Go语言入门学习
一.Go语言介绍
Go 是一个开源的编程语言,它能让构造简单、可靠且高效的软件变得容易。Go是从2007年末由Robert Griesemer, Rob Pike, Ken Thompson主持开发,后来还加入了Ian Lance Taylor, Russ Cox等人,并最终于2009年11月开源,在2012年早些时候发布了Go 1稳定版本。现在Go的开发已经是完全开放的,并且拥有一个活跃的社区。
二.环境搭建
到go的官网可以下载,下载链接

点击Download即可下载,下载完之后,选择安装路径,默认会自动配置环境变量,如果没有配置,把path/go/bin添加到环境变量即可
测试是否安装成功,输入go version
在VsCode里编写go代码
在VsCode拓展里找到go的扩展,并安装

然后就可以编写go代码了
下面演示一个hello world代码hello.go
package main import ("fmt") func main() { fmt.Println("Hello, World!") }
注意,main函数的大括号一定要和main函数在一行,不然会报错
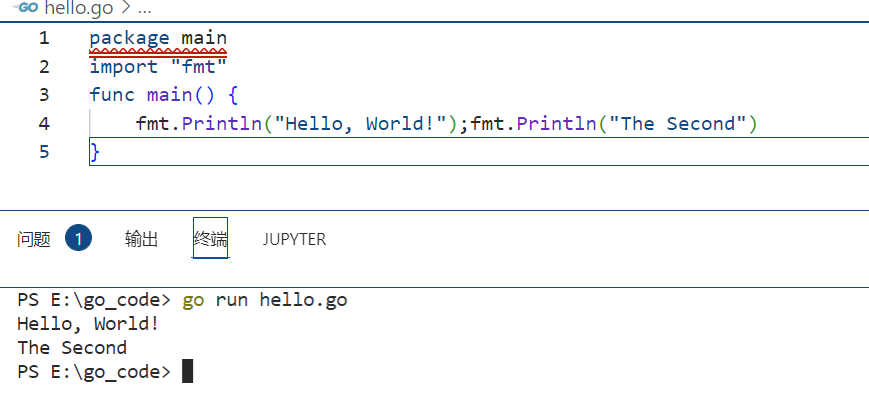
运行测试一下,在终端输入go run hello.go

二.Go语言的基本结构
Go 语言的基础组成有以下几个部分:
- 包声明
- 引入包
- 函数
- 变量
- 语句 & 表达式
- 注释
以我们写的Hello world为例

//包声明 package main //引入包 import "fmt"//主函数 func main() { /*这是一个简单的程序 */ //语句 fmt.Println("Hello, World!") fmt.Println("The Second") }
第一行的package main定义了包名,每个文件的除注释之外第一行代码都要加上包名,指明这个文件属于哪个包,例如package main,package main表示一个可独立执行的程序,每个 Go 应用程序都包含一个名为 main 的包
第二行的import "fmt"表示引入了fmt包,因为在程序中使用了fmt的Println函数
下面是程序的主函数,每一个可执行文件都应该有一个主函数,在没有init函数的情况下,main函数是最早被执行的
下面两行注释/**/可以表示多行注释,//可以表示单行注释
fmt.Println()表示调用了fmt包中的Println函数,注意这里的输出函数首字母是大写的
当一个标识符以大写开头,,如:Group1,那么使用这种形式的标识符的对象就可以被外部包的代码所使用(程序需要先导入这个包),这被称为导出(像面向对象语言中的 public);标识符如果以小写字母开头,则对包外是不可见的,但是他们在整个包的内部是可见并且可用的(像面向对象语言中的 protected )
执行go程序有两种办法,一种是使用go run命令直接运行.go文件
另一种是先使用go build生成可执行文件,然后在运行可执行文件

三.基本语法
标识符
标识符用来给变量、结构体、函数等进行命名,命名的规则和C语言类似,由字符数字和下划线组成,不能以数字开头、
例如:add result _begin a_123
行分割符
go语言每条语句后是没有分号的,一行就代表一条单独的语句
如果要把两条语句写在同一行,则必须要分号来进行分隔,例如
