二:用电信号传输TCP/IP数据-3.1-收发数据
当控制流程从connect回到应用程序之后,就进入到数据收发阶段。
一、把数据交给协议栈之后
数据收发操作是从应用程序调用write将要发送的数据交给协议栈开始的。
协议栈执行发送操作有两个要点:
1、协议栈并不关心应用程序传来的内容。
应用程序调用write时会指定发送数据的长度,在协议栈看来,要发送的数据就是一定长度的二进制序列而已。
2、协议栈并不是已收到数据就马上发送出去。
协议栈会将数据存放在内部的缓冲区,并等待应用程序的下一段数据。
这样做的原因是,应用程序交给协议栈的数据长度由应用程序本身决定,不同的应用程序有不同的实现,有的会一次传递所有数据,有的会逐行或逐字节传递数据,协议栈如果一收到数据就马上发送就可能发送大量的小包,导致网络效率下降,因此需要积累到一定量再发送。
至于要积累到多少数据才发送,不同的操作系统有不同的实现,判断要素有两个:
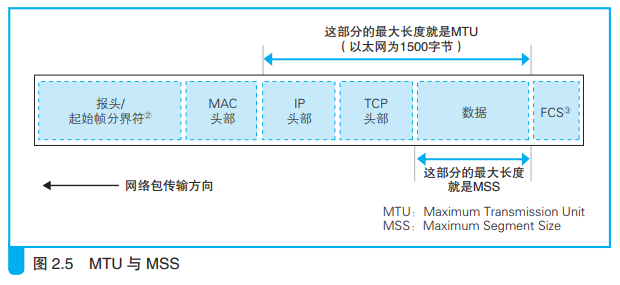
1、每个网络包能容纳的数据长度。
协议栈会根据MTU来判断一个网络包的最大长度,在以太网中,MTU一般是1500字节。
MTU是包含头部的总长度,因此需要从MTU减去头部的长度,然后得到的长度就是一个网络包中所能容纳的最大数据长度,叫做MSS。
当从应用程序收到的数据长度超过或者接近MSS时再发送出去,就可以避免发送大量小包的问题。
MTU:Maximum Transmission Unit,最大传输单元。
MSS:Maximum Segment Size,最大分段大小。
TCP和IP的头部加起来一般是40字节,MTU减去这个长度就是MSS。
例如,以太网中MTU一般是1500,MSS就是1460。
2、时间。
当应用程序发送数据的频率不高时,如果每次都等到长度接近MSS再发送,就会因为等待时间太长而造成发送延迟。
这种情况下,即使缓冲区中的数据长度没有达到MSS,也应该发送出去。
为此,协议栈内部有个计时器,当经过一定时间后就会执行发送。
这两个判断要素其实时互相矛盾的,如果长度优先,那么网络的效率会提高,但可能会因为等待填满缓冲区而产生延迟;如果时间优先,延迟会减少,但网络的效率会降低。
因此,协议栈执行发送操作时需要综合考虑这两个因素以达到平衡。
TCP协议规格中没有对应的指导,如何进行综合考虑是由协议栈的开发者决定的,所以不同的操作系统的发送操作上存在差异。
协议栈也给应用程序提供了控制发送时机的选项,比如应用程序可以指定“不等待填满缓冲区就直接发送”,这样协议栈的“综合判断”就会让路于应用程序的请求。
