,以便充分利用两个分支的信息。
-
黄色框(Booster)内的Auxiliary Loss分支。
指标表现为:

Backbone-Detail Branch
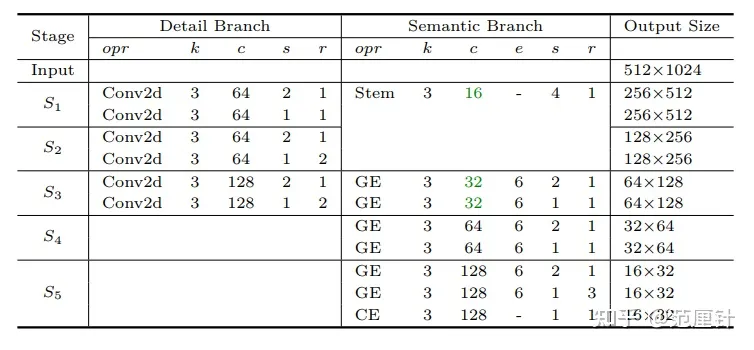
Detail分支旨在提取低级别的空间细节信息,具有以下特点:
- 网络通道数需要足够多;
- 特征图尺寸应该稍大;
- 网络深度相对较浅;
- 应避免在网络结构中使用残差连接,以避免增加显存占用和降低推理速度。
代码为:
class DetailBranch(BaseModule):
"""Detail Branch with wide channels and shallow layers to capture low-level
details and generate high-resolution feature representation.
Args:
detail_channels (Tuple[int]): Size of channel numbers of each stage
in Detail Branch, in paper it has 3 stages.
Default: (64, 64, 128).
in_channels (int): Number of channels of input image. Default: 3.
conv_cfg (dict | None): Config of conv layers.
Default: None.
norm_cfg (dict | None): Config of norm layers.
Default: dict(type='BN').
act_cfg (dict): Config of activation layers.
Default: dict(type='ReLU').
init_cfg (dict or list[dict], optional): Initialization config dict.
Default: None.
Returns:
x (torch.Tensor): Feature map of Detail Branch.
"""
def __init__(self,
detail_channels=(64, 64, 128),
in_channels=3,
conv_cfg=None,
norm_cfg=dict(type='BN'),
act_cfg=dict(type='ReLU'),
init_cfg=None):
super().__init__(init_cfg=init_cfg)
detail_branch = []
for i in range(len(detail_channels)):
if i == 0:
detail_branch.append(
nn.Sequential(
ConvModule(
in_channels=in_channels,
out_channels=detail_channels[i],
kernel_size=3,
stride=2,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg),
ConvModule(
in_channels=detail_channels[i],
out_channels=detail_channels[i],
kernel_size=3,
stride=1,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg)))
else:
detail_branch.append(
nn.Sequential(
ConvModule(
in_channels=detail_channels[i - 1],
out_channels=detail_channels[i],
kernel_size=3,
stride=2,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg),
ConvModule(
in_channels=detail_channels[i],
out_channels=detail_channels[i],
kernel_size=3,
stride=1,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg),
ConvModule(
in_channels=detail_channels[i],
out_channels=detail_channels[i],
kernel_size=3,
stride=1,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg)))
self.detail_branch = nn.ModuleList(detail_branch)
def forward(self, x):
for stage in self.detail_branch:
x = stage(x)
return x
代码中构建了3层卷积块,输出通道分别为64,64,128,尺寸分别为1/2,1/4,1/8整体特征图大小较大
Backbone-Semantic Branch
Semantic Branch与Detail Branch平行,主要用于捕获高级语义信息。在这一个分支中,通道数比较少,因为更多信息可以由Detail Branch提供。由于获取高级语义信息需要上下文的依赖和较大的感受野,所以,在这一个分支中,使用快速采样的策略来迅速扩大感受野;使用全局平均池化来嵌入上下文信息
主要包括三部分:
- Stem Block用于快速下采样;
- Gather-and-Expansion Layer(GE Layer)用于卷积获取细节信息。
- Context Embedding Block(CE Layer)用于嵌入上下文信息。
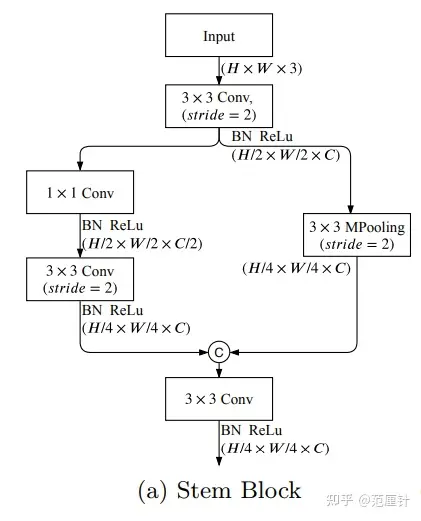
Stem Block在2个分支中使用了2种不同的下采样操作,2个分支的输出通过concat操作进行融合。
class StemBlock(BaseModule):
"""Stem Block at the beginning of Semantic Branch.