package main import "fmt" func main() { fmt.Println("Hello, World!");fmt.Println("The Second") }
字符串连接
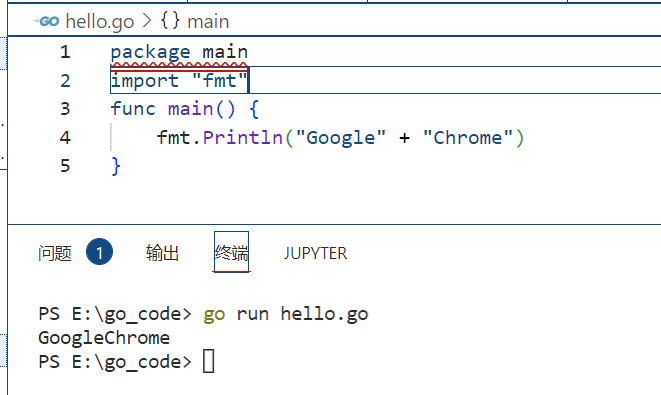
go语言中的字符串可以直接用+进行连接
比如
package main import "fmt" func main() { fmt.Println("Google" + "Chrome") }
格式化字符串
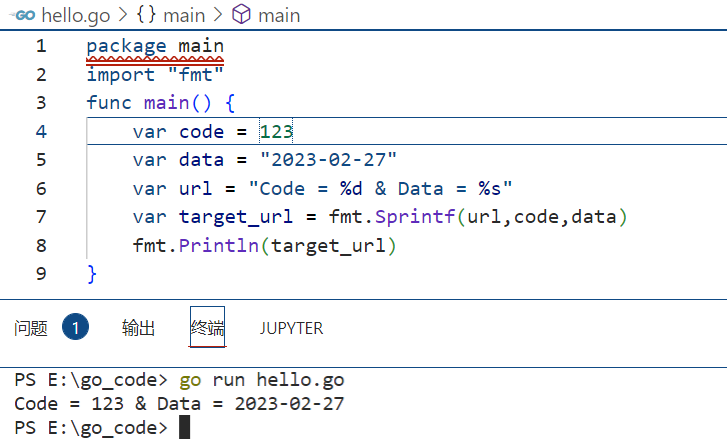
go语言使用fmt.Sprintf 或 fmt.Printf 格式化字符串并赋值给新串:
- Sprintf 根据格式化参数生成格式化的字符串并返回该字符串。
- Printf 根据格式化参数生成格式化的字符串并写入标准输出。
例如
package main import "fmt" func main() {var code = 123 var data = "2023-02-27" var url = "Code = %d & Data = %s" var target_url = fmt.Sprintf(url,code,data) fmt.Println(target_url) }
关于fmt.Sprintf的格式,可以到网站查询
关键字
以下是go语言中的关键字
| break | default | func | interface | select |
| case | defer | go | map | struct |
| chan | else | goto | package | switch |
| const | fallthrough | if | range | type |
| continue | for | import | return | var |
还有一些go语言中的预定义标识符,这些标识符不能再被当做变量名或者函数名使用
| append | bool | byte | cap | close | complex | complex64 | complex128 | uint16 |
| copy | false | float32 | float64 | imag | int | int8 | int16 | uint32 |
| int32 | int64 | iota | len | make | new | nil | panic | uint64 |
| println | real | recover | string | true | uint | uint8 | uintptr |
Go 语言数据类型
package main import "fmt" func main() { // 声明复数 var c1 complex64 = 3 + 4i var c2 complex64 = 2 + 3i // 打印复数 fmt.Println(c1) // 输出:(3+4i) fmt.Println(c2) // 输出:(2+3i) // 操作复数 fmt.Println(c1 + c2) // 输出:(5+7i) fmt.Println(c1 - c2) // 输出:(1+1i) fmt.Println(c1 * c2) // 输出:(-6+17i) fmt.Println(c1 / c2) // 输出:(1.56-0.08i) // 获取实部和虚部 fmt.Println(real(c1)) // 输出:3 fmt.Println(imag(c1)) // 输出:4 }
