ChatGLM
ChatGLM
本人是做视觉模型的,后续大模型这块在自然语言的火起来,后续视觉大模型要发展也是结合多模态,突然发现语言模型逃不开,还是需要学习点。在语言大模型这块呢,因为金钱和能力限制,坐不了真正意义的大模型,模型参数估计限制在10B内,为此需要找到合适的技术方向进行学习。(太大参数模型还真搞不了,落地估计更难了,这么大参数的模型只能在芯片集群分析的,没点金钱实力办不了)
在调研中国外的模型在国内的垂直应用,存在一定的水土不服,有的还涉及到商用授权的问题,在B站学习后,先研究下ChatGLM,看完之后国内在研究后有一定的教程,这个还是很不错,最近在各个公司的社区中相关技术文档越来越完善,其实学习时,掌握开源作者的readme就够了(当然还有些是环境配置的问题,这个都是小事)
一、中文语言大模型介绍
下表统计了,截止到至 2023 年 5 月 31 日在 github 上星标大于 3k 的中文开源项目。
| 模型名 | 介绍 |
|---|---|
| ChatGLM | ChatGLM-6B是一个基于通用语言模型(GLM)框架的开放式双语语言模型,使用了和ChatGPT 相似的技术,针对中文问答和对话进行了优化,模型拥有62亿参数。 |
| Moss | MOSS是一个支持中英双语和多种插件的开源对话语言模型, moss-moon系列模型具有160亿参数,MOSS基座语言模型在约七千亿中英文以及代码单词上预训练得到,后续经过对话指令微调、插件增强学习和人类偏好训练具备多轮对话能力及使用多种插件的能力。 |
| Chinese-LLaMA-Alpaca | 在LLaMA模型的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力。同时,中文Alpaca模型进一步使用了中文指令数据进行精调,显著提升了模型对指令的理解和执行能力。 |
| BELLE | BELLE团队在LLaMA、Bloomz等开源模型的基础上针对中文做了优化,在模型调优时使用由ChatGPT生产的数据,项目持续开放指令训练数据、相关模型、训练代码、应用场景等。 |
| 华驼(HuaTuo) | 在LLaMA-7B模型的基础上使用中文医学指令精调/指令微调 (Instruct-tuning)。项目通过医学知识图谱和GPT3.5API构建了中文医学指令数据集,提高了LLaMA在医疗领域的问答效果。 |
| LaWGPT | 基于中文法律知识的大语言模型,在通用中文基座模型(如 Chinese-LLaMA、ChatGLM 等)的基础上扩充法律领域专有词表、大规模中文法律语料预训练,增强了大模型在法律领域的基础语义理解能力。 |
ChatGLM 是由清华大学 KEG 实验室和智谱 AI 联合开发的基于 GLM 框架(Du, 2022)的大语言模型,2023 年 3 月,团队开源了 ChatGLM 62 亿参数的版本——ChatGLM-6B,6B 规模的大小使 ChatGLM 模型非常适合本地部署,目前 ChatGLM-6B 在全球下载量已超过 200 万。
二、ChatGLM介绍
其源码在github地址为:ChatGLM
开源项目如图所示:
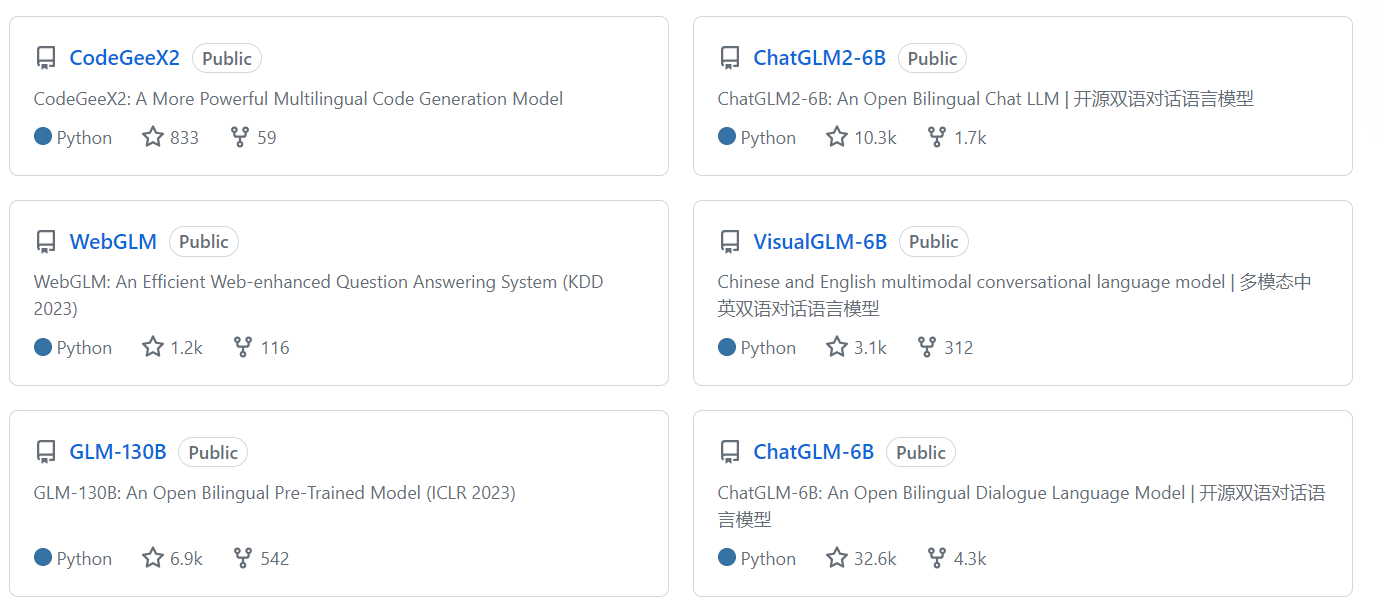
正如图中所示,根据自己的需要选在对应的模型,对与开发展,可能更愿意拥抱chatglm2-6B。
三、ChatGLM2-6B
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
ChatGLM2-6B,ChatGLM-6B 的升级版本,在保留了了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