像浏览器这种会话型的应用程序,等待缓冲区填满导致延迟会产生很大影响,因此一般会试用直接发送的选项。
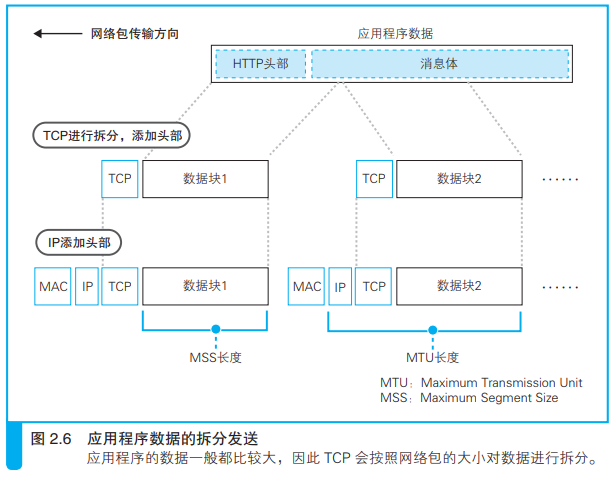
二、对较大的数据进行拆分
HTTP请求消息一般不会太长,一个网络包就能装下,但如果是提交表单数据,比如像现在这样在博客中提交一篇长文,长度就可能超过一个网络包能容纳的数据量。
这种情况下,缓冲区中的数据就超过了MSS,就不需要等待后面的数据。
缓冲区中的数据会被以MSS长度为单位进行拆分,拆分出来的每块数据会被放进单独的网络包中。
需要发送时,在每一块数据前面加上TCP头部,并根据套接字中记录的控制信息标记发送方和接收方的端口号,然后交给IP模块来执行发送数据的操作。
三、使用ACK号确认网络包已收到
3.1 单向的过程——原理讲解
TCP具备一个机制,可以确认对方是否收到网络包,以及当对方没有收到时进行重发。
看下具体原理。
1、TCP模块拆分数据时,会计算好每一块数据相当于从头开始的第多少个字节,发送时,将这个数字写在TCP头部中的“序号”字段。
2、接收方自行计算每一块数据的长度,方法是用整个网络包的长度减去头部的长度。
通过上面的两个数据:从头开始的第N个字节和整个数据块的长度,接收方可以检查收到的网络包有没有遗漏。比如,上次接收的数据块是从第1个字节开始,数据块的长度是1460,那么接下来收到的网络包的序号应该是1461,即从头开始的第1461个字节。如果是,说明没有遗漏;如果不是,说明中间有遗漏。
接收方会像这样对每一个网络包进行检查,如果没有遗漏,接收方会将到目前为止接收到的数据长度加起来,计算出一共收到了多少字节,然后将这个数字写入头部的ACK号中发送给对方。
返回ACK号时,除了要设置ACK的值,还要将控制位中的ACK比特设置为1,代表ACK号字段有效,对方也就可以知道这个网络包时用来告知ACK号的。
简单来说,确认的过程类似如下的对话:
发送方:现在发送的是从第XXX字节开始的部分,一共有XXX字节。
接收方:到第XXX字节之前的数据我已收到。
返回ACK号的操作被称为确认响应,通过这样的方式,发送方就能够确认对方收到了多少数据。
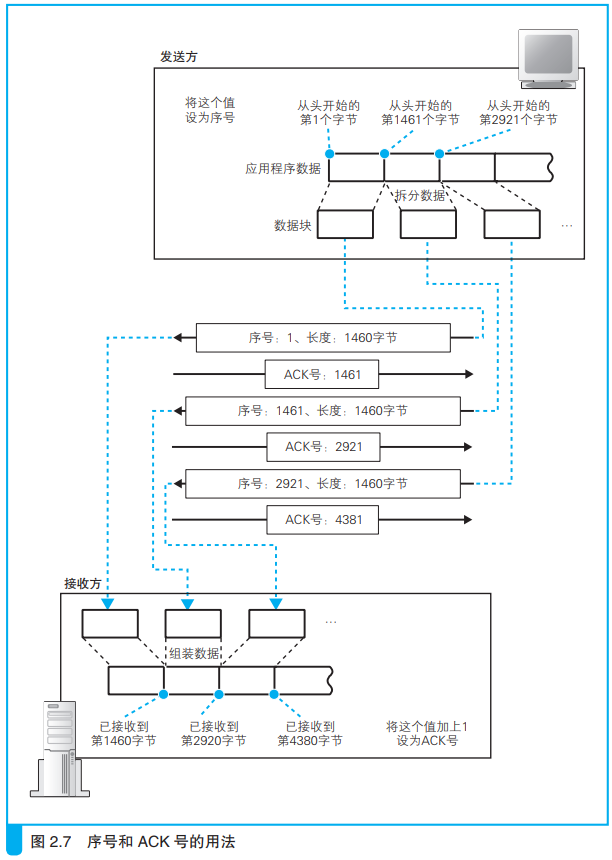
实际的通信和上图的示例有些出入,实际通信中,序号并不是从1开始,而是一个随机的初始值。这是因为如果从1开始,通信过程会非常容易预测,有人可以利用这一点来发动攻击,所以要使用一个无法预测的初始值。也因此需要在开始收发数据之前将初始值告知通信对象。
在上一节讲连接时,在第一步“创建TCP头部”中,需要将控制位中的SYN比特设置为1,并设置序号的值,这里的序号值就是上面讲的那个随机的初始值。