- (a) 指针类型(Pointer)
- (b) 数组类型
- (c) 结构化类型(struct)
- (d) Channel 类型
- (e) 函数类型
- (f) 切片类型
- (g) 接口类型(interface)
- (h) Map 类型
以上的类型在用到时还会具体介绍
Go语言变量
Go语言的变量名可以有数字,字母和下划线构成
声明变量一般使用var,在变量名之后指名变量的类型
var identifier type
声明变量时可以指定变量的值,如果赋值时没有指名变量的类型,则go语言会自动推导变量的类型,比如
var s1 string = "123" //自动推导s2为string类型 var s2 = "abc"
也可以一次声明多个变量并赋值
var a,b int = 1,2 var c,d = 1,"abc" fmt.Println(a) fmt.Println(b) fmt.Println(c) fmt.Println(d)
输出结果

如果一个变量没有被赋值,那么会默认赋为零值
var id int
var flag bool
var s string
-
数值类型(包括complex64/128)为 0
-
布尔类型为 false
-
字符串为 ""(空字符串)
-
以下几种类型为 nil:
var a *int var a []int var a map[string] int var a chan int var a func(string) int var a error // error 是接口
go语言中还可以使用:=来表示声明和赋值语句
s:= "abc" //相当于下面两句 var s string s = "abc"
注意,声明过的变量不可以再被声明
var s int = 1 s := -1 //会报错,因为变量被声明了两次
多变量声明
//类型相同多个变量, 非全局变量 var vname1, vname2, vname3 type vname1, vname2, vname3 = v1, v2, v3 var vname1, vname2, vname3 = v1, v2, v3 // 和 python 很像,不需要显示声明类型,自动推断 vname1, vname2, vname3 := v1, v2, v3 // 出现在 := 左侧的变量不应该是已经被声明过的,否则会导致编译错误 // 这种因式分解关键字的写法一般用于声明全局变量 var ( vname1 v_type1 vname2 v_type2 )
注意,go语言中声明过的变量是一定要被使用的,不然会报错
Go语言常量
常量在程序运行时不会被修改
常量的数据类型只可以是布尔型,数字型和字符串型
常量的定义方式
const identifier type = value
常量和变量的声明基本没有什么差别

当尝试修改常量时,会报错
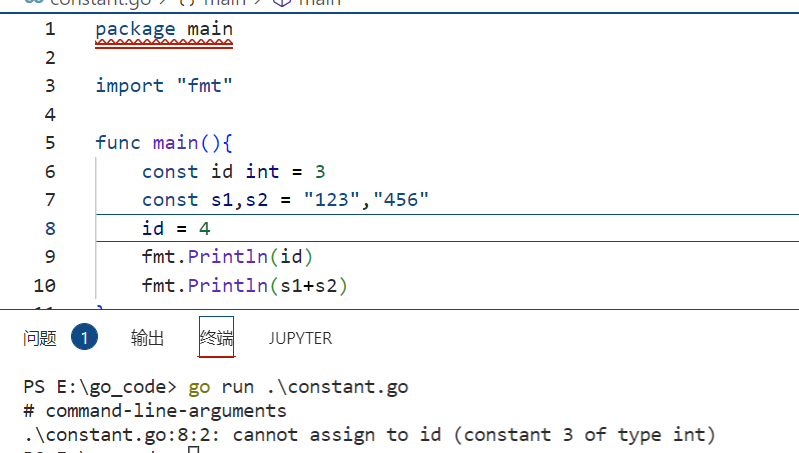
常量还可以用作枚举
const( a = 0 b = 1 c = 2 }
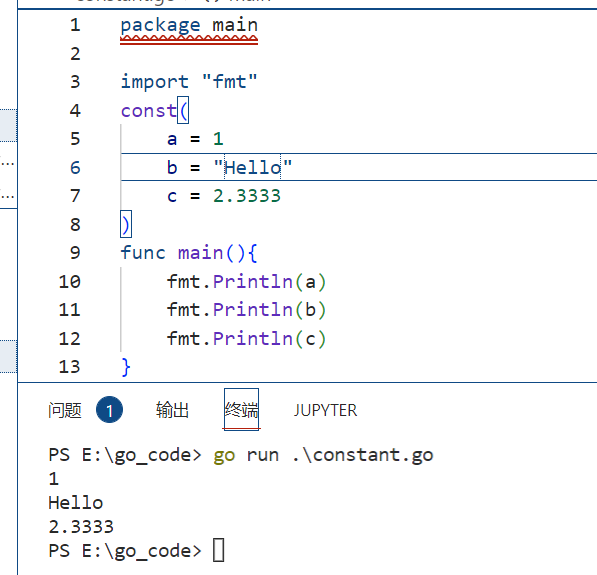
如果没有对枚举后面的变量赋值,会默认赋值为最后一个赋值变量的值
例如
iota
特殊常量,可以认为是一个可以被编译器修改的常量
iota 在 const关键字出现时将被重置为 0(const 内部的第一行之前),const 中每新增一行常量声明将使 iota 计数一次(iota 可理解为 const 语句块中的行索引)。