- 更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
- 更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
- 更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
详情请看:ChatGLM2-6B详情介绍
| 量化等级 | 最低 GPU 显存(推理) | 最低 GPU 显存(高效参数微调) |
|---|---|---|
| FP16(无量化) | 13 GB | 14 GB |
| INT8 | 8 GB | 9 GB |
| INT4 | 6 GB | 7 GB |
其对于我们来讲能否看到落地的希望,重点则是前向推理显存占用较少。
四、学习指南
下面的开源项目是官方推荐:
对 ChatGLM 进行加速的开源项目:
- lyraChatGLM: 对 ChatGLM-6B 进行推理加速,最高可以实现 9000+ tokens/s 的推理速度
- ChatGLM-MNN: 一个基于 MNN 的 ChatGLM-6B C++ 推理实现,支持根据显存大小自动分配计算任务给 GPU 和 CPU
- JittorLLMs:最低3G显存或者没有显卡都可运行 ChatGLM-6B FP16, 支持Linux、windows、Mac部署
- InferLLM:轻量级 C++ 推理,可以实现本地 x86,Arm 处理器上实时聊天,手机上也同样可以实时运行,运行内存只需要 4G
基于或使用了 ChatGLM-6B 的开源项目:
- langchain-ChatGLM:基于 langchain 的 ChatGLM 应用,实现基于可扩展知识库的问答
- 闻达:大型语言模型调用平台,基于 ChatGLM-6B 实现了类 ChatPDF 功能
- glm-bot:将ChatGLM接入Koishi可在各大聊天平台上调用ChatGLM
- Chuanhu Chat: 为各个大语言模型和在线模型API提供美观易用、功能丰富、快速部署的用户界面,支持ChatGLM-6B。
支持 ChatGLM-6B 和相关应用在线训练的示例项目:
第三方评测:
更多开源项目参见 [PROJECT.md]
自己实践学习的如图所示:
在整个实践中环境部署不难,重点是下载各种模型。模型放在model_data中,这样所有项目可以共用模型,到时修改配置文件即可
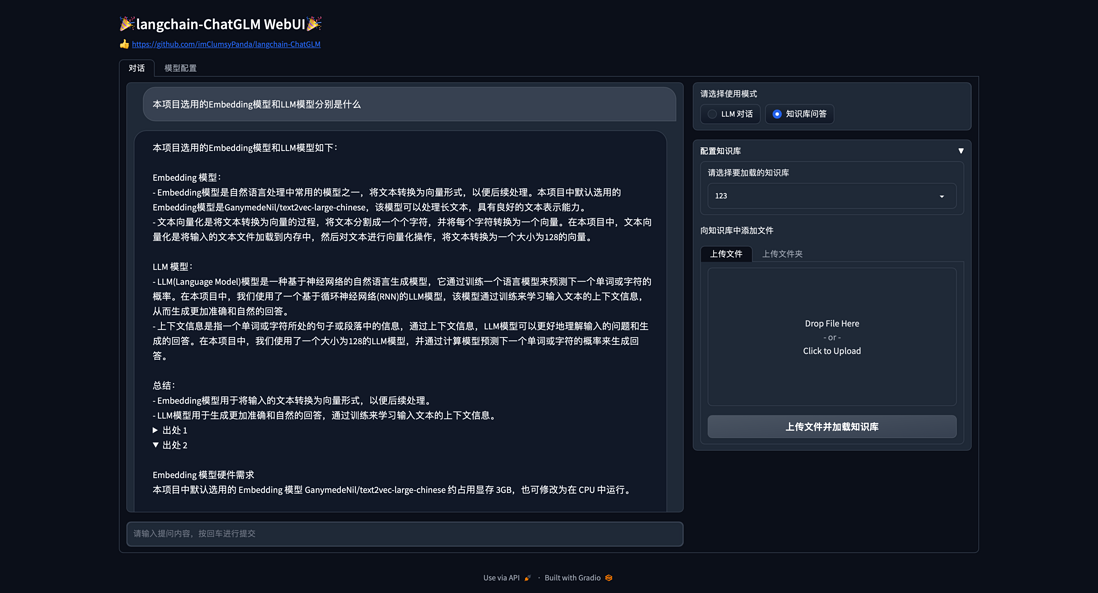
项目中readme比较详细,直接参考用即可。具体的示例图
ChatGLM-6B
的web_demo如下:

langchain-ChatGLM
angchain-ChatGLM是基于 ChatGLM-6B + langchain 实现的基于本地知识的 ChatGLM 应用。
项目亮点:可以本地上传知识库,并且计划支持联网搜索。
项目地址:https://github.com/imClumsyPanda/langchain-ChatGLM
visual-openllm
基于 ChatGLM + Visual ChatGPT + Stable Diffusion
项目亮点:整合了ChatGLM和Stable Diffusion,支持作图。
项目地址:https://github.com/visual-openllm/visual-openllm

 浙公网安备 33010602011771号
浙公网安备 33010602011771号