Args:
in_channels (int): Number of input channels.
Default: 3.
out_channels (int): Number of output channels.
Default: 16.
conv_cfg (dict | None): Config of conv layers.
Default: None.
norm_cfg (dict | None): Config of norm layers.
Default: dict(type='BN').
act_cfg (dict): Config of activation layers.
Default: dict(type='ReLU').
init_cfg (dict or list[dict], optional): Initialization config dict.
Default: None.
Returns:
x (torch.Tensor): First feature map in Semantic Branch.
"""
def __init__(self,
in_channels=3,
out_channels=16,
conv_cfg=None,
norm_cfg=dict(type='BN'),
act_cfg=dict(type='ReLU'),
init_cfg=None):
super().__init__(init_cfg=init_cfg)
self.conv_first = ConvModule(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=3,
stride=2,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
self.convs = nn.Sequential(
ConvModule(
in_channels=out_channels,
out_channels=out_channels // 2,
kernel_size=1,
stride=1,
padding=0,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg),
ConvModule(
in_channels=out_channels // 2,
out_channels=out_channels,
kernel_size=3,
stride=2,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg))
self.pool = nn.MaxPool2d(
kernel_size=3, stride=2, padding=1, ceil_mode=False)
self.fuse_last = ConvModule(
in_channels=out_channels * 2,
out_channels=out_channels,
kernel_size=3,
stride=1,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
def forward(self, x):
x = self.conv_first(x)
x_left = self.convs(x)
x_right = self.pool(x)
x = self.fuse_last(torch.cat([x_left, x_right], dim=1))
return x
Gather-and-Expansion Layer(GE)是一种层,其设计灵感来自于MobileNetv2中的反向瓶颈结构。反向瓶颈结构如图(a)所示,其中虚线表示当该模块的步长为2时,残差连接不存在;当该模块的步长为1时,残差连接存在。
当步长为1时,Gather-and-Expansion Layer的结构如图(b)所示:
- 首先使用卷积来增加通道数;
- 然后在高维度上使用depthwise卷积进行特征提取;
- 最后使用卷积来降低通道数。
当步长为2时,Gather-and-Expansion Layer的结构如图(c)所示:
- 使用2个depthwise卷积来进一步增加感受野;
- 在shortcut中使用1个depthwise卷积。
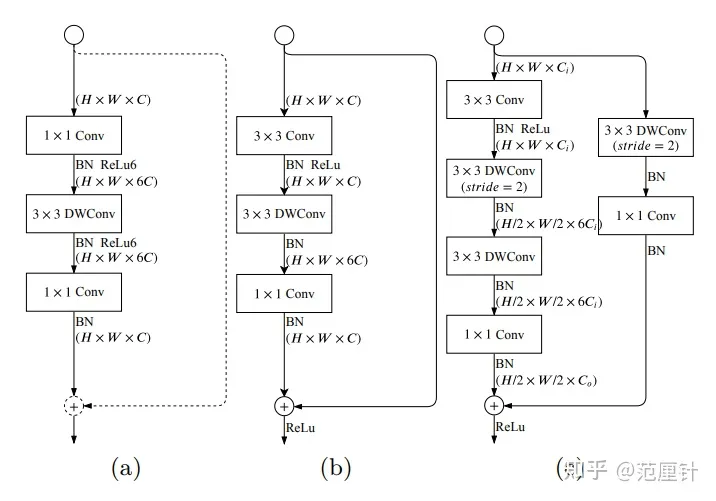
lass GELayer(BaseModule):
"""Gather-and-Expansion Layer.