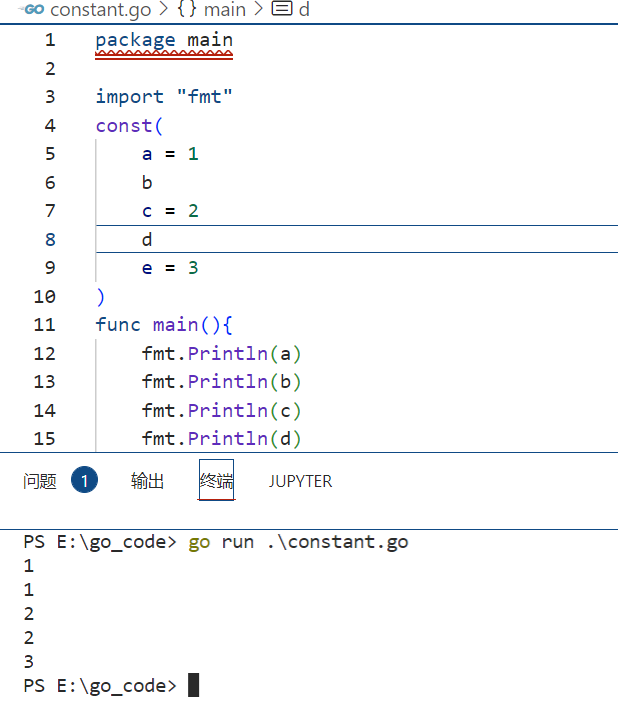
const ( a = iota b = iota c = iota )
第一个 iota 等于 0,每当 iota 在新的一行被使用时,它的值都会自动加 1;所以 a=0, b=1, c=2 可以简写为如下形式:
const ( a = iota // a= 0 b // b= 1 c // c= 2 )
iota 用法
运行结果
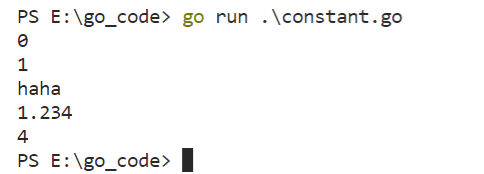
可以看出,只要没有再次出现const,iota的值就会不断的+1
Go语言运算符
go语言的内置运算法主要有以下几种
- 算术运算符
- 关系运算符
- 逻辑运算符
- 位运算符
- 赋值运算符
- 其他运算符
一些基本的运算和其他语言没有太大的差别,这里不做过多介绍
这里讲一下其他运算符,主要包括&和*
| & | 返回变量存储地址 | &a; 将给出变量的实际地址。 |
| * | 指针变量。 | *a; 是一个指针变量 |
下面是一个示例,演示了如何使用这两个运算符
package main import "fmt" func main(){ var a int = 4 var ptr *int = &a fmt.Println(a) fmt.Println(ptr) fmt.Println(*ptr) }
运行结果

Go语言指针
和C语言一样,&符号用来取变量的地址,而存储地址的变量就是指针,go语言中声明指针变量
var a int = 1 var p *int = &a
可以查看p里存储的值和*p的值
fmt.Println(p)
fmt.Println(*p)
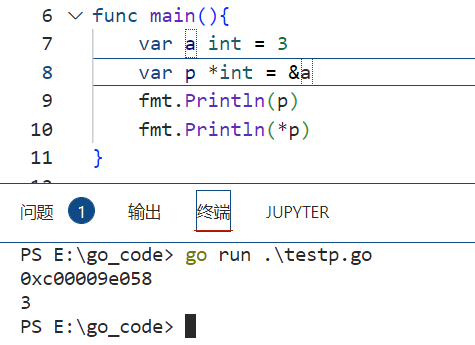
可以看到,p里存放的是变量a的地址
如果一个指针变量没有被赋值,那么默认为nil
var p *int fmt.Println(p == nil) //true
当然也可以取指针变量的地址
var a int = 4 var p *int = &a var dp **int = &p fmt.Println(*dp) fmt.Println(**dp)
这里注意一个点,就是关于局部变量的生命周期,正常来说,一个局部变量只在函数内生效,但是在go语言中,这个局部变量的值可以被延续到函数结束之后
比如
package main import "fmt" func main(){ a := f() fmt.Println(a) fmt.Println(*a) } func f()*int{ var c int = 4 return &c }
这里,每次调用f时,打印a和*a的值,都是存在的,但是a指向的是一个局部变量。并且每次f的返回值都不同,因为每次在函数f中都会声明一个新的局部变量
new函数
go语言中,除了声明变量之外,还可以使用new函数来创建一个变量,new(T)将创建一个T类型的匿名变量
p := new(int) // p, *int 类型, 指向匿名的 int 变量 fmt.Println(*p) // "0" *p = 2 // 设置 int 匿名变量的值为 2 fmt.Println(*p) // "2
这里p被推导为一个int*类的变量,他指向了一个匿名变量,要修改这个匿名变量,则只能通过指针p
使用new函数作为函数的返回值,下面两个函数的作用是相同的
