oracle常用语法
别名
别名中不能出现中文括号
()
不能使用全角符号
coalesce
coalesce(参数列表):返回参数列表中第一个非空参数,最后一个参数通常为常量
distinct
去重
nvl
作用:判断某个值是否为空值,若不为空值则输出,若为空值,返回指定值。专
详细解释如下:
1、nvl()函数的格属式如下:NVL(expr1,expr2);
2、含义是:如果oracle第一个参数为空那么显示第二个参数的值,如果第一个参数的值不为空,则显示第一个参数本来的值。
3、例:select name,NVL(name,-1) from user;运行后,结果返回两列数值,若name为空,则返回-1,若name不为空值,则返回其自身。
round
round函数用于数据的四舍五入
1、round(x,d) ,x指要处理的数,d是指保留几位小数
这里有个值得注意的地方是,d可以是负数,这时是指定小数点左边的d位整数位为0,同时小数位均为0;
2、round(x) ,其实就是round(x,0),也就是默认d为0;
union与union all
union:去重复,排序
union all:不重复也不排序.(推荐)
intersect 与 minus
intersect 就是交集
minus 就是差集
交集就是两个结果集中都有的元素
比如 select uid from tb1
intersect
select uid from tb2
那么既存在zhitb1 又存在tb2中 相同的UID 就会查dao出来
差集:select uid from tb1
minus
select uid from tb2
存在于tb1 但不存在与tb2中的uid 会被查出
表的复制
如果需要对表中的数据进行删除和修改,建议通过复制表中的数据来对数据进行操作
create table 表名 as 查询语句;
--将emp表中的数据复制到t_emp表中
create table t_emp
as
select * from emp;
--只需要表的结构
--将emp表的结构复制到t_emp表中
create table t_emp
as
select * from emp
where 1=0;/*提供一个否定条件*/
--只复制一部分数据
--将emp表中部门10的员工的数据复制到t_emp表中
create table t_emp
as
select * from emp
where deptno=10;
--将emp表中的员工姓名,工资,年薪保存到t_emp表中
create table t_emp
as
select ename,sal,sal*12 year_sal /*如果字段中出现函数或者计算需要提供别名*/
from emp;
--统计emp表中部门的人数,将部门编码和人数保存到t_emp表中
create table t_emp(did,ecount)
as
select deptno,count(ename)
from emp
group by deptno;
注意:表的复制只会复制表中的数据,不会复制表中的约束
伪列rowid,rownum
select rowid from dual;
rowid:是一个伪列,Oracle独有的.每一条记录的
rowid的记录是唯一的
sign比较大小
与0进行比较,判断是不是正数,大于0显示1 ,小于0显示-1 ,等于0显示0
select sign( 100 ),sign(- 100 ),sign( 0 ) from dual;
如何进行SQL语句的优化
在select语句中避免使用*
减少数据库的访问次数
删除重复记录
尽量多使用commit
使用where替换having
多使用内部函数提高sql语句效率
多使用表的别名
使用exists替换in,使用not exists替换notin
尽量使用索引类进行查询
sql语句尽量大写.oracle会自动转换成大写
避免在索引列上进行计算
避免在索引类上使用not,oracle遇到not就使用全表扫描
可以使用>=替换>
使用in替换or
尽量使用where替换groupby
避免使用消耗资源的操作.如union
子查询注意事项
1.子查询需要定义在括号当中
2.子查询通常定义在条件判断的右边
3.在子查询中不建议使用
order by
子查询中多行比较符
in :等于列表中的任何一个
any:和子查询结果中的任意一个值进行比较
all:和子查询结果中的所有值进行比较
oracle 与 mysql的区别
(1) 对事务的提交
MySQL默认是自动提交,而Oracle默认不自动提交,需要用户手动提交,需要在写commit;指令或者点击commit按钮
(2) 分页查询
MySQL是直接在SQL语句中写"select... from ...where...limit x, y",有limit就可以实现分页;而Oracle则是需要用到伪列ROWNUM和嵌套查询
(3) 事务隔离级别
MySQL是read commited的隔离级别,而Oracle是repeatable read的隔离级别,同时二者都支持serializable串行化事务隔离级别,可以实现最高级别的