Args:
in_channels (int): Number of input channels.
out_channels (int): Number of output channels.
exp_ratio (int): Expansion ratio for middle channels.
Default: 6.
stride (int): Stride of GELayer. Default: 1
conv_cfg (dict | None): Config of conv layers.
Default: None.
norm_cfg (dict | None): Config of norm layers.
Default: dict(type='BN').
act_cfg (dict): Config of activation layers.
Default: dict(type='ReLU').
init_cfg (dict or list[dict], optional): Initialization config dict.
Default: None.
Returns:
x (torch.Tensor): Intermediate feature map in
Semantic Branch.
"""
def __init__(self,
in_channels,
out_channels,
exp_ratio=6,
stride=1,
conv_cfg=None,
norm_cfg=dict(type='BN'),
act_cfg=dict(type='ReLU'),
init_cfg=None):
super().__init__(init_cfg=init_cfg)
mid_channel = in_channels * exp_ratio
self.conv1 = ConvModule(
in_channels=in_channels,
out_channels=in_channels,
kernel_size=3,
stride=1,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
if stride == 1:
self.dwconv = nn.Sequential(
# ReLU in ConvModule not shown in paper
ConvModule(
in_channels=in_channels,
out_channels=mid_channel,
kernel_size=3,
stride=stride,
padding=1,
groups=in_channels,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg))
self.shortcut = None
else:
self.dwconv = nn.Sequential(
ConvModule(
in_channels=in_channels,
out_channels=mid_channel,
kernel_size=3,
stride=stride,
padding=1,
groups=in_channels,
bias=False,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=None),
# ReLU in ConvModule not shown in paper
ConvModule(
in_channels=mid_channel,
out_channels=mid_channel,
kernel_size=3,
stride=1,
padding=1,
groups=mid_channel,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg),
)
self.shortcut = nn.Sequential(
DepthwiseSeparableConvModule(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=3,
stride=stride,
padding=1,
dw_norm_cfg=norm_cfg,
dw_act_cfg=None,
pw_norm_cfg=norm_cfg,
pw_act_cfg=None,
))
self.conv2 = nn.Sequential(
ConvModule(
in_channels=mid_channel,
out_channels=out_channels,
kernel_size=1,
stride=1,
padding=0,
bias=False,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=None,
))
self.act = build_activation_layer(act_cfg)
def forward(self, x):
identity = x
x = self.conv1(x)
x = self.dwconv(x)
x = self.conv2(x)
if self.shortcut is not None:
shortcut = self.shortcut(identity)
x = x + shortcut
else:
x = x + identity
x = self.act(x)
return x
Context Embedding Block(CE)
这个模块结合了全局平均池化和残差连接来提取全局上下文特征
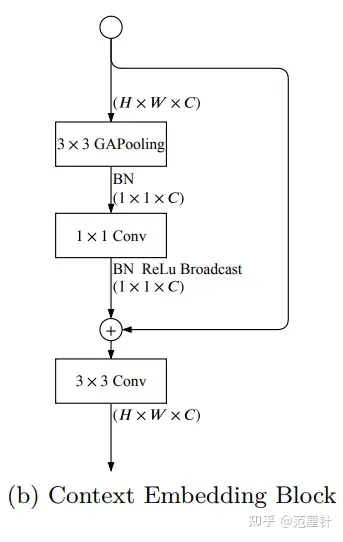
class CEBlock(BaseModule):
"""Context Embedding Block for large receptive filed in Semantic Branch.
Args:
in_channels (int): Number of input channels.
Default: 3.
out_channels (int): Number of output channels.
Default: 16.
conv_cfg (dict | None): Config of conv layers.
Default: None.
norm_cfg (dict | None): Config of norm layers.
Default: dict(type='BN').
act_cfg (dict): Config of activation layers.
Default: dict(type='ReLU').
init_cfg (dict or list[dict], optional): Initialization config dict.
Default: None.
Returns:
x (torch.Tensor): Last feature map in Semantic Branch.
