
【推荐系统】FM都不会怎么做推荐系统
FFM的全称是Field-aware FM,直观翻译过来,就是能够意识到特征域(Field)的存在的FM模型。那么FFM模型是有第六感吗?它怎么能够感知到特征域的存在呢?
先来看一个例子。
组合特征的重要性:如果在体育网站ESPN上发布Nike的广告,那么100次展现,80次会被点击,而20次不会被点击。意味着组合特征(Publisher=”ESPN” and Advertiser=”Nike”)是个很强的预测用户是否点击的二阶组合特征。
我们用这个例子来说明FFM的基本思想,FM模型可以看做是FFM模型的一个特例,所以在说明FFM模型思想之前,我们先用上述例子说明FM的思想。
FM模型怎么做二阶特征组合的?
是根据对应两个特征的Embedding向量内积。
当训练好FM模型后,每个特征都可以学会一个特征embedding向量。
分解机(Factorization Machines,FM)
2012年提出FM模型。
传统机器学习问题,一般仅考虑如何对特征赋予权重,而没有考虑特征间存在相互作用,FM模型的提出较好地解决了该问题。
优势:对于稀疏数据有更强的学习能力
经过One-Hot编码之后,大部分样本数据特征是比较稀疏的。比如职业特征有7类,就要7个维度,但仅有1维特征具有非零值。更重要的是,通过One-Hot编码方式输入到传统线性模型中进行训练,各特征分量xi和xj是相互独立的:
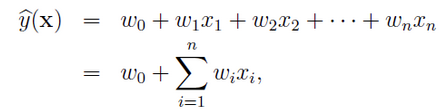
所以,特征之间的组合十分有意义:
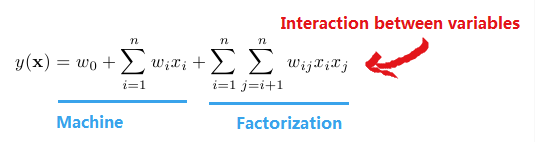
前半部分就是传统的线性模型,后半部分引入两个特征之间的关联特征。但是二次项参数训练很困难。
每个参数wij的训练需要大量 xi和 xj 都非零的样本,训练样本的不足,很容易导致参数 xi和xj训练 不准确,最终将严重影响模型的性能。
那么,如何解决二次项参数的训练问题呢?矩阵分解提供了一种解决思路。
协同过滤中的做法:一个rating矩阵可以分解为user矩阵和item矩阵,每个user和item都可以采用一个隐向量表示
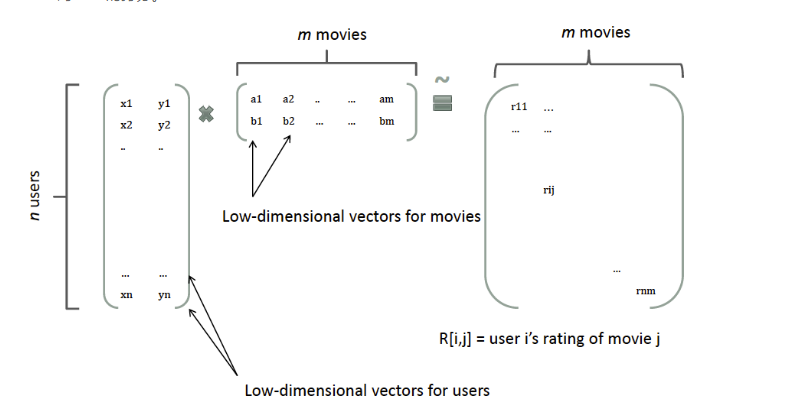
FM模型中二次项系数构成的矩阵是对称正定的(若所有特征值均大于零,则称为正定),故可以分解成两个低维的矩阵相乘,从而解决数据稀疏导致训练不准确的问题。
总结起来一句话就是:FM引入二维组合特征,然后利用矩阵分解降维减少了训练参数,从而能够适应数据的稀疏性
至此,FM模型可以化为如下形式:
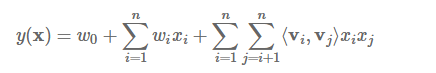
FM的学习算法主要包括,随机梯度下降(sgd)、交替最小二乘(als)、马尔可夫链蒙特卡罗(mcmc)。
| Task | Solver | Loss |
|---|---|---|
| Regression | als, mcmc, sgd | Square Loss |
| Classification | als, mcmc, sgd | Probit(Map), Probit, Sigmoid |
| Ranking | sgd | BPR |
来一个fm做分类的例子。tensorflow版本的
git clone https://github.com/geffy/tffm.git cd tffm
conda-env list
source activate tf
pip install scikit-learnpip install tqdm (Tqdm 是一个快速,可扩展的Python进度条,可以在 Python 长循环中添加一个进度提示信息)
https://github.com/geffy/tffm/blob/master/example.ipynb
/Users/jingyuli/PycharmProjects/tffm/tffm
example.py
先把MNIST数据集下载下来,既然是演示binary classification的任务。每个样本拉平784的长度。a 28 by 28 pixel image。灰度是0到1,而且大部分都是0.
取出两类 mnist_labels==3 mnist_labels==5作为正负类,Classes 还是比较balanced的。
再盖掉80%非零的元素,make it more sparse
Baselines表现怎么样?sk-learn里面的LogisticRegression、RandomForestClassifier(1w多样本,开根号,用200颗树吧)
model.fit一下,model.predict一下,搞定。
accuracy_score分别是0.881,0.889
TFFM 成绩是多少呢?accuracy: 0.909