SYN就是Synchronize(同步)的缩写,意思时通过告知初始序号使通信双方步调一致,以便完成后续的数据收发检查。
3.2 双向的过程——实际收发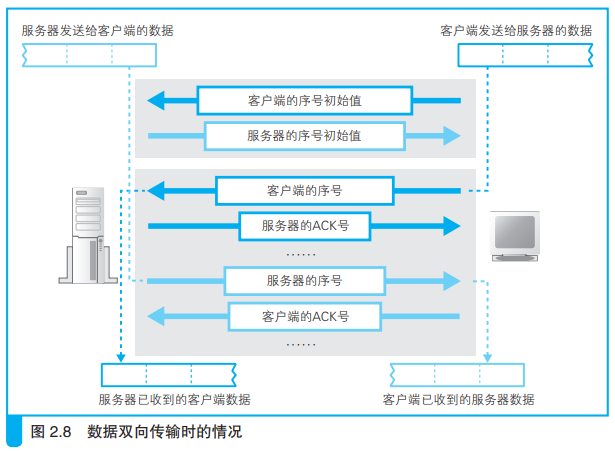
TCP数据收发时双向的,在客户端向服务器发送数据的同时,服务器也会向客户端发送数据。
原理和上面的单向过程类似,最重要的就是要在连接的时候告知对方自己计算的序号初始值。
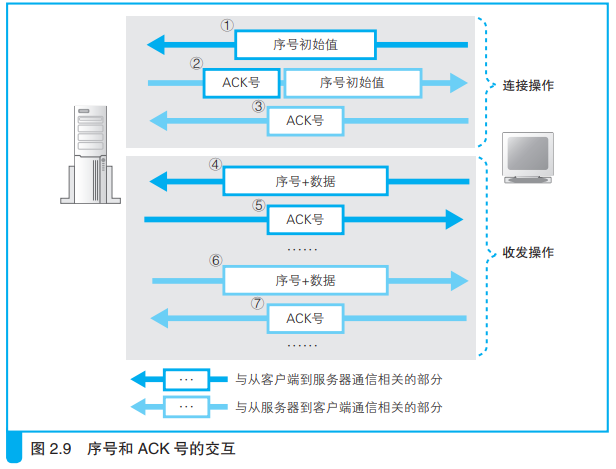
具体过程:
1、客户端在连接时计算出客户端→服务器方向的序号初始值,并发送给服务器(图2.9①)。
2、服务器通过收到的初始值计算出ACK号并返回给客户端(图2.9②)。
ACK号的计算:ACK号=序号+数据块的长度
比如,序号是153,数据块长度是100,那么ACK号就是153+100=253。
253也是下一个数据块的序号。
同时可以这样理解ACK号,ACK号告知对方自己已经收到了253之前的所有数据块,下面请从253开始继续发送。
同时,服务器也要计算出服务器→客户端方向的序号初始值,并发送给客户端(图2.9②)。
3、客户端根据服务器的序号初始值计算出ACK号并返回给服务器(图2.9③)。
4、到此,序号和ACK号都已经准备完成(完成连接),现在就可以开始数据收发。
客户端向服务器发送请求时,头部信息会带着序号跟数据一起发送(图2.9④)。
服务器收到后再返回ACK号(图2.9⑤)。
服务器向客户端发送数据的过程正好相反(图2.9⑥⑦)。
TCP采用这样的方式确认对方是否收到了数据,在得到对方确认之前,发送过的包都会保存在发送缓冲区中,如果对方没有返回某个包对应的ACK号,那么就从缓冲区中重新发送。
通过这个机制,我们可以确认对方有没有收到某个包,如果没有收到就重新发送。这样,无论网络中发生任何错误,我们都可以发现并补救。也就是说,有了这个机制保证,就不需要在其他地方对错误进行补救。
因此,网卡、集线器、路由器都没有错误补救机制,它们一旦检测到错误就直接丢弃相应的包。
应用程序也是这样,因为有TCP的机制保证,即便发生什么错误对方也能收到正确的数据,所以应用程序只管发送就行了。
不过如果发生网络中断、服务器宕机等问题,无论TCP如何重传都无法补救。这种情况下,TCP会在尝试几次重传无效之后结束通信,并向应用程序报错。
本文来自博客园,作者:GPL-技术沉思录,转载请注明原文链接:https://www.cnblogs.com/polin/p/17379753.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号