"""
def __init__(self,
in_channels=3,
out_channels=16,
conv_cfg=None,
norm_cfg=dict(type='BN'),
act_cfg=dict(type='ReLU'),
init_cfg=None):
super().__init__(init_cfg=init_cfg)
self.in_channels = in_channels
self.out_channels = out_channels
self.gap = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
build_norm_layer(norm_cfg, self.in_channels)[1])
self.conv_gap = ConvModule(
in_channels=self.in_channels,
out_channels=self.out_channels,
kernel_size=1,
stride=1,
padding=0,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
# Note: in paper here is naive conv2d, no bn-relu
self.conv_last = ConvModule(
in_channels=self.out_channels,
out_channels=self.out_channels,
kernel_size=3,
stride=1,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
def forward(self, x):
identity = x
x = self.gap(x)
x = self.conv_gap(x)
x = identity + x
x = self.conv_last(x)
return x
SemanticBranch
class SemanticBranch(BaseModule):
"""Semantic Branch which is lightweight with narrow channels and deep
layers to obtain high-level semantic context.
Args:
semantic_channels(Tuple[int]): Size of channel numbers of
various stages in Semantic Branch.
Default: (16, 32, 64, 128).
in_channels (int): Number of channels of input image. Default: 3.
exp_ratio (int): Expansion ratio for middle channels.
Default: 6.
init_cfg (dict or list[dict], optional): Initialization config dict.
Default: None.
Returns:
semantic_outs (List[torch.Tensor]): List of several feature maps
for auxiliary heads (Booster) and Bilateral
Guided Aggregation Layer.
"""
def __init__(self,
semantic_channels=(16, 32, 64, 128),
in_channels=3,
exp_ratio=6,
init_cfg=None):
super().__init__(init_cfg=init_cfg)
self.in_channels = in_channels
self.semantic_channels = semantic_channels
self.semantic_stages = []
for i in range(len(semantic_channels)):
stage_name = f'stage{i + 1}'
self.semantic_stages.append(stage_name)
#最初一开始连接stem模块
if i == 0:
self.add_module(
stage_name,
StemBlock(self.in_channels, semantic_channels[i]))
#第三层加入过了GE模块
elif i == (len(semantic_channels) - 1):
self.add_module(
stage_name,
nn.Sequential(
GELayer(semantic_channels[i - 1], semantic_channels[i],
exp_ratio, 2),
GELayer(semantic_channels[i], semantic_channels[i],
exp_ratio, 1),
GELayer(semantic_channels[i], semantic_channels[i],
exp_ratio, 1),
GELayer(semantic_channels[i], semantic_channels[i],
exp_ratio, 1)))
#进入到第1/2层,重复加入GE和CE模块
else:
self.add_module(
stage_name,
nn.Sequential(
GELayer(semantic_channels[i - 1], semantic_channels[i],
exp_ratio, 2),
GELayer(semantic_channels[i], semantic_channels[i],
exp_ratio, 1)))
self.add_module(f'stage{len(semantic_channels)}_CEBlock',
CEBlock(semantic_channels[-1], semantic_channels[-1]))
self.semantic_stages.append(f'stage{len(semantic_channels)}_CEBlock')
def forward(self, x):
semantic_outs = []
for stage_name in self.semantic_stages:
semantic_stage = getattr(self, stage_name)
x = semantic_stage(x)
semantic_outs.append(x)
return semantic_outs
特征融合
特征融合模块是用于合并Detail分支和Semantic分支提取的特征的模块。由于Semantic分支包含大量下采样操作,其输出的特征图尺寸较小,因此需要对Semantic分支的特征图进行上采样,使其与Detail分支的特征图尺寸相同。简单地使用元素相加或连接的方式来融合这两个分支的特征是不可取的,因为这种方法忽略了这两个分支提取的特征之间的差异性。
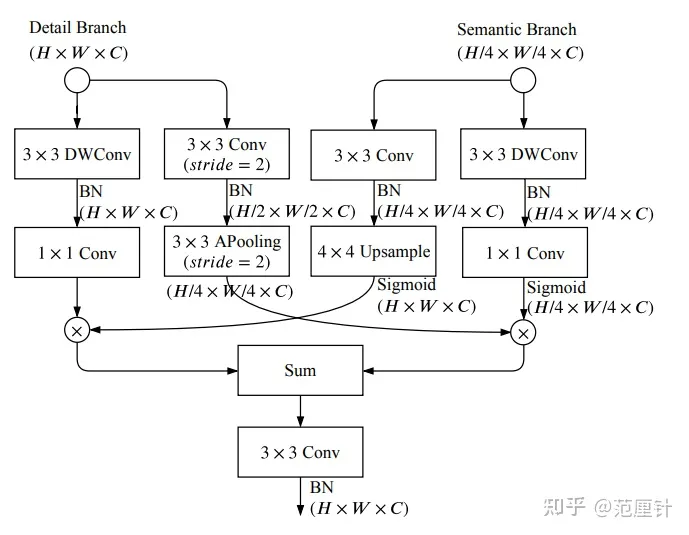
lass BGALayer(BaseModule):
"""Bilateral Guided Aggregation Layer to fuse the complementary information
from both Detail Branch and Semantic Branch.
