机器学习整理(逻辑回归)
二分类问题
问题定义:给定一些特征,给其分类之一。
假设函数 定义:
决策边界:
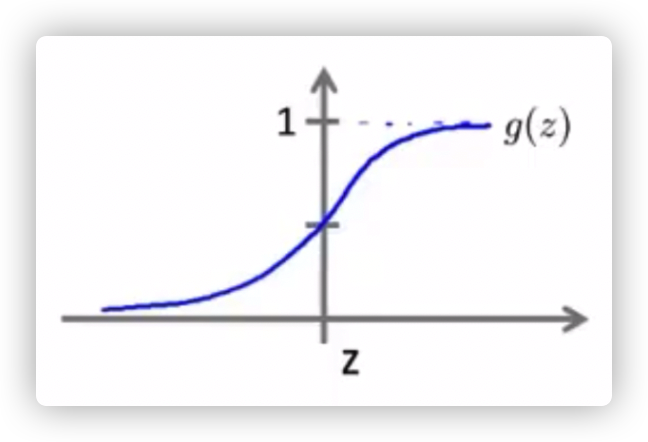
当 的时候,y 更有可能预测为 1。
当 的时候,y 更有可能预测为 0。
当 z 的值为 0,也就是 = 0 时就是区分两种分类的决策边界。
决策边界可能是直线,也有可能是曲线、圆。
代价函数
是一个“非凸函数”,如果将点距离公式带入到逻辑回归中,就会存在很多局部最优解。
新的代价函数定义:
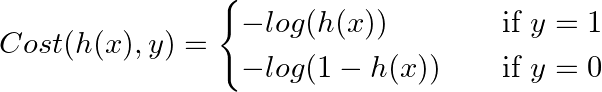
定义的代价函数图像和原因如下:

如果预测是/接近 0,但是实际的y是 1,这样代价函数的值就会非常大,以此来惩罚(修正)代价函数,而我们需要将代价函数最小化才能计算出 的参数 θ。
因为总是存在 或 ,所以可以将代价函数合并:
梯度下降的算法和之前一致,只不过偏导数相对复杂一些。
多分类问题
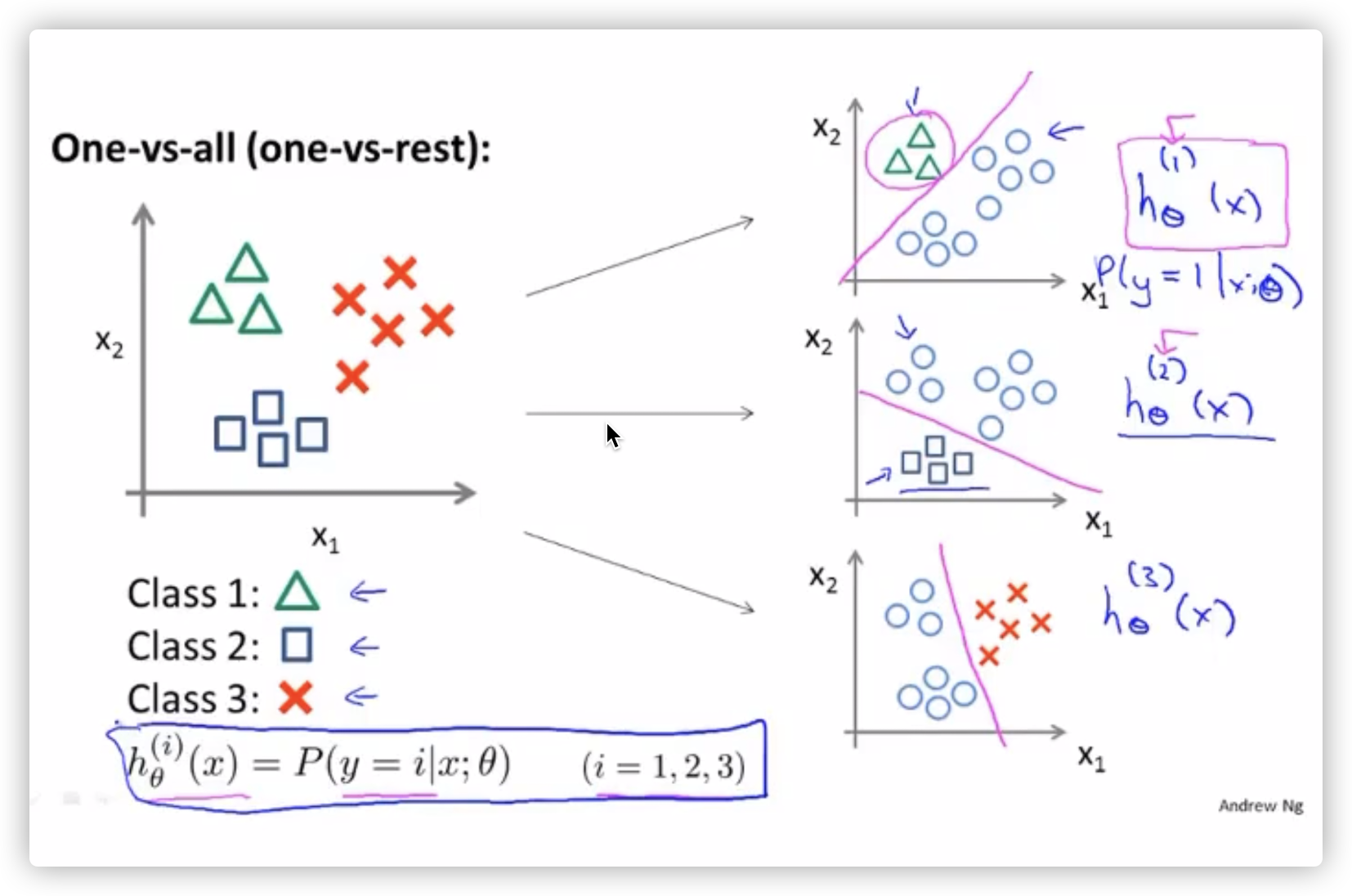
将多个类别的分类,转化成一对一的分类(分类器),每一个分类器相当于在计算属于自己那个分类的逻辑回归。
进行预测时:选择 的分类器,也就是概率最高的一个,如图(右侧)。
本文来自博客园,作者:pokpok,转载请注明原文链接:https://www.cnblogs.com/pokpok/p/16042257.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~