func newInt()*int{ return new(int) } fun Int()*int{ var tmp int return &tmp }
通常来说,用new定义的变量,他们的内存地址都不相同,但是如果定义的是大小为0的结构体和数组,则有可能会相同,这取决与其他因素,如编译器等
这里注意,new只是一个预定义的函数,他并不属于预定义标识符和关键字,因此,可以声明和使用名字为new的变量
func delta(old,new int)int{ return old - int }
变量的生命周期
变量的生命周期指的是在程序运行期间变量有效存在的时间段。对于在包一级声明的变量来说,它们属于全局变量,它们的生命周期和整个程序的运行周期是一致的。而相比之下,局部变量的生命周期则是动态的:每次从创建一个新变量的声明语句开始,直到该变量不再被引用为止,然后变量的存储空间可能被回收。函数的参数变量和返回值变量都是局部变量。它们在函数每次被调用的时候创建。
for t := 0.0; t < cycles*2*math.Pi; t += res { x := math.Sin(t) y := math.Sin(t*freq + phase) img.SetColorIndex( size+int(x*size+0.5), size+int(y*size+0.5), blackIndex, ) }
在每次循环的开始会创建临时变量t,然后在每次循环迭代中创建临时变量x和y。
那么Go语言的自动垃圾收集器是如何知道一个变量是何时可以被回收的呢?这里我们可以避开完整的技术细节,基本的实现思路是,从每个包级的变量和每个当前运行函数的每一个局部变量开始,通过指针或引用的访问路径遍历,是否可以找到该变量。如果不存在这样的访问路径,那么说明该变量是不可达的,也就是说它是否存在并不会影响程序后续的计算结果。那么这个这个变量就可以被回收了
因为一个变量的有效周期只取决于是否可达,因此一个循环迭代内部的局部变量的生命周期可能超出其局部作用域。同时,局部变量可能在函数返回之后依然存在。就像之前在指针的地方讲的例子
编译器会自动选择在栈上还是在堆上分配局部变量的存储空间,但可能令人惊讶的是,这个选择并不是由用var还是new声明变量的方式决定的。
var global *int func f() { var x int x = 1 global = &x } func g() { y := new(int) *y = 1 }
f函数里的x变量必须在堆上分配,因为它在函数退出后依然可以通过包一级的global变量找到,虽然它是在函数内部定义的;用Go语言的术语说,这个x局部变量从函数f中逃逸了。相反,当g函数返回时,变量*y将是不可达的,也就是说可以马上被回收的。因此,*y并没有从函数g中逃逸,编译器可以选择在栈上分配*y的存储空间(译注:也可以选择在堆上分配,然后由Go语言的GC回收这个变量的内存空间),虽然这里用的是new方式。其实在任何时候,你并不需为了编写正确的代码而要考虑变量的逃逸行为,要记住的是,逃逸的变量需要额外分配内存,同时对性能的优化可能会产生细微的影响。
Go语言的自动垃圾收集器对编写正确的代码是一个巨大的帮助,但也并不是说你完全不用考虑内存了。你虽然不需要显式地分配和释放内存,但是要编写高效的程序你依然需要了解变量的生命周期。例如,如果将指向短生命周期对象的指针保存到具有长生命周期的对象中,特别是保存到全局变量时,会阻止对短生命周期对象的垃圾回收(从而可能影响程序的性能)。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律