Args:
out_channels (int): Number of output channels.
Default: 128.
align_corners (bool): align_corners argument of F.interpolate.
Default: False.
conv_cfg (dict | None): Config of conv layers.
Default: None.
norm_cfg (dict | None): Config of norm layers.
Default: dict(type='BN').
act_cfg (dict): Config of activation layers.
Default: dict(type='ReLU').
init_cfg (dict or list[dict], optional): Initialization config dict.
Default: None.
Returns:
output (torch.Tensor): Output feature map for Segment heads.
"""
def __init__(self,
out_channels=128,
align_corners=False,
conv_cfg=None,
norm_cfg=dict(type='BN'),
act_cfg=dict(type='ReLU'),
init_cfg=None):
super().__init__(init_cfg=init_cfg)
self.out_channels = out_channels
self.align_corners = align_corners
self.detail_dwconv = nn.Sequential(
DepthwiseSeparableConvModule(
in_channels=self.out_channels,
out_channels=self.out_channels,
kernel_size=3,
stride=1,
padding=1,
dw_norm_cfg=norm_cfg,
dw_act_cfg=None,
pw_norm_cfg=None,
pw_act_cfg=None,
))
#下采样分支1的创建
self.detail_down = nn.Sequential(
ConvModule(
in_channels=self.out_channels,
out_channels=self.out_channels,
kernel_size=3,
stride=2,
padding=1,
bias=False,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=None),
nn.AvgPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False))
#分支2
self.semantic_conv = nn.Sequential(
ConvModule(
in_channels=self.out_channels,
out_channels=self.out_channels,
kernel_size=3,
stride=1,
padding=1,
bias=False,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=None))
self.semantic_dwconv = nn.Sequential(
DepthwiseSeparableConvModule(
in_channels=self.out_channels,
out_channels=self.out_channels,
kernel_size=3,
stride=1,
padding=1,
dw_norm_cfg=norm_cfg,
dw_act_cfg=None,
pw_norm_cfg=None,
pw_act_cfg=None,
))
self.conv = ConvModule(
in_channels=self.out_channels,
out_channels=self.out_channels,
kernel_size=3,
stride=1,
padding=1,
inplace=True,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg,
)
def forward(self, x_d, x_s):
detail_dwconv = self.detail_dwconv(x_d)
detail_down = self.detail_down(x_d)
semantic_conv = self.semantic_conv(x_s)
semantic_dwconv = self.semantic_dwconv(x_s)
semantic_conv = resize(
input=semantic_conv,
size=detail_dwconv.shape[2:],
mode='bilinear',
align_corners=self.align_corners)
fuse_1 = detail_dwconv * torch.sigmoid(semantic_conv)
fuse_2 = detail_down * torch.sigmoid(semantic_dwconv)
fuse_2 = resize(
input=fuse_2,
size=fuse_1.shape[2:],
mode='bilinear',
align_corners=self.align_corners)
output = self.conv(fuse_1 + fuse_2)
return output
网络结构的代码:
class BiSeNetV2(BaseModule):
"""BiSeNetV2: Bilateral Network with Guided Aggregation for
Real-time Semantic Segmentation.
This backbone is the implementation of
`BiSeNetV2 <https://arxiv.org/abs/2004.02147>`_.
Args:
in_channels (int): Number of channel of input image. Default: 3.
detail_channels (Tuple[int], optional): Channels of each stage
in Detail Branch. Default: (64, 64, 128).
semantic_channels (Tuple[int], optional): Channels of each stage
in Semantic Branch. Default: (16, 32, 64, 128).