读一致性。每个session提交后其他session才能看到提交的更改。Oracle通过在undo表空间中构造多版本数据块来实现读一致性,每个session
查询时,如果对应的数据块发生变化,Oracle会在undo表空间中为这个session构造它查询时的旧的数据块
MySQL没有类似Oracle的构造多版本数据块的机制,只支持read commited的隔离级别。一个session读取数据时,其他session不能更改数据,但
可以在表最后插入数据。session更新数据时,要加上排它锁,其他session无法访问数据
(4) 对事务的支持
MySQL在innodb存储引擎的行级锁的情况下才可支持事务,而Oracle则完全支持事务
(5) 保存数据的持久性
MySQL是在数据库更新或者重启,则会丢失数据,Oracle把提交的sql操作线写入了在线联机日志文件中,保持到了磁盘上,可以随时恢复
(6) 并发性
MySQL以表级锁为主,对资源锁定的粒度很大,如果一个session对一个表加锁时间过长,会让其他session无法更新此表中的数据。
虽然InnoDB引擎的表可以用行级锁,但这个行级锁的机制依赖于表的索引,如果表没有索引,或者sql语句没有使用索引,那么仍然使用表级锁。
Oracle使用行级锁,对资源锁定的粒度要小很多,只是锁定sql需要的资源,并且加锁是在数据库中的数据行上,不依赖与索引。所以Oracle对并
发性的支持要好很多。
(7) 逻辑备份
MySQL逻辑备份时要锁定数据,才能保证备份的数据是一致的,影响业务正常的dml使用,Oracle逻辑备份时不锁定数据,且备份的数据是一致
(8) 复制
MySQL:复制服务器配置简单,但主库出问题时,丛库有可能丢失一定的数据。且需要手工切换丛库到主库。
Oracle:既有推或拉式的传统数据复制,也有dataguard的双机或多机容灾机制,主库出现问题是,可以自动切换备库到主库,但配置管理较复杂。
(9) 性能诊断
MySQL的诊断调优方法较少,主要有慢查询日志。
Oracle有各种成熟的性能诊断调优工具,能实现很多自动分析、诊断功能。比如awr、addm、sqltrace、tkproof等
(10)权限与安全
MySQL的用户与主机有关,感觉没有什么意义,另外更容易被仿冒主机及ip有可乘之机。
Oracle的权限与安全概念比较传统,中规中矩。
(11)分区表和分区索引
MySQL的分区表还不太成熟稳定。
Oracle的分区表和分区索引功能很成熟,可以提高用户访问db的体验。
(12)管理工具
MySQL管理工具较少,在linux下的管理工具的安装有时要安装额外的包(phpmyadmin, etc),有一定复杂性。
Oracle有多种成熟的命令行、图形界面、web管理工具,还有很多第三方的管理工具,管理极其方便高效。
(13)最重要的区别
MySQL是轻量型数据库,并且免费,没有服务恢复数据。
Oracle是重量型数据库,收费,Oracle公司对Oracle数据库有任何服务。
分组排序函数的用法
- row_number() over()
先分组后排序
row_number() over(partition by col1 order by col2)表示根据col1分组,在分组内部根据col2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)。
与rownum的区别在于:使用rownum进行排序的时候是先对结果集加入伪劣rownum然后再进行排序,而此函数在包含排序从句后是先排序再计算行号码。row_number()和rownum差不多,功能更强一点(可以在各个分组内从1开始排序)。
- rank() over()
rank()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内)
- dense_rank() over()
dense_rank()也是连续排序,有两个第二名时仍然跟着第三名。相比之下row_number是没有重复值的。
我用到的是第一个row_number() over()函数,要使用这个函数分组排序后获取最大值的oracle语句:
select a,b from(select a,b,row_number()over(partition by a order by b desc)rownumber from tablename ) where rownumber =1
- 获取一组中最大值
SELECT * FROM (
SELECT last_comment,
row_number() over(partition BY
employeeid,roadline,stationname
ORDER BY logindate DESC) rn
FROM reocrd) t
WHERE t.rn <=1
这段的意思是,将reocrd表根据员工工号( employeeid),线路(,roadline),站点名称(stationname)分组后,取登录日期(logindate) 最大的那一行的last_comment的值.
