
【深度学习】文本匹配
参考
https://tech.meituan.com/2018/06/21/deep-learning-doc.html
背景
我最近在做query suggestion,根据前缀去推荐问题。
文本匹配在很多信息检索相关场景都用到,比如
1、搜索:Query-Doc
2、广告:Query-Ad
3、搜索Suggestion:Query前缀-Query
我现在只会用前缀树和布尔模型(匹配到了几个字是一样的,然后用log频率做一个排序)。但是后面肯定要去做优化的,你只停留在1970年不行啊。
其中一个难题就是设计模型如何充分考虑语义。因为中文的多义词、同义词非常普遍,它们在不同的语境中表达的含义是不一样的。比如苹果多少钱一台?苹果多少钱一斤?
语义表示匹配模型演进历程:

1. 向量空间
对文本“丽江的酒店价格”分词去除停用词后,得到丽江、酒店、价格,词出现次数是1,查表IDF得到这句文本的表示:[0, 1.5, 2.1, 0, 0, …, 0, 4.1]。其中权重使用的是TF×IDF,TF是Term在文本里的频次,IDF是逆文档频次(查表)。
文档有了向量表示,那么如何计算相似度?
度量的公式有Jaccard、Cosine、Euclidean distance、BM25等,其中BM25是衡量文档匹配相似度非常经典的方法,公式如下
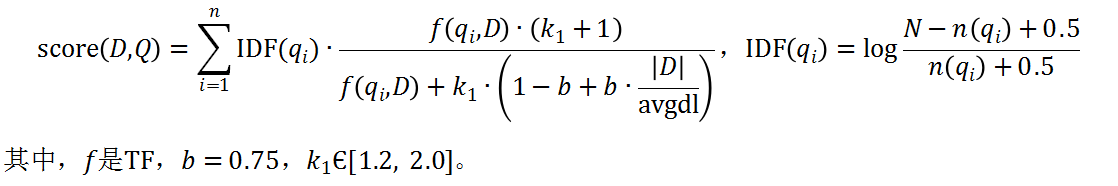
2. 矩阵分解
向量空间模型的高维度对语义信息刻画不好,文档集合会表示成高维稀疏大矩阵。1990年左右,有人研究通过矩阵分解的方法,把高维稀疏矩阵分解成两小矩阵,而这两个低维矩阵包含了语义信息,这个过程即潜在语义分析。
假设有N篇文档,共有V个词,用TF-IDF的向量空间表示一个N×V的稀疏矩阵X,
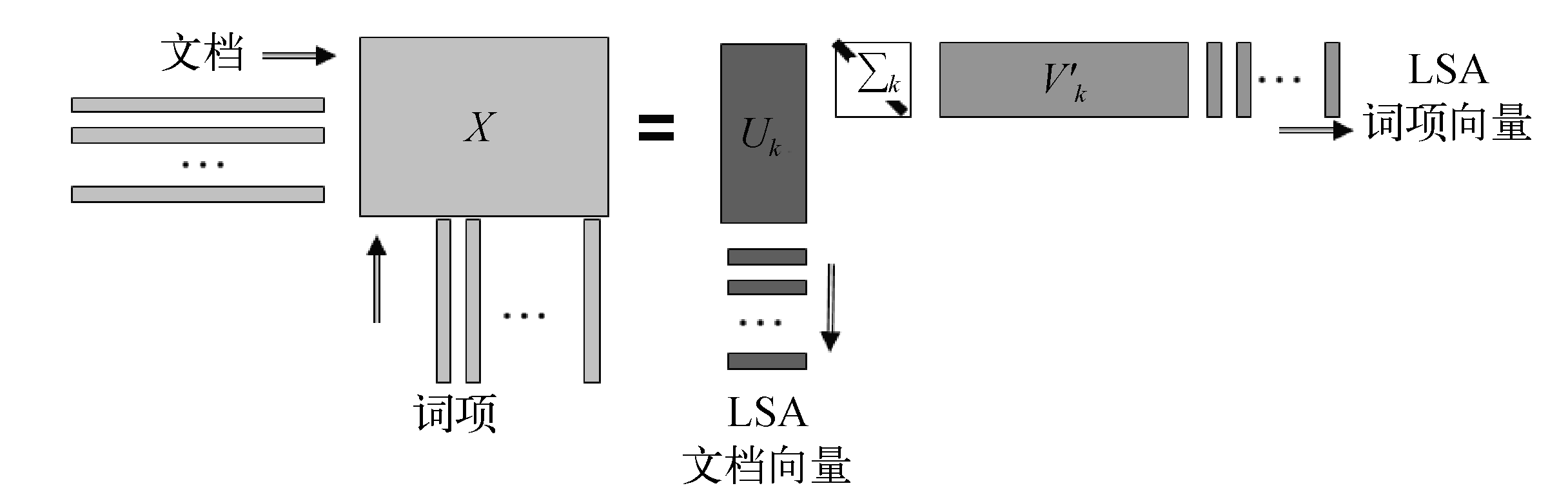
3. 主题模型
2000~2015年,以概率图模型为基础的主题模型掀起了一股热潮,那么究竟这种模型有什么吸引大家的优势呢?
pLSA(Probabilistic Latent Semantic Analysis)
假设每篇文章都由若干主题构成,每个主题的概率是p(z|d),在给定主题的条件下,每个词都以一定的概率p(w|z)产生。这样,文档和词的共现可以用一种产生式的方式来描述:
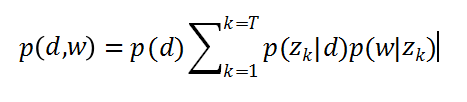
可以通过EM算法把p(z|d)和p(w|z)作为参数来学习,具体算法参考Thomas Hofmann的pLSA论文。需要学习的p(z|d)参数数目是主题数和文档数乘的关系,p(w|z)是词表数乘主题数的关系,参数空间很大,容易过拟合。因而我们引入多项式分布的共轭分布来做贝叶斯建模,即LDA使用的方法。
4. 深度学习
在2003年,Yoshua Bengio使用神经网络来训练语言模型比N-Gram的效果好很多,网络结构如图9所示。输入是N-Gram的词,预测下一个词。前n个词通过词向量矩阵Matrix C(维度:n*emb_size)查出该词的稠密向量C(w(t-1)),C(w(t-2));再分别连接到隐含层(Hidden Layer)做非线性变换;再和输出层连接做Softmax预测下一个词的概率;训练时根据最外层误差反向传播以调节网络权重。可以看出,该模型的训练复杂度为O(n×emb_size + n×emb_size×hidden_size + hidden_size×output_size),其中n为5~10,emb_size为64~1024,hidden_size为64~1023,output_size是词表大小,比如为10^7。因为Softmax在概率归一化时,需要所有词的值,所以复杂度主要体现在最后一层。从此以后,提出了很多优化算法,比如Hierarchical Softmax、噪声对比估计(Noise Contrastive Estimation)等。