See Table 1 and Figure 3 of paper for more details.
semantic_expansion_ratio (int, optional): The expansion factor
expanding channel number of middle channels in Semantic Branch.
Default: 6.
bga_channels (int, optional): Number of middle channels in
Bilateral Guided Aggregation Layer. Default: 128.
out_indices (Tuple[int] | int, optional): Output from which stages.
Default: (0, 1, 2, 3, 4).
align_corners (bool, optional): The align_corners argument of
resize operation in Bilateral Guided Aggregation Layer.
Default: False.
conv_cfg (dict | None): Config of conv layers.
Default: None.
norm_cfg (dict | None): Config of norm layers.
Default: dict(type='BN').
act_cfg (dict): Config of activation layers.
Default: dict(type='ReLU').
init_cfg (dict or list[dict], optional): Initialization config dict.
Default: None.
"""
def __init__(self,
in_channels=3,
detail_channels=(64, 64, 128),
semantic_channels=(16, 32, 64, 128),
semantic_expansion_ratio=6,
bga_channels=128,
out_indices=(0, 1, 2, 3, 4),
align_corners=False,
conv_cfg=None,
norm_cfg=dict(type='BN'),
act_cfg=dict(type='ReLU'),
init_cfg=None):
if init_cfg is None:
init_cfg = [
dict(type='Kaiming', layer='Conv2d'),
dict(
type='Constant', val=1, layer=['_BatchNorm', 'GroupNorm'])
]
super().__init__(init_cfg=init_cfg)
self.in_channels = in_channels
self.out_indices = out_indices
self.detail_channels = detail_channels
self.semantic_channels = semantic_channels
self.semantic_expansion_ratio = semantic_expansion_ratio
self.bga_channels = bga_channels
self.align_corners = align_corners
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
self.act_cfg = act_cfg
self.detail = DetailBranch(self.detail_channels, self.in_channels)
self.semantic = SemanticBranch(self.semantic_channels,
self.in_channels,
self.semantic_expansion_ratio)
self.bga = BGALayer(self.bga_channels, self.align_corners)
def forward(self, x):
# stole refactoring code from Coin Cheung, thanks
x_detail = self.detail(x)
x_semantic_lst = self.semantic(x)
x_head = self.bga(x_detail, x_semantic_lst[-1])
outs = [x_head] + x_semantic_lst[:-1]
outs = [outs[i] for i in self.out_indices]
return tuple(outs)
网络配置文件:注意将主干网络的输入与head的in_index结合起来使用
# model settings
norm_cfg = dict(type='SyncBN', requires_grad=True)
data_preprocessor = dict(
type='SegDataPreProcessor',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
bgr_to_rgb=True,
pad_val=0,
seg_pad_val=255)
model = dict(
type='EncoderDecoder',
data_preprocessor=data_preprocessor,
pretrained=None,
backbone=dict(
type='BiSeNetV2',
detail_channels=(64, 64, 128),
semantic_channels=(16, 32, 64, 128),
semantic_expansion_ratio=6,
bga_channels=128,
out_indices=(0, 1, 2, 3, 4),
init_cfg=None,
align_corners=False),
decode_head=dict(
type='FCNHead',
in_channels=128,
in_index=0,
channels=1024,
num_convs=1,
concat_input=False,
dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
auxiliary_head=[
dict(
type='FCNHead',
in_channels=16,
channels=16,
num_convs=2,
num_classes=19,
in_index=1,
norm_cfg=norm_cfg,
concat_input=False,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
dict(
type='FCNHead',
in_channels=32,
channels=64,
num_convs=2,
num_classes=19,
in_index=2,
norm_cfg=norm_cfg,
concat_input=False,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
dict(
type='FCNHead',
in_channels=64,
channels=256,
num_convs=2,
num_classes=19,
in_index=3,
norm_cfg=norm_cfg,
concat_input=False,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
dict(
type='FCNHead',
in_channels=128,
channels=1024,
num_convs=2,
num_classes=19,
in_index=4,
norm_cfg=norm_cfg,
concat_input=False,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
],
# model training and testing settings
train_cfg=dict(),
test_cfg=dict(mode='whole'))