CONCAT(str1,str2,…)
返回结果为连接参数产生的字符串。如有任何一个参数为NULL ,则返回值为 NULL。
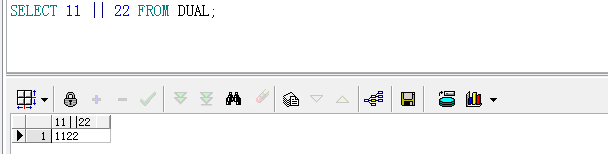
||连接符
在oracle数据库中"||"起到连接的作用
SELECT 11 || 22 FROM DUAL;
WM_CONCAT regexp_like replace 查询数据
创建表
--选课表
create table testcourse(
id varchar2(20) primary key,
name varchar2(30),
course varchar2(30)
)
--课程表
CREATE TABLE testDetailedcourse (
id varchar2(20) primary key,
name varchar2(30)
);
插入数据
select * from testcourse
| ID | NAME | COURSE |
|---|---|---|
| 1 | 张三 | 1,2,3 |
select * from testdetailedcourse
| ID | NAME |
|---|---|
| 1 | 语文 |
| 2 | 英语 |
| 3 | 数学 |
| 4 | 物理 |
查询数据:“张三选课详情”
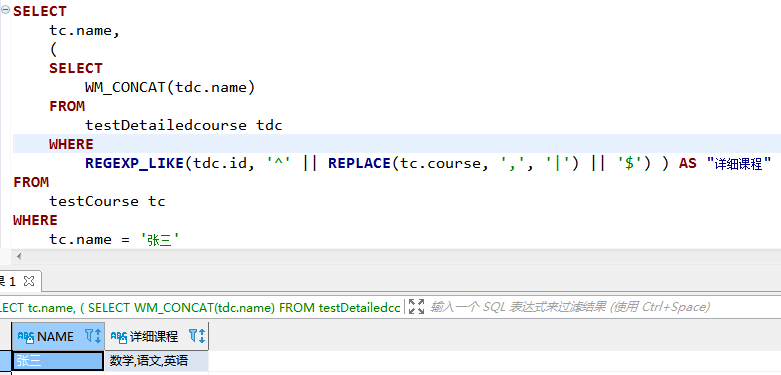
WM_CONCAT: 用于数据合并,示例中用于连接课程名称name
regexp_like: 用于正则 regexp_like(原字段,正则)
replace: replace(原字段,“原字段旧内容“,“原字段新内容“)
- 首先将course中的
,替换成|,配合管道||使用拼接成正则表达式,如上述表达式 : ^1|2|3|$ 判断id中包含1,2,3的数据 - 使用regexp_like匹配数据
- WM_CONCAT连接
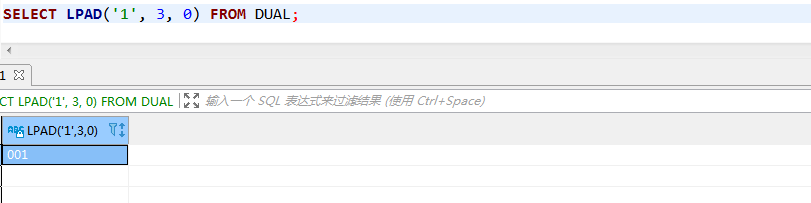
lpad
lpad( string, padded_length, [ pad_string ] )
lpad函数格式-从左至右填充
string:为需要被填充的字符串,
padded_length: 填充后字段长度
pad_string: 填充的字符
拼音排序
SCHINESE_RADICAL_M 按照部首(第一顺序)、笔划(第二顺序)排序
SCHINESE_STROKE_M 按照笔划(第一顺序)、部首(第二顺序)排序
SCHINESE_PINYIN_M 按照拼音排序
select * from student order by nlssort(name,'NLS_SORT=SCHINESE_STROKE_M');
表创建和最后修改时间
SELECT * FROM USER_TABLES 查看当前用户下的表
SELECT * FROM DBA_TABLES 查看数据库中所有的表
SELECT CREATED,LAST_DDL_TIME from user_objects where object_name=upper('表名')
SELECT CREATED, LAST_DDL_TIME
FROM USER_OBJECTS
WHERE OBJECT_NAME = 'PDCA_NEW_REPAIR';
其中CREATED 为创建时间 ,LAST_DDL_TIME为最后修改时间
vmkash
截取字符串SUBSTR
语法:SUBSTR(string,start, [length])
string:表示源字符串,即要截取的字符串。
start:开始位置,从1开始查找。如果start是负数,则从string字符串末尾开始算起。
length:可选项,表示截取字符串长度。
根据父节点查询子节点
SELECT ... FROM + 表名 START WITH + 条件1 CONNECT BY PRIOR + 条件2 WHERE + 条件3
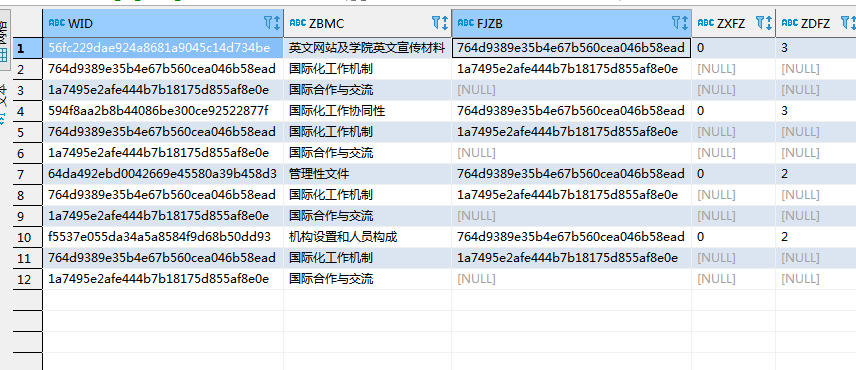
树形结构表查询
SYS_CONNECT_BY_PATH
oracle按照指定字段排序
比如按照编号排序,编号A_02排在A_01前,然后根据时间排序
SELECT * FROM STUDENT ORDER BY DECODE(BH,'A_02','1','A_01','2'), DATE